强化学习实例11:策略梯度法(Policy Gradient)
本实例基于策略梯度的算法来学习“打乒乓球”游戏

首先本实例的定义马尔可夫决策过程:
- 状态s:每一时刻的游戏画面
- 行动a:右边绿色拍,向上或向下
- 策略
 :状态为s下,采取行动a的概率
:状态为s下,采取行动a的概率
强化学习的目标是最大化长期回报期望:
 其中
其中![]() 为策略参数
为策略参数
定义目标函数J
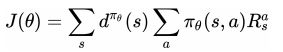
策略梯度为

用Q代替r
![]()
使用蒙特卡罗法求解

使用蒙特卡罗法,方差大。为了模型的稳定,提出Actor-Critic 算法,其主要特点是用一个独立的模型设计轨迹的长期回报,而不再直接使用轨迹的真实回报。算法整体包含了两个模型,一个是策略模型(actor),一个是价值模型(critic)。


伪代码

为了进一步减小方差,引入b
![]()
![]()
伪代码:

代码实现如下:使用神经网络拟合策略函数![]() ,输入为80x80的灰度图像,输出为向上移动的概率,模型包含130万个参数,需要训练几天。
,输入为80x80的灰度图像,输出为向上移动的概率,模型包含130万个参数,需要训练几天。

实际上并不知道label,因此需要转换为一局游戏策略和游戏结果

#import dependencies
import numpy as np #for matrix math
# import cPickle as pickle #to save/load model
import pickle #to
import gym
#hyperparameters
H = 200 #number of nodes in the hidden layer
batch_size = 10
learning_rate = 1e-4
gamma = 0.99 #discount factor
decay_rate = 0.99 #for RMS Prop Optimiser for Gradient Descent
resume = True #to resume from previous checkpoint or not
#initialise : init model
D = 80*80 #input dimension
if resume:
model = pickle.load(open('model.v','rb'))
else:
model = {}
#xavier initialisation of weights
model['W1'] = np.random.randn(H,D)*np.sqrt(2.0/D)
model['W2'] = np.random.randn(H)*np.sqrt(2.0/H)
grad_buffer = {k: np.zeros_like(v) for k,v in model.items()} #to store our gradients which can be summed up over a batch
rmsprop_cache = {k: np.zeros_like(v) for k,v in model.items()} #to store the value of rms prop formula
print(model)
#activation function
def sigmoid(x):
return 1.0/(1.0+np.exp(-x)) #adding non linearing + squashing
def relu(x):
x[x<0] = 0
return x
#preprocessing function
def prepro(I): #where I is the single frame of the game as the input
""" prepro 210x160x3 uint8 frame into 6400 (80x80) 1D float vector """
#the values below have been precomputed through trail and error by OpenAI team members
I = I[35:195] #cropping the image frame to an extent where it contains on the paddles and ball and area between them
I = I[::2,::2,0] #downsample by the factor of 2 and take only the R of the RGB channel.Therefore, now 2D frame
I[I==144] = 0 #erase background type 1
I[I==109] = 0 #erase background type 2
I[I!=0] = 1 #everything else(other than paddles and ball) set to 1
return I.astype('float').ravel() #flattening to 1D
def discount_rewards(r):
""" take 1D float array of rewards and compute discounted reward """
discount_r = np.zeros_like(r)
running_add = 0 #addition of rewards
for t in reversed(range(0,r.size)):
if r[t] != 0: #episode ends
running_add = 0
running_add = gamma*running_add+r[t]
discount_r[t] = running_add
return discount_r
def policy_forward(x):
h = np.dot(model['W1'],x)
h = relu(h)
logit = np.dot(model['W2'],h)
p = sigmoid(logit)
return p,h #probability of action 2(i.e. UP) and hidden layer state i.e. hidden state
def policy_backward(arr_hidden_state,gradient_logp,observation_values):
""" backward pass """
#arr_hidden_state is array of intermediate hidden states shape [200x1]
#gradient_logp is the loss value [1x1]
dW2 = np.dot(arr_hidden_state.T,gradient_logp).ravel() # [200x1].[1x1] => [200x1] =>flatten=>[1x200]
dh = np.outer(gradient_logp,model['W2']) # [1x1]outer[1x200] => [1x200]
dh = relu(dh) #[1x200]
dW1 = np.dot(dh.T,observation_values) #[200x1].[1x6400] => [200x6400]
return {'W1':dW1,'W2':dW2}
#implementation details
env = gym.make('Pong-v0')
observation = env.reset()
prev_x = None #prev frame value in order to compute the difference between current and previous frame
#as discussed frames are static and the difference is used to capture the motion
#Intially None because there's no previous frame if the current frame is the 1st frame of the game
episode_hidden_layer_values, episode_observations, episode_gradient_log_ps, episode_rewards = [], [], [], []
running_reward = None
reward_sum = 0
episode_number = 0
#begin training
while True:
env.render()
#get the input and preprocess it
cur_x = prepro(observation)
#get the frame difference which would be the input to the network
if prev_x is None:
prev_x = np.zeros(D)
x = cur_x - prev_x
prev_x = cur_x
#forward propagation of the policy network
#sample an action from the returned probability
aprob, h = policy_forward(x)
#stochastic part
if np.random.uniform() < aprob:
action = 2
else:
action = 3
episode_observations.append(x) #record observation
episode_hidden_layer_values.append(h) #record hidden state
if action == 2:
y = 1 # 上
else:
y = 0 # 下
episode_gradient_log_ps.append(y-aprob) #record the gradient
#new step in the environment
observation,reward,done,info = env.step(action)
reward_sum+=reward #for advantage purpose
episode_rewards.append(reward) #record the reward
if done: #if the episode is over
episode_number+=1
#stack inputs,hidden_states,actions,gradients_logp,rewards for the episode
arr_hidden_state = np.vstack(episode_hidden_layer_values)
gradient_logp = np.vstack(episode_gradient_log_ps)
observation_values = np.vstack(episode_observations) #
reward_values = np.vstack(episode_rewards) # label
#reset the memory arrays
episode_hidden_layer_values, episode_observations, episode_gradient_log_ps, episode_rewards = [], [], [], []
#discounted reward computation
discounted_episoderewards = discount_rewards(reward_values)
#normalise discounted_episoderewards i.e. we obtain Advantage
discounted_episoderewards = (discounted_episoderewards - np.mean(discounted_episoderewards))/np.std(discounted_episoderewards)
#modulate the gradient with the advantage
gradient_logp *= discounted_episoderewards
grad = policy_backward(arr_hidden_state,gradient_logp,observation_values)
#summing the gradients over the batch size
for layer in model:
grad_buffer[layer]+=grad[layer]
#perform RMS prop to update weights after every 10 episodes
if episode_number % batch_size == 0:
epsilon = 1e-5
for weight in model.keys():
g = grad_buffer[weight] #gradient
rmsprop_cache[weight] = decay_rate*rmsprop_cache[weight]+(1-decay_rate)*g**2
model[weight]+=learning_rate*g/(np.sqrt(rmsprop_cache[weight]) + epsilon)
grad_buffer[weight] = np.zeros_like(model[weight]) # 清零
if running_reward is None:
running_reward = reward_sum
else:
running_reward = running_reward*learning_rate+reward_sum*(1-learning_rate)
print('Episode Reward : {}, Running Mean Award : {}'.format(reward_sum,running_reward))
if episode_number % 100 == 0:
pickle.dump(model,open('model.v','wb'))
reward_sum = 0
prev_x = None
observation = env.reset() #resetting the environment since episode has ended
if reward != 0: #if reward is either +1 or -1 i.e. an episode has ended
print("Episode {} ended with reward {}".format(episode_number,reward))