HDFS的BLOCK损坏或丢失问题检查与处理
1. fsck命令介绍
fsck是file system check的简写,中文名其实就是文件系统检查,通过hdfs fsck命令可以看出具体的参数。
[hdfs@rtn01 ~]$ hdfs fsck
Usage: DFSck [-list-corruptfileblocks | [-move | -delete | -openforwrite] [-files [-blocks [-locations | -racks]]]] [-maintenance]
start checking from this path
-move move corrupted files to /lost+found
-delete delete corrupted files
-files print out files being checked
-openforwrite print out files opened for write
-includeSnapshots include snapshot data if the given path indicates a snapshottable directory or there are snapshottable directories under it
-list-corruptfileblocks print out list of missing blocks and files they belong to
-blocks print out block report
-locations print out locations for every block
-racks print out network topology for data-node locations
-maintenance print out maintenance state node details
-blockId print out which file this blockId belongs to, locations (nodes, racks) of this block, and other diagnostics info (under replicated, corrupted or not, etc)
Please Note:
1. By default fsck ignores files opened for write, use -openforwrite to report such files. They are usually tagged CORRUPT or HEALTHY depending on their block allocation status
2. Option -includeSnapshots should not be used for comparing stats, should be used only for HEALTH check, as this may contain duplicates if the same file present in both original fs tree and inside snapshots.
Generic options supported are
-conf specify an application configuration file
-D use value for given property
-fs specify a namenode
-jt specify a ResourceManager
-files specify comma separated files to be copied to the map reduce cluster
-libjars specify comma separated jar files to include in the classpath.
-archives specify comma separated archives to be unarchived on the compute machines.
The general command line syntax is
bin/hadoop command [genericOptions] [commandOptions]
Generic options supported are
-conf specify an application configuration file
-D use value for given property
-fs specify a namenode
-jt specify a ResourceManager
-files specify comma separated files to be copied to the map reduce cluster
-libjars specify comma separated jar files to include in the classpath.
-archives specify comma separated archives to be unarchived on the compute machines.
The general command line syntax is
bin/hadoop command [genericOptions] [commandOptions]
[hdfs@rtn01 ~]$
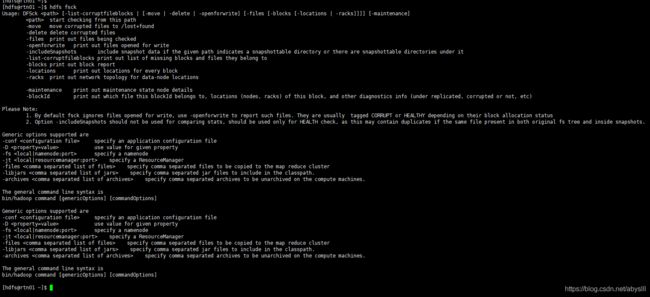
# 中文注解如下:
-move: 移动损坏的文件到/lost+found目录下
-delete: 删除损坏的文件
-openforwrite: 输出检测中的正在被写的文件
-list-corruptfileblocks: 输出损坏的块及其所属的文件
-files: 输出正在被检测的文件
-blocks: 输出block的详细报告 (需要和-files参数一起使用)
-locations: 输出block的位置信息 (需要和-files参数一起使用)
-racks: 输出文件块位置所在的机架信息(需要和-files参数一起使用)
2. 检测缺失的BLOCK块
- 输出损坏的块及其所属的文件
hdfs fsck -list-corruptfileblocks
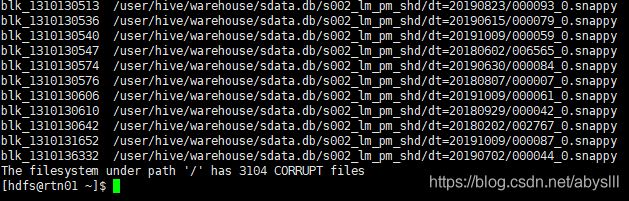
- 输出文件及其对应的块信息
hdfs fsck / | egrep -v '^\.+$' | grep -v eplica
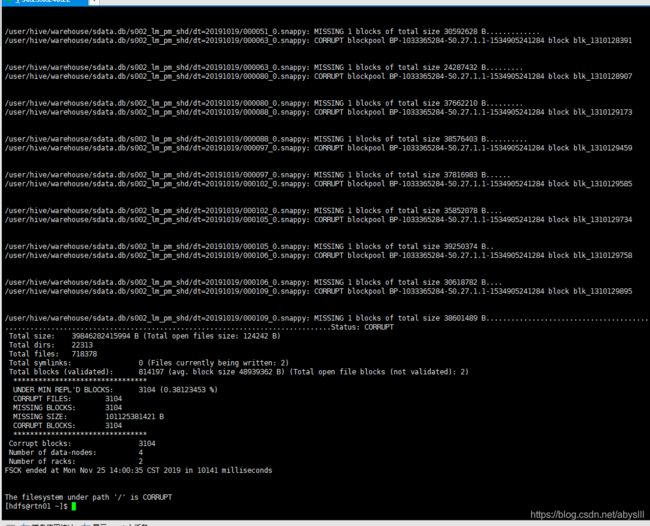
上图显示的不清晰,将最下方几行粘贴到下方:
/user/hive/warehouse/sdata.db/s002_lm_pm_shd/dt=20191019/000105_0.snappy: MISSING 1 blocks of total size 39250374 B..
/user/hive/warehouse/sdata.db/s002_lm_pm_shd/dt=20191019/000106_0.snappy: CORRUPT blockpool BP-1033365284-50.27.1.1-1534905241284 block blk_1310129758
/user/hive/warehouse/sdata.db/s002_lm_pm_shd/dt=20191019/000106_0.snappy: MISSING 1 blocks of total size 30618782 B....
/user/hive/warehouse/sdata.db/s002_lm_pm_shd/dt=20191019/000109_0.snappy: CORRUPT blockpool BP-1033365284-50.27.1.1-1534905241284 block blk_1310129895
/user/hive/warehouse/sdata.db/s002_lm_pm_shd/dt=20191019/000109_0.snappy: MISSING 1 blocks of total size 38601489 B...............................................................
..............................................................................Status: CORRUPT
Total size: 39846282415994 B (Total open files size: 124242 B)
Total dirs: 22313
Total files: 718378
Total symlinks: 0 (Files currently being written: 2)
Total blocks (validated): 814197 (avg. block size 48939362 B) (Total open file blocks (not validated): 2)
********************************
UNDER MIN REPL'D BLOCKS: 3104 (0.38123453 %)
CORRUPT FILES: 3104
MISSING BLOCKS: 3104
MISSING SIZE: 101125381421 B
CORRUPT BLOCKS: 3104
********************************
Corrupt blocks: 3104
Number of data-nodes: 4
Number of racks: 2
FSCK ended at Mon Nov 25 14:00:35 CST 2019 in 10141 milliseconds
The filesystem under path '/' is CORRUPT
[hdfs@rtn01 ~]$
- 查看上方命令返回的某一个块信息
hdfs fsck /user/hive/warehouse/sdata.db/s002_lm_pm_shd/dt=20191019/000106_0.snappy -locations -blocks -files

上图显示的不清晰,将信息粘贴到下方:
[hdfs@rtn01 ~]$ hdfs fsck /user/hive/warehouse/sdata.db/s002_lm_pm_shd/dt=20191019/000106_0.snappy -locations -blocks -files
Connecting to namenode via http://rtn02:50070
FSCK started by hdfs (auth:SIMPLE) from /50.27.1.1 for path /user/hive/warehouse/sdata.db/s002_lm_pm_shd/dt=20191019/000106_0.snappy at Mon Nov 25 14:07:19 CST 2019
/user/hive/warehouse/sdata.db/s002_lm_pm_shd/dt=20191019/000106_0.snappy 30618782 bytes, 1 block(s):
/user/hive/warehouse/sdata.db/s002_lm_pm_shd/dt=20191019/000106_0.snappy: CORRUPT blockpool BP-1033365284-50.27.1.1-1534905241284 block blk_1310129758
Replica placement policy is violated for BP-1033365284-50.27.1.1-1534905241284:blk_1310129758_236410095. Block should be additionally replicated on 1 more rack(s).
MISSING 1 blocks of total size 30618782 B
0. BP-1033365284-50.27.1.1-1534905241284:blk_1310129758_236410095 len=30618782 MISSING!
Status: CORRUPT
Total size: 30618782 B
Total dirs: 0
Total files: 1
Total symlinks: 0
Total blocks (validated): 1 (avg. block size 30618782 B)
********************************
UNDER MIN REPL'D BLOCKS: 1 (100.0 %)
dfs.namenode.replication.min: 1
CORRUPT FILES: 1
MISSING BLOCKS: 1
MISSING SIZE: 30618782 B
CORRUPT BLOCKS: 1
********************************
Minimally replicated blocks: 0 (0.0 %)
Over-replicated blocks: 0 (0.0 %)
Under-replicated blocks: 0 (0.0 %)
Mis-replicated blocks: 1 (100.0 %)
Default replication factor: 1
Average block replication: 0.0
Corrupt blocks: 1
Missing replicas: 0
Number of data-nodes: 4
Number of racks: 2
FSCK ended at Mon Nov 25 14:07:19 CST 2019 in 1 milliseconds
The filesystem under path '/user/hive/warehouse/sdata.db/s002_lm_pm_shd/dt=20191019/000106_0.snappy' is CORRUPT
[hdfs@rtn01 ~]$
3. BLOCK丢失后的解决办法
3.1 BLOCK部分副本损坏
- 方案一:hadoop会在6个小时候自动检测并修复
主动发现阶段:
当数据块损坏后,DN节点执行directoryscan操作(间隔6小时)之前,不会发现损坏。
dfs.datanode.directoryscan.interval : 21600
主动回复阶段:
在DN向NN进行blockreport(间隔6小时)前,都不会恢复数据块;
dfs.blockreport.intervalMsec : 21600000
当NN收到blockreport才会进⾏行行恢复操作(也就是12小时之后)
- 方案二:手工重启hdfs服务后会自动修复
重启hdfs服务会进行坏块检测,若发现坏块就会进行主动修复(不定期的重启集群服务对数据块的保护有很大的益处)
- 方案三:手工修复(推荐使用)
# 其实hdfs dfs -get而后-put就可以解决,或者用下面的命令也行。
hdfs debug recoverLease -path /user/hive/warehouse/sdata.db/s002_lm_pm_shd/dt=20191019/000106_0.snappy -retries 10
![]()
上图显示
成功,但由于我的集群是单副本,其实损坏的副本是没办法通过手工修复进行解决的,这里只是演示命令的截图。
3.2 BLOCK全副本均损坏
-
单副本(伪分布式),特别容易出现坏块,例如内存、磁盘、网络等各方面原因均能导致该现象出现
-
多副本,某些或某个BLOCK的所有副本全部丢失
若出现了上述的两种情况,那就只能通过如下两类处理办法解决。
3.2.1 若文件不重要
# 退出安全模式
hdfs dfsadmin -safemode leave
#删除损坏(丢失)的BLOCK
hdfs fsck /path -delete
执行上述命令前需确认如下两点:
-
退出安全模式
hadoop dfsadmin -safemode leave -
注意
/path的正确性,尽量不使用/,导致重要文件(已经全部损坏)还没有做相应处理就被删除,导致回溯困难。
注意: 这种方式会出现数据丢失,损坏的block会被删掉
3.2.2 若文件很重要
- 场景一:若数据来源于其他Hadoop集群,重新获取BLOCK并上传至缺失目录
# 源Hadoop集群,获取BLOCK
hdfs dfs -get /user/hive/warehouse/sdata.db/s002_lm_pm_shd/dt=20191019/000106_0.snappy
# 丢失BLOCK的集群
hdfs dfs -put 000106_0.snappy /user/hive/warehouse/sdata.db/s002_lm_pm_shd/dt=20191019/
- 场景二:若数据为Hadoop内部生成,需要重新生成数据
# 需要注意BLOCK若为某张HIVE表的一部分时,需要对表进行重新生成,而非仅仅对HDFS文件的操作
4.处理完成后再次检查BLOCK
hdfs fsck -list-corruptfileblocks
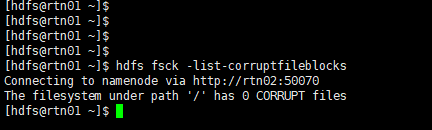
hdfs fsck /
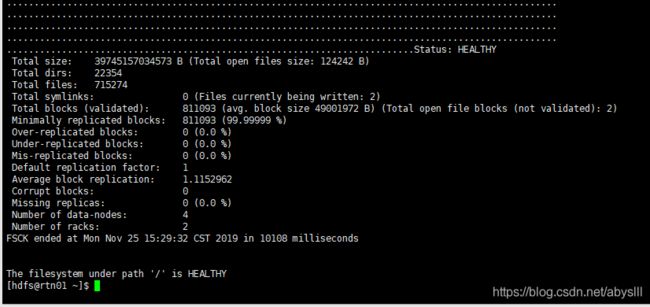
从上图可以看到,损坏(丢失)的BLOCK已经消失。