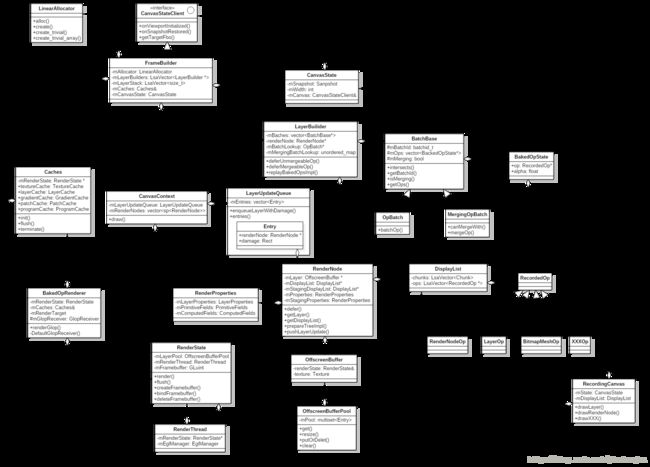
Android N中UI硬件渲染(hwui)的HWUI_NEW_OPS(基于Android 7.1)
原文地址:http://blog.csdn.net/jinzhuojun/article/details/54234354
- 背景
UI作为用户体验的核心之一,始终是Android每次升级中的重点。从Androd 3.0(Honeycomb)开始,Android开始支持
hwui(UI硬件加速)。到Android 4.0(ICS)时,硬件加速被默认开启。同时ICS还引入了
DisplayList的概念(不是OpenGL里的那个),它相当于是从View的绘制命令到GL命令之间的“中间语言”。它记录了绘制该View所需的全部信息,之后只要重放(replay)即可完成内容的绘制。这样如果View没有改动或只部分改动,便可重用或修改DisplayList,从而避免调用了一些上层代码,提高了效率。Android 4.3(JB)中引入了DisplayList的
defer操作,它主要用于对DisplayList中命令进行
Batch(批次)和
Merge(合并)。这样可以减少GL draw call和context切换以提高效率。之后,在Android 5.0(Lollipop)中又引入了
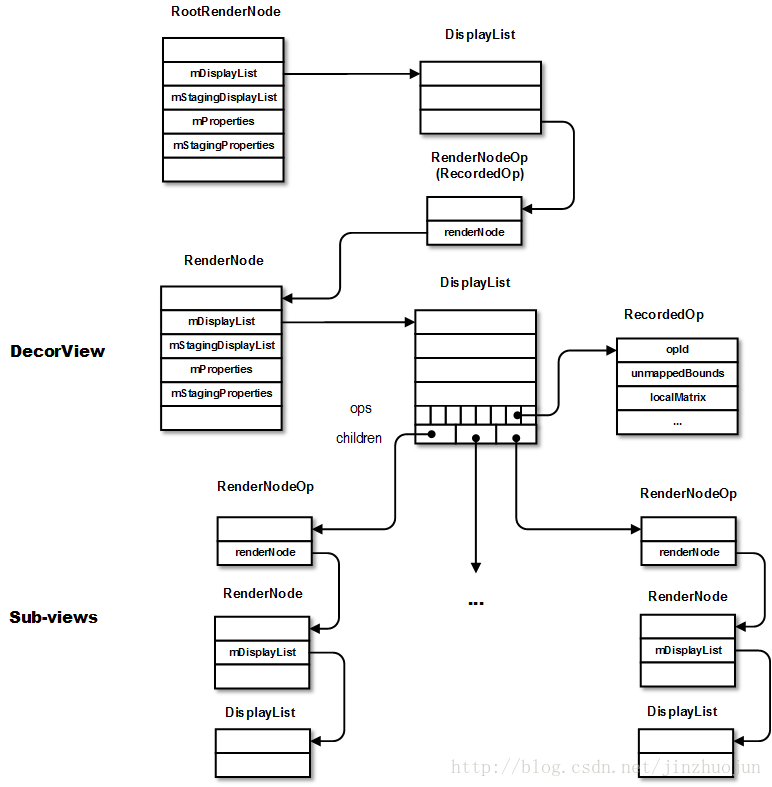
RenderNode(渲染节点)的概念,它是对DisplayList及一些View显示属性的进一步封装。代码上,一个View对应一个RenderNode(Native层对应同名类),其中管理着对应的DisplayList和OffscreenBuffer(如果该View为硬件绘制层)。每个向WindowManagerService注册的窗口对应一个RootRenderNode,通过它可以找到View层次结构中所有View的DisplayList信息。在Java层的DisplayListCanvas用于生成DisplayList,其在native层的对应类为RecordingCanvas(在Android N前为DisplayListCanvas)。另外Android L中还引入了
RenderThread(渲染线程)。所有的GL命令执行都放到这个线程上。渲染线程在RenderNode中存有渲染帧的所有信息,且还监听VSync信号,因此可以独立做一些属性动画。这样即便主线程block也可以保证动画流畅。引入渲染线程后ThreadedRenderer替代了Gl20Renderer,作为proxy用于主线程(UI线程)把渲染任务交给渲染线程。近期,在Android 7.0(Nougat)中又对hwui进行了小规模重构,引入了BakedOpRenderer, FrameBuilder, LayerBuilder, RecordingCanvas等类,用宏
HWUI_NEW_OPS管理。下面简单介绍下这些新成员:
- RecordingCanvas: 之前Java层的DisplayListCanvas对应native层的DisplayListCanvas。引入RecordingCanvas后,其在native层的对应物就变成了RecordingCanvas。和DisplayListCanvas类似,画在RecordingCanvas上的内容都会被记录在RenderNode的DisplayList中。
- BakedOpRenderer: 顾名思义,就是用于绘制batch/merge好的操作。用于替代之前的OpenGLRenderer。它是真正用GL绘制到on-screen surface上的。
- BakedOpDispatcher: 提供一系列onXXX(如onBitmapOp)和onMergedXXX(如onMergedBitmapOps)静态函数供replay时调用。这些dispatch函数最后一般都会通过GlopBuilder来构造Glop然后通过BakedOpRenderer的renderGlop()函数来用OpenGL绘制。
- LayerBuilder: 用于存储绘制某一层的操作和状态。替代了部分原DeferredDisplayList的工作。对于所有View通用,即如果View有render layer,它对应一个FBO;如果对于普通View,它对应的是SurfaceFlinger提供的surface。 其中的mBatches存储了当前层defer后(即batch/merge好)的绘制操作。
- FrameBuilder: 管理某一帧的构建,用于处理,优化和存储从RenderNode和LayerUpdateQueue中来的渲染命令,同时它的replayBakedOps()方法还用于该帧的绘制命令重放。一帧中可能需要绘制多个层,每一层的上下文都会存在相应的LayerBuilder中。在FrameBuilder中通过mLayerBuilders和mLayerStack存储一个layer stack。它替代了原Snapshot类的一部分功能。
- OffscreenBuffer: 用于替代Layer类,但是设计上更轻量,而且自带内存池(通过OffscreenBufferPool)。
- LayerUpdateQueue:用于记录类型为硬件绘制层的RenderNode的更新操作。之后会通过FrameBuilder将该layer对应的RenderNode通过deferNodeOps()方法进行处理。
- RecordedOp: 由RecordedCanvas将View中的绘制命令转化为RecordedOp。RecordedOp也是DisplayList中的基本元素,用于替代Android N之前的DisplayListOp。它有一坨各式各样的继承类代表各种各样的绘制操作。BakedOpState是RecordedOp和相应的状态的自包含封装(封装的过程称为bake)。
- BatchBase: LayerBuilder中对DisplayList进行batch/merge处理后的结果以BatchBase形式保存在LayerBuilder的mBatches成员中。它有两个继承类分别为OpBatch和MergingOpBatch,分别用于不可合并和可合并操作。
概括下它们和相关类的关系图如下,接下来从DisplayList(RenderNode)的构建和绘制两个阶段分析下具体有哪些改动。
- RenderNode构建
我们知道,通常情况下,App要完成一帧渲染,是通过ViewRootImpl的performTraversals()函数来实现。而它又可分为measure, layout, draw三个阶段。上面这些改动主要影响的是最后这步,因此我们就主要focus在draw这个阶段的流程。首先看DisplayList是怎么录制的。在ViewRootImpl::performDraw()中会调用draw()函数。当判断需要进行绘制时(比如有脏区域,或在动画中时),又如果硬件加速可用(通过ThreadedRenderer的isEnabled()),会进行下面的重绘动作。接下来根据是否有相关请求(如resize时)或offset是否有变化来判断是否要调用ThreadedRenderer的invalidRoot()来标记更新RootRenderNode。
扯个题外话。和Android M相比,N中UI子系统中加入了不少对用户进行窗口resize的处理,主要应该是为了Android N新增加的多窗口分屏模式。比如当用户拖拽分屏窗口边缘时,onWindowDragResizeStart()被调用。它其中会创建BackdropFrameRenderer。BackdropFrameRenderer本身运行单独的线程,它负责在resize窗口而窗口绘制来不及的情况下填充背景。它会通过addRenderNode()加入专用的RenderNode。同时,Android N中将DecorView从PhoneWindow中分离成一个单独的文件,并实现新加的WindowCallbacks接口。它主要用于当用户变化窗口大小时ViewRootImpl对DecorView的回调。因为ViewRootImpl和WindowManagerService通信,它会被通知到窗口变化,然后回调到DecorView中。而DecorView中的相应回调会和BackupdropFrameRenderer交互。如updateContentDrawBounds()中最后会调用到了BackupdropFrmeRenderer的onContentDrawn()函数,其返回值代表在下面的内容绘制后是否需要再发起一次绘制。如果需要,之后会调用requestDrawWindow()。
回到ViewRootImpl::performDraw()函数,接下来,最重要的就是通过ThreadedRenderer的draw()来进行绘制。在这个draw()函数中,比较重要的一步是通过updateRootDisplayList()函数来更新根结点的DisplayList。
652 private void updateRootDisplayList(View view, HardwareDrawCallbacks callbacks) {
653 Trace.traceBegin(Trace.TRACE_TAG_VIEW, "Record View#draw()");
654 updateViewTreeDisplayList(view);
655
656 if (mRootNodeNeedsUpdate || !mRootNode.isValid()) {
657 DisplayListCanvas canvas = mRootNode.start(mSurfaceWidth, mSurfaceHeight);
658 try {
659 final int saveCount = canvas.save();
660 canvas.translate(mInsetLeft, mInsetTop);
661 callbacks.onHardwarePreDraw(canvas);
662
663 canvas.insertReorderBarrier();
664 canvas.drawRenderNode(view.updateDisplayListIfDirty());
665 canvas.insertInorderBarrier();
666
667 callbacks.onHardwarePostDraw(canvas);
668 canvas.restoreToCount(saveCount);
669 mRootNodeNeedsUpdate = false;
670 } finally {
671 mRootNode.end(canvas);
672 }
673 }
674 Trace.traceEnd(Trace.TRACE_TAG_VIEW);
675 }
函数updateRootDisplayList()中的updateViewTreeDisplayList()会调到DecorView的updateDisplayListIfDirty()函数。这个函数主要功能是更新DecorView对应的RenderNode中的DisplayList。它返回的RenderNode会通过RecordingCanvas::drawRenderNode()函数将之作为RenderNodeOp加入到RootRenderNode的DisplayList中。函数updateDisplayListIfDirty()中首先判断当前View是否需要更新。如果不需要就调用dispatchGetDisplayList()让子View更新,然后直接返回。否则就是当前View的DisplayList需要更新。这里我们假设是第一次绘制,更新DisplayList的流程首先通过RenderNode的start()来获得一个用于记录绘制操作的Canvas,即DisplayListCanvas(在Android M中Java层由GLES20RecordingCanvas改为DisplayListCanvas,native层中的DisplayListRenderer改为DisplayListCanvas,Android N中native层中的DisplayListCanvas改为RecordingCanvas)。
接下去就是比较关键的步骤了。这里就要分几种情况了,一个View可以为三种类型(LAYER_TYPE_NONE, LAYER_TYPE_SOFTWARE, LAYER_TYPE_HARDWARE)中的一种。LAYER_TYPE_NONE为默认值,代表没有layer。LAYER_TYPE_SOFTWARE代表该View有软件层,以bitmap为back,内容用软件渲染。LAYER_TYPE_HARDWARE和LAYER_TYPE_SOFTWARE类似,区别在于其有硬件层,以FBO(Framebuffer object)为back,内容使用硬件渲染。如果硬件加速没有打开,它的行为和LAYER_TYPE_SOFTWARE是一样的。
16145 final DisplayListCanvas canvas = renderNode.start(width, height);
16146 canvas.setHighContrastText(mAttachInfo.mHighContrastText);
16147
16148 try {
16149 if (layerType == LAYER_TYPE_SOFTWARE) {
16150 buildDrawingCache(true);
16151 Bitmap cache = getDrawingCache(true);
16152 if (cache != null) {
16153 canvas.drawBitmap(cache, 0, 0, mLayerPaint);
16154 }
16155 } else {
16156 computeScroll();
16157
16158 canvas.translate(-mScrollX, -mScrollY);
16159 mPrivateFlags |= PFLAG_DRAWN | PFLAG_DRAWING_CACHE_VALID;
16160 mPrivateFlags &= ~PFLAG_DIRTY_MASK;
16161
16162 // Fast path for layouts with no backgrounds
16163 if ((mPrivateFlags & PFLAG_SKIP_DRAW) == PFLAG_SKIP_DRAW) {
16164 dispatchDraw(canvas);
16165 if (mOverlay != null && !mOverlay.isEmpty()) {
16166 mOverlay.getOverlayView().draw(canvas);
16167 }
16168 } else {
16169 draw(canvas);
16170 }
16171 }
16172 } finally {
16173 renderNode.end(canvas);
16174 setDisplayListProperties(renderNode);
16175 }
如果当前View是软件渲染层(类型为LAYER_TYPE_SOFTWARE)的话,则调用buildDrawingCache()获得Bitmap后调用drawBitmap()将该Bitmap记录到DisplayListCanvas中。现在Android中都默认硬件渲染了,为什么还要考虑软件渲染层呢?一方面有些平台不支持硬件渲染,或app不启用硬件加速,另一方面有些UI控件不支持硬件渲染 。在复杂的View(及子View)在动画过程中,可以被绘制成纹理,这样只需要画一次。显然,在View经常更新的情况下并不适用。因为这样每次都需要重新用软件渲染,如果硬件渲染打开时还要上传成硬件纹理(上传纹理是个比较慢的操作)。类似的,硬件渲染层(LAYER_TYPE_HARDWARE)也是适用于类似的复杂View结构进行属性动画的场景,但它与LAYER_TYPE_SOFTWARE的层的区别为它对应FBO,可以直接硬件渲染生成纹理。因此渲染的过程中不需要先生成Bitmap,从而省去了上传成硬件纹理的这一步操作。
如果当前View对应LAYER_TYPE_NONE或者LAYER_TYPE_HARDWARE,下面会考查是否为没有背景的Layout。这种情况下当前View没什么好画的,会走快速路径。即通过dispatchDraw()直接让子View重绘。否则就调draw()来绘制当前View及其子View。注意View中的draw()有两个重载同名函数。一个参数的版本用于直接调用。三个参数的版本用于ViewGroup中drawChild()时调用。这里调的是一个参数的版本。这个draw()函数中会按下面的顺序进行绘制(DisplayList的更新):
17162 /*
17163 * Draw traversal performs several drawing steps which must be executed
17164 * in the appropriate order:
17165 *
17166 * 1. Draw the background
17167 * 2. If necessary, save the canvas' layers to prepare for fading
17168 * 3. Draw view's content
17169 * 4. Draw children
17170 * 5. If necessary, draw the fading edges and restore layers
17171 * 6. Draw decorations (scrollbars for instance)
17172 */
这些是通过drawBackground(), onDraw(), dispatchDraw()和onDrawForeground()等函数实现。这些函数本质上就是将相应内容绘制到提供的DisplayListCanvas上。由于View是以树形层次结构组织的,draw()中会通过dispatchDraw()来更新子View的DisplayList。dispatchDraw()为对每个子View调用drawChild()。然后调用子View的draw()函数(这次就是上面说的draw()的三个参数的版本了)。这个版本的draw()函数里会更新其View的DisplayList,然后调用DisplayListCanvas的drawRenderNode()将该子view对应的RenderNode记录到其父view的DisplayList中去。这样便根据View的树型结构生成了DisplayList的树型结构。
其中onDraw()用于绘制当前View的自定义UI,它是每个View需要自定义的成员函数。比较典型地,在View的绘制函数中会调用canvas的drawXXX函数。比如canvas.drawLine(),它会通过JNI最后调到RecordingCanvas.cpp中的RecordingCanvas::drawLines():
284void RecordingCanvas::drawLines(const float* points, int floatCount, const SkPaint& paint) {
285 if (CC_UNLIKELY(floatCount < 4 || PaintUtils::paintWillNotDraw(paint))) return;
286 floatCount &= ~0x3; // round down to nearest four
287
288 addOp(alloc().create_trivial(
289 calcBoundsOfPoints(points, floatCount),
290 *mState.currentSnapshot()->transform,
291 getRecordedClip(),
292 refPaint(&paint), refBuffer(points, floatCount), floatCount));
293}
RecordingCanvas中绝大多数的drawXXX系函数都是类似于这样,通过addOp()将一个RecordedOp的继承类存到其成员mDisplayList中。RecordedOp家庭成员很多,有不少继承类,每个对应一种操作。操作的种类可以参照下这个表:
#define MAP_OPS_BASED_ON_TYPE(PRE_RENDER_OP_FN, RENDER_ONLY_OP_FN, UNMERGEABLE_OP_FN, MERGEABLE_OP_FN) \
76 PRE_RENDER_OP_FN(RenderNodeOp) \
77 PRE_RENDER_OP_FN(CirclePropsOp) \
78 PRE_RENDER_OP_FN(RoundRectPropsOp) \
79 PRE_RENDER_OP_FN(BeginLayerOp) \
80 PRE_RENDER_OP_FN(EndLayerOp) \
81 PRE_RENDER_OP_FN(BeginUnclippedLayerOp) \
82 PRE_RENDER_OP_FN(EndUnclippedLayerOp) \
83 PRE_RENDER_OP_FN(VectorDrawableOp) \
84 \
85 RENDER_ONLY_OP_FN(ShadowOp) \
86 RENDER_ONLY_OP_FN(LayerOp) \
87 RENDER_ONLY_OP_FN(CopyToLayerOp) \
88 RENDER_ONLY_OP_FN(CopyFromLayerOp) \
89 \
90 UNMERGEABLE_OP_FN(ArcOp) \
91 UNMERGEABLE_OP_FN(BitmapMeshOp) \
92 UNMERGEABLE_OP_FN(BitmapRectOp) \
93 UNMERGEABLE_OP_FN(ColorOp) \
94 UNMERGEABLE_OP_FN(FunctorOp) \
95 UNMERGEABLE_OP_FN(LinesOp) \
96 UNMERGEABLE_OP_FN(OvalOp) \
97 UNMERGEABLE_OP_FN(PathOp) \
98 UNMERGEABLE_OP_FN(PointsOp) \
99 UNMERGEABLE_OP_FN(RectOp) \
100 UNMERGEABLE_OP_FN(RoundRectOp) \
101 UNMERGEABLE_OP_FN(SimpleRectsOp) \
102 UNMERGEABLE_OP_FN(TextOnPathOp) \
103 UNMERGEABLE_OP_FN(TextureLayerOp) \
104 \
105 MERGEABLE_OP_FN(BitmapOp) \
106 MERGEABLE_OP_FN(PatchOp) \
107 MERGEABLE_OP_FN(TextOp)
各个View的DisplayList更新好后,回到udpateRootDisplayList()。如果发现RootRenderNode也需要更新,则先通过Java层的RenderNode::start()获得DisplayListCanvas,在这个Canvas上的动作都会被记录到DisplayList中,直到调用RenderNode.end()。然后为了防止对上下文状态的影响,用Canvas::save()和Canvas::restoreToCount()来生成临时的画布状态。再接下来就是通过drawRenderNode()将DecorView的RenderNode以RenderNodeOp的形式记录到RootRenderNode。
以上为DisplayList构建过程,列个大体流程图备忘。

- RenderNode绘制
在ThreadedRenderer的draw()函数中构建完DisplayList后,接下来需要准备渲染了。首先通过JNI调用nSyncAndDrawFrame()调用到native层的android_view_ThreadedRenderer_syncAndDrawFrame()。其中将参数中的FrameInfo数组传到RenderProxy的mFrameInfo成员中。它是Android M开始加入用来细化hwui性能统计的。同时调用RenderProxy的syncAndDrawFrame()函数,并将创建的TreeObserver作为参数。函数syncAndDrawFrame()中即调用DrawFrameTask(这是RenderThread的TaskQueue中的特殊Task实例)的drawFrame()函数。继而通过postAndWait()往RenderThread的TaskQueue里插入自身(即DrawFrameTask)来申请新一帧的渲染。在RenderThread的queue()函数中会按Task的运行时间将之插入到适当的位置。接着postAndWait()函数中会block UI线程等待渲染线程将之unblock。渲染线程在N中的改动不大,这里就不花太多文字介绍了,需要的时候把它当作跨线程调用即可。
另一边,渲染线程处理这个DrawFrameTask时会调用到其run()函数:
85void DrawFrameTask::run() {
86 ATRACE_NAME("DrawFrame");
87
88 bool canUnblockUiThread;
89 bool canDrawThisFrame;
90 {
91 TreeInfo info(TreeInfo::MODE_FULL, *mContext);
92 info.observer = mObserver;
93 canUnblockUiThread = syncFrameState(info);
94 canDrawThisFrame = info.out.canDrawThisFrame;
95 }
96
97 // Grab a copy of everything we need
98 CanvasContext* context = mContext;
99
100 // From this point on anything in "this" is *UNSAFE TO ACCESS*
101 if (canUnblockUiThread) {
102 unblockUiThread();
103 }
104
105 if (CC_LIKELY(canDrawThisFrame)) {
106 context->draw();
107 }
108
109 if (!canUnblockUiThread) {
110 unblockUiThread();
111 }
112}
其中首先通过DrawFrameTask::syncFrameState()函数将主线程的渲染信息(如DisplayList,Property和Bitmap等)同步到渲染线程。这个函数中首先会处理DrawFrameTask中的mLayers。它是DeferredLayerUpdater的vector,顾名思义,就是延迟处理的layer更新任务。这主要用于TextureView。TextureView是比较特殊的类。它通常用于显示内容流,生产者端可以是另一个进程。中间通过BufferQueue进行buffer的传输和交换。当有新的buffer来到(或者有属性变化,如visibility等)是,会通过回调设置标志位(mUpdateLayer)并通过invalidate()调度下一次重绘。当下一次draw()被调用时,先通过applyUpdate()->updateSurfaceTexture()->ThreadedRenderer::pushLayerUpdate(),再调到渲染线程中的 DrawFrameTask::pushLayerUpdate(),将本次更新记录在DrawFrameTask的mLayers中。这样,在后面调用DrawFrameTask::syncFrameState()是会依次调用mLayers中的apply()进行真正的更新。这里调用它的apply()函数就会取新可用buffer(通过doUpdateTexImage()函数),并将相关纹理信息更新到mLayer。在syncFrameState()函数中,接下来,通过CanvasContext的prepareTree()继而调用RenderNode的prepareTree()同步渲染信息。最后会输出TreeInfo结构,其中的prepareTextures代表纹理上传是否成功。如果为false,说明texture cache用完了。这样为了防止渲染线程在渲染过程中使用的资源和主线程竞争,在渲染线程绘制当前帧时就不能让主线程继续往下跑了,也就不能做到真正并行。在sync完数据后,DrawFrameTask::run()最后会调用CanvasContext::draw()来进行接下来的渲染。这部分的大体流程如下:

接下来瞄下CanvasContext::draw()里做了什么。先要小小准备下EGL环境,比如通过EglManager的beginFrame()函数,继而用eglMakeCurrent()将渲染context切换到相应的surface。然后EglManager的damageFrame()设定当前帧的脏区域(如果gfx平台支持局部更新的话)。接下来就是绘制的主体部分了。这也是N中改动比较大的部分。
405 auto& caches = Caches::getInstance();
406 FrameBuilder frameBuilder(dirty, frame.width(), frame.height(), mLightGeometry, caches);
407
408 frameBuilder.deferLayers(mLayerUpdateQueue);
409 mLayerUpdateQueue.clear();
410
411 frameBuilder.deferRenderNodeScene(mRenderNodes, mContentDrawBounds);
412
413 BakedOpRenderer renderer(caches, mRenderThread.renderState(),
414 mOpaque, mLightInfo);
415 frameBuilder.replayBakedOps(renderer);
416 profiler().draw(&renderer);
417 bool drew = renderer.didDraw();
先得到Caches的实例。它是一个单例类,包含了各种绘制资源的cache。然后创建FrameBuilder。该类用于当前帧的构建。FrameBuilder的构造函数中又会创建对应fbo0的LayerBuilder。fbo0即对应通过SurfaceFlinger申请来的on-screen surface,然后将之放入layer stack(通过mLayerBuilders和mLayerStack两个成员维护)。同时还会在initializeSaveStack()函数中创建和初始化Snapshot。就像名字一样,它保存了渲染surface的当前状态的一个“快照”。每个Snapshot有一个指向前继的Snapshot,从而形成一个"栈"。每次调用save()和restore()就相当于压栈和弹栈。

接下来deferLayers()函数处理LayerUpdateQueue中的元素。之前在渲染线程每画一帧前同步信息时调用RenderNode::prepareTree()会遍历DisplayList的树形结构,对于子节点递归调用prepareTreeImpl(),如果是render layer,在RenderNode::pushLayerUpdate()中会将该layer的更新操作记录到LayerUpdateQueue中。至于哪些节点是render layer。主要是根据之前提到的view类型(LAYER_TYPE_NONE/SOFTWARE/HARDWARE)。但会有一个优化,如果一个普通view满足promotedToLayer()定义的条件,它会被当做render layer处理。
76void FrameBuilder::deferLayers(const LayerUpdateQueue& layers) {
77 // Render all layers to be updated, in order. Defer in reverse order, so that they'll be
78 // updated in the order they're passed in (mLayerBuilders are issued to Renderer in reverse)
79 for (int i = layers.entries().size() - 1; i >= 0; i--) {
80 RenderNode* layerNode = layers.entries()[i].renderNode;
81 // only schedule repaint if node still on layer - possible it may have been
82 // removed during a dropped frame, but layers may still remain scheduled so
83 // as not to lose info on what portion is damaged
84 OffscreenBuffer* layer = layerNode->getLayer();
...
97
98 saveForLayer(layerNode->getWidth(), layerNode->getHeight(), 0, 0,
99 layerDamage, lightCenter, nullptr, layerNode);
100
101 if (layerNode->getDisplayList()) {
102 deferNodeOps(*layerNode);
103 }
104 restoreForLayer();
回到deferLayers()函数。这里就是把LayerUpdateQueue里的元素按逆序拿出来,依次调用saveForLayer(),deferNodeOps()和restoreForLayer()。saveForLayer()为该render laye创建Snapshot和LayerBuilder并放进mLayerStack和mLayerBuilders。而restoreForLayer()则是它的逆操作。Layer stack和canvas state是栈的结构。saveForLayer() 和restoreForLayer()就相当于一个push stack,一个pop stack。这里核心的deferNodeOps()函数处理该layer对应的DisplayList,将它们按以下类型以batch的形式组织存放在LayerBuilder的mBatches成员中。其中同一类型中能合并的操作还会进行合并(目前只支持Bitmap, Text和Patch三种类型的操作合并)。Batch的类型有以下几种:
45 enum {
46 Bitmap,
47 MergedPatch,
48 AlphaVertices,
49 Vertices,
50 AlphaMaskTexture,
51 Text,
52 ColorText,
53 Shadow,
54 TextureLayer,
55 Functor,
56 CopyToLayer,
57 CopyFromLayer,
58
59 Count // must be last
60 };511void FrameBuilder::deferNodeOps(const RenderNode& renderNode) {
512 typedef void (*OpDispatcher) (FrameBuilder& frameBuilder, const RecordedOp& op);
513 static OpDispatcher receivers[] = BUILD_DEFERRABLE_OP_LUT(OP_RECEIVER);
514
515 // can't be null, since DL=null node rejection happens before deferNodePropsAndOps
516 const DisplayList& displayList = *(renderNode.getDisplayList());
517 for (auto& chunk : displayList.getChunks()) {
...
522 for (size_t opIndex = chunk.beginOpIndex; opIndex < chunk.endOpIndex; opIndex++) {
523 const RecordedOp* op = displayList.getOps()[opIndex];
524 receivers[op->opId](*this, *op);
DisplayList以chunk为单位组合RecordedOp。这些RecordedOp的opId代表它们的类型。根据这个类型调用receivers这个查找表(通过BUILD_DEFERABLE_OP_LUT构造)中的函数。它会调用FrameBuilder中相应的deferXXX函数(比如deferArcOp, deferBitmapOp, deferRenderNodeOp等)。这些deferXXX系函数一般会将RecordedOp用BakedOpState封装一下,然后会调用LayerBuilder的deferUnmergeableOp()和deferMergeableOp()函数将BakedOpState组织进mBatches成员。同时还有两个查找表mBatchLookup和mMergingBatchLookup分别用于不能合并的batch(OpBatch)和能合并的batch(MergingOpBatch)。它们分别用于查找特定类型的最近一个OpBatch或者MergingOpBatch。
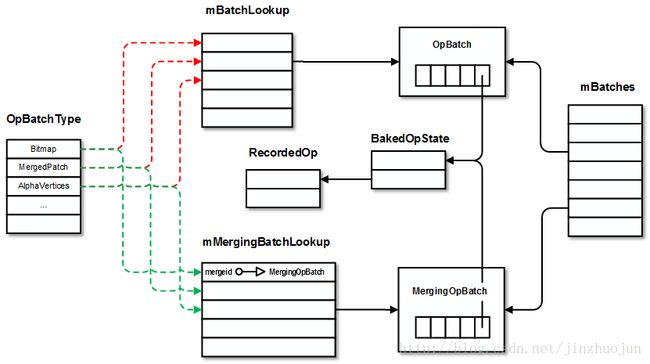
先看下deferUnmergeableOp()函数。它会将BakedOpState按batch类型放进mBatches中。mBatches是指向BatchBase对象的vector,每个处理好的BakedOpState都会按类型放进来。如果还未有该类型的batch则创建OpBatch,并把它插入到mBatches的末尾。同时插入mBatchLookup这个查找表(batchId到最近一个该类型的OpBatch对象的映射)。这样之后处理同类型的BakedOpState时候,就会先搜索这个查找表。假如找到了,则进一步在mBatches数组中找到相应的OpBatch并通过它的batchOp()将该BakedOpState加入。
287void LayerBuilder::deferUnmergeableOp(LinearAllocator& allocator,
288 BakedOpState* op, batchid_t batchId) {
289 onDeferOp(allocator, op);
290 OpBatch* targetBatch = mBatchLookup[batchId];
291
292 size_t insertBatchIndex = mBatches.size();
293 if (targetBatch) {
294 locateInsertIndex(batchId, op->computedState.clippedBounds,
295 (BatchBase**)(&targetBatch), &insertBatchIndex);
296 }
297
298 if (targetBatch) {
299 targetBatch->batchOp(op);
300 } else {
301 // new non-merging batch
302 targetBatch = allocator.create(batchId, op);
303 mBatchLookup[batchId] = targetBatch;
304 mBatches.insert(mBatches.begin() + insertBatchIndex, targetBatch);
305 }
306}
接下来看用于合并操作的deferMergeableOp()函数。它也是类似的,当没有可以合并的MergingOpBatch时会创建新的,并且插入到mBatches。因为可能存在情况这个batchId在mBatches中有但是mMergingBatchLookup中没找到(说明还没有可合并的MergingOpBatch对象)或者通过MergingOpBatch::canMergeWidth()判断不满足合并条件。这时候就要插入到mBatches中该类型所在位置。如果很顺利的情况下,前面已经有MergingOpBatch在mMergingBatchLookup中而且又满足合并条件,就通过MergingOpBatch::mergeOp()将该BakedOpState和已有的进行合并。
308void LayerBuilder::deferMergeableOp(LinearAllocator& allocator,
309 BakedOpState* op, batchid_t batchId, mergeid_t mergeId) {
310 onDeferOp(allocator, op);
311 MergingOpBatch* targetBatch = nullptr;
312
313 // Try to merge with any existing batch with same mergeId
314 auto getResult = mMergingBatchLookup[batchId].find(mergeId);
315 if (getResult != mMergingBatchLookup[batchId].end()) {
316 targetBatch = getResult->second;
317 if (!targetBatch->canMergeWith(op)) {
318 targetBatch = nullptr;
319 }
320 }
321
322 size_t insertBatchIndex = mBatches.size();
323 locateInsertIndex(batchId, op->computedState.clippedBounds,
324 (BatchBase**)(&targetBatch), &insertBatchIndex);
325
326 if (targetBatch) {
327 targetBatch->mergeOp(op);
328 } else {
329 // new merging batch
330 targetBatch = allocator.create(batchId, op);
331 mMergingBatchLookup[batchId].insert(std::make_pair(mergeId, targetBatch));
332
333 mBatches.insert(mBatches.begin() + insertBatchIndex, targetBatch);
334 }
335}
回到CanvasContext::draw()函数,处理好layer后,下面得就是通过FrameBuilder::deferRenderNodeScene()函数处理FrameBuilder成员mRenderNodes中的RenderNode,其中包含了RootRenderNode(也可能有其它的RenderNode,比如backdrop和overlay nodes)。对于每个RenderNode,如果需要绘制则调用FrameBuilder的deferRenderNode()函数:
117void FrameBuilder::deferRenderNode(float tx, float ty, Rect clipRect, RenderNode& renderNode) {
118 renderNode.computeOrdering();
119
120 mCanvasState.save(SaveFlags::MatrixClip);
121 mCanvasState.translate(tx, ty);
122 mCanvasState.clipRect(clipRect.left, clipRect.top, clipRect.right, clipRect.bottom,
123 SkRegion::kIntersect_Op);
124 deferNodePropsAndOps(renderNode);
125 mCanvasState.restore();
126}
这里和前面类似,会为之创建独立的Snapshot(Canvas渲染状态),deferNodePropsAndOps()根据RenderNode中的RenderProperties通过CanvasState设置一堆状态。如果该RenderNode对应是一个render layer,则将它封装为LayerOp(绘制offscreen buffer)并通过deferUnmergeableOp()加入batch。如果该RenderNode对应RenderProperties有半透明效果且不是render layer,则可以将该RenderNode绘制到一个临时的layer(称为save layer)。这是通过BeginLayerOp和EndLayerOp来记录的。正常情况下,还是通过deferNodeOps()来将RenderNode进行batch/merge。这个函数前面已有说明。
再次回到CanvasContext::draw()函数,下面终于要真得进行渲染了。首先创建BakedOpRenderer,然后调用FrameBuilder::replayBakedOps()函数并将BakedOpRenderer作为参数传进去。注意这是个模板函数,这里模板参数为BakedOpDispatcher。在replayBakedOps()函数中会构造两个用于处理BakedOpState的函数查找表。它们将BakedOpState按操作类型分发到BakedOpDispatcher的相应静态处理函数(onXXX或者onMergedXXX,分别用于非合并和合并的操作) 。
87 template
88 void replayBakedOps(Renderer& renderer) {
89 std::vector temporaryLayers;
90 finishDefer();
91 /**
92 * Defines a LUT of lambdas which allow a recorded BakedOpState to use state->op->opId to
93 * dispatch the op via a method on a static dispatcher when the op is replayed.
94 *
95 * For example a BitmapOp would resolve, via the lambda lookup, to calling:
96 *
97 * StaticDispatcher::onBitmapOp(Renderer& renderer, const BitmapOp& op, const BakedOpState& state);
98 */
99 #define X(Type) \
100 [](void* renderer, const BakedOpState& state) { \
101 StaticDispatcher::on##Type(*(static_cast(renderer)), \
102 static_cast(*(state.op)), state); \
103 },
104 static BakedOpReceiver unmergedReceivers[] = BUILD_RENDERABLE_OP_LUT(X);
105 #undef X
106
107 /**
108 * Defines a LUT of lambdas which allow merged arrays of BakedOpState* to be passed to a
109 * static dispatcher when the group of merged ops is replayed.
110 */
111 #define X(Type) \
112 [](void* renderer, const MergedBakedOpList& opList) { \
113 StaticDispatcher::onMerged##Type##s(*(static_cast(renderer)), opList); \
114 },
115 static MergedOpReceiver mergedReceivers[] = BUILD_MERGEABLE_OP_LUT(X);
116 #undef X
117
如前面如述,之前已经在FrameBuilder中构造了LayerBuilder的stack。接下来,这儿就是按push时的逆序(z-order高到底)对其中的BakedOpState进行replay,因为下面的layer可能会依赖的上面layer的渲染结果。比如要把上面layer画在FBO上的东西当成纹理画到下一层layer上。对于layer(persistent或者temporary的),先在BakedOpRenderer::startRepaintLayer()中初始化相关GL环境,比如创建FBO,绑定layer对应OffscreenBuffer中的纹理,设置viewport,清color buffer等等。对应地,BakedOpRenderer::endLayer()中最相应的销毁和清理工作。中间调用LayerBuilder::replayBakedOpsImpl()函数做真正的replay动作。对于fbo0(即on-screen surface),也是类似的,只是把startRepaintLayer()和endLayer()换成BakedOpRenderer::startFrame()和BakedOpRenderer::endFrame()。它们的功能也是初始化和销毁GL环境。
118 // Relay through layers in reverse order, since layers
119 // later in the list will be drawn by earlier ones
120 for (int i = mLayerBuilders.size() - 1; i >= 1; i--) {
121 GL_CHECKPOINT(MODERATE);
122 LayerBuilder& layer = *(mLayerBuilders[i]);
123 if (layer.renderNode) {
124 // cached HW layer - can't skip layer if empty
125 renderer.startRepaintLayer(layer.offscreenBuffer, layer.repaintRect);
126 GL_CHECKPOINT(MODERATE);
127 layer.replayBakedOpsImpl((void*)&renderer, unmergedReceivers, mergedReceivers);
128 GL_CHECKPOINT(MODERATE);
129 renderer.endLayer();
130 } else if (!layer.empty()) {
131 // save layer - skip entire layer if empty (in which case, LayerOp has null layer).
132 layer.offscreenBuffer = renderer.startTemporaryLayer(layer.width, layer.height);
133 temporaryLayers.push_back(layer.offscreenBuffer);
134 GL_CHECKPOINT(MODERATE);
135 layer.replayBakedOpsImpl((void*)&renderer, unmergedReceivers, mergedReceivers);
136 GL_CHECKPOINT(MODERATE);
137 renderer.endLayer();
138 }
139 }
140
141 GL_CHECKPOINT(MODERATE);
142 if (CC_LIKELY(mDrawFbo0)) {
143 const LayerBuilder& fbo0 = *(mLayerBuilders[0]);
144 renderer.startFrame(fbo0.width, fbo0.height, fbo0.repaintRect);
145 GL_CHECKPOINT(MODERATE);
146 fbo0.replayBakedOpsImpl((void*)&renderer, unmergedReceivers, mergedReceivers);
147 GL_CHECKPOINT(MODERATE);
148 renderer.endFrame(fbo0.repaintRect);
149 }
在replayBakedOpsImpl()函数中,会根据操作的类型调用前面生成的unmergedReceivers和mergedReceivers两个函数分发表中的对应处理函数。它们实质指向BakedOpDispatcher中的静态函数。这些函数onXXXOp()和onMergedXXXOps()函数大同小异,基本都是通过GlopBuilder将BakedOpState和相关的信息封装成Glop对象,然后调用BakedOpRenderer::renderGlop(),接着通过DefaultGlopReceiver()调用BakedOpRenderer::renderGlopImpl()函数,最后在RenderState::render()中通过GL命令将Glop渲染出来。大功告成。
- 结语

这样做有几个好处:第一、对绘制操作进行batch/merge可以减少GL的draw call,从而减少渲染状态切换,提高了性能。第二、因为将View层次结构要绘制的东西转化为DisplayList这种“中间语言”的形式,当需要绘制时才转化为GL命令。因此在View中内容没有更改或只有部分属性更改时只要修改中间表示(即RenderNode和RenderProperties)即可,从而避免很多重复劳动。第三、由于DisplayList中包含了要绘制的所有信息,一些属性动画可以由渲染线程全权处理,无需主线程介入,主线程卡住也不会让界面卡住。另一方面,也可以看到一些潜力可挖。比如当前可以合并的操作类型有限。另外主线程和渲染线程间的很多调用还是同步的,并行度或许可以进一步提高。另外Vulkan的引入也可以帮助进一步榨干GPU的能力。