TAILQ的使用与源码分析
TAILQ是Linux中的一种双向队列(在libevent中有广泛引用),能实现操作队列需要的各种操作:插入元素,删除元素,遍历队列等。这个队列的优点是插入元素很快。
简单的例子
#include 源码分析
1. TAILQ_ENTRY TAILQ_HEAD结构体
TAILQ_ENTRY结构体和TAILQ_HEAD结构体基本一致,但是表示的含义不一样。TAILQ_ENTRY结构体用来表示链表节点的指针域(类似于平时编程中的链表指针域,单向链表中一般含有next指针,而双向链表含有pre,next指针)。
TAILQ_HEAD结构是用来表示链表的头节点和尾节点的指针。
#define TAILQ_HEAD(name, type) \
struct name { \
struct type *tqh_first; \
struct type **tqh_last; \
}
#define TAILQ_ENTRY(type) \
struct { \
struct type *tqe_next; /* next element */ \
struct type **tqe_prev; /* address of previous next element */ \
}
注意到,这里的tqe_pre和tqh_last都是二级指针。下图是TAILQ的内部结构(来源:https://blog.csdn.net/ylo523/article/details/43274627)
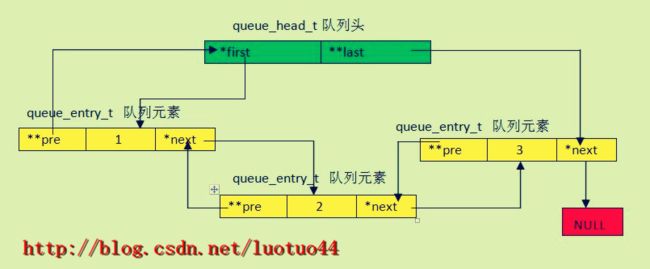
为什么是二级指针?
next是指向的是下一个元素的地址(由于下一个元素的类型是type,所以是一级指针type*)
pre是指向上一个元素next成员的地址(由于next成员类型是type*,所以需要使用指针type**)
跟我们平常实现的链表有什么不同?
我们平常的双向链表大概是这样子的,
struct item_t {
int value;
item_t *pre, *next;
};
// 简单的3个节点插入过程
item_t head,node1,node2;
head.value=1,node1.value=2,node2.value=3;
head.pre=NULL;head.next=&node1;
node1.pre=&head;node1.next=&node2;
node2.pre=&node1;node2.next=NULL;
指针域都是以及指针,因为只需要存放下一个元素或者是上一个元素的地址;而TAILQ的pre指针存放的是上一个元素某一个成员的地址,而该成员的类型刚好是type*。
2. 初始化和尾部插入 TAILQ_INIT TAILQ_INSERT_TAILQ
#define TAILQ_INIT(head) do { \
(head)->tqh_first = NULL; \
(head)->tqh_last = &(head)->tqh_first; \
} while (/*CONSTCOND*/0)
#define TAILQ_INSERT_TAIL(head, elm, field) do{ \
(elm)->field.tqe_next = NULL; \
(elm)->field.tqe_prev = (head)->tqh_last; \
*(head)->tqh_last = (elm); \
(head)->tqh_last = &(elm)->field.tqe_next; \
}while (0)
初始化:将last指向链表的first域
尾插入:画图之后很好理解。。
3. 头部插入TAILQ_INSERT_HEAD
#define TAILQ_INSERT_HEAD(head, elm, field) do { \
if (((elm)->field.tqe_next = (head)->tqh_first) != NULL) \
(head)->tqh_first->field.tqe_prev = \
&(elm)->field.tqe_next; \
else \
(head)->tqh_last = &(elm)->field.tqe_next; \
(head)->tqh_first = (elm); \
(elm)->field.tqe_prev = &(head)->tqh_first; \
} while (/*CONSTCOND*/0)
这里的思路与前面的一样,画个图就能看出来,需要注意的是head的可能是空,所以head的tqe_first如果是空的话,则需要单独处理。
4. 遍历与逆序遍历
#define TAILQ_FOREACH(var, head, field) \
for ((var) = ((head)->tqh_first); \
(var); \
(var) = ((var)->field.tqe_next))
这个就是对TAILQ的进行简单的遍历,容易理解。
逆序遍历比较的复杂,源码如下:
#define TAILQ_FOREACH_REVERSE(var, head, headname, field) \
for ((var) = (*(((struct headname *)((head)->tqh_last))->tqh_last)); \
(var); \
(var) = (*(((struct headname *)((var)->field.tqe_prev))->tqh_last)))
为了理解这个源码,我们需要知道以下:
①假设现在有一个TAILQ,其中某一个节点的指针为node,如何找到node的上一个节点?
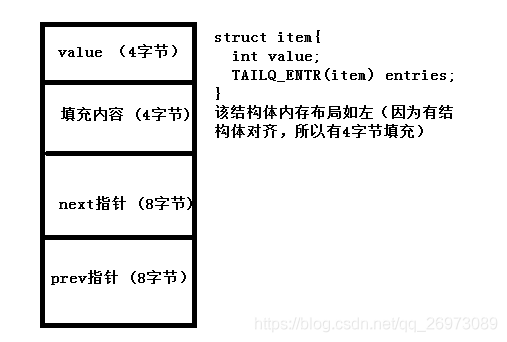
结构体在64位下的内存布局如上图所示(64位的指针为8字节)
根据TAILQ结构的性质,我们可以得到该等式是成立的(不考虑空指针的问题)
*(node->prev) == node
由上面的公式得知,把node->prev看成整体,知道一个节点的prev指针就可以获取到该节点的指针(这就是用二级指针的原因)。知道这个性质,我们就可以来求解node节点的前置指针了。
首先: 获取到node节点的前一个节点的next域的地址 node->prev
然后: 以这个地址为起始,将next和prev看成是一个TAILQ_HEAD的结构体,即可获取到node前一个节点的prev指针的地址 item_head_t* p1 = (item_head_t*)(node->prev); item_t *p2 = p1->last;
最后,按上面那个公式的套路来获取指针 *p2
②如何获取尾节点
按照上面的分析,思路是一样的。。