MySql并列排名
业务背景
数据排名是很常用的功能,简单的排名功能可以根据order by来实现,但是如果数据一样,排名应该并列的时候,order by虽然是排序的,但是名次却不是并列的。
我们先通过order by演示一下。
建表
CREATE TABLE `user_score` (
`user_id` INT(11) NOT NULL AUTO_INCREMENT COMMENT '用户id',
`score` TINYINT(3) UNSIGNED NOT NULL COMMENT '得分',
PRIMARY KEY (`user_id`)
) ENGINE=INNODB DEFAULT CHARSET=utf8 COMMENT='用户成绩表'插入数据
INSERT INTO user_score (score)
VALUES
(95),
(94),
(97),
(95),
(96),
(96),
(99),
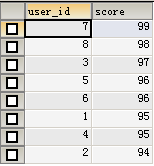
(98);通过order by 排名
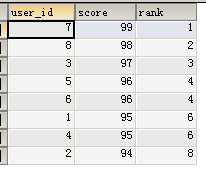
select * from user_score order by score desc;结果如下:
可以看出,通过order by的结果虽然是有序的,但是不是真正的名次,此时如果要得到名次只有通过业务代码中去排序得到1,2,3这样的。
基本思路
我们通过order by可以得到排序后的结果,不过这个结果不代表名次,我们应该再进行一次遍历来得到最终的名次。
这个遍历的过程当然可以放到业务上去做,不过也可以通过sql直接就生成的。
思路也是一样的,先order by获取到了有序的数据,然后通过一个变量来计算真正的名次。
简单的排名
我们先不考虑并列的情况,先通过MySql的变量,直接生成带有顺序的结果
SELECT u.user_id, u.score, @rank := @rank + 1
FROM
(SELECT * FROM user_score ORDER BY score DESC) u, (SELECT @rank := 0) r;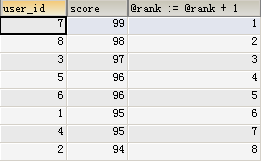
这里我先通过order by得到了有序的结果,然后定义了一个变量@rank并赋值为0。
再次通过SELECT 语句查询排序后的结果,每一条数据结果都加变量@rank++,这样就有了一个不区分并列情况的名次了。
并列排名
并列排名分为两种情况,一种是并列了就占位位置了,比如名次是:1,2,2,4… 因为有两个第二名,所以就占了第三名的位置。另一种就是并列了不占位置,名次就是:1,2,3,4…
并列但不占位
再简单排名的基础上,多创建一个变量,用来记录上一个人的分数,然后通过比较来判断名次是否需要增加
SELECT u.user_id, u.score,
CASE
WHEN @last_score = u.score
THEN @rank
WHEN @last_score := u.score
THEN @rank := @rank + 1
END AS rank
FROM
(SELECT * FROM user_score ORDER BY score DESC) u, (SELECT @rank := 0, @last_score := NULL) r;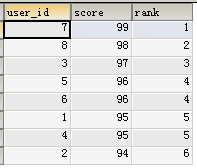
并列要占位
将简单排名和不占位的并列排名综合一下就可以得到并列要占位的排名了。
按照并列且占位的规则来排名,那么96分应该是第四名,95分是第6名。
我们观察之前两次查询的结果,可以发现,当分数和上一次一样的时候取第一个分数的排名,当分数不一样的时候,取简单排名的名次。
SELECT t.user_id, t.score, t.rank
FROM
(SELECT u.user_id, u.score, @rank := @rank + 1,
@last_rank := CASE
WHEN @last_score = u.score
THEN @last_rank
WHEN @last_score := u.score
THEN @rank
END AS rank
FROM
(SELECT * FROM user_score ORDER BY score DESC) u,
(SELECT @rank := 0, @last_score := NULL, @last_rank := 0) r
) t;