前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者:气象学渣
一、准备工作
1、Selenium的介绍与安装
Selenium是一个Web的自动化(测试)工具,它可以根据我们的指令,让浏览器执行自动加载页面,获取需要的数据等操作。
爬虫,就是一段自动抓取互联网信息的程序,从互联网上抓取对于我们有价值的信息,就好像一只虫子在一幢楼里不知疲倦地爬来爬去。
传统的爬虫通过直接模拟 HTTP 请求来爬取站点信息,由于这种方式和浏览器访问差异比较明显,很多站点都采取了一些反爬的手段。 Selenium 是通过模拟浏览器来爬取信息,其行为和用户几乎一样,而且不用去分析每个请求的具体参数,比起传统的爬虫学起来更容易。唯一缺点是速度较慢,如果对爬虫的速度没有要求,那使用 Selenium 是个非常不错的选择。
Selenium的安装相当简单,直接pip install selenium在线安装就行了。
PS:如有需要Python学习资料的小伙伴可以加下方的群去找免费管理员领取
可以免费领取源码、项目实战视频、PDF文件等
2. chromedriver的下载与安装
Selenium 自身并不具备浏览器的功能,它需要与第三方浏览器结合在一起才能使用。Google的Chrome浏览器能很方便的支持此项功能,只需安装其驱动程序Chromedriver就可以了。
下载地址:http://chromedriver.storage.googleapis.com/index.html
如何查看浏览器版本?可以在地址栏输入‘chrome://version/’,第一行就是版本信息。以小渣自己的浏览器为例,版本为76.0.3809.132(32位)。(补充,也可以在软件通常都有的“关于”信息中找到)

接着,下载对应版本的chromedriver(若无,则下载版本号最接近的即可)。小渣这里下载的是76.0.38.09.126。
解压下载文件,得到chromedriver.exe。作为一个新手教程,小渣不建议去设置什么复杂的环境变量,后续在使用chromedriver时用加绝对路径引用就行。
二、Python+Selenium爬虫
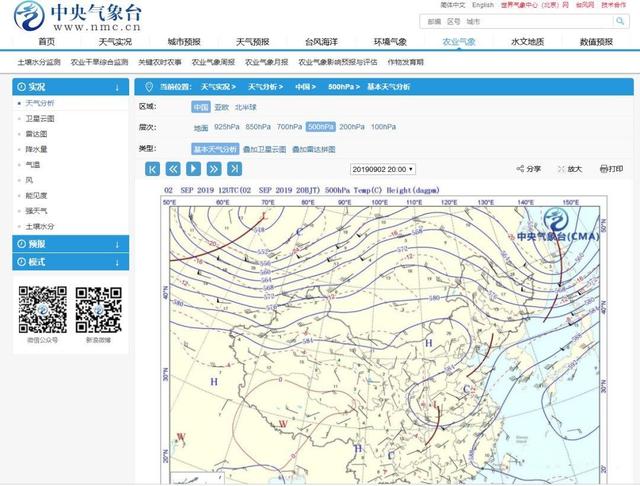
完成准备工作之后就可以进行爬虫了。首先我们使用Selenium的浏览器驱动接口工具webdriver打开我们的爬取目标:中央气象台网站上的每日天气图。
代码:
from selenium import webdriver ## 导入selenium的浏览器驱动接口 chrome_driver = 路径+'chromedriver.exe' #chromedriver的文件位置 driver = webdriver.Chrome(executable_path = chrome_driver) #加载浏览器驱动 driver.get('http://www.nmc.cn/publish/observations/china/dm/weatherchart-h000.htm') #打开页面
1、Selenium页面元素定位
假设我们想下载500hPa高度的基本天气分析图,在平时我们会怎么做?肯定是在页面上点击500hPa,选择基本天气分析,然后对图片右键另存为对不对?那么接下来我们就要借助Selenium对网页进行控制,爬取的过程也就是模拟上述一系列人为操作让机器来自动执行。
Selenium对网页的控制是基于各种HTML结构元素的,在使用过程中,对于网页各类元素的定位是基础,只有准确抓取到对应元素才能进行后续的自动化控制。
1.1 查看页面元素
Selenium定位时会涉及到一点HTML基础知识,但不懂也没关系,我们有偷懒的办法。利用chrome浏览器的开发者工具,在chrome浏览器中右键点击-->检查,我们可以轻松地查看应的页面元素。
举个例子:我们移动鼠标到层次500hPa,就可以自动定位到500hPa层级按钮对应的HTML元素了,查看到它的属性,可以看到500hPa这个按钮对应的页面元素是link文字。

1.2 元素定位
元素查看完毕后,接着就要进行元素定位,顾名思义就是要找到这个元素在网页中的位置,这样后续才能进行精确的页面控制。Selenium提供了很多种定位元素的方法,本文用到的主要有2个:
id定位:find_element_by_id()
link定位:find_element_by_link_text()
button1=driver.find_element_by_link_text('500hPa') #通过link文字精确定位元素 button2=driver.find_element_by_id('plist') #通过id精确定位元素 elem_pic = driver.find_element_by_id('imgpath') #通过id精确定位元素
2、ActionChains模拟鼠标操作
元素定位完成后,还需要模拟鼠标进行悬浮和单击等操作来选择和下载我们所需目标图片。Selenium给我们提供了一个类来处理这类事件——ActionChains。这里用到的2个操作是:
鼠标悬浮操作:move_to_element ()
单击鼠标左键:click()
下面给出完整的实现脚本:
from selenium import webdriver ## 导入selenium的浏览器驱动接口 from selenium.webdriver.common.action_chains import ActionChains import time import os chrome_driver = 路径+'chromedriver.exe' #chromedriver的文件位置 driver = webdriver.Chrome(executable_path = chrome_driver) #加载浏览器驱动 driver.get('http://www.nmc.cn/publish/observations/china/dm/weatherchart-h000.htm') #打开页面 # driver.maximize_window() time.sleep(1) #模拟鼠标选择高度层 button1=driver.find_element_by_link_text('500hPa') #通过link文字精确定位元素 action = ActionChains(driver).move_to_element(button1) #鼠标悬停在一个元素上 action.click(button1).perform() #鼠标单击 time.sleep(1) #注意加等待时间,避免因速度太快而失败 for p in range(1,3): #下载昨日08点和20点的天气图 str_p=str(p) #模拟鼠标选择时间 button2=driver.find_element_by_id('plist') #通过id精确定位元素 action = ActionChains(driver).move_to_element(button2) #鼠标悬停在一个元素上 action.click(button2).perform() #鼠标单击 time.sleep(1) Select(button2).select_by_index(str_p) #下拉菜单通过文本值定位从0开始 time.sleep(1) #模拟鼠标选择图片 elem_pic = driver.find_element_by_id('imgpath') #通过id精确定位元素 action = ActionChains(driver).move_to_element(elem_pic) action.context_click(elem_pic).perform() #鼠标右击 filename= str(elem_pic.get_attribute('src')).split('/')[-1].split('?')[0] #获取文件名 print(filename) time.sleep(1)