CVPR 2018 | 旷视科技Face++新方法——通过角点定位和区域分割检测场景文本
全球计算机视觉顶会 CVPR 2018 (Conference on Computer Vision and Pattern Recognition,即IEEE国际计算机视觉与模式识别会议)将于6月18日至22日在美国盐湖城举行。作为大会钻石赞助商,旷视科技Face++研究院也将在孙剑博士的带领下重磅出席此次盛会。而在盛会召开之前,旷视将针对 CVPR 2018 收录论文集中进行系列解读。

论文名称:Multi-Oriented Scene Text Detection via Corner Localization and Region Segmentation
论文链接:https://arxiv.org/abs/1802.08948
目录
- 导语
- 设计思想
- 网络架构
- 特征提取
- 角点检测
- 位置敏感分割
- 训练与推理
- 实验结果
- 多方向文本
- 水平文本
- 多方向长文本
- 多语种文本
- 泛化能力
- 结论
- 参考文献
导语
在机器之眼的检测矩阵中,自然场景文本是一类不可避及的重要对象,且有外景、视频、网页、字幕、截图等多种表现形式。旷视科技Face++通过吸取物体检测与语义分割的各自优势,并作创新性整合,突破性地提出了一种新型文本检测器,把检测精度推进到全新高度。这种底层检测技术迭代升级的影响是普适性的,意味着绝大多数与文本识别相关的实际应用都可得到不同程度的优化和完善,促进文本检测技术在直播、电商、论坛等 UGC 型内容平台网站,或者弹幕、评论、群聊、昵称等视频网站与社交 APP 中的应用;进一步提升产品和图像中关于文本的搜索检索能力,促进智能零售、无人超市等产业的发展和普及,甚至是促进自动驾驶技术的进步。由此可见,旷视科技推出的新型文本检测技术不仅有助于帮助客户走出海量数据的困境,制定个性化策略,高效过滤多类垃圾文字及敏感词,消除文本隐患,进而营造智能、安全、文明的社会环境,还可以推动新零售、无人超市、自动驾驶的进步发展。
设计思想
最近,由于实际应用需求不断增长,从现实场景图像中提取文本信息变得日益流行。场景文本检测——一种自然图像文本的定位技术——在各种文本阅读系统中发挥着不可或缺的作用。
由于内外两种因素,场景文本检测挑战重重。外部因素是指噪音、模糊、遮挡等外在环境,它们同样是困扰一般物体检测的主要根源。内部因素来自场景文本的属性。相较于一般物体检测,场景文本检测更为复杂,因为:1)自然场景中文本可以是任意方向的,因此需要检测的边界框通常为旋转的矩形或四边形;2)场景文本边界框的长宽比变化很大,且通常会存在极端的长宽比;3)场景文本的粒度多样,有字符、单词或者文本行等多种形式,算法在定位边界框时会难以判定文本实例。

图 1:上行和下行自左至右依次是已预测的左上、右上、右下、左下角点和位置敏感图。
过去几年中,场景文本检测获得大量研究,加之一般物体检测和语义分割的推动,场景文本检测近期成果显著,演化出两类主流的检测器。第一类基于一般物体检测器 SSD、YOLO、DenseBox,可以直接预测候选边界框;第二类基于语义分割,可以生成分割图,通过后处理给出最终的文本框。
本文结合了上述两类方法的思想,并加以创新,其提出主要基于下面两个发现:1)我们可以通过矩形的角点(corner point,左上,右上,右下,左下,如图 1 所示)来确定一个矩形,而不用考虑其大小、长宽比或者方向;2)文本区域分割图可以提供有效的文本定位信息,位置敏感(position-sensitive)的文本区域分割图(图 1)可以提供有效的文本实例信息。因此,本文首先直接检测文本的角点而不是回归文本框。另外,本文预测位置敏感的的分割图而不是文本/非文本图。最后,本文通过采样和组合已检测的角点生成候选边界框,并根据分割信息消除不合理的边界框。本文提出方法的 pipeline 如图 2 所示。

图 2:本文方法概览。给定一张图像,网络借助角点检测和位置敏感的分割输出角点和分割图;然后通过采样和组合角点生成候选框;最后,这些候选框通过分割图进行评分,并由 NMS 抑制冗余的候选框。
本文方法的主要亮点有:1)由于通过采样和组合角点的方式来检测场景文本,该方法可以处理任意方向的文本;2)由于检测角点而不是文本边界框,该方法可以自然而然地避免长宽比大幅变化的问题;3)通过位置敏感的分割,该方法可以很好地分割文本实例,而不管其是字符、单词或者文本行;4)在该方法中,候选框的边界由角点决定。相较于基于 anchor 或者文本区域回归文本边界框,该方法生成的边界框更精确,特别是对于长文本。
这一方法的有效性在水平文本、多方向文本、多方向长文本以及多语种文本的公开数据集上得到验证,结果证明了它在精度和速度上的优势。尤其是,该方法的 F-Measures 在 ICDAR2015、MSRA-TD500 和 MLT 上分别是 84.3%、81.5% 和 72.4%,显著优于先前最佳方法。另外,该方法在效率方面同样具有竞争优势,在输入图片大小为 512x512 情况下,每秒可处理超过 10.4 张图像。
网络架构
本文方法是一个全卷积网络,可实现特征提取、角点检测和位置敏感的文本区域分割,其网络架构如图 3 所示。给定一张图像,则网络给出候选角点和分割图。

图 3:该网络包含 3 部分:Backbone、角点检测器和位置敏感分割检测器。Backbone 沿用DSSD。角点检测器构建在多个特征层(粉色模块)之上。位置敏感分割检测器与角点检测器共享粉色模块。
特征提取
该模型的 backbone 改编自预训练的 VGG16 网络,并基于下述考量进行设计:1)场景文本的大小变化巨大,因此 backbone 必须足以应对该问题;2)自然场景中的背景非常复杂,因此特征最好包含较多的语境。鉴于 FPN/DSSD 结构在上述问题上的良好表现,本文通过 FPN/DSSD backbone 提取特征。
角点检测
本文使用一个正方形框来表示一个角点,并用 default box 来回归角点。其中,框的中心点为角点位置,框的边长为角点所属的文本框的最短边。与 SSD/DSSD 每个 default box 输出一种相应候选框的分类分值和偏移量(offset)不同,角点检测更为复杂。因为同一位置可以存在多个的角点,因此本文中 default box 对应的输出分别为 4 类角点的 4 个候选框的分类分值和偏移量。
本文以卷积的方式通过预测模块预测两个分支的分值和偏移量。对于每个单元中带有 k 个 default box 的 m × n 特征图,“分值”分支和“偏移量”分支分别为每个 default box 的每个类型的角点输出 2 个分值和 4 个偏移量。这里,在“分值”分支中 2 表示该位置是否有角点存在。总体上,“分数”分支和“偏移量”分支的输出通道是 k×q×2 和 k×q×4,其中 q 表示角点类型。 q 默认等于 4。
训练阶段则遵从 SSD 中 default box 和 groundtruth 的匹配策略。为检测不同大小的场景文本,本文在多个层特征上使用不同大小的 default box。
位置敏感分割
先前基于分割的文本检测方法通过生成分割图表征每个像素属于文本区域的概率。但是由于文本区域的重叠和文本像素的不当预测,分值图中的文本区域经常无法彼此分离。为从分割图中获得文本边界框,需要进行复杂的后处理。
受到 InstanceFCN 启发,本文使用位置敏感分割生成文本分割图。相较于先前的文本分割方法,相对位置信息被引入。具体而言,通过一个 g x g 规则网格把文本边界框 R 分成多个 bin。对于每个 bin 来说,可使用一个分割图决定该图的像素是否属于该 bin。如图 4 所示,借助位置敏感的分割图, 本文可以有效地处理相近或相互重叠的文本区域。
本文在统一网络中构建位置敏感分割,利用特征 F3 , F4 , F7 , F8 , F9 等预测 g x g 张文本区域分割 map。默认 g 为 2。

图 4:位置敏感的区域分割能提供实例信息,有效地过滤掉虚警。(a)输入图像;(b)已预测文本 proposal 和分割图。(c)评分。红框分别是对应于单词(有效)、相近单词和相互覆盖的单词(无效)的文本 proposal。文本框 proposal 的评分由旋转的位置敏感 ROI 平均池化层(算法1)计算。
训练与推理
对于输入训练样本,本文首先把 groundtruth 中的每个文本框(任意四边形)转化为一个能覆盖这个文本框且面积最小的矩形,并确定 4 个角点的相对位置。转化后的矩形相对位置应遵循以下原则:1)左上、左下角点的 x 轴必须分别小于右上、右下角点的 x 轴;2)左上、右上角点的 y 轴必须分别小于左下、右下角点的 y 轴。基于角点的相对位置,本文可以生成角点和位置敏感的分割的 groundtruth,如图 5。

图 5:为角点检测和位置敏感分割生成标签。 (a) 重新定义角点并用正方形表示(白色,红色,绿色,蓝色框),边长设置为文本边界框 R(黄框)的短边。 (b) (a) 中对应于位置敏感分割的 R 的 groundtruth。
在推理阶段,会产生很多包含预测位置、短边长度和置信度信息的角点。高分值角点(默认值大于0.5)被保留。NMS 之后,根据相对位置信息组成 4 个角点集。采样和分组角点之后会产生大量的候选边界框。本文使用位置敏感的区域分割对候选文本框打分。处理过程如图 6 所示。

图 6:评分过程概览。 (a) 中的黄框是候选框。(b) 是已预测分割图。本文通过集合分割图生成候选框的实例分段(c)。分值通过平均实例分段区域来计算。
为处理旋转的文本边界框,本文提出旋转的位置敏感 ROI 平均池化层。具体地,对于一个旋转的边界框,本文首先把框分成 g x g 个 bin,对于每一个 bin,计算其对应预图 bin区域内所有像素的均值,最后对所有 bin 的均值求平均。具体过程如算法 1 所示。

算法 1:旋转的位置敏感 ROI 平均池化层。
低评分的候选框将被过滤掉。本文默认阈值为 0.6。
实验结果
为验证本文方法的有效性,作者在 5 个数据集上开展实验:ICDAR2015,ICDAR2013,MSRA-TD500,MLT,COCO-Text,分别检测了多方向文本,水平文本,多方向长文本,多语种文本以及泛化能力。
多方向文本
本文在 ICDAR2015 数据上测试了该模型在任意方向文本检测上的性能,并与其他当前最优方法进行对比,所有结果如表 2 所示。该方法大幅超越先前方法。当在单尺度上测试时,该方法的 F-measure 为 80.7%,优于其他所有方法;当在多尺度上测试时,该方法的 F-measure 为 84.3%,优于当前最佳方法 3.3%。
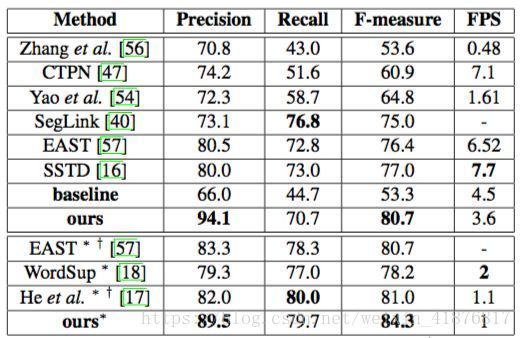
表 2:ICDAR2015 结果。∗ 表示多尺度,† 表示模型的基础网络不是 VGG16。
水平文本
本文在 ICDAR2013 数据上测试了该模型在水平文本检测上的性能,结果如表 3 所示。当在单尺度上测试时,该方法的 F-measure 为 85.8%,略低于最高值。另外,该方法每秒可处理 10.4 张图像,快于绝大多数方法。当在多尺度上测试时,该方法的 F-measure 为 88.0%,同样很有竞争优势。
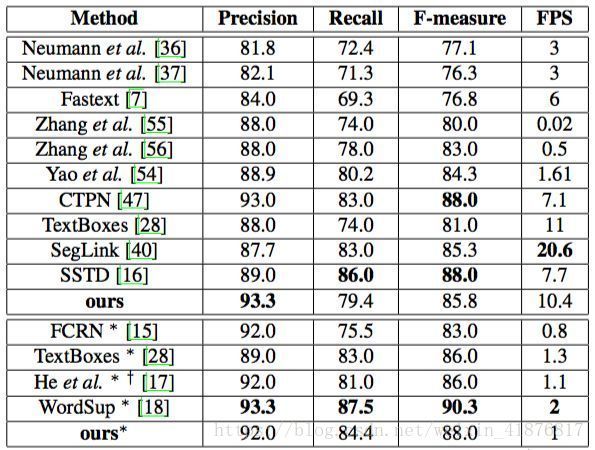
表 3:ICDAR2013 结果。∗ 表示多尺度,† 表示模型的基础网络不是 VGG16。注意,前三行的方法是在 “ICDAR2013” 评估协议下进行的。
多方向长文本
本文在 MSRA-TD500 数据上测试了该模型在多方向长文本检测上的性能,结果如表 4 所示,其性能大幅优于先前所有方法。该方法在召回率、精确度和 F-measure 上同时取得当前最佳性能(87.6%,76.2% 和 81.5% ),并显著优于先前最佳结果(81.5% vs. 77.0% )。这说明该方法较于其他方法更擅长检测任意方向的长文本。
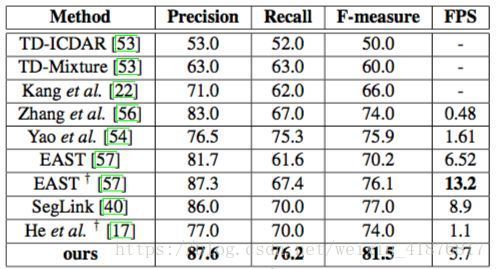
表 4:MSRA-TD500 结果。† 表示模型的基础网络不是 VGG16。
多语种文本
本文在 MLT 数据上测试了该模型在多语种文本检测上的性能。如表 5 所示,该方法超越其他方法至少 3.1%。
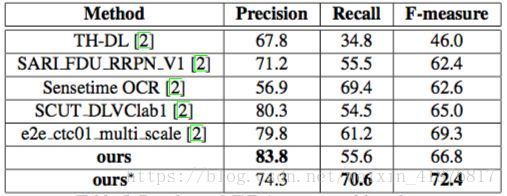
表 5:MLT 结果。∗ 表示多尺度。
泛化能力
为评估该模型的泛化能力,本文使用在 ICDAR2015 数据集上训练得到的模型在 COCO-Text 数据集上进行测试,结果如表 6 所示。无需训练,该方法在COCO-Text 数据集上的 F-measure 为 42.5%,优于其他方法。

表 6:COCO-Text 结果。∗ 表示多尺度。
结论
本文提出一种场景文本检测器,它可以通过角点检测和位置敏感分割定位文本。作者在若干个专门的多方向文本,水平文本,多方向长文本,多语种文本公共基准上评估了该检测器,其优越的性能证实了该方法的有效性和鲁棒性。
该方法的贡献有如下 4 个方面:1)提出一种结合物体检测和分割思想的新型场景文本检测器,可以实现端到端的训练与评估;2)基于位置敏感的 ROI 池化,提出一种位置敏感的旋转 ROI 平均池化层,可以处理任意方向的 proposals;3)该方法可同时应对多种困扰先前多方向文本检测方法的难点,比如旋转、长宽比变化、非常接近的文本实例等;4)该方法在精度和效率方面同样取得了更优或更具竞争力的结果。未来,作者将会基于该方法构建一个端到端的 OCR 系统。
参考文献
[1] Zhou et al. EAST: An Efficient and Accurate Scene Text Detector. CVPR2017
[2] Fu et al .DSSD : Deconvolutional single shot detector. Arxiv
[3] Tychsen-Smith et al. Denet: Scalable realtime object detection with directed sparse sampling. ICCV2017
[4] Wang et al. Point linking network for object detection. Arxiv
[5] Dai et al. Instance-sensitive fully convolutional networks. ECCV2016
[6] Li et al. Fully convolutional instance-aware semantic segmentation. CVPR2017