SQLite | Join 语句
文章目录
- 1. Join
- 1.1 表联合
- 1.2 内联合
- 1.3 左联合
- 1.4 其他联合类型
- 1.5 多表联合
- 1.6 分组联合
- 参考资料
1. Join
我们在上一篇中介绍了 Case 子句
,接下来我们将使用 join ,对表格进行合并。
-
使用Jupyter Notebook 运行 SQL 语句需安装 ipython-sql
-
%sql 以及 %%sql 为在 Notebook 中运行 SQL 语句,在 SQLite 命令行或 SQLite Stiduo 中不需要 %sql 或 %%sql
载入 SQL 以及连接 SQLite:
%load_ext sql
%sql sqlite:///DataBase/rexon_metals.db
'Connected: @DataBase/rexon_metals.db'
本文将使用 rexon_metals.db 数据库,其中包含了 CUSTOMER、CUSTOMER_ORDER 和 PRODUCT 三张表。
1.1 表联合
Joining 是 SQL 内置的一个子句,但却和其他的子句不同。当我们讨论一个关系数据库时,
里面通常有着几张表,表与表之间通过某一列数据相联系。举个例子,在这样 CUSTOMER_ORDER
表中,有这 CUSTOMER_ID 这一列:
%%sql
select * from customer_order
limit 0,5;
* sqlite:///DataBase/rexon_metals.db
Done.
| ORDER_ID | ORDER_DATE | SHIP_DATE | CUSTOMER_ID | PRODUCT_ID | ORDER_QTY | SHIPPED |
|---|---|---|---|---|---|---|
| 1 | 2015-05-15 | 2015-05-18 | 1 | 1 | 450 | false |
| 2 | 2015-05-18 | 2015-05-21 | 3 | 2 | 600 | false |
| 3 | 2015-05-20 | 2015-05-23 | 3 | 5 | 300 | false |
| 4 | 2015-05-18 | 2015-05-22 | 5 | 4 | 375 | false |
| 5 | 2015-05-17 | 2015-05-20 | 3 | 2 | 500 | false |
这一列是我们和 CUSTOMER 表联系起来的键(key),因此你也能猜出,在
CUSTOMER 表中,也有 CUSTOMER_ID 这一列数据:
%%sql
select * from customer
limit 0,5;
* sqlite:///DataBase/rexon_metals.db
Done.
| CUSTOMER_ID | NAME | REGION | STREET_ADDRESS | CITY | STATE | ZIP |
|---|---|---|---|---|---|---|
| 1 | LITE Industrial | Southwest | 729 Ravine Way | Irving | TX | 75014 |
| 2 | Rex Tooling Inc | Southwest | 6129 Collie Blvd | Dallas | TX | 75201 |
| 3 | Re-Barre Construction | Southwest | 9043 Windy Dr | Irving | TX | 75032 |
| 4 | Prairie Construction | Southwest | 264 Long Rd | Moore | OK | 62104 |
| 5 | Marsh Lane Metal Works | Southeast | 9143 Marsh Ln | Avondale | LA | 79782 |
我们可以按顺序从这一个表中读取客户的信息,这与 Excel 中的 VLOOKUP 非常相似。
下面是 CUSTOMER_ORDER 表与 CUSTOMER 表之间关系的示意图,我们可以说 CUSTOMER 表是 CUSTOMER_ORDER 表的父表,因为 CUSTOMER_ORDER 表依赖于 CUSOMER 表中的信息,因此它是一个子表。相反的,CUSTOMER 不可能是 CUSTOMER_ORDER 的子表,因为它没有什么信息是依赖于
CUSTOMER_ORDER 表的。
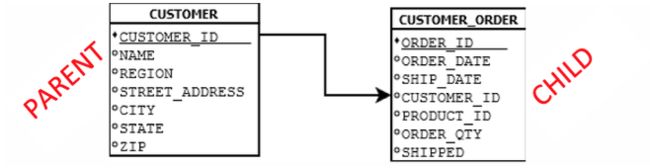
箭头显示了 CUSTOMER 表同过 CUSTOMER_ID 这一列数据与 CUSTOMER_ORDER 表联系。
我们也可以从另一个方面来考虑两个表之间的关系,那就是对于两个表相同的列,子表中的数据通常是重复的,而父表中的数据通常是唯一的。还是以这两张表为例,在下面这张图中你可以看到
一对多的关系:一位 CUSTOMER_ID 为 3 的 Re-Barre Construction 的客户对应着三张订单。
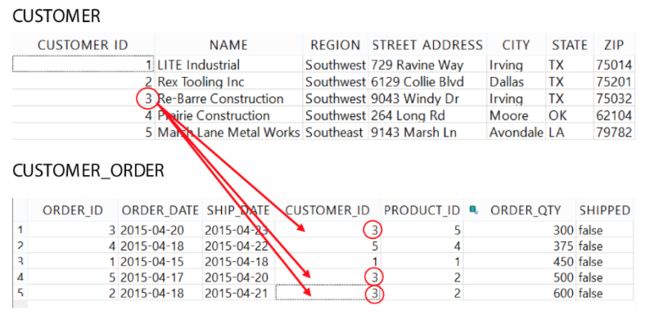
一对多是最常见的数据关系,因为这符合大多数商业需要,如一个客户对应着多张订单。最不常见的关系就是一对一和多对多的关系。
1.2 内联合
理解了表的关系,我们来考虑下将两张表联合到一起,这样我们可以在同一张表内即看到 CUSTOMER 的数据,又看到 CUSTOMER_ORDER 的数据。
INNER JOIN 让你能够将两张表联合到一起,但如果我们要联合表,就需要定义一个或多个两张表都有的列作为键。如果我们要查询 CUSTOMER_ORDER 并用 CUSTOMER 表来补充客户的信息,我们可以将共同的 CUSTOMER_ID 作为键:
%%sql
SELECT
order_id, -- CUSTOMER_ORDER
customer.customer_id, -- CUSTOMER
order_date, -- CUSTOMER_ORDER
ship_date, -- CUSTOMER_ORDER
name, -- CUSTOMER
street_address, -- CUSTOMER
city, -- CUSTOMER
state, -- CUSTOMER
zip, -- CUSTOMER
product_id, -- CUSTOMER_ORDER
order_qty -- CUSTOMER_ORDER
FROM customer INNER JOIN customer_order
ON customer.customer_id = customer_order.customer_id
LIMIT 0,5
* sqlite:///DataBase/rexon_metals.db
Done.
| ORDER_ID | CUSTOMER_ID | ORDER_DATE | SHIP_DATE | NAME | STREET_ADDRESS | CITY | STATE | ZIP | PRODUCT_ID | ORDER_QTY |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 2015-05-15 | 2015-05-18 | LITE Industrial | 729 Ravine Way | Irving | TX | 75014 | 1 | 450 |
| 2 | 3 | 2015-05-18 | 2015-05-21 | Re-Barre Construction | 9043 Windy Dr | Irving | TX | 75032 | 2 | 600 |
| 3 | 3 | 2015-05-20 | 2015-05-23 | Re-Barre Construction | 9043 Windy Dr | Irving | TX | 75032 | 5 | 300 |
| 4 | 5 | 2015-05-18 | 2015-05-22 | Marsh Lane Metal Works | 9143 Marsh Ln | Avondale | LA | 79782 | 4 | 375 |
| 5 | 3 | 2015-05-17 | 2015-05-20 | Re-Barre Construction | 9043 Windy Dr | Irving | TX | 75032 | 2 | 500 |
你可能注意到了我们可以同时从 CUSTOMER 和 CUSTOMER_ORDER 两张表中提取列,并将它们合并。
让我们看看刚才的查询是怎么完成的,首先我们从两张表中提取出我们想要的数据:
SELECT
order_id, -- CUSTOMER_ORDER
customer.customer_id, -- CUSTOMER
order_date, -- CUSTOMER_ORDER
ship_date, -- CUSTOMER_ORDER
name, -- CUSTOMER
street_address, -- CUSTOMER
city, -- CUSTOMER
state, -- CUSTOMER
zip, -- CUSTOMER
product_id, -- CUSTOMER_ORDER
order_qty -- CUSTOMER_ORDER
这样我们可以在每一个订单中看见客户的地址信息。同时也要注意到:由于两张表都具有 ORDER_ID ,所以需要指定使用某一章表的数据。在这个例子中,我们选择了 COSTOMER 表中的 CUSTOMER_ID 数据:
customer.customer_id
最后我们用 select … inner join … 语句临时将两张表合并为一张表。指定了从 CUSTOMER 表中提取数据并加入到 CUSTOMER_ORDER 表中,而它们共同的列就是 CUSTOMER_ID:
FROM customer INNER JOIN customer_order
ON customer.customer_id = customer_order.customer_id
正因为我们是将根据 CUSTOMER_ORDER 上的 CUSTOMER_ID 添加 CUSTOMER 的信息,因此并不是CUSTOMER 上所有的信息都会出现在 CUSTOMER_ORDER 上,以下图为例,当我们合并两张表时,合并的结果中只出现了三个顾客的名字,而由于 CUSTOMER_ORDER 中并没有 Rex Tooling Inc 和 Prairie Construction,因此合并表中也就不会出现这两家公司了。

1.3 左联合
考虑下我们刚才说到的问题,在内联合中,Rex Tooling Inc 和 Prairie Construction 两家公司由于没有订单而没有呈现在最后的合并结果中。但如果我就是想要在合并结果中保留它们呢(尽管没有数据)?
如果你对我们刚才所介绍 inner join 能接受的话,那么 left 或 out join 也就依葫芦画瓢了。你可以将前面代码中的 inner 换成 left ,你会发现左表(CUSTOMER)中所有信息都被保留下来了:
%%sql
SELECT
order_id, -- CUSTOMER_ORDER
customer.customer_id, -- CUSTOMER
order_date, -- CUSTOMER_ORDER
ship_date, -- CUSTOMER_ORDER
name, -- CUSTOMER
street_address, -- CUSTOMER
city, -- CUSTOMER
state, -- CUSTOMER
zip, -- CUSTOMER
product_id, -- CUSTOMER_ORDER
order_qty -- CUSTOMER_ORDER
FROM customer LEFT JOIN customer_order
ON customer.customer_id = customer_order.customer_id
LIMIT 0,5
* sqlite:///DataBase/rexon_metals.db
Done.
| ORDER_ID | CUSTOMER_ID | ORDER_DATE | SHIP_DATE | NAME | STREET_ADDRESS | CITY | STATE | ZIP | PRODUCT_ID | ORDER_QTY |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 2015-05-15 | 2015-05-18 | LITE Industrial | 729 Ravine Way | Irving | TX | 75014 | 1 | 450 |
| None | 2 | None | None | Rex Tooling Inc | 6129 Collie Blvd | Dallas | TX | 75201 | None | None |
| 5 | 3 | 2015-05-17 | 2015-05-20 | Re-Barre Construction | 9043 Windy Dr | Irving | TX | 75032 | 2 | 500 |
| 2 | 3 | 2015-05-18 | 2015-05-21 | Re-Barre Construction | 9043 Windy Dr | Irving | TX | 75032 | 2 | 600 |
| 3 | 3 | 2015-05-20 | 2015-05-23 | Re-Barre Construction | 9043 Windy Dr | Irving | TX | 75032 | 5 | 300 |
可以看到虽然 Rex Tooling Inc 并没有订单数据,但会以缺失值的显示出现在结果中,如下图过程所示:
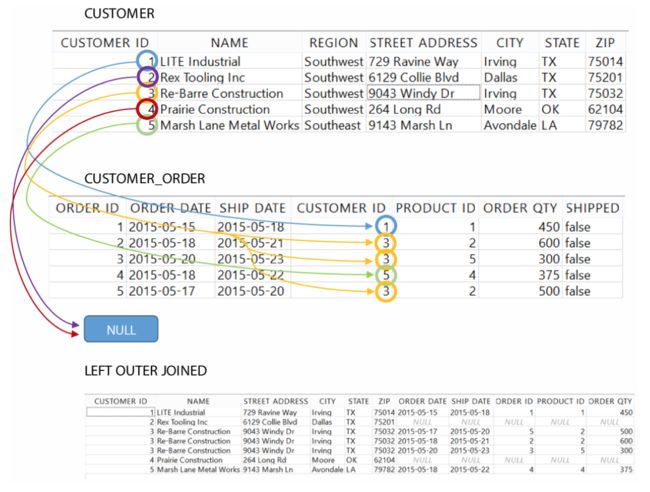
left join 也经常被用于检查是否有 “孤儿(orphaned)”数据,即子数据无父数据,或相反的父数据无子数据。如用于查找是否有客户没有订单的或订单丢失客户的:
%%sql
SELECT
customer.customer_id,
name AS customer_name
FROM customer LEFT JOIN customer_order
ON customer.customer_id == customer_order.customer_id
WHERE order_id IS null
* sqlite:///DataBase/rexon_metals.db
Done.
| CUSTOMER_ID | customer_name |
|---|---|
| 2 | Rex Tooling Inc |
| 4 | Prairie Construction |
1.4 其他联合类型
我们已经介绍了内联合于左联合,SQL 中还包含了其他联合方法,如 right join、out join 等方法。
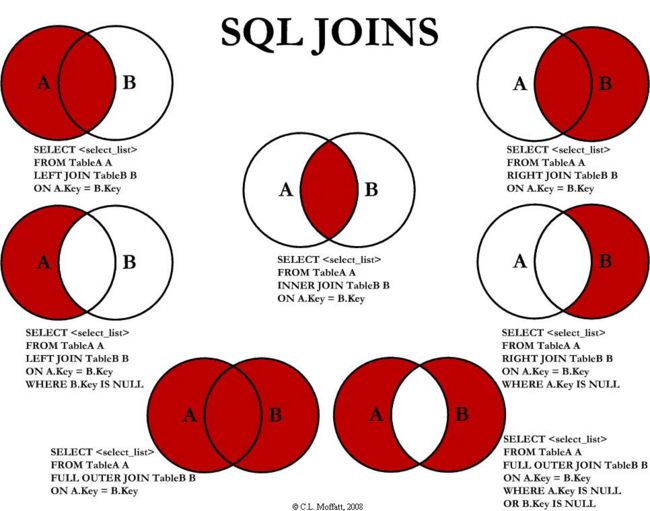
right join 与 left join 几乎相同,不过是换了个方向:将右表的所有数据都包含了进来。然而 right join 很少使用,而且你也得避免使用它。要习惯于将保留所有数据的表作为左表!
SQLite 并不支持 right join 和 outer join,但大多数的数据库都支持
1.5 多表联合
由于表与表之间存在着关系,因此关系数据库可以变得异常的复杂。一张子表可能存在着多张父表,同时是其他表的子表(贵圈也挺乱的hhhh),所以它们之间是如何协作的呢?
%%sql
select * from product
limit 0,5
* sqlite:///DataBase/rexon_metals.db
Done.
| PRODUCT_ID | DESCRIPTION | PRICE |
|---|---|---|
| 1 | Copper | 7.51 |
| 2 | Aluminum | 2.58 |
| 3 | Silver | 15 |
| 4 | Steel | 12.31 |
| 5 | Bronze | 4 |
我们已经探索了 CUSTOMER 和 CUSTOMER_ID 两张表了,但在这个数据库中还有一张 PRODUCT 表我们没用到。在 CUSTOMER_ORDER 和 PRODUCT 两张表中都存在着 PRODUCT_ID 这一列数据,因此我们不仅可以为 CUSTOMER_ORDER 表添加顾客信息,还能添加产品信息。

我们可以利用这两个关系将顾客信息和产品信息同时添加到订单中:
%%sql
SELECT
order_id, -- CUSTOMER_ORDER
customer.customer_id, -- CUSTOMER
name AS customer_name, -- CUSTOMER
street_address, -- CUSTOMER
city, -- CUSTOMER
state, -- CUSTOMER
zip, -- CUSTOMER
order_date, -- CUSTOMER_ORDER
product.product_id, -- PRODUCT
description, -- PRODUCT
order_qty, -- CUSTOMER_ORDER
order_qty * price as revenue -- CUSTOMER_ORDER, PRODUCT
FROM customer LEFT JOIN customer_order
ON customer.customer_id = customer_order.customer_id
LEFT JOIN product
ON customer_order.product_id = product.product_id
LIMIT 0,5
* sqlite:///DataBase/rexon_metals.db
Done.
| ORDER_ID | CUSTOMER_ID | customer_name | STREET_ADDRESS | CITY | STATE | ZIP | ORDER_DATE | PRODUCT_ID | DESCRIPTION | ORDER_QTY | revenue |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | LITE Industrial | 729 Ravine Way | Irving | TX | 75014 | 2015-05-15 | 1 | Copper | 450 | 3379.5 |
| None | 2 | Rex Tooling Inc | 6129 Collie Blvd | Dallas | TX | 75201 | None | None | None | None | None |
| 5 | 3 | Re-Barre Construction | 9043 Windy Dr | Irving | TX | 75032 | 2015-05-17 | 2 | Aluminum | 500 | 1290.0 |
| 2 | 3 | Re-Barre Construction | 9043 Windy Dr | Irving | TX | 75032 | 2015-05-18 | 2 | Aluminum | 600 | 1548.0 |
| 3 | 3 | Re-Barre Construction | 9043 Windy Dr | Irving | TX | 75032 | 2015-05-20 | 5 | Bronze | 300 | 1200 |
1.6 分组联合
还是以上面的查询为例,加入我们想要计算每一个顾客的总收入,我们可以在之前查询的基础上使用 group by 子句。为了简便,我们省去了其他的列:
%%sql
select
customer.customer_id,
name as customer_name,
sum(order_qty * price) as total_revenue
from customer inner join customer_order
on customer.customer_id = customer_order.customer_id
inner join product
on customer_order.product_id = product.product_id
group by 1,2
* sqlite:///DataBase/rexon_metals.db
Done.
| CUSTOMER_ID | customer_name | total_revenue |
|---|---|---|
| 1 | LITE Industrial | 3379.5 |
| 3 | Re-Barre Construction | 4038.0 |
| 5 | Marsh Lane Metal Works | 4616.25 |
注意到上面的结果中并没有 Rex Tooling 和 Prairie Construction 两家公司的数据,这是因为它们并没有订单。如果你想要保留着部分缺失值,可以使用 left join:
%%sql
select
customer.customer_id,
name as customer_name,
sum(order_qty * price) as total_revenue
from customer left join customer_order
on customer.customer_id = customer_order.customer_id
left join product
on customer_order.product_id = product.product_id
group by 1,2
* sqlite:///DataBase/rexon_metals.db
Done.
| CUSTOMER_ID | customer_name | total_revenue |
|---|---|---|
| 1 | LITE Industrial | 3379.5 |
| 2 | Rex Tooling Inc | None |
| 3 | Re-Barre Construction | 4038.0 |
| 4 | Prairie Construction | None |
| 5 | Marsh Lane Metal Works | 4616.25 |
我们对两次联合都使用了 LEFT JOIN 而不是 LEFT JOIN 与 INNER JOIN 混合使用,这是因为 INNER JOIN 会过滤缺失值,而 LEFT JOIN 可以保留缺失值。当我们先使用 LEFT JOIN 并产生缺失值时,如果我们再使用 INNER JOIN,会导致部分缺失值丢失
我们在之前的文章中提过,sum 函数会对非缺失值的数据进行加总,因此如果你想要在查询结果中保留该公司的总收入为 0 的话,可以使用 coalesce 函数将缺失值替换为 0:
%%sql
select
customer.customer_id,
name as customer_name,
coalesce(sum(order_qty * price), 0) as total_revenue
from customer left join customer_order
on customer.customer_id = customer_order.customer_id
left join product
on customer_order.product_id = product.product_id
group by 1,2
* sqlite:///DataBase/rexon_metals.db
Done.
| CUSTOMER_ID | customer_name | total_revenue |
|---|---|---|
| 1 | LITE Industrial | 3379.5 |
| 2 | Rex Tooling Inc | 0 |
| 3 | Re-Barre Construction | 4038.0 |
| 4 | Prairie Construction | 0 |
| 5 | Marsh Lane Metal Works | 4616.25 |
参考资料
[1] Thomas Nield.Getting Started with SQL[M].US: O’Reilly, 2016: 53-66
相关文章:
SQL | 目录
SQLite | SQLite 与 Pandas 比较篇之一
SQLite | Select 语句
SQLite | Where 子句
SQLite | Group by 与 Order by 子句
SQLite | CASE 子句
SQLite | 数据库设计与 Creat Table 语句
SQLite | Insert、Delete、Updata 与 Drop 语句