centos7.3中搭建hadoop分布式集群环境详细过程
一、准备工作
1、准备3台物理机或者虚拟机;
2、安装centos7系统;
3、准备好相关软件包并拷贝相关软件到目标服务器上
hadoop-2.9.0.tar.gz
jdk-8u131-linux-x64.tar.gz
二、配置网络
1、设置静态网络ip
1)设置静态ip的文件路径在:cd /etc/sysconfig/network-scripts/目录中

2)打开对应的网络配置文件 vim ifcfg-p3p1

3)编辑保存后,重启网络服务 systemctl restart network
4)查看当前网络地址 ifconfig
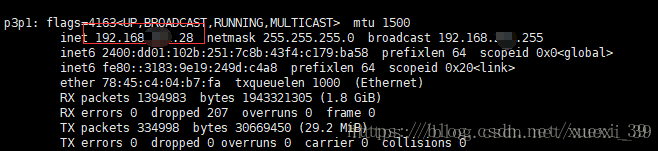
2、设置主机名称及进行IP映射
1)修改主机名称;vim /etc/hostname

2) 打开hosts文件,进行主机名与ip映射 ,在文件底部添加集群环境中关联的ip地址及对应机器名称
vim /etc/hosts

3)重复以上步骤,分别修改第二台及第三台服务器的机器名称及进行ip映射
4)通过ping+主机名,检测是否可以设置及映射成功

3、设置DNS服务(设置DNS服务可以访问外网)
1)进入cd /etc/sysconfig/network-scripts目录中
2)打开网络配置文件,在文件中添加网关ip地址
![]()
3)编辑保存退出后,重启网络服务 service network restart
![]()
4)使用ping www.baidu.com,检测是否可以访问外网地址
![]()
5)重复以上步骤,配置其它两台机器
6)3台机器之间,利用主机名称可以进行互ping,检测网络是否正常

三、创建hadoop用户
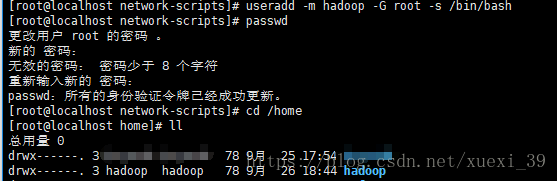
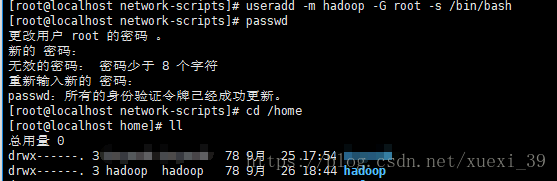
1、创建用户并设置密码
useradd -m hadoop -G root -s /bin/bash
passwd hadoop
2、授予管理员权限
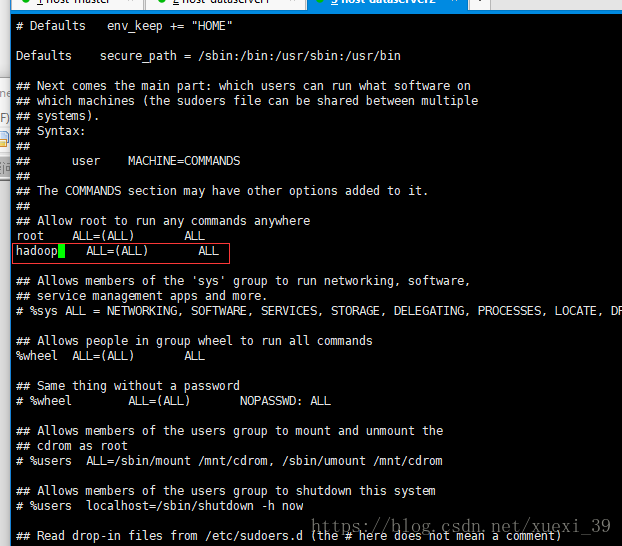
输入visudo命令,在打开的文件中找到 root ALL=(ALL) ALL 这一行
在底部补充添加一行 hadoop ALL=(ALL) ALL 保存退出
四、配置SSH无密码登录
1、查看是否安装SSH,检测命令rpm -qa | grep ssh

如上所示,显示ssh client和ssh server已安装,不需安装,若没有安装可以使用命令:
sudo yum install openssh-clients
sudo yum install openssh-server
2、配置SSH无密码登录
1)在主机master中生成密钥(切换到hadoop用户的主题目录下的.ssh文件,如果没有.ssh文件请先执行一次ssh localhost)
2) ssh-keygen -t rsa # 会有提示,都按回车就可以
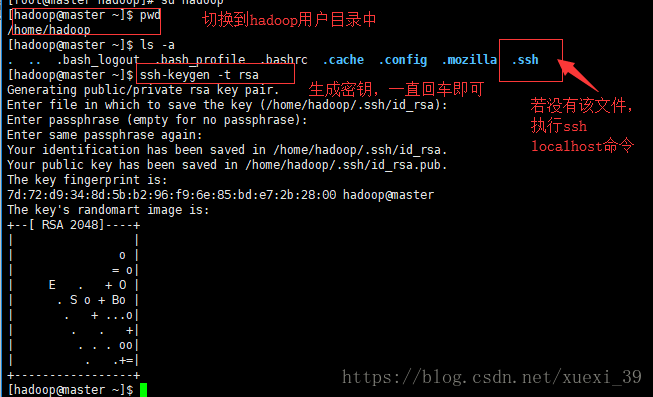
如下所示生成.ssh文件
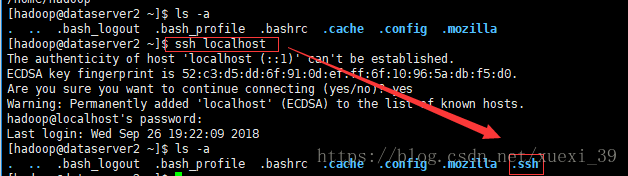
3)进入.ssh目录中,查看是否生成成功

4)重复以上步骤,将其它机器dataserver1及dataserver2生成自己相对应的密钥文件
5)将其它分支机器(dataserver*)中生成的公钥文件复制一份,并重命名

6)将复制的公钥文件远程拷贝到master主机中
scp id_rsa_dataserver2.pub hadoop@master:~/.ssh/
scp id_rsa_dataserver1.pub hadoop@master:~/.ssh/
将集群内所有的公钥文件集中到主节点master中
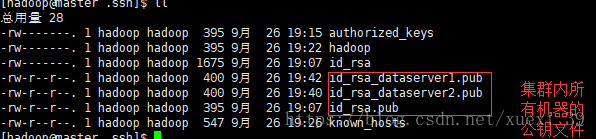
8)将master中生成的密钥加入授权(authorized_keys)
cat id_rsa.pub # 查看生成的公钥
cat id_rsa.pub >> authorized_keys # 加入授权
9) 将分节点生成的公钥文件也加入授权
cat id_rsa_dataserver1.pub >> authorized_keys
cat id_rsa_dataserver2.pub >> authorized_keys
10)将集群中所有机器的公钥信息到加入授权文件中,查看

11)修改文件权限
chmod 600 authorized_keys # 修改文件权限,如果不修改文件权限,那么其它用户就能查看该授权文件,然后使用该密钥也能进行登录,不安全
12)将master中的authorized_keys文件远程拷贝到其它主机中
scp authorized_keys hadoop@dataserver1:~/.ssh/

13)在目标机器对应的目录中查看拷贝成功的文件

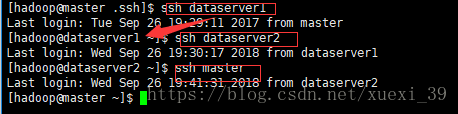
14)测试验证,是否可以利用ssh免密登录
五、安装JDK
可参考该地址下的jdk安装过程进行安装:
https://mp.csdn.net/postedit/82854735
六、正式安装hadoop
1、安装hadoop
1)将Hadoop压缩包解压到目标安装目录下
tar -zxvf hadoop-2.9.0.tar.gz -C /usr/local/
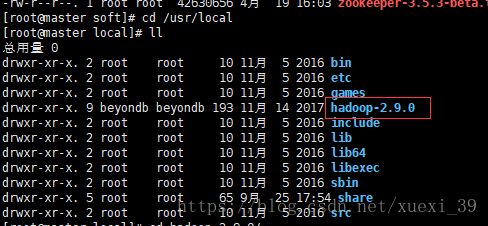
2)修改文件名hadoop-2.9.0为hadoop
sudo mv ./hadoop-2.9.0/ ./hadoop
3) 更改hadoop目录所属者及所属组为hadoop用户
chown -hR hadoop /usr/local/hadoop/ # 修改所有者为hadoop
chgrp -hR hadoop /usr/local/hadoop/ # 修改所属组为hadoop
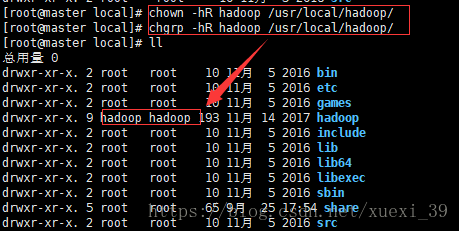
4)检测hadoop是否可用,查看hadoop版本信息
进入hadoop安装目录中,输入:./bin/hadoop version,显示如下信息,说明安装成功

5)重复以上步骤,其它分支机器也安装hadoop
2、配置环境变量
1)打开bashrc文件
vim ~/.bashrc
添加下列信息:
# Hadoop Environment Variables
export HADOOP_HOME=/usr/local/hadoop # hadoop的安装目录,替换为你的hadoop的安装目录
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
2)重新加载bashrc文件,使得配置信息生效
source ~/.bashrc3)检测环境变量是否生效
echo $PATH
hadoop version
4)集群中的其它分支重复上面步骤,配置环境变量
3、关闭防火墙及selinux进程
1)查看
systemctl status firewalld # 查看防火墙状态
systemctl stop firewalld # 关闭防火墙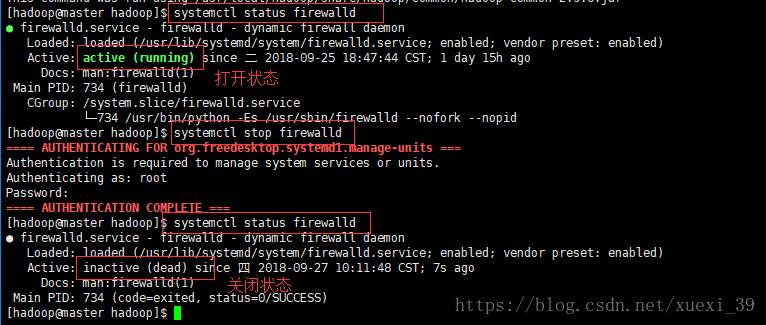
2)关闭selinux守护线程(使用root用户)
getenforce # 查看selinux守护线程的状态
setenforce 0 # 关闭selinux守护线程
exit # 回到原来的终端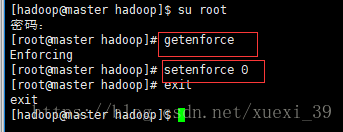
3)集群中的其它分支重复上面步骤,关闭防火墙及进程
七、hadoop分布式集群配置
1、修改hadoop的配置文件
集群/分布式模式需要修改 /usr/local/hadoop/etc/hadoop 中的5个配置文件,分别为:
core-site.xml:Hadoop的核心配置文件
hdfs-site.xml :用于配置NameNode的URI及NameNode和DataNode的存放位置
mapred-site.xml:mapreduce相关配置
yarn-site.xml: 配置资源管理系统yarn
slaves:配置DataNode的主机名
可查看官方文档:hadoop集群搭建官方文档
1)修改core-site.xml文件
在configuration节点中添加如下内容
hadoop.tmp.dir
file:/usr/local/hadoop/tmp
fs.defaultFS
hdfs://Master:9000
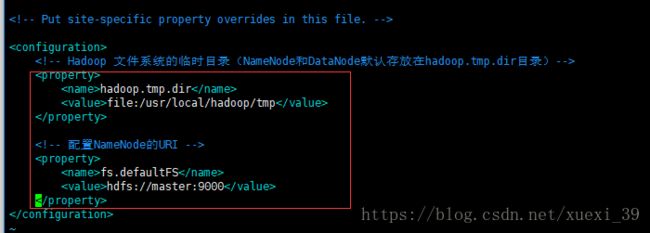
2)修改hdfs-site.xml文件(在configuration节点中添加如下内容)
dfs.namenode.secondary.http-address
Master:50090
dfs.replication
1
dfs.namenode.name.dir
file:/usr/local/hadoop/tmp/dfs/name
dfs.datanode.data.dir
file:/usr/local/hadoop/tmp/dfs/data
3)修改mapred-site.xml 文件(在configuration节点中添加如下内容)
在添加下面信息之前,因 /usr/local/hadoop/etc/hadoop目录中没有mapred-site.xml文件,可复制mapred-site.xml. template文件重命名为mapred-site.xml,进行修改
mapreduce.framework.name
yarn
执行框架设置为Hadoop YARN
mapreduce.jobhistory.address
master:10020
Master可替换为IP
mapreduce.jobhistory.webapp.address
master:19888
Master可替换为IP
mapreduce.jobhistory.done-dir
${yarn.app.mapreduce.am.staging-dir}/history/done
mapreduce.jobhistory.intermediate-done-dir
${yarn.app.mapreduce.am.staging-dir}/history/done_intermediate
yarn.app.mapreduce.am.staging-dir
/tmp/hadoop-yarn/staging
mapred.job.tracker
master:49001
4)修改yarn-site.xml文件在configuration节点中添加如下内容)
yarn.resourcemanager.hostname
master
master可替换为IP
The address of the applications manager interface in the RM.
yarn.resourcemanager.address
${yarn.resourcemanager.hostname}:8032
The address of the scheduler interface.
yarn.resourcemanager.scheduler.address
${yarn.resourcemanager.hostname}:8030
The http address of the RM web application.
yarn.resourcemanager.webapp.address
${yarn.resourcemanager.hostname}:8088
The https adddress of the RM web application.
yarn.resourcemanager.webapp.https.address
${yarn.resourcemanager.hostname}:8090
yarn.resourcemanager.resource-tracker.address
${yarn.resourcemanager.hostname}:8031
The address of the RM admin interface.
yarn.resourcemanager.admin.address
${yarn.resourcemanager.hostname}:8033
yarn.scheduler.maximum-allocation-mb
2048
每个节点可用内存,单位MB,默认8182MB
yarn.nodemanager.vmem-pmem-ratio
2.1
yarn.nodemanager.resource.memory-mb
2048
yarn.nodemanager.vmem-check-enabled
false
yarn.nodemanager.aux-services
mapreduce_shuffle
Shuffle service 需要加以设置的MapReduce的应用程序服务
yarn.log-aggregation-enable
true
5)修改slaves文件(将集群中的分节点机器名称写入)
2、配置hadoop-env.sh
将
export JAVA_HOME=${JAVA_HOME}
修改为:
export JAVA_HOME=/opt/java/jdk1.8.0_1313、将以上的配置拷贝复制到其它的分支节点上
scp core-site.xml hadoop@dataserver1:/usr/local/hadoop/etc/hadoop/
scp hdfs-site.xml hadoop@dataserver1:/usr/local/hadoop/etc/hadoop/
scp mapred-site.xml hadoop@dataserver1:/usr/local/hadoop/etc/hadoop/
scp yarn-site.xml hadoop@dataserver1:/usr/local/hadoop/etc/hadoop/
scp slaves hadoop@dataserver1:/usr/local/hadoop/etc/hadoop/
scp hadoop-env.sh hadoop@dataserver1:/usr/local/hadoop/etc/hadoop/八、启动hadoop
1、格式化namenode
1) 进入bin目录
[hadoop@master bin]$ cd /usr/local/hadoop/bin
2)执行namenode格式化命令:
./hadoop namenode -format
注意:若启动失败,查看之前配置文件过程中,xml文件复制粘贴的编码是否正确(因我直接复制的信息不是utf8格式导致格式化错误)
2、启动hadoop
方式1):
启动hadoop
start-all.sh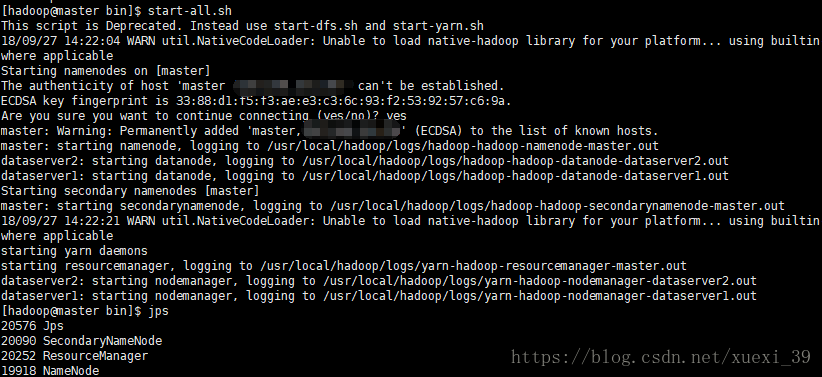
停止hadoop
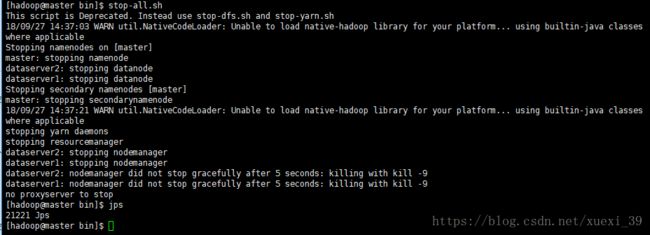
方式二:
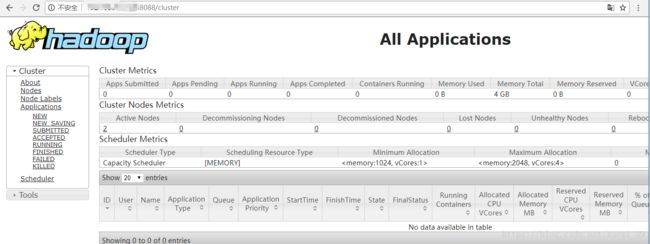
start-dfs.sh #开启 NameNode 和 DataNode 守护进程3、访问web页面
http://masterIP地址:50070
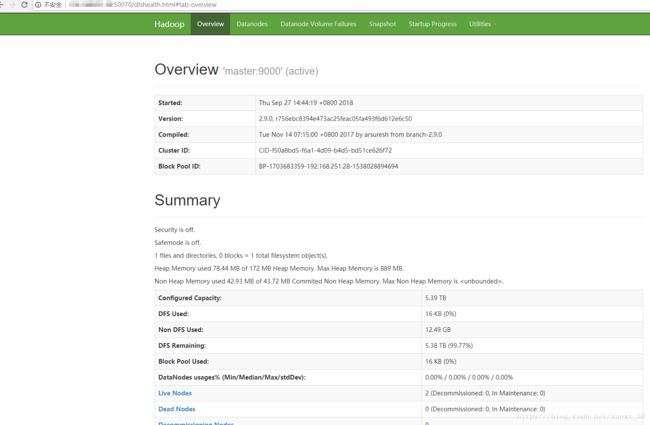
参考部署文件资料
https://blog.csdn.net/hg_harvey/article/details/72819007