常见多语言模型详解 (M-Bert, LASER, MultiFiT, XLM)
文章目录
- 往期文章链接目录
- Ways of tokenization
- Word-based tokenization
- Character-based tokenization
- Subword tokenization
- Existing approaches for cross-lingual NLP
- Out-of-vocabulary (OOV) problem in mono/multi-lingual settings
- M-BERT (Multi-lingual BERT)
- WHY MULTILINGUAL BERT WORKS
- A significant shortcoming of M-BERT
- LASER (Language-Agnostic SEntence Representations)
- Universal, language-agnostic sentence embeddings
- Zero-shot, cross-lingual natural language inference
- Usage
- MultiFiT (Efficient multi-lingual language model fine-tuning)
- Main idea
- Quasi-Recurrent Neural Networks (QRNNs)
- Drawbacks of RNN
- QRNN
- Zero-shot Transfer with a Cross-lingual Teacher
- XLM (Cross-lingual Language Model)
- Shared sub-word vocabulary
- CLM (Causal Language Modeling)
- Modified MLM (Masked Language Modeling)
- TLM (Translation Language Modeling)
- XLM-RoBERTa
- 往期文章链接目录
往期文章链接目录
Multilingual Models are a type of Machine Learning model that can understand different languages. In this post, I’m going to discuss four common multi-lingual language models Multilingual-Bert (M-Bert), Language-Agnostic SEntence Representations (LASER Embeddings), Efficient multi-lingual language model fine-tuning (MultiFiT) and Cross-lingual Language Model (XLM).
Ways of tokenization
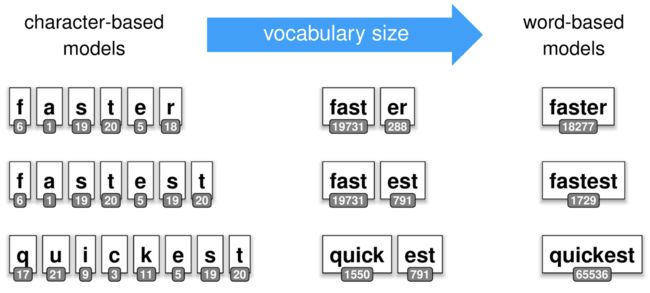
Word-based tokenization
Word-based tokenization works well for the morphologically poor English, but results in very large and sparse vocabularies for morphologically rich languages, such as Polish and Turkish. Some languages such as Chinese don’t really even have the concept of a “word”, so require heuristic segmentation approaches, which tend to be complicated, slow, and inaccurate.
Character-based tokenization
Character-based models use individual characters as tokens. While in this case the vocabulary (and thus the number of parameters) can be small, such models require modelling longer-term dependencies and can thus be harder to train and less expressive than word-based models.
Subword tokenization
Subword tokenization strikes a balance between the two approaches above by using a mixture of character, subword and word tokens, depending on how common they are.
subword tokenization has two very desirable properties for multilingual language modelling:
-
Subwords more easily represent inflections (the change in the form of a word), including common prefixes and suffixes and are thus well-suited for morphologically rich languages.
-
Subword tokenization is a good fit for open-vocabulary problems and eliminates out-of-vocabulary tokens, as the coverage is close to 100% tokens.
Existing approaches for cross-lingual NLP
-
Parallel data across languages — that is, a corpus of documents with exactly the same contents, but written in different languages. This is very hard to acquire in a general setting.
-
A shared vocabulary — that is, a vocabulary that is common across multiple languages. This approach over-represents languages with a lot of data (e.g., Multi-lingual BERT, which I’ll discuss in this post).
Out-of-vocabulary (OOV) problem in mono/multi-lingual settings
It has been shown that the performance on many NLP tasks drops dramatically on held-out data when a significant percentage of words do not appear in the training data, i.e., out-of-vocabulary (OOV) words. OOV problems have been addressed in previous works under monolingual settings, through replacing OOV words with their semantically similar in-vocabulary words or using character/word information or subword information like byte pair encoding (BPE).
All those monolingual pre-trained models (e.x. BERT, GPT) rely on language modeling, where a common trick is to tie the weights of softmax and word embeddings. However, in multilingual setting, due to the expensive computation of softmax and data imbalance across different languages, the vocabulary size for each language in a multilingual model is relatively small compared to the monolingual BERT models, especially for low-resource languages. Even for a high-resource language like Chinese, its vocabulary size 10k in the multilingual BERT is only half the size of that in the Chinese BERT. Just as in monolingual settings, the OOV problem also hinders the performance of a multilingual model on tasks that are sensitive to token-level or sentence-level information.
M-BERT (Multi-lingual BERT)
Multilingual BERT is pre-trained in the same way as monolingual BERT, but instead of being trained only on monolingual English data with an English-derived vocabulary, it is trained on the Wikipedia pages of 104 languages with a shared word piece vocabulary. The vocabulary is 119,547 WordPiece model, and the input is tokenized into word-pieces (also known as subwords) so that each word piece is an element of the dictionary. Non-word-initial units are prefixed with ## as a continuation symbol except for Chinese characters which are surrounded by spaces before any tokenization takes place.
To account for the differences in the size of Wikipedia, some languages are sub-sampled, and some are super-sampled using exponential smoothing (assigns exponentially decreasing weights as the observation get older).
It does not use any marker denoting the input language, and does not have any explicit mechanism to encourage translation equivalent pairs to have similar representations.
WHY MULTILINGUAL BERT WORKS
Definitions:
-
Word-piece overlap: the texts from different languages share some common word-piece vocabulary (like numbers, links, etc… including actual words, if they have the same script).
-
structural similarity: They define the structure of a language as every property of an individual language that is invariant to the script of the language (e.g., morphology, word-ordering, word frequency are all parts of structure of a language).
In the paper Cross-lingual ability of multilingual bert, the authors provide a comprehensive study of the contribution of different components in M-BERT to its cross-lingual ability.
The most notable finding is that word-piece overlap on the one hand, and multi-head attention on the other, are both not significant, whereas structural similarity and the depth of the model are crucial for its cross-lingual ability.

Note:
-
Previous work hypothesizes that M-BERT generalizes across languages because these shared word-pieces force the other word-pieces to be mapped to the same shared space. The paper shows that the contribution of word-piece overlap is very small, which is quite surprising and contradictory to prior hypotheses.
-
The authors’ experiment results shows that the number of attention heads doesn’t have a significant effect on cross-lingual ability. B-BERT (bilingual-bert) is satisfactorily cross-lingual even with a single attention head, which is in agreement with the recent study on monolingual BERT.
A significant shortcoming of M-BERT
The author observe a drastic drop in the entailment performance (NLI task) of B-BERT when the premise and hypothesis are in different languages. One of the possible explanations could be that BERT is learning to make textual entailment decisions by matching words or phrases in the premise to those in the hypothesis. In the following LASER model, it instead supports any combination of premises and hypotheses in different languages in the NLI task.
LASER (Language-Agnostic SEntence Representations)
Facebook open-sourced LASER (Language-Agnostic SEntence Representations) toolkit in Jan 2019. It is the first successful exploration of massively multilingual sentence representations to be shared publicly with the NLP community.
The toolkit now works with more than 90 languages and LASER achieves these results by embedding all languages jointly in a single shared space (rather than having a separate model for each).
LASER also offers several additional benefits:
-
It delivers extremely fast performance, processing up to 2,000 sentences per second on GPU.
-
The sentence encoder is implemented in PyTorch with minimal external dependencies.
-
Languages with limited resources can benefit from joint training over many languages.
-
The model supports the use of multiple languages in one sentence.
-
Performance improves as new languages are added, as the system learns to recognize characteristics of language families.
Universal, language-agnostic sentence embeddings
LASER’s vector representations maps a sentence in any language to a point in a high dimensional space with the goal that the same statement in any language will end up in the same neighborhood. This representation could be seen as a universal language in a semantic vector space. We have observed that the distance in that space correlates very well to the semantic closeness of the sentences.
In the following figure, the image on the left shows a monolingual embedding space. The one on the right illustrates LASER’s approach, which embeds all languages in a single, shared space.

Their approach builds on the same underlying technology as neural machine translation: an encoder/decoder approach. they use one shared encoder for all input languages and a shared decoder to generate the output language. The encoder is a five-layer bidirectional LSTM network. In contrast with neural machine translation, we do not use an attention mechanism but instead have a 1,024-dimension fixed-size vector to represent the input sentence. It is obtained by max-pooling over the last states of the BiLSTM. This enables us to compare sentence representations and feed them directly into a classifier.
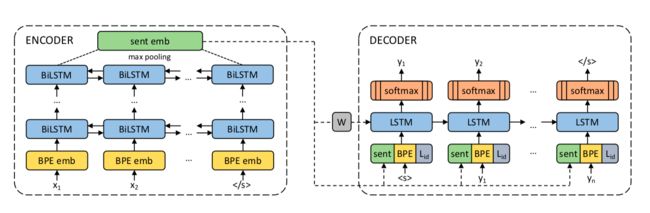
For the detailed results, check out the original paper.
Zero-shot, cross-lingual natural language inference
- natural language inference (NLI): the task of determining whether a “hypothesis” is true (entailment), false (contradiction), or undetermined (neutral) given a “premise”.
The table table shows LASER’s zero-shot transfer performance on the XNLI corpus.
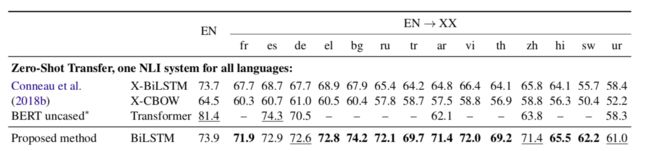
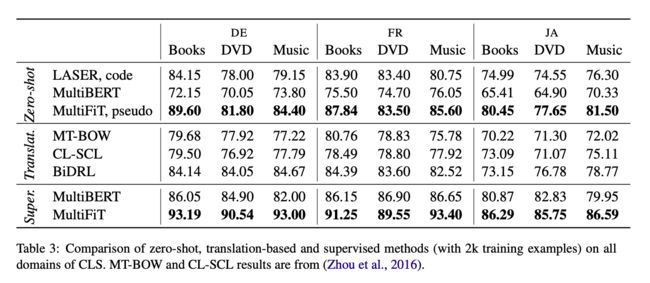
Their proposed model achieves excellent results in cross-lingual natural language inference (NLI). Performance on this task is a strong indicator of how well the model represents the meaning of a sentence. They consider the zero-shot setting; in other words, they train the NLI classifier on English and then apply it to all target languages with no fine tuning or target-language resources. For 8 out of 14 languages, the zero-shot performance is within 5 percent of performance on English, including distant languages like Russian, Chinese, and Vietnamese. They also achieve strong results on low-resource languages like Swahili and Urdu. Finally, LASER outperforms all previous approaches to zero-shot transfer for 13 out of 14 languages.
In contrast to previous methods, which required one sentence to be in English, their system is fully multilingual and supports any combination of premises and hypotheses in different languages.

Usage
!pip install laserembeddings
!python -m laserembeddings download-models
>>> from laserembeddings import Laser
>>> laser = Laser()
>>> embedding = laser.embed_sentences("I like natural language processing.",
lang="en")
>>> embedding.shape
(1, 1024)
MultiFiT (Efficient multi-lingual language model fine-tuning)
Main idea
MultiFiT extends ULMFiT (Universal Language Model Fine-Tuning) to make it more efficient and more suitable for language modelling beyond English: It utilizes tokenization based on subwords rather than words and employs a QRNN rather than an LSTM. In addition, it leverages a number of other improvements.
Quasi-Recurrent Neural Networks (QRNNs)
Drawbacks of RNN
Recurrent neural networks (RNNs) are a powerful tool for modeling sequential data, but the dependence of each timestep’s computation on the previous timestep’s output limits parallelism and makes RNNs unwieldy for very long sequences.
QRNN
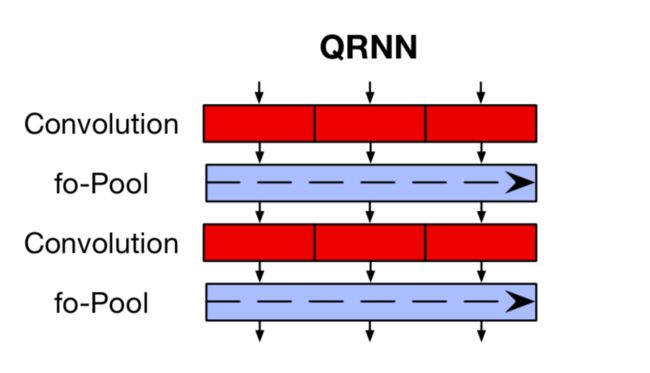
The QRNN is a proposed new LM which strikes a balance between an CNN and an LSTM: It can be parallelized across time and minibatch dimensions like a CNN and inherits the LSTM’s sequential bias as the output depends on the overall order of elements in the sequence. Specifically, the QRNN alternates convolutional layers, which are parallel across timesteps and a recurrent pooling function, which is parallel across channels. Despite lacking trainable recurrent layers, stacked QRNNs have better predictive accuracy than stacked LSTMs of the same hidden size. Due to their increased parallelism, they are up to 16 times faster at train and test time.
ULMFiT ensembles the predictions of a forward and backward language model. Even though bidirectionality has been found to be important in contextual word vectors, they did not see big improvements for our downstream tasks (text classification) with ELMo-style joint training. As joint training is quite memory-intensive and they emphasize efficiency, they opted to just train forward language models for all languages.
The full model can be seen in the below figure. It consists of a subword embedding layer, four QRNN layers, an aggregation layer, and two linear layers. The dimensionality of each layer can be seen in each box at the top.
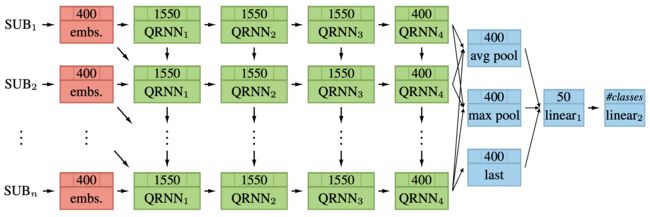
For the detailed results, check out the original paper.
Zero-shot Transfer with a Cross-lingual Teacher
Definitions:
-
Source Language: the language being translated from.
-
Target Language: also called the receptor language, is the language being translated into.
-
Inductive bias: The inductive bias of a machine learning algorithm is the set of assumptions that the model makes in order to predict results given inputs it has not yet encountered (generalize to new inputs).
-
Language-agnostic representation: Sentences in different languages with the same meaning should be given similar embeddings.
Intuition:
If a powerful cross-lingual model and labeled data in a high-resource language are available, it would be nice to make use of them in some way. To this end, they propose to use the classifier that is learned on top of the cross-lingual model on the source language data as a teacher to obtain labels for training their model on the target language. This way, they can perform zero-shot transfer using the monolingual language model by bootstrapping from a cross-lingual one (uses the pre-trained model’s zero-shot predictions as pseudo labels to fine-tune the monolingual model on target language data).
To illustrate how this works, take a look at the following diagram:

The process consists of three main steps:
-
The monolingual language model is pretrained on Wikipedia data in the target language (a) and fine-tuned on in-domain data (target language documents) of the corresponding task (b).
-
Train a classifier on top of cross-lingual model such as LASER using labelled data in a high-resource source language and perform zero-shot inference as usual with this classifier to predict labels on target language documents.
-
In the final step ©, use these predicted labels to fine-tune a classifier on top of the fine-tuned monolingual language model.
This is similar to distillation, which has recently been used to train smaller language models or distill task-specific information into downstream models. In contrast, they do not just seek to distill the information of a big model into a small model but into one with a different inductive bias.
In addition to circumventing the need for labels in the target language, our approach thus brings another benefit: As the monolingual model is specialized to the target language, its inductive bias might be more suitable than the more language-agnostic representations learned by the cross-lingual model. It might thus be able to make better use of labels in the target language, even if they are noisy.
They’re saying that a monolingual model will be more easily fine-tunable for a particular target-language task than a cross-lingual model. Put another way: suppose you’re trying to train a POS tagger for Hindi. It’s better to have a monolingual Hindi pre-trained LM than a cross-lingual model, although that cross-lingual model could potentially do things like generalize an English tagger to work in Hindi.
Their results show that the monolingual language model fine-tuned on zero-shot predictions outperforms its teacher in all settings as you can see in the figure below.
XLM (Cross-lingual Language Model)
XLM uses a known pre-processing technique (BPE) and a dual-language training mechanism with BERT in order to learn relations between words in different languages. The model outperforms other models in a cross-lingual classification task (sentence entailment in 15 languages) and significantly improves machine translation when a pre-trained model is used for initialization of the translation model.
Shared sub-word vocabulary
It uses Byte-Pair Encoding (BPE) that splits the input into the most common sub-words across all languages. This greatly improves the alignment of embedding spaces across languages that share either the same alphabet or anchor tokens such as digits or proper nouns. This is a common pre-processing algorithm.
The authors of the paper proposed three language modeling objectives CLM, MLM, and TLM. The first two only requires monolingual data, while the third one requires parallel sentences.
CLM (Causal Language Modeling)
Their causal language modeling (CLM) task consists of a Transformer language model trained to model the probability of a word given the previous words in a sentence P ( w t ∣ w 1 , . . . , w t − 1 , θ ) P(w_t|w_1, ... , w_{t−1}, \theta) P(wt∣w1,...,wt−1,θ). Given the previous hidden state to the current batch, the model predicts the next word.
Note: this technique does not scale to the cross-lingual setting.
Modified MLM (Masked Language Modeling)
There are two differences between the proposed MLM and the normal MLM
-
Include the use of text streams of an arbitrary number of sentences (truncated at 256 tokens) instead of pairs of sentences.
-
Subsample the frequent subword to counter the imbalance between rare and frequent tokens (e.g. punctuations or stop words).
TLM (Translation Language Modeling)
Both the CLM and MLM objectives are unsupervised and only require monolingual data. However, these objectives cannot be used to leverage parallel data when it is available. The objective of TLM is an extension of MLM, where instead of considering monolingual text streams, we concatenate parallel sentences as illustrated in the figure below. They randomly mask words in both the source and target sentences. To predict a word masked in an English sentence, the model can either attend to surrounding English words or to the French translation, encouraging the model to align the English and French representations. In particular, the model can leverage the French context if the English one is not sufficient to infer the masked English words. To facilitate the alignment, they also reset the positions of target sentences.
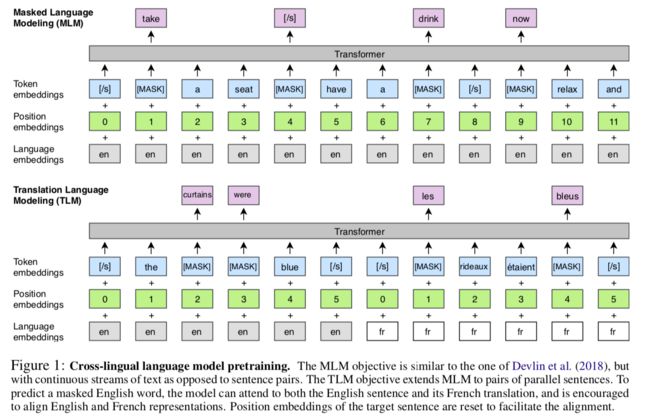
Note: BERT use segment embeddings (represent different sentence) while XLM use language embeddings (represent different language).
The paper also shows that training a cross-lingual language-model can be very beneficial for low-resource languages, as they can leverage data from other languages, especially similar ones mainly due to the BPE pre-processing.
On the XNLI benchmark, it achieves very good performance on Zero-shot. Even better performance if translated data is used during training.
XLM-RoBERTa
The biggest update that XLM-Roberta offers over the original is a significantly increased amount of training data. The cleaned CommonCrawl data that it is trained on takes up a whopping 2.5tb of storage! It is several orders of magnitude larger than the Wiki-100 corpus that was used to train its predecessor and the scale-up is particularly noticeable in the lower resourced languages. The “RoBERTa” part comes from the fact that its training routine is the same as the monolingual RoBERTa model, specifically, that the sole training objective is the Masked Language Model.
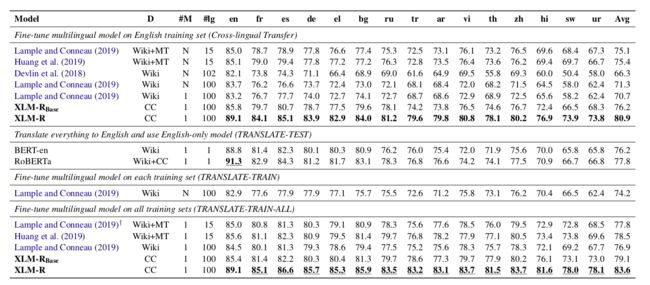
XLM-R significantly outperforms Multilingual-BERT (M-BERT) on a variety of cross-lingual benchmarks, including +14.6% average accuracy on XNLI, +13% average F1 score on MLQA, and +2.4% F1 score on NER. XLM-R performs particularly well on low-resource languages, improving 15.7% in XNLI accuracy for Swahili and 11.4% for Urdu over previous XLM models.
XLM-R seems to be the best solution to date. It is very possible that the TLM (Translation Language Model) approach to train multilingual transformers will be combined with other technologies.
Website Reference:
- Judit Ács’s blog: http://juditacs.github.io/2019/02/19/bert-tokenization-stats.html
- https://huggingface.co/bert-base-multilingual-cased
- Inductive bias 1: https://blog.aylien.com/emnlp-2018-highlights-inductive-bias-cross-lingual-learning-and-more/
- Inductive bias 2: https://stackoverflow.com/questions/35655267/what-is-inductive-bias-in-machine-learning
- fast.ai: http://nlp.fast.ai/classification/2019/09/10/multifit.html
- XLM 1: https://towardsdatascience.com/xlm-enhancing-bert-for-cross-lingual-language-model-5aeed9e6f14b
- XLM 2: https://medium.com/towards-artificial-intelligence/cross-lingual-language-model-56a65dba9358
- http://nlpprogress.com/english/natural_language_inference.html
- https://medium.com/deepset-ai/xlm-roberta-the-multilingual-alternative-for-non-english-nlp-cf0b889ccbbf
- Multilingual Transformers: https://towardsdatascience.com/multilingual-transformers-ae917b36034d
Paper Reference:
- Facebook engineering: https://engineering.fb.com/ai-research/laser-multilingual-sentence-embeddings/
- MultiFiT: Efficient Multi-lingual Language Model Fine-tuning: https://arxiv.org/pdf/1909.04761.pdf
- QUASI-RECURRENT NEURAL NETWORKS: https://arxiv.org/pdf/1611.01576.pdf
- Massively Multilingual Sentence Embeddings for Zero-Shot Cross-Lingual Transfer and Beyond (LASER): https://arxiv.org/pdf/1812.10464.pdf
- Improving Pre-Trained Multilingual Models with Vocabulary Expansion: https://www.groundai.com/project/improving-pre-trained-multilingual-models-with-vocabulary-expansion/1
- Cross-lingual ability of multilingual bert: an empirical study: https://openreview.net/pdf?id=HJeT3yrtDr
- Cross-lingual Language Model Pretraining: https://arxiv.org/pdf/1901.07291.pdf
- Unsupervised Cross-lingual Representation Learning at Scale: https://arxiv.org/pdf/1911.02116.pdf