后端系统缓存技术分析
缓存有很多种,如CPU 缓存、磁盘缓存、浏览器缓存等;本文主要针对后端系统的缓存,也就是将程序或系统经常要使用的对象存在内存中,以便在使用时可以快速调用,避免加载数据或者创建重复的实例,以达到减少系统开销,提高系统效率的目的。
为什么需要缓存?
我觉得操作系统里面讲高速缓存(CPU Cache)的一句话特别好:
为什么要使用CPU Cache?
因为CPU 和内存访问性能的差距非常大,为了弥补两者之间的性能差异,充分利用 CPU,现代 CPU 中引入了高速缓存(CPU Cache)。
因为我们一般都会把数据存放在关系型数据库中,不管数据库的性能有多么好,受限于磁盘IO性能和远程网络的原因,一个简单的查询也要消耗毫秒级的时间,这样我们的 QPS 就会被数据库的性能所限制。
而内存的性能高于磁盘,也没有远程网络的花费。如果恰好这些数据的数据量不大,不经常变动,而且访问频繁。那么就非常适合引入缓存。
总结一下,缓存使用场景:数据不常变更且查询比较频繁是最好的场景,如果查询量不够大或者数据变动太频繁,缓存使用的意义不大,甚至可能适得其反。
缓存的类型
常用的缓存可以分为内部缓存和外部缓存。
内部缓存是指存放在运行实例内部并使用实例内存的缓存,这种缓存可以使用代码直接访问。
外部缓存是指存放在运行实例外部的缓存,通常是通过网络获取,反序列化后进行访问。
一般来说对于不需要实例间同步的,都更加推荐内部缓存,因为内部缓存有访问方便,性能好的特点;需要实例间同步的数据可以使用外部缓存。
内部缓存
内部缓存有容量的限制,毕竟还是在 JVM 里的,存放的数据总量不能超出内存容量。
本地缓存的优点:
- 直接使用内存,速度快,通常存取的性能可以达到每秒千万级
- 可以直接使用 Java 对象存取
本地缓存的缺点:
- 数据保存在当前实例中,无法共享
- 重启应用会丢失
最简单内部缓存-Map
对于字典型的数据,在项目启动的时候加载到 Map 中,程序就可以使用了,也很容易更新。
Map configs = Maps.newHashMap();
public void reloadConfigs(){
configs = loadConfigFromDB();
}
public String getConfigs(String key){
return configs.getOrDefault(key, "null");
} 但是JDK自带的Map做缓存存在一定的问题:
1、hashmap的容量理论上是无上限的(内存无限的情况下),如果缓存太大会严重的占用内存,甚至导致OutOfMemory异常,因此应该限制缓存的容量,容量达到上限后采取合适的淘汰策略。
有准备面试的童鞋应该知道,这就是面试中常见的实现LRU缓存。
实现方式一:可以通过继承LinkedHashMap重写removeEldestEntry()方法实现。
class LRUCache extends LinkedHashMap{
private int capacity;
public LRUCache(int capacity) {
super(capacity, 0.75F, true);
this.capacity = capacity;
}
public int get(int key) {
return super.getOrDefault(key, -1);
}
public void put(int key, int value) {
super.put(key, value);
}
@Override
protected boolean removeEldestEntry(Map.Entry eldest) {
return size() > capacity;
}
} 实现方式二,通过HashMap加双向链表的方式实现。
public class LRUCache {
class DLinkedNode {
int key;
int value;
DLinkedNode prev;
DLinkedNode next;
public DLinkedNode() {}
public DLinkedNode(int key, int value) {key = key; value = value;}
}
private Map cache = new HashMap();
private int size;
private int capacity;
private DLinkedNode head, tail;
public LRUCache(int capacity) {
this.size = 0;
this.capacity = capacity;
// 使用伪头部和伪尾部节点
head = new DLinkedNode();
tail = new DLinkedNode();
head.next = tail;
tail.prev = head;
}
public int get(int key) {
DLinkedNode node = cache.get(key);
if (node == null) {
return -1;
}
// 如果 key 存在,先通过哈希表定位,再移到头部
moveToHead(node);
return node.value;
}
public void put(int key, int value) {
DLinkedNode node = cache.get(key);
if (node == null) {
// 如果 key 不存在,创建一个新的节点
DLinkedNode newNode = new DLinkedNode(key, value);
// 添加进哈希表
cache.put(key, newNode);
// 添加至双向链表的头部
addToHead(newNode);
++size;
if (size > capacity) {
// 如果超出容量,删除双向链表的尾部节点
DLinkedNode tail = removeTail();
// 删除哈希表中对应的项
cache.remove(tail.key);
--size;
}
}
else {
// 如果 key 存在,先通过哈希表定位,再修改 value,并移到头部
node.value = value;
moveToHead(node);
}
}
private void addToHead(DLinkedNode node) {
node.prev = head;
node.next = head.next;
head.next.prev = node;
head.next = node;
}
private void removeNode(DLinkedNode node) {
node.prev.next = node.next;
node.next.prev = node.prev;
}
private void moveToHead(DLinkedNode node) {
removeNode(node);
addToHead(node);
}
private DLinkedNode removeTail() {
DLinkedNode res = tail.prev;
removeNode(res);
return res;
}
} 2、无法设置过期时间。这一点是非常致命的,我们在大多数场景都希望缓存可以在合理的时间后自动失效。
3、并发安全。HashMap、LinkedHashMap都是非并发安全的集合类型。所以应该使用ConcurrentHashMap。
使用ConcurrentHashMap、ReentrantLock 和ScheduledThreadPoolExecutor可以实现带过期时间线程安全的缓存设计。
4、清除数据时的回调通知。
由于代码篇幅过长,见附录1
功能强大的内部缓存-Guava Cache
如果需要缓存有强大的性能,或者对缓存有更多的控制,可以使用 Guava 里的 Cache 组件。
它是 Guava 中的缓存工具包,是非常简单易用且功能强大的 JVM 内缓存。
1、支持多种缓存过期策略:基于容量回收、定时回收、基于引用回收
2、自动加载:
3、显示清除缓存:个别、批量、全量清除
4、移除监听器
5、统计功能:缓存命中率,加载新值的平均时间,缓存项被回收的总数
LoadingCache configs = CacheBuilder.newBuilder()
.maximumSize(1000) // 设置最大大小
.expireAfterWrite(10, TimeUnit.MINUTES) // 设置过期时间, 10分钟
.build(
new CacheLoader() {
// 加载缓存内容
public String load(String key) throws Exception {
return getConfigFromDB(key);
}
public Map loadAll() throws Exception {
return loadConfigFromDB();
}
});
//CacheLoader.loadAll// 获取某个key的值try {
return configs.get(key);} catch (ExecutionException e) {
throw new OtherException(e.getCause());
}
// 显式的放入缓存
configs.put(key, value)
// 个别清除缓存
configs.invalidate(key)
// 批量清除缓存
configs.invalidateAll(keys)
// 清除所有缓存项
configs.invalidateAll() Guava Cache的使用
1、创建(加载)cache
两种方法 CacheLoader和Callable。
LoadingCache userCache = CacheBuilder.newBuilder().maximumSize(100).
expireAfterAccess(30, TimeUnit.MINUTES)
.build(new CacheLoader() {
@Override
public Object load(Object name) throws Exception {
return getIdFromDBByName(name);
}
});Cache cache = CacheBuilder.newBuilder().maximumSize(100).
expireAfterAccess(30, TimeUnit.MINUTES)
.build();
String resultVal = cache.get("hello", new Callable() {
@Override
public String call() throws Exception {
return "hello" + "heitao";
}
}); 以上两种,都实现了一种逻辑:先取缓存——娶不到再执行load 或者call方法来娶。
简单比较,CacheLoader 是按key统一加载,所有娶不到的统一执行一种load逻辑;而callable方法允许在get的时候根据指定key值执行对应的call方法。
在使用缓存前,拍拍自己的四两胸肌,问自己一个问题:有没有【默认方法】来加载或计算与键关联的值?如果有的话,你应当使用CacheLoader。如果没有,或者想要覆盖默认的加载运算。你应该在调用get时传入一个Callable实例。
2、添加、插入key
get : 要么返回已经缓存的值,要么使用CacheLoader向缓存原子地加载新值;
getUnchecked:CacheLoader 会抛异常,定义的CacheLoader没有声明任何检查型异常,则可以 getUnchecked 查找缓存;反之不能;
getAll :方法用来执行批量查询;
put : 向缓存显式插入值,Cache.asMap()也能修改值,但不具原子性;
getIfPresent :该方法只是简单的把Guava Cache当作Map的替代品,不执行load方法;
3、清除key
guava cache 自带 清除机制,但仍旧可以手动清除:
个别清除:Cache.invalidate(key)
批量清除:Cache.invalidateAll(keys)
清除所有缓存项:Cache.invalidateAll()
4 refresh和expire刷新机制
expireAfterAccess(30, TimeUnit.MINUTES ) // 30min内没有被读或写就会被回收 ;
expireAfterWrite(30, TimeUnit.MINUTES ) // 30min内没有没有更新就会被回收 :
refreshAfterAccess(30, TimeUnit.MINUTES) //上一次更新操作30min后再刷新;
注意:和redis的惰性回收机制一样
30min内没有被读或写就会被回收” 不等于 “30min内会被回收” ,因为真正的过期/刷新操作是在key被读或写时发生的。
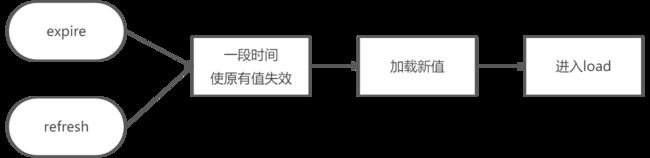
只有发生“取值”操作,才会执行load,然而为了防止“缓存穿透”,在多线程的环境下,任何时刻只允许一个线程操作执行load操作 。
但在执行load操作这个步骤,expire 与 refresh 的线程机制不同:
expire 在load 阶段——同步机制:当前线程load未完成,其他线程呈阻塞状态,待当前线程load完成,其他线程均需进行”获得锁--获得值--释放锁“的过程。这种方法会让性能有一定的损耗。
refresh 在load阶段——异步机制 :当前线程load未完成,其他线程仍可以取原来的值,等当前线程load完成后,下次某线程再取值时,会判断系统时间间隔是否时超过设定refresh时间,来决定是否设定新值。所以,refresh机制的特点是,设定30分钟刷新,30min后并不一定就是立马就能保证取到新值
expire与refresh 都能控制key得回收,究竟如何选择?
答案是,两个一起来!
只要refresh得时间小于expire时间,就能保证多线程在load取值时不阻塞,也能保证refresh时间到期后,取旧值向新值得平滑过渡,当然,仍旧不能解决取到旧值得问题。
5 监听
在guava cache中移除key可以设置相应得监听操作,以便key被移除时做一些额外操作。缓存项被移除时,RemovalListener会获取移除通知[RemovalNotification],其中包含移除原因[RemovalCause]、键和值。监听有同步监听和异步监听两种 :
同步监听:
默认情况下,监听器方法是被同步调用的(在移除缓存的那个线程中执行),执行清理key的操作与执行监听是单线程模式,当然监听器中抛出的任何异常都不会影响其正常使用,顶多把异常写到日记了。
@Test
public void testCacheRemovedNotification(){
CacheLoader loader = CacheLoader.from(String::toUpperCase);
RemovalListener listener = notification -> {
if (notification.wasEvicted()){
RemovalCause cause = notification.getCause();
System.out.println("remove case is : " + cause.toString());
System.out.println("key: "+notification.getKey()+" value:" + notification.getValue());
}
};
LoadingCache cache = CacheBuilder.newBuilder().maximumSize(4)
.removalListener(listener).build(loader);
cache.getUnchecked("maomao");
cache.getUnchecked("wangwang");
cache.getUnchecked("guava");
cache.getUnchecked("cache");
cache.getUnchecked("hello");
} 异步监听:
假如在同步监听模式下,监听方法中的逻辑特别复杂,执行效率慢,那此时如果有大量的key进行清理,会使整个缓存性能变得很低下,所以此时适合用异步监听,移除key与监听key的移除分属2个线程。
@Test
public void testCacheRemovedNotification(){
CacheLoader loader = CacheLoader.from(String::toUpperCase);
RemovalListener listener = notification -> {
if (notification.wasEvicted()){
RemovalCause cause = notification.getCause();
System.out.println("remove case is : " + cause.toString());
System.out.println("key: "+notification.getKey()+" value:" + notification.getValue());
}
};
LoadingCache cache = CacheBuilder.newBuilder().maximumSize(4)
.removalListener(RemovalListeners.asynchronous(listener, Executors.newSingleThreadExecutor())).build(loader);
cache.getUnchecked("maomao");
cache.getUnchecked("wangwang");
cache.getUnchecked("guava");
cache.getUnchecked("cache");
cache.getUnchecked("hello");
} 6 统计
guava cache还有一些其他特性,比如weight 按权重回收资源,统计等,这里列出统计。CacheBuilder.recordStats()用来开启Guava Cache的统计功能。统计打开后Cache.stats()方法返回如下统计信息:
- hitRate():缓存命中率;
- hitMiss(): 缓存失误率;
- loadcount() ; 加载次数;
- averageLoadPenalty():加载新值的平均时间,单位为纳秒;
- evictionCount():缓存项被回收的总数,不包括显式清除。
Guava Cache 的替代者 Caffeine
外部缓存
最著名的外部缓存 - Redis / Memcached
Redis / Memcached 都是使用内存作为存储,所以性能上要比数据库要好很多,再加上Redis 还支持很多种数据结构,使用起来也挺方便,所以作为很多人的首选。
Redis 确实不错,不过即便是使用内存,也还是需要通过网络来访问,所以网络的性能决定了 Reids 的性能;
在一些性能测试中,在万兆网卡的情况下,对于 Key 和 Value 都是长度为 20 Byte 的字符串的 get 和 set 是每秒10w左右的,如果 Key 或者 Value 的长度更大或者使用数据结构,这个会更慢一些;
作为一般的系统来使用已经绰绰有余了,从目前来看,Redis 确实很适合来做系统中的缓存。
如果考虑多实例或者分布式,可以考虑下面的方式:
- Jedis 的 ShardedJedis( 调用端自己实现分片 )
- twemproxy / codis( 第三方组件实现代理 )
- Redis Cluster( 3.0 之后官方提供的集群方案 )
缓存的异常情况
缓存穿透
指的是对某个一定不存在的数据进行请求,该请求将会穿透缓存到达数据库。
解决方案:
- 对这些不存在的数据缓存一个空数据;
- 对这类请求进行过滤。
缓存击穿
指的是由于数据没有被加载到缓存中,或者缓存数据在同一时间大面积失效(过期),又或者缓存服务器宕机,导致大量的请求都到达数据库。
在有缓存的系统中,系统非常依赖于缓存,缓存分担了很大一部分的数据请求。当发生缓存雪崩时,数据库无法处理这么大的请求,导致数据库崩溃。
解决方案:
- 为了防止缓存在同一时间大面积过期导致的缓存雪崩,可以通过观察用户行为,合理设置缓存过期时间来实现;
- 为了防止缓存服务器宕机出现的缓存雪崩,可以使用分布式缓存,分布式缓存中每一个节点只缓存部分的数据,当某个节点宕机时可以保证其它节点的缓存仍然可用。
- 也可以进行缓存预热,避免在系统刚启动不久由于还未将大量数据进行缓存而导致缓存雪崩。
缓存一致性
缓存一致性要求数据更新的同时缓存数据也能够实时更新。
解决方案:
- 在数据更新的同时立即去更新缓存;
- 在读缓存之前先判断缓存是否是最新的,如果不是最新的先进行更新。
要保证缓存一致性需要付出很大的代价,缓存数据最好是那些对一致性要求不高的数据,允许缓存数据存在一些脏数据。
缓存“无底洞”现象
指的是为了满足业务要求添加了大量缓存节点,但是性能不但没有好转反而下降了的现象。
产生原因:缓存系统通常采用 hash 函数将 key 映射到对应的缓存节点,随着缓存节点数目的增加,键值分布到更多的节点上,导致客户端一次批量操作会涉及多次网络操作,这意味着批量操作的耗时会随着节点数目的增加而不断增大。此外,网络连接数变多,对节点的性能也有一定影响。
解决方案:
- 优化批量数据操作命令;
- 减少网络通信次数;
- 降低接入成本,使用长连接 / 连接池,NIO 等。
附录
附录1 使用ConcurrentHashMap实现带过期时间的缓存
private static ScheduledExecutorService swapExpiredPool = new ScheduledThreadPoolExecutor(10);
private ReentrantLock lock = new ReentrantLock();
private ConcurrentHashMap cache = new ConcurrentHashMap<>(1024);
/**
* 让过期时间最小的数据排在队列前,在清除过期数据时
* ,只需查看缓存最近的过期数据,而不用扫描全部缓存
*
* @see Node#compareTo(Node)
* @see SwapExpiredNodeWork#run()
*/
private PriorityQueue expireQueue = new PriorityQueue<>(1024);
public LocalCache() {
//使用默认的线程池,每5秒清除一次过期数据
//线程池和调用频率 最好是交给调用者去设置。
swapExpiredPool.scheduleWithFixedDelay(
new SwapExpiredNodeWork(), 5, 5, TimeUnit.SECONDS);
}
public Object set(String key, Object value, long ttl) {
Assert.isTrue(StringUtils.hasLength(key), "key can't be empty");
Assert.isTrue(ttl > 0, "ttl must greater than 0");
long expireTime = System.currentTimeMillis() + ttl;
Node newNode = new Node(key, value, expireTime);
lock.lock();
try {
Node old = cache.put(key, newNode);
expireQueue.add(newNode);
//如果该key存在数据,还要从过期时间队列删除
if (old != null) {
expireQueue.remove(old);
return old.value;
}
return null;
} finally {
lock.unlock();
}
}
/**
* 拿到的数据可能是已经过期的数据,可以再次判断一下
* if(n.expireTime
*
* 无法判断不存在该key,还是该key存的是一个null值,如果需要区分这两种情况
* 可以定义一个全局标识,标识key不存在
* public static final NOT_EXIST = new Object();
* 返回值时
* return n==null?NOT_EXIST:n.value;
*/
public Object get(String key) {
Node n = cache.get(key);
return n == null ? null : n.value;
}
/**
* 删除KEY,并返回该key对应的数据
*/
public Object remove(String key) {
lock.lock();
try {
Node n = cache.remove(key);
if (n == null) {
return null;
} else {
expireQueue.remove(n);
return n.value;
}
} finally {
lock.unlock();
}
}
/**
* 删除已经过期的数据
*/
private class SwapExpiredNodeWork implements Runnable {
@Override
public void run() {
long now = System.currentTimeMillis();
while (true) {
lock.lock();
try {
Node node = expireQueue.peek();
//没有数据了,或者数据都是没有过期的了
if (node == null || node.expireTime > now) {
return;
}
cache.remove(node.key);
expireQueue.poll();
} finally {
lock.unlock();
}
}
}
}
private static class Node implements Comparable {
private String key;
private Object value;
private long expireTime;
public Node(String key, Object value, long expireTime) {
this.value = value;
this.key = key;
this.expireTime = expireTime;
}
/**
* @see SwapExpiredNodeWork
*/
@Override
public int compareTo(Node o) {
long r = this.expireTime - o.expireTime;
if (r > 0) {
return 1;
}
if (r < 0) {
return -1;
}
return 0;
}
}