08_sklearn数据集,数据集划分train_test_split,sklearn.datasets及其api,sklearn分类数据集,sklearn回归数据集,转换器与预估器
1、sklearn数据集
1.1 数据集划分
机器学习一般的数据集会划分为两个部分
训练数据:用于训练,构建模型
测试数据:在模型检验时使用,用来评估模型是否有效
1.1.1 sklearn数据集划分API
sklearn.model_selection.train_test_split
功能
将数组或矩阵拆分为随机的训练子集和测试子集 。
输入和输出
输入:
1、arrays: 具有相同长度的可索引序列,x-y的映射(sequence of indexables with same length / shape[0])
2、test_size(optional):float,int,or None(default=None)
A:如果为float,则应介于0.0和1.0之间,并表示要包含在测试拆分中的数据集的比例。
B:如果是int,则表示测试样本的绝对数量
C:如果为None,则将该值设置为train_size的补码。如果train_size也是None,则将其设置为0.25
3、train_size:float,int,or None,(default=None)
A:如果为float,则应介于0.0和1.0之间,并表示要包含在列车拆分中的数据集的比例。
B:如果是int,则表示测试集大小的绝对数量。
C:如果为None,则该值自动设置为test_size 的补码。
4、random_state (optional) : int, RandomState instance or None, (default=None)
A:如果是int,则random_state是随机数生成器使用的种子。
B:如果是RandomState instance,则random_state是随机数生成器。
C:如果为None,则随机数生成器是由其使用的RandomState实例np.random。
5、shuffle(optional):bool类型,(default=True)
是否在拆分之前对数据打乱。如果shuffle = False,则stratify必须为None。
6、stratify : array-like or None (default=None)
如果不是None,则数据以分层方式拆分,使用此作为类标签。
输出:
1、splitting : list类型, length=2 * len(arrays)
包含划分好的训练子集和测试子集的列表。
示例:
# -*- coding: UTF-8 -*-
import numpy as np
from sklearn.model_selection import train_test_split
# train_test_split 字面含义是"训练数据"和"测试数据"的切分
"""
X:当成特征值,为5行3列的值
y:当成目标值,为1行5列的一维数组
"""
X, y = np.arange(15).reshape((5,3)), range(5)
print(X)
print(list(y))
"""
上面的运行结果为:
[[ 0 1 2]
[ 3 4 5]
[ 6 7 8]
[ 9 10 11]
[12 13 14]]
[0, 1, 2, 3, 4]
"""
# 划分训练集合测试集(shuffle=default=True)
#下面test_size=0.33表示测试集占33%
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.33,random_state=42)
print("X_train特征值中的训练集数据:")
print(X_train)
print("y_train 目标值中的训练集数据:")
print(y_train)
print("X_test:测试集中的特征值:")
print(X_test)
print("y_test:测试集中的目标值:")
print(y_test)
# shuffle=False的划分方式,为True的时候,表示将会打乱数据
print("y:")
print(y)
print("train_test_split(y,shuffle=False):")
print(train_test_split(y,shuffle=False))
print("train_test_split(y,shuffle=True):")
print(train_test_split(y,shuffle=True))
输出结果:
[[ 0 1 2]
[ 3 4 5]
[ 6 7 8]
[ 9 10 11]
[12 13 14]]
[0, 1, 2, 3, 4]
X_train特征值中的训练集数据:
[[ 6 7 8]
[ 0 1 2]
[ 9 10 11]]
y_train 目标值中的训练集数据:
[2, 0, 3]
X_test:测试集中的特征值:
[[ 3 4 5]
[12 13 14]]
y_test:测试集中的目标值:
[1, 4]
y:
range(0, 5)
train_test_split(y,shuffle=False):
[[0, 1, 2], [3, 4]]
train_test_split(y,shuffle=True):
[[0, 4, 3], [1, 2]]
1.2 sklearn数据集接口API介绍
sklearn.datasets
1、加载获取流行数据集
2、datasets.load_*()
获取小规模数据集,数据包含在datasets里
datasets.fetch_*(data_home=None)
1、获取大规模数据集,需要从网络上下载,函数的第一个参数是data_home,表示数据集下载的目录,默认是 ~/scikit_learn_data/
获取数据集返回的类型:
load*和fetch*返回的数据类型datasets.base.Bunch(字典格式)
1、data:特征数据数组,是 [n_samples * n_features] 的二维numpy.ndarray数组。
2、target:标签数组,是 n_samples 的一维 numpy.ndarray 数组
3、DESCR:数据描述
4、feature_names:特征名,新闻数据,手写数字、回归数据集没有
5、target_names:标签名,回归数据集没有。
1.3 sklearn分类数据集
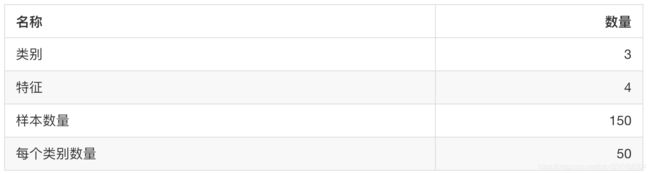
sklearn.datasets.load_iris()
加载并返回鸢尾花数据集
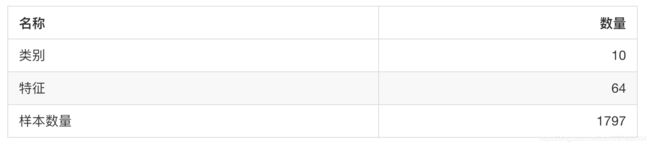
sklearn.datasets.load_digits()
加载并返回数字数据集
案例:
from sklearn.datasets import load_iris,fetch_20newsgroups,load_boston
from sklearn.model_selection import train_test_split
li = load_iris()
print("获取特征值:")
print(li.data)
print("目标值:")
print(li.target)
#数据集的描述
# print(li.DESCR)
#注意返回值, 训练集 train x_train, y_train 测试集 test x_test, y_test
x_train, x_test, y_train, y_test = train_test_split(li.data, li.target, test_size=0.25)
print("训练集里的特征值和目标值:", x_train, y_train)
print("测试集里的特征值和目标值:", x_test,y_test)
输出结果:
获取特征值:
[[5.1 3.5 1.4 0.2]
[4.9 3. 1.4 0.2]
[4.7 3.2 1.3 0.2]
......
[6.3 2.5 5. 1.9]
[6.5 3. 5.2 2. ]
[6.2 3.4 5.4 2.3]
[5.9 3. 5.1 1.8]]
目标值:
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]
训练集里的特征值和目标值: [[5. 3.6 1.4 0.2]
[5.1 3.3 1.7 0.5]
[5.6 3. 4.5 1.5]
[5. 3.4 1.6 0.4]
[6. 2.7 5.1 1.6]
......
[5. 2. 3.5 1. ]
[6.9 3.1 4.9 1.5]
[7.1 3. 5.9 2.1]
[6.7 3.1 4.7 1.5]
[4.6 3.4 1.4 0.3]
[6.3 2.7 4.9 1.8]] [0 0 1 0 1 2 1 0 1 0 2 2 1 2 2 0 0 2 0 2 0 0 1 2 0 0 0 1 1 1 2 0 0 2 0 2 2
1 0 0 2 2 0 0 1 1 2 1 2 2 1 1 0 2 0 1 2 1 2 0 2 1 2 1 2 0 0 1 2 0 1 1 2 1
0 1 1 2 1 2 2 2 0 0 1 2 2 0 1 1 1 0 2 2 1 1 0 1 0 1 0 0 0 0 2 2 1 1 2 1 0
2]
测试集里的特征值和目标值: [[5. 3.5 1.3 0.3]
[6.1 2.6 5.6 1.4]
[5.7 2.9 4.2 1.3]
[6.5 3. 5.2 2. ]
[5.2 3.4 1.4 0.2]
......
[6.7 3.3 5.7 2.1]
[5.2 4.1 1.5 0.1]
[6.7 2.5 5.8 1.8]
[7.3 2.9 6.3 1.8]] [0 2 1 2 0 1 1 1 2 0 2 2 0 1 0 2 2 0 1 0 1 1 0 0 2 2 0 1 0 1 1 1 2 1 2 0 2 2]
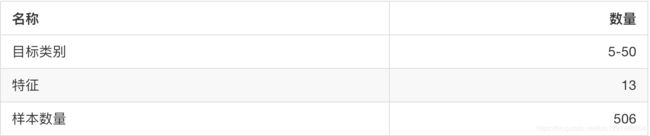
用于分类的大数据集
sklearn.datasets.fetch_20newsgroups(data_home=None,subset=‘train’)
1、subset: 'train'或者'test','all',可选,选择要加载的数据集.
训练集的“训练”,测试集的“测试”,两者的“全部”
datasets.clear_data_home(data_home=None)
清除目录下的数据
案例:
from sklearn.datasets import fetch_20newsgroups,load_boston
from sklearn.model_selection import train_test_split
news = fetch_20newsgroups(subset='all')
print("-----------news.data:----------------")
print(news.data)
print("-----------news.target:--------------")
print(news.target)
1.4 sklearn回归数据集
sklearn.datasets.load_boston()
加载并返回波士顿房价数据集
sklearn.datasets.load_diabetes()
加载和返回糖尿病数据集
from sklearn.datasets import fetch_20newsgroups,load_boston
from sklearn.model_selection import train_test_split
lb = load_boston()
print("load_boston获取特征值:")
print(lb.data)
print("load_boston目标值")
print(lb.target)
# print(lb.DESCR)
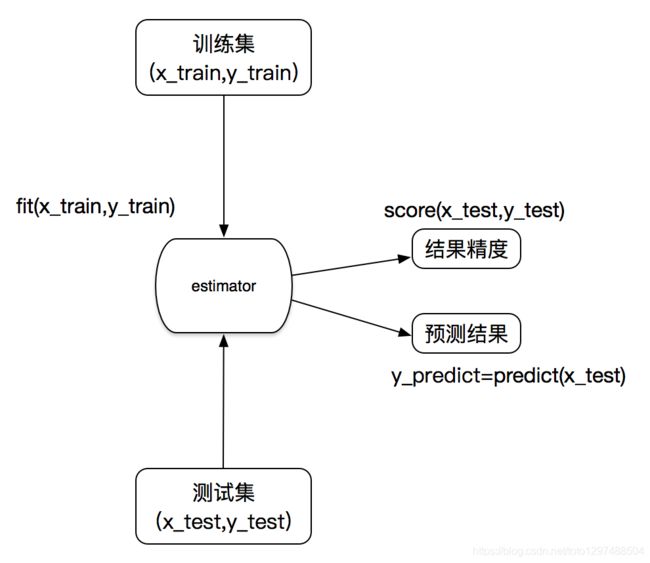
2、转换器与预估器
想一下之前做的特征工程的步骤?
1、实例化 (实例化的是一个转换器类(Transformer))
2、调用fit_transform(对于文档建立分类词频矩阵,不能同时调用)

2.1、sklearn机器学习算法的实现–估计器
在sklearn中,估计器(estimator)是一个重要的角色,分类器和回归器都属于estimator,是一类实现了算法的API
1、用于分类的估计器:
A:sklearn.neighbors K-近邻算法
B:sklearn.naive_bayes 贝叶斯
C:sklearn.linear_model.LogisticRegression 逻辑回归
2、用于回归的估计器:
A:sklearn.linear_model.LinearRegression 线性回归
B:sklearn.linear_model.Ridge 岭回归
2.2、估计器的工作流程