Kafka入门实例
摘要:本文主要讲了Kafka的一个简单入门实例
源码下载:https://github.com/appleappleapple/BigDataLearning
kafka安装过程看这里:Kafka在Windows安装运行
整个工程目录如下:
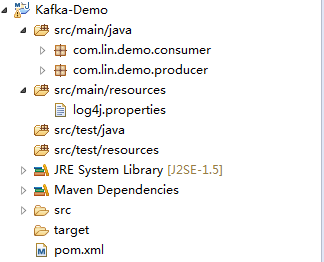
1、pom文件
4.0.0
com.lin
Kafka-Demo
0.0.1-SNAPSHOT
org.apache.kafka
kafka_2.10
0.9.0.0
org.opentsdb
java-client
2.1.0-SNAPSHOT
org.slf4j
slf4j-log4j12
log4j
log4j
org.slf4j
jcl-over-slf4j
com.alibaba
fastjson
1.2.4
2、生产者
package com.lin.demo.producer;
import java.util.Properties;
import kafka.javaapi.producer.Producer;
import kafka.producer.KeyedMessage;
import kafka.producer.ProducerConfig;
public class KafkaProducer {
private final Producer producer;
public final static String TOPIC = "linlin";
private KafkaProducer() {
Properties props = new Properties();
// 此处配置的是kafka的端口
props.put("metadata.broker.list", "127.0.0.1:9092");
props.put("zk.connect", "127.0.0.1:2181");
// 配置value的序列化类
props.put("serializer.class", "kafka.serializer.StringEncoder");
// 配置key的序列化类
props.put("key.serializer.class", "kafka.serializer.StringEncoder");
props.put("request.required.acks", "-1");
producer = new Producer(new ProducerConfig(props));
}
void produce() {
int messageNo = 1000;
final int COUNT = 10000;
while (messageNo < COUNT) {
String key = String.valueOf(messageNo);
String data = "hello kafka message " + key;
producer.send(new KeyedMessage(TOPIC, key, data));
System.out.println(data);
messageNo++;
}
}
public static void main(String[] args) {
new KafkaProducer().produce();
}
} 右键:run as java application
运行结果:
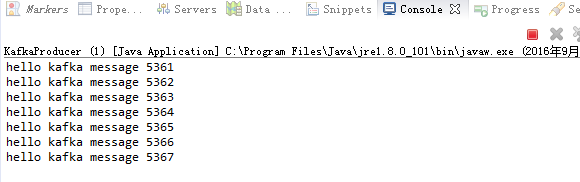
3、消费者
package com.lin.demo.consumer;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Properties;
import kafka.consumer.ConsumerConfig;
import kafka.consumer.ConsumerIterator;
import kafka.consumer.KafkaStream;
import kafka.javaapi.consumer.ConsumerConnector;
import kafka.serializer.StringDecoder;
import kafka.utils.VerifiableProperties;
import com.lin.demo.producer.KafkaProducer;
public class KafkaConsumer {
private final ConsumerConnector consumer;
private KafkaConsumer() {
Properties props = new Properties();
// zookeeper 配置
props.put("zookeeper.connect", "127.0.0.1:2181");
// group 代表一个消费组
props.put("group.id", "lingroup");
// zk连接超时
props.put("zookeeper.session.timeout.ms", "4000");
props.put("zookeeper.sync.time.ms", "200");
props.put("rebalance.max.retries", "5");
props.put("rebalance.backoff.ms", "1200");
props.put("auto.commit.interval.ms", "1000");
props.put("auto.offset.reset", "smallest");
// 序列化类
props.put("serializer.class", "kafka.serializer.StringEncoder");
ConsumerConfig config = new ConsumerConfig(props);
consumer = kafka.consumer.Consumer.createJavaConsumerConnector(config);
}
void consume() {
Map topicCountMap = new HashMap();
topicCountMap.put(KafkaProducer.TOPIC, new Integer(1));
StringDecoder keyDecoder = new StringDecoder(new VerifiableProperties());
StringDecoder valueDecoder = new StringDecoder(new VerifiableProperties());
Map>> consumerMap = consumer.createMessageStreams(topicCountMap, keyDecoder, valueDecoder);
KafkaStream stream = consumerMap.get(KafkaProducer.TOPIC).get(0);
ConsumerIterator it = stream.iterator();
while (it.hasNext())
System.out.println("<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<" + it.next().message() + "<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<");
}
public static void main(String[] args) {
new KafkaConsumer().consume();
}
} 运行结果:

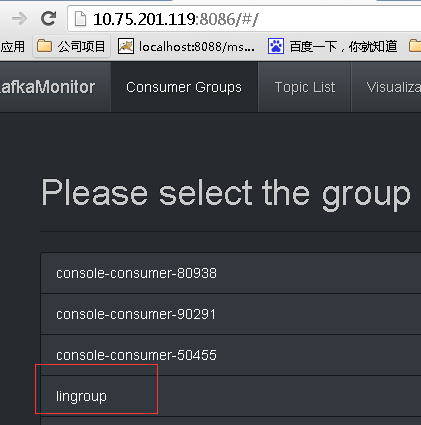
监控页面
源码下载:https://github.com/appleappleapple/BigDataLearning