'''数据分析模块:
numpy
pandas
torch
keras
tensorflow
tushare
sklearn
opencv
kivy-------用到再补充
pyqt-------用到再补充
'''
#第二十一章:numpy
import numpy as np
#print(np.__all__)#共615个属性及方法,只需抽重点掌握即可
#一、基本操作
a=np.array([[1,2,3],[2,3,4]],dtype=np.float32)#传入矩阵与数据类型(默认int32)
print(type(a))#,全称numpy data array类型
print(type(a[1]))#
print(type(a[1][1]))#,注意这个int32是numpy下自定义的
print(a.shape)#(2, 3),形状
print(a.ndim)#2,numpy dimension维度
print(a.size)#6,元素量
print(a.dtype)#float32,data type数据类型
print(np.min(a))#1.0
print(np.max(a))#4.0
print(np.sum(a))#15.0,全元素求和
print(np.sum(a,axis=1))#[6. 9.],行方向求和,生成的shape=(2,)
print(np.max(a,axis=0))#[2. 3. 4.],列方向求和,生成的shape=(3,)
print(np.zeros((1,4)))#[[0. 0. 0. 0.]],0
print(np.empty((1,2)))#[[7.74860419e-304 7.74860419e-304]],极小数
print(np.arange(1,7,2))#[1 3 5],按区间及步长生成一维矩阵
print(np.arange(6).reshape((2,3)))#[[0 1 2], [3 4 5]],变形
print(np.linspace(1,10,6))#[ 1. 2.8 4.6 6.4 8.2 10. ],线性生成一维矩阵
print(np.random.random((1,3)))#[[0.04366155 0.42265875 0.83824841]],随机数0~1
#二、运算符操作
a=np.array([10,20,30,40])
b=np.array([0,1,2,3])
print(a+b)#[10 21 32 43]
print(a-b)#[10 19 28 37]
print(a*2)#[20 40 60 80]
print(a/2)#[ 5. 10. 15. 20.]
print(a**2)#[ 100 400 900 1600]
print(a<25)#[ True True False False]
print(np.sin(np.array([0,1.57,3.14])))#[0. 0.99999968 0.00159265]
a=np.array([1,1,0,1]).reshape(2,2)
b=np.arange(4).reshape(2,2)
print(a*b)#[[0 1],[0 3]]
print(np.dot(a,b))#[[2 4],[2 3]]
#三、进阶操作
a=np.arange(10,4,-1).reshape((2,3))
print(a)#[[10 9 8] [ 7 6 5]]
print(a[:,:])#[[10 9 8] [ 7 6 5]]
print(a[0:2,1:3])#[[9 8] [6 5]],0~1行,1~2列
print(a.flatten())#[10 9 8 7 6 5]压平
for row in a:print(row,end='~')#[10 9 8]~[7 6 5]~遍历行
for column in a.T:print(column,end='~')#[10 7]~[9 6]~[8 5]~遍历列
for item in a.flat:print(item)#10 9 8 7 6 5,a.flat生成一维迭代器
print(np.argmax(a))#0,一个函数
print(np.average(a))#7.5,平均
print(np.median(a))#7.5,平均
print(np.cumsum(a))#[10 19 27 34 40 45],前缀和
print(np.diff(a))#[[-1 -1] [-1 -1]],离散差值
print(np.nonzero(a))#返回非零的X,Y,(array([0, 0, 0, 1, 1, 1], dtype=int64), array([0, 1, 2, 0, 1, 2], dtype=int64))
print(np.sort(a))#[[ 8 9 10] [ 5 6 7]],排序
print(a.T)#[[10 7] [ 9 6] [ 8 5]],转置
print(np.transpose(a))#转置同上
print(np.clip(a,5,9))#[[9 9 8] [7 6 5]],设上下限,超限值调整至限值
print(np.mean(a,axis=0))#[8.5 7.5 6.5]对,列计算均值
print(np.mean(a,axis=1))#[9. 6.],对行计算均值
#四、特殊操作
#(1)分割split
a=np.arange(12).reshape((3,4))
b,c=np.split(a,2,axis=1)#按列分割,等价于np.hsplit(a,2)
d,e,f=np.split(a,3,axis=0)#按行分割,等价于np.vsplit(a,3)
print(b,c)#[[0 1],[4 5],[8 9]] [[2 3],[6 7],[10 11]],shape=(3,2)
print(d,e,f)#[[0 1 2 3]] [[4 5 6 7]] [[ 8 9 10 11]],shpae=(1,4)
a=np.arange(4)
#(2)拷贝copy
b=a#软拷贝,AB等价
c=a.copy()#硬拷贝,AC不等价
a[0]=11
print(a)#[11 1 2 3]
print(b)#[11 1 2 3]
print(c)#[0 1 2 3]
#(3)升维newaxis
a=np.array([1,1,1])#一阶,阶与维是同概念
print(a.shape)#(3,),numpy对一阶矩阵是没分行列
print(a.T.shape)#(3,),既是行也是列,所以一阶的转置不变
c=a[np.newaxis,:]#行升维,变二阶
d=a[:,np.newaxis]#列升维,变二阶
print(c,c.shape)#[[1 1 1]] (1, 3),在行上加维度,二维数组
print(d,d.shape)#[[1] [1] [1]] (3, 1),在列上加维度,二维数组
#(4)合并concatenate,vstack,hstack
a=np.array([1,1,1])#
b=np.array([2,2,2])
c=np.vstack((a,b))
d=np.hstack((a,b))
print(a,a.shape)#[1 1 1] (3,)
print(b,b.shape)#[2 2 2] (3,)
print(c,c.shape)#[[1 1 1] [2 2 2]] (2, 3),列合并,即变成多行
print(d,d.shape)#[1 1 1 2 2 2] (6,),行合并,即变成多列
d=np.array([[1,2,3],[4,5,6],[7,8,9]])
e=np.array([[1,2,3],[4,5,6],[7,8,9]])
f=np.concatenate((d,e),axis=0)#行合并
g=np.concatenate((d,e),axis=1)#列合并
print(f)
print(g)
'''
[[1 2 3]
[4 5 6]
[7 8 9]
[1 2 3]
[4 5 6]
[7 8 9]]
[[1 2 3 1 2 3]
[4 5 6 4 5 6]
[7 8 9 7 8 9]]
'''
#第二十二章:pandas
import numpy as np#numpy重在矩阵内部运算,pandas重在矩阵间挑选合并
import pandas as pd#numpd升级版有行列标签
print('numpy\nPart1创建:DataFrame数据框架')
s=pd.Series([1,3,6,np.nan,44,1])
print(s)
'''
0 1.0
1 3.0
2 6.0
3 NaN
4 44.0
5 1.0
dtype: float64
'''
dates=pd.date_range('20160101',periods=6)
print(dates)
'''
DatetimeIndex([
'2016-01-01',
'2016-01-02',
'2016-01-03',
'2016-01-04',
'2016-01-05',
'2016-01-06'],
dtype='datetime64[ns]',
freq='D')
'''
df=pd.DataFrame(np.random.randn(6,4),index=dates,columns=['a','b','c','d'])
print(df)#注意下面的行列标签,默认是0123……
''' a b c d
2016-01-01 -0.346525 1.320273 1.264326 0.310309
2016-01-02 -0.803533 0.834628 0.242953 0.617996
2016-01-03 -1.056487 -0.542874 1.257013 -0.739535
2016-01-04 0.248479 0.620812 -0.485491 0.132013
2016-01-05 -1.196680 -0.024697 1.959581 -0.392433
2016-01-06 -0.705661 1.524657 -0.125209 0.432786
'''
df2=pd.DataFrame({'a':1.,'b':[2,3]})#可用字典创建,键是属性名
print(df2)#'a':1应写成'a':[1.,1.]比较好,此处写得简洁了
'''
a b
0 1.0 2
1 1.0 3
'''
print(df2.dtypes)
'''
a float64
b int64
dtype: object\
'''
print(df2.sort_index(axis=1,ascending=False))
'''按列属性排序,且非升序,所以下面是b a
b a
0 2 1.0
1 3 1.0
'''
print('\n\n\nPart2访问:loc索引属性访问,iloc下标访问')
dates = pd.date_range('20130101', periods=6)#注意下面创建DF中的数据就是用numpy的
df = pd.DataFrame(np.arange(24).reshape((6,4)),index=dates, columns=['A','B','C','D'])
print(df.loc[:,['A','B']])#取所有行,选择属性名对应列输出(注意用[,]列举属性名)
''' A B
2013-01-01 0 1
2013-01-02 4 5
2013-01-03 8 9
2013-01-04 12 13
2013-01-05 16 17
2013-01-06 20 21
'''
print(df.iloc[3:5,1:3])#用下标输出,第3~4行,第1~2列
''' B C
2013-01-04 13 14
2013-01-05 17 18
'''
df.B[df.A>4]=0#把A列中值大于0的行的B属性改为0
df.loc['20130101','D']=2222#改对应值为2222
df.loc['20130101','C']=np.nan#改对应值为空
print(df)
''' A B C D
2013-01-01 0 1 NaN 2222
2013-01-02 4 5 6.0 7
2013-01-03 8 0 10.0 11
2013-01-04 12 0 14.0 15
2013-01-05 16 0 18.0 19
2013-01-06 20 0 22.0 23
'''
print('\n\n\nPart3空值:dropna删掉空行列,isnull判空值,fillna给空值赋值')
dates = pd.date_range('20130101', periods=6)
df = pd.DataFrame(np.arange(24).reshape((6,4)),index=dates, columns=['A','B','C','D'])
df.iloc[0,0]=np.nan
print(df.dropna(axis=0,how='any'))#该行存在空值就删去这行,即2013-01-01这行
''' A B C D
2013-01-02 4.0 5 6 7
2013-01-03 8.0 9 10 11
2013-01-04 12.0 13 14 15
2013-01-05 16.0 17 18 19
2013-01-06 20.0 21 22 23
'''
df.loc[:,'D']=np.nan
print(df.dropna(axis=1,how='all'))#该列全空值就删掉
''' A B C
2013-01-01 NaN 1 2
2013-01-02 4.0 5 6
2013-01-03 8.0 9 10
2013-01-04 12.0 13 14
2013-01-05 16.0 17 18
2013-01-06 20.0 21 22
'''
print(df.isnull())#是否空值
''' A B C D
2013-01-01 True False False True
2013-01-02 False False False True
2013-01-03 False False False True
2013-01-04 False False False True
2013-01-05 False False False True
2013-01-06 False False False True
'''
print(df.fillna(333))#把空值赋为333
''' A B C D
2013-01-01 333.0 1 2 333.0
2013-01-02 4.0 5 6 333.0
2013-01-03 8.0 9 10 333.0
2013-01-04 12.0 13 14 333.0
2013-01-05 16.0 17 18 333.0
2013-01-06 20.0 21 22 333.0
'''
print(np.any(df.isnull())==True)#True,是否存在空值,注意这里df直接传给np.any
print('\n\n\nPart4合并:concat合并')
df1 = pd.DataFrame(np.ones((3,4))*0, columns=['a','b','c','d'])
df2 = pd.DataFrame(np.ones((3,4))*1, columns=['a','b','c','d'])
df3 = pd.DataFrame(np.ones((3,4))*2, columns=['a','b','c','d'])
print(pd.concat([df1, df2, df3], axis=0))#concat纵向合并
''' a b c d
0 0.0 0.0 0.0 0.0
1 0.0 0.0 0.0 0.0
2 0.0 0.0 0.0 0.0
0 1.0 1.0 1.0 1.0
1 1.0 1.0 1.0 1.0
2 1.0 1.0 1.0 1.0
0 2.0 2.0 2.0 2.0
1 2.0 2.0 2.0 2.0
2 2.0 2.0 2.0 2.0
'''
print(pd.concat([df1, df2, df3], axis=0, ignore_index=True))#统一索引
''' a b c d
0 0.0 0.0 0.0 0.0
1 0.0 0.0 0.0 0.0
2 0.0 0.0 0.0 0.0
3 1.0 1.0 1.0 1.0
4 1.0 1.0 1.0 1.0
5 1.0 1.0 1.0 1.0
6 2.0 2.0 2.0 2.0
7 2.0 2.0 2.0 2.0
8 2.0 2.0 2.0 2.0
'''
df1 = pd.DataFrame(np.ones((3,4))*0, columns=['a','b','c','d'], index=[1,2,3])
df2 = pd.DataFrame(np.ones((3,4))*1, columns=['b','c','d','e'], index=[2,3,4])
print(pd.concat([df1, df2], axis=0))#纵向"外"合并(默认是外)
# a b c d e
# 1 0.0 0.0 0.0 0.0 NaN
# 2 0.0 0.0 0.0 0.0 NaN
# 3 0.0 0.0 0.0 0.0 NaN
# 2 NaN 1.0 1.0 1.0 1.0
# 3 NaN 1.0 1.0 1.0 1.0
# 4 NaN 1.0 1.0 1.0 1.0
print(pd.concat([df1, df2], axis=0, join='inner'))#纵向"内"合并
# b c d
# 1 0.0 0.0 0.0
# 2 0.0 0.0 0.0
# 3 0.0 0.0 0.0
# 2 1.0 1.0 1.0
# 3 1.0 1.0 1.0
# 4 1.0 1.0 1.0
print('\n\n\nPart5合并:append合并')
df1 = pd.DataFrame(np.ones((3,4))*0, columns=['a','b','c','d'])
df2 = pd.DataFrame(np.ones((3,4))*1, columns=['a','b','c','d'])
df3 = pd.DataFrame(np.ones((3,4))*1, columns=['a','b','c','d'])
s1 = pd.Series([1,2,3,4], index=['a','b','c','d'])
print(df1.append(df2, ignore_index=True))#将df2合并到df1的下面及重置index(只有纵向)
# a b c d
# 0 0.0 0.0 0.0 0.0
# 1 0.0 0.0 0.0 0.0
# 2 0.0 0.0 0.0 0.0
# 3 1.0 1.0 1.0 1.0
# 4 1.0 1.0 1.0 1.0
# 5 1.0 1.0 1.0 1.0
print(df1.append([df2,df3],ignore_index=True))#将df2与df3合并至df1的下面及重置index
# a b c d
# 0 0.0 0.0 0.0 0.0
# 1 0.0 0.0 0.0 0.0
# 2 0.0 0.0 0.0 0.0
# 3 1.0 1.0 1.0 1.0
# 4 1.0 1.0 1.0 1.0
# 5 1.0 1.0 1.0 1.0
# 6 1.0 1.0 1.0 1.0
# 7 1.0 1.0 1.0 1.0
# 8 1.0 1.0 1.0 1.0
print(df1.append(s1, ignore_index=True))#将s1合并至df1及重置index
# a b c d
# 0 0.0 0.0 0.0 0.0
# 1 0.0 0.0 0.0 0.0
# 2 0.0 0.0 0.0 0.0
# 3 1.0 2.0 3.0 4.0
print('\n\n\nPart6合并:merge合并')
left=pd.DataFrame({'key':['K0','K1','K2','K3'],'A':['A0','A1','A2','A3'],'B':['B0','B1','B2','B3']})
right=pd.DataFrame({'key':['K0','K1','K2','K3'],'C':['C0','C1','C2','C3'],'D':['D0','D1','D2','D3']})
print(left)#左表
# A B key
# 0 A0 B0 K0
# 1 A1 B1 K1
# 2 A2 B2 K2
# 3 A3 B3 K3
print(right)#右表
# C D key
# 0 C0 D0 K0
# 1 C1 D1 K1
# 2 C2 D2 K2
# 3 C3 D3 K3
print(pd.merge(left, right, on='key'))#取关键字相同的行右右连接
# A B key C D
# 0 A0 B0 K0 C0 D0
# 1 A1 B1 K1 C1 D1
# 2 A2 B2 K2 C2 D2
# 3 A3 B3 K3 C3 D3
left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
print(pd.merge(left,right,on=['key1','key2'],how='inner'))#内连
# A B key1 key2 C D
# 0 A0 B0 K0 K0 C0 D0
# 1 A2 B2 K1 K0 C1 D1
# 2 A2 B2 K1 K0 C2 D2
print(pd.merge(left,right,on=['key1','key2'],how='outer'))#外连
# A B key1 key2 C D
# 0 A0 B0 K0 K0 C0 D0
# 1 A1 B1 K0 K1 NaN NaN
# 2 A2 B2 K1 K0 C1 D1
# 3 A2 B2 K1 K0 C2 D2
# 4 A3 B3 K2 K1 NaN NaN
# 5 NaN NaN K2 K0 C3 D3
print(pd.merge(left,right,on=['key1','key2'],how='left'))#左连
# A B key1 key2 C D
# 0 A0 B0 K0 K0 C0 D0
# 1 A1 B1 K0 K1 NaN NaN
# 2 A2 B2 K1 K0 C1 D1
# 3 A2 B2 K1 K0 C2 D2
# 4 A3 B3 K2 K1 NaN NaN
print(pd.merge(left,right,on=['key1','key2'],how='right'))#右连
# A B key1 key2 C D
# 0 A0 B0 K0 K0 C0 D0
# 1 A2 B2 K1 K0 C1 D1
# 2 A2 B2 K1 K0 C2 D2
# 3 NaN NaN K2 K0 C3 D3
df1 = pd.DataFrame({'col1':[0,1], 'col_left':['a','b']})
df2 = pd.DataFrame({'col1':[1,2,2],'col_right':[2,2,2]})
print(pd.merge(df1, df2, on='col1', how='outer', indicator=True))#启用显式会自动生成一列表示生成方式
# col1 col_left col_right _merge
# 0 0.0 a NaN left_only
# 1 1.0 b 2.0 both
# 2 2.0 NaN 2.0 right_only
# 3 2.0 NaN 2.0 right_only
print(pd.merge(df1, df2, on='col1', how='outer', indicator='indicator_column'))#同上,只是只定义列名
# col1 col_left col_right indicator_column
# 0 0.0 a NaN left_only
# 1 1.0 b 2.0 both
# 2 2.0 NaN 2.0 right_only
# 3 2.0 NaN 2.0 right_only
left = pd.DataFrame({'A':['A0','A1','A2'],'B':['B0','B1','B2']},index=['K0','K1','K2'])
right = pd.DataFrame({'C':['C0','C2','C3'],'D':['D0','D2','D3']},index=['K0','K2','K3'])
print(pd.merge(left, right, left_index=True, right_index=True, how='outer'))#用index合并
# A B C D
# K0 A0 B0 C0 D0
# K1 A1 B1 NaN NaN
# K2 A2 B2 C2 D2
# K3 NaN NaN C3 D3
print(pd.merge(left, right, left_index=True, right_index=True, how='inner'))#用index合并
# A B C D
# K0 A0 B0 C0 D0
# K2 A2 B2 C2 D2
boys = pd.DataFrame({'k': ['K0', 'K1', 'K2'], 'age': [1, 2, 3]})
girls = pd.DataFrame({'k': ['K0', 'K0', 'K3'], 'age': [4, 5, 6]})
print(pd.merge(boys, girls, on='k', suffixes=['_boy', '_girl'], how='inner'))#suffixes解决同名属性问题
# age_boy k age_girl
# 0 1 K0 4
# 1 1 K0 5
#第二十三章torch
#例一:线性回归
import torch
x_data=torch.Tensor([[1.0],[2.0],[3.0]])#已知样本输入
y_data=torch.Tensor([[2.0],[4.0],[6.0]])#已知样本输出
class myModel(torch.nn.Module):
def __init__(self):
super(myModel,self).__init__()
self.linear=torch.nn.Linear(1,1)
def forward(self,x):
return self.linear(x)
cal_model=myModel()#创建类对象建立计算模型cal_model
criterion=torch.nn.MSELoss(reduction='sum')#损失函数
optimizer=torch.optim.SGD(cal_model.parameters(),lr=0.01)#为cal_model参数建立优化器,学习率0.01
for epoch in range(500):#循环训练500次
y_pred=cal_model(x_data)#利用创建好的模型求预测值
loss=criterion(y_pred,y_data)#计算误差
loss.backward()#计算梯度误差
optimizer.step()#用误差乘以学习率来更新权值
optimizer.zero_grad()#梯度清0
print(cal_model.linear.weight.item(),cal_model.linear.bias.item())#斜率1.98 偏置0.02
#例二:逻辑回归(对比线性其实就改了四处)
import torch
x_data=torch.Tensor([[1.0],[2.0],[3.0]])
y_data=torch.Tensor([[0],[0],[1]])#第一,不是预测值,而是分类
class myLogisticRegressionModel(torch.nn.Module):
def __init__(self):
super(myLogisticRegressionModel,self).__init__()
self.linear=torch.nn.Linear(1,1)
def forward(self,x):
y_pred=torch.sigmoid(self.linear(x))#第二,线性基础上加torch..nn.functional.sigmoid,即1/(1+exp(-x))
return y_pred
model=myLogisticRegressionModel()
criterion=torch.nn.BCELoss(reduction='sum')#第三,改用BCE损失
optimizer=torch.optim.SGD(model.parameters(),lr=0.01)
for epoch in range(10000):
y_pred=model(x_data)
loss=criterion(y_pred,y_data)
optimizer.zero_grad()
loss.backward()
optimizer.step()
import numpy as np#第四、画图观看结果
import matplotlib.pyplot as plt
x=np.linspace(0,10,200)#得到1到10的200个均分点
x_t=torch.Tensor(x).view((200,1))#其实就是reshape成200个一维输入
y_t=model(x_t)#得到200个一维输出
y=y_t.data.numpy()#tensor原来还能这么转成numpy,得到200个numpy输出
plt.plot(x,y)
plt.plot([0,10],[0.5,0.5],c='r')
plt.xlabel('hours')
plt.ylabel('probability of pass')
plt.grid()
plt.show()#1/(1+exp(-y))中的y=kx+b,就是sigmoid在X轴方向平移拉伸!这是逻辑回归的根本!
#下面补充说明张量的view用法
import numpy as np
import torch
a=torch.randn(3,4,5,7)
b = a.view(1,-1)
c = a.view(2,-1)
print(b.size(),c.size())#torch.Size([1, 420]) torch.Size([2, 210])
#例三:多维输入(就是建立模型那里改了一下,逐步降维,多了几层线性)
import torch
import numpy as np
xy = np.loadtxt('./dataset/diabetes.csv.gz', delimiter=',', dtype=np.float32)
x_data = torch.from_numpy(xy[:,:-1])#Size([759, 8])
y_data = torch.from_numpy(xy[:, [-1]])#Size([759, 1]
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(8, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x): #
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
model = Model()
criterion = torch.nn.BCELoss(size_average=True)
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
for epoch in range(100):
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
print(epoch, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
'''
优化器
torch.optim.SGD:随机梯度下降Stochastic Gradient Descent,每次迭代使用一个样本来对参数进行更新,克服鞍点
BGD:批量梯度下降Batch Gradient Descent,每次迭代使用全部样本来对参数进行更新,速度快
MBGD:小批量梯度下降Mini-Batch Gradient Descent,每次迭代使用batch_size个样本来对参数进行更新
Momentum冲量:修正时算上上一次的梯度乘以衰减权重
Nesterov Momentum牛顿冲量:求梯度时是对(误差-上一次修正值*误减权重)求导
torch.optim.Adagrad:在训练中自动的对learning rate进行调整,非常适合处理稀疏数据。
Adagrad对于出现频率较低参数采用较大的α更新;对于出现频率较高的参数采用较小的α更新。
torch.optim.RMSprop:
对比Adagrad会累加之前所有梯度平方,RMSprop仅计算对应平均值,缓解Adagrad算法学习率下降较快的问题
torch.optim.Adam:利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。
Adam的优点主要在于经过偏置校正后,每一次迭代学习率都有个确定范围,使得参数比较平稳。
Adam全称:Adaptive Moment Estimation
torch.optim.Adamax:如图操作,又多了一个Ut修正
torch.optim.ASGD:延迟补偿异步随机梯度下降Asynchronous Stochastic Gradient Descent with Delay Compensation
torch.optim.LBFGS:如图操作,原理是牛顿法求驻点(泰勒展开)
torch.optim.Rprop:为各权重设定变化加速因子与减速因子。
在网络前馈迭代中当连续误差梯度符号不变时用加速策略加快训练速度;当连续误差梯度符号变化时用减速策略稳定收敛。
网络结合当前误差梯度符号与变化步长实现BP,同时,为了避免网络学习发生振荡或下溢,算法要求设定权重变化上下限。
损失函数
第一部分:主要用于回归预测
torch.nn.MSELoss:均方误差损失,即误差平方和均值
torch.nn.L1Loss:L1范数损失,即绝对值差
第二部分:用于多分类:softmax~log~NLL
torch.nn.CrossEntropyLoss:log_softmax() + NLLLoss()
补充参数一 weight:给每一个类别设置的权重,是一个一维向量,长度是C(C就是类别数)
补充参数二 ignore_index:整数索引值,指定target哪些值不计算,不用梯度更新,不参与误差平均值计算
softmax函数又称为归一化指数函数,它可以把一个多维向量压缩在(0,1)之间,并且它们的和为1,见图
torch.nn.NLLLoss:就是把softmax的输出与Label对应的那个值拿出来,再去掉负号,再求均值
第三部分:用于二分类:sigmoid~-∑(Y×lny+(1−Y)×ln(1−y)),含多标签二分类(即成人/小孩,男/女多个二分)
torch.nn.BCEWithLogitsLoss:sigmoid+BCELoss
torch.nn.BCELoss:-∑(Y×lny+(1−Y)×ln(1−y)),其中Y是标签,y是预测概率(线性预测后sigmoid而来)
补充参数一 weight:为每一个batch设置的权重,是一个长度等于batch的个数一维向量
'''
#softmax
import math
z = [1.0, 2.0, 3.0, 4.0, 1.0, 2.0, 3.0]
z_exp = [math.exp(i) for i in z] #[2.72, 7.39, 20.09, 54.6, 2.72, 7.39, 20.09]
sum_z_exp = sum(z_exp) #114.98,下面的round是四舍五入,两位小数
print([round(i/sum_z_exp,2)for i in z_exp])#Result[0.02,0.06,0.17,0.47,0.02,0.06,0.17]
#log_softmax
#log_softmax是指在softmax函数基础上,再进行一次log运算,softemax计算式子可见文末的图清晰理解。
#此时结果有正有负,log函数的值域是负无穷到正无穷,当x在0—1之间的时候,log(x)值在负无穷到0之间。
#nn.NLLLoss
#nn.NLLLoss是把上面的输出与Label对应的那个值拿出来,再去掉负号,再求均值
#如下面标签是[0,1,2],第一行取第0个元素,第二行取第1个,第三行取第2个,去掉负号求均值,得损失值。
import torch
inputs=torch.randn(3,3) #随机生成3x3矩阵
mySoftmax=torch.nn.Softmax(dim=1) #建立Softmax模型
softval=torch.log(mySoftmax(inputs)) #计算Softmax模型输出
loss1=torch.nn.NLLLoss() #建立NLL模型
loss2=torch.nn.CrossEntropyLoss() #建立交叉熵模型
target=torch.tensor([0,1,2]) #生成样本标签
print(abs(softval[0][0]+softval[1][1]+softval[2][2])/3)
print(loss1(softval,target))
print(loss2(inputs,target))
#最后三个print输出的值是一样的
'''
损失函数传入的三个参数:
参数一:
size_average:默认True情况,如只一个batch每个batch多元素,误差计算结果是这个batch中多个元素的平均值;
如有多个batch每个batch有多元素,那么误差计算的结果是将每个batch的平均值放到一块再求多个batch的平均值。
把这个参数设置为False,那么只需要将计算平均值换成计算和即可,其他完全一样;
但是如果 reduce参数被指定为False,那么这个参数将被忽略,也即不起作用。
参数二:
reduce:默认True情况下,计算结果形式由size_average决定,要么均值要么求和,返回标量
False不求平均也不求和,把每个batch,batch每个元素计算结果直接列,也即返回的是个向量
参数三:
reduction:可以有三种取值,"none","mean","sum",默认值是"mean"。
"none",则既求平均,也不求和,返回的是向量;等价于reduce=False,size_average无效
"sum",则计算的是和,返回的是标量; 等价于reduce=True,size_average=False
"mean",则计算的是均值,返回的是标量;等价于reduce=True,size_average=True
具体见下例:'''
import torch
from torch import nn
loss1 = nn.L1Loss(reduction="none")
loss2 = nn.L1Loss(reduction="mean")
loss3 = nn.L1Loss(reduction="sum")
inputs = torch.tensor(([1.,2.,3.],[4.,5.,6.]))
target = torch.tensor(([3.,2.,1.],[8.,5.,2.]))
output1 = loss1(inputs, target)#直接求对应差值
output2 = loss2(inputs, target)#(4/3+8/3)/2=4/2=2
output3 = loss3(inputs, target)#4+8=12
print(output1,output2,output3)
#tensor([[2.,0.,2.],[4.,0.,4.]]) tensor(2.) tensor(12.)
#例四、卷积神经网络
#卷积实现
import torch
#(一)创建数组转成张量得输入层(batch批量维度,channel通道维度,长,宽)
input = [3,4,6,5,7, 2,4,6,8,2, 1,6,7,8,4, 9,7,4,6,2, 3,7,5,4,1]
input = torch.Tensor(input).view(1, 1, 5, 5)
#(二)创建卷积层(输出通道数1,输入通道数1,卷积核大小3,不改变长宽,无偏置)
conv_layer = torch.nn.Conv2d(1, 1, kernel_size=3, padding=1, bias=False)
#(三)创建卷积核张量(输出通道数,输入通道数,长,宽)
kernel = torch.Tensor([1,2,3,4,5,6,7,8,9]).view(1, 1, 3, 3)#先创建张量
conv_layer.weight.data = kernel.data#再把上面张量即卷积核赋给卷积层的权重
#(四)计算卷积
output = conv_layer(input)
print(output)#依然是5x5
'''
tensor([[[[ 91., 168., 224., 215., 127.],
[114., 211., 295., 262., 149.],
[192., 259., 282., 214., 122.],
[194., 251., 253., 169., 86.],
[ 96., 112., 110., 68., 31.]]]],grad_fn=)
'''
#然后我把padding改成步长为2
input = [3,4,6,5,7, 2,4,6,8,2, 1,6,7,8,4, 9,7,4,6,2, 3,7,5,4,1]
input = torch.Tensor(input).view(1, 1, 5, 5)
conv_layer = torch.nn.Conv2d(1, 1, kernel_size=3, stride=2, bias=False)
kernel = torch.Tensor([1,2,3,4,5,6,7,8,9]).view(1, 1, 3, 3)
conv_layer.weight.data = kernel.data
output = conv_layer(input)
print(output)#果然只有 2x2
'''
tensor([[[[211., 262.],
[251., 169.]]]], grad_fn=)
'''
#池化实现
import torch
input = [3,4,6,5, 2,4,6,8, 1,6,7,8, 9,7,4,6, ]
input = torch.Tensor(input).view(1, 1, 4, 4)
maxpooling_layer = torch.nn.MaxPool2d(kernel_size=2)#最大池化,尺寸必缩小
output = maxpooling_layer(input)
print(output)#算子核size是2则步长也是2
'''
tensor([[[[4., 8.],
[9., 8.]]]])
'''
#卷积神经网络实现
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
batch_size = 64
transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.1307, ), (0.3081, )) ])
train_dataset = datasets.MNIST(root='./dataset/mnist/', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = datasets.MNIST(root='./dataset/mnist/', train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)
class Net(torch.nn.Module):#其实也就是建立模型时调用语句改一下,
def __init__(self):
super(Net,self).__init__()
self.conv1=torch.nn.Conv2d(1,10,kernel_size=5)
self.conv2=torch.nn.Conv2d(10,20,kernel_size=5)
self.pooling=torch.nn.MaxPool2d(2)
self.fc=torch.nn.Linear(320,10)
def forward(self,x):
batch_size=x.size(0)
x=F.relu(self.pooling(self.conv1(x)))
x=F.relu(self.pooling(self.conv2(x)))
x=x.view(batch_size,-1)
x=self.fc(x)
return x
model = Net()
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
inputs, target = inputs.to(device),target.to(device)
optimizer.zero_grad()
# forward + backward + update
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))
running_loss = 0.0
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
images, labels = images.to(device),labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy on test set: %d %%' % (100 * correct / total))
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test()
#例五、循环神经网络
#RNN神经元
import torch
batch_size = 1#每个batch的大小是1
seq_len = 3#连续样本3个
input_size = 4#每个样本维度即输入维度是4
hidden_size = 2#隐藏层维度即输出维度是2
#一、建RNN神经元:Hi=(Wh*Hi-1+Bh+Wx*Xi-1+Bx),仅需知道输入输出维度!
cell = torch.nn.RNNCell(input_size=input_size, hidden_size=hidden_size)
print(cell,type(cell))#RNNCell(4, 2)
#二、初始化输入数据
dataset = torch.randn(seq_len, batch_size, input_size)#三样本,一批次,四维度
print(dataset,type(dataset)) #
'''
tensor([[[ 1.0752, 1.1479, -1.1661, -1.3619]],
[[-2.6396, -1.4944, -0.9441, 0.9037]],
[[-0.3176, -0.2014, 1.0491, 0.3992]]])
'''
#三、初始化权重为0
hidden = torch.zeros(batch_size, hidden_size)#一批次,二维度
print(hidden,type(hidden))#tensor([[0., 0.]])
#四、执行若干次cell运算
for idx, input in enumerate(dataset):
#print('=' * 20, idx, '=' * 20)
#print('Input size: ', input.shape)
#print('outputs size: ', hidden.shape)
hidden = cell(input, hidden)
print(hidden)
#RNN网络前向
import torch
batch_size = 1#每批次训练使用1个数据样本
seq_len = 3#输出序列长度是3
input_size = 4#每个样本输入维度是4
hidden_size = 2#隐藏维度及输出维度是2
num_layers = 1#RNN的一共1层
#一、建RNN,输入维度,输出维度,得到了个RNN网络类的对象
cell = torch.nn.RNN(input_size=input_size, hidden_size=hidden_size,num_layers=num_layers)
#二、初始化输入样本,序列长3,每批次1,输入维度4,其实就是一个1x3x4的张量
inputs = torch.randn(seq_len, batch_size, input_size)
#三、初始化隐藏权值,RNN共1层,每批次1,输出维度2,其实就是一个1x1x2的张量
hidden = torch.zeros(num_layers, batch_size, hidden_size)
#四、执行一次cell就是前向计算一次
out, hidden = cell(inputs, hidden)
#RNN由hello生成ohlol的RNNCell写法
import torch
input_size = 4#输入维度4
hidden_size = 4#输出维度4
batch_size = 1#每批次训练1个样本
idx2char = ['e', 'h', 'l', 'o']#字典
x_data = [1, 0, 2, 2, 3]#hello
y_data = [3, 1, 2, 3, 2]#ohlol
one_hot_lookup = [[1, 0, 0, 0],[0, 1, 0, 0],[0, 0, 1, 0],[0, 0, 0, 1]]#四种字母打成一维01表示
x_one_hot = [one_hot_lookup[x] for x in x_data]#得出输入的样本序列如下
print(x_one_hot)#[[0, 1, 0, 0], [1, 0, 0, 0], [0, 0, 1, 0], [0, 0, 1, 0], [0, 0, 0, 1]]
inputs = torch.Tensor(x_one_hot).view(-1, batch_size, input_size)#把样本序列变张量
print(inputs.shape)#torch.Size([5, 1, 4]),序列长5,每批次训练1个序列,每个序列中的样本是4维
labels = torch.LongTensor(y_data).view(-1, 1)#得出标签,这里未化成one_hot
print(labels.shape)#torch.Size([5, 1]),序列长5,每批次1个序列
class Model(torch.nn.Module):
def __init__(self, input_size, hidden_size, batch_size):
super(Model, self).__init__()
self.batch_size = batch_size#外部变量传进来
self.input_size = input_size#外部变量传进来
self.hidden_size = hidden_size#外部变量传进来
self.rnncell = torch.nn.RNNCell(input_size=self.input_size,hidden_size=self.hidden_size)#建立细胞
def forward(self, input, hidden):#前向计算
hidden = self.rnncell(input, hidden)
return hidden
def init_hidden(self):#求h0
return torch.zeros(self.batch_size, self.hidden_size)#batch_size就构造h0时用到
net = Model(input_size, hidden_size, batch_size)#构造模型实例
criterion = torch.nn.CrossEntropyLoss()#代价函数
optimizer = torch.optim.Adam(net.parameters(), lr=0.1)#优化器
for epoch in range(15):
loss = 0#15遍每遍开始时先清0
optimizer.zero_grad()#优化器梯度清0
hidden = net.init_hidden()#初始化H0
print('Predicted string: ', end='')
for input, label in zip(inputs, labels):
hidden = net(input, hidden)#跑一次RNNCELL
loss += criterion(hidden, label)#序列长5,所以是5次的代价累加(同一个细胞用五次)
_, idx = hidden.max(dim=1)#读出预测值
print(idx2char[idx.item()], end='')#输出预测值对应的字符
loss.backward()#反向求梯度
optimizer.step()#梯度修正权值
print(', Epoch [%d/15] loss=%.4f' % (epoch+1, loss.item()))
#RNN由hello生成ohlol的RNN写法(全文最重点是这一个!)
import torch
input_size = 4
hidden_size = 4
num_layers = 1
batch_size = 1
seq_len = 5
idx2char = ['e', 'h', 'l', 'o']
x_data = [1, 0, 2, 2, 3]
y_data = [3, 1, 2, 3, 2]
one_hot_lookup = [[1, 0, 0, 0],[0, 1, 0, 0],[0, 0, 1, 0],[0, 0, 0, 1]]
x_one_hot = [one_hot_lookup[x] for x in x_data]
inputs = torch.Tensor(x_one_hot).view(seq_len, batch_size, input_size)
labels = torch.LongTensor(y_data)
class Model(torch.nn.Module):
def __init__(self, input_size, hidden_size, batch_size, num_layers=1):
super(Model, self).__init__()
self.num_layers = num_layers
self.batch_size = batch_size
self.input_size = input_size
self.hidden_size = hidden_size
self.rnn = torch.nn.RNN(input_size=self.input_size,hidden_size=self.hidden_size,num_layers=num_layers)
def forward(self, input):
hidden = torch.zeros(self.num_layers,self.batch_size,self.hidden_size)
out, _ = self.rnn(input, hidden)
return out.view(-1, self.hidden_size)
net = Model(input_size, hidden_size, batch_size, num_layers)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=0.05)
for epoch in range(15):
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
_, idx = outputs.max(dim=1)
idx = idx.data.numpy()
print('Predicted: ', ''.join([idx2char[x] for x in idx]), end='')
print(', Epoch [%d/15] loss = %.3f' % (epoch + 1, loss.item()))
#第二十四章:keras(超级简单)
#线回一个神经元->非线回多个全连接层含隐藏层->CNN含卷积层池化层Dropout->RNN
#线性回归
import numpy as np
import matplotlib.pyplot as plt
from keras.models import Sequential
from keras.layers import Dense
x_data=np.random.rand(100)#生成100个随机点,默认范围0-1
noise=np.random.normal(0,0.01,x_data.shape)#范围0-0.01,形状同x_data
y_data=x_data*0.1+0.2+noise#生成Y数据
model=Sequential()#构建一个顺序模型
model.add(Dense(units=1,input_dim=1))#在模型中添加一个全连接层(输出一维,输入一维),无激活函数
model.compile(optimizer='sgd',loss='mse')#随机梯度下降,均方误差
for step in range(3001):#训练3001个批次,每次都重复使用x_data,y_data中的数据
cost=model.train_on_batch(x_data,y_data)#每次训练一个批次,随机梯度每次都更新
W,b=model.layers[0].get_weights()
print('W:',W,'b:',b)
y_pred=model.predict(x_data)#x_data输入网络中,得到预测值y_pred
plt.scatter(x_data,y_data)#显示随机离散点集:X坐标,Y坐标
plt.plot(x_data,y_pred,'r-',lw=3)#显示预测直线的点集,颜色red,线粗3
plt.show()
#非线性回归(通过添加10个隐藏层来表现)
import numpy as np
import matplotlib.pyplot as plt
import keras
x_data=np.linspace(-0.5,0.5,200)#生成200个随机点,区间[-0.5,0.5]
noise=np.random.normal(0,0.02,x_data.shape)#生成噪声
y_data=np.square(x_data)+noise#生成200个随机点对应的y点
model=keras.models.Sequential()#构建一个顺序模型
model.add(Dense(units=10,input_dim=1,activation='tanh'))#第一全连接层输入1维,输出10维,激活函数tanh
model.add(Dense(units=1,input_dim=10,activation='tanh'))#第二全连接层输入10维,输出1维,激活函数tanh
sgd=keras.optimizers.SGD(lr=0.3)#定义优化算法(learning ratio学习率改为0.3)
model.compile(optimizer=sgd,loss='mse')#随机梯度下降,均方误差
for step in range(3001):cost=model.train_on_batch(x_data,y_data)
W,b=model.layers[0].get_weights()
print('W:',W,'b:',b)
y_pred=model.predict(x_data)#x_data输入网络中,得到预测值y_pred
plt.scatter(x_data,y_data)#显示随机点:X坐标,Y坐标
plt.plot(x_data,y_pred,'r-',lw=3)#显示预测结果:X坐标,Y坐标,颜色red,线粗3
plt.show()
#CNN
import numpy as np
from keras.datasets import mnist
from keras.utils import np_utils
from keras.models import Sequential
from keras.layers import Dense,Dropout,Convolution2D,MaxPooling2D,Flatten#二维卷积,二维池化,扁平化
from keras.optimizers import Adam
(x_train,y_train),(x_test,y_test)=mnist.load_data()#载入数据
x_train=x_train.reshape(-1,28,28,1)/255.0#(60000,28,28)->(60000,28,28,1)
x_test=x_test.reshape(-1,28,28,1)/255.0#shape0就是60000,-1自动计算28*28
y_train=np_utils.to_categorical(y_train,num_classes=10)#换one hot格式:把输出训练成10个类
y_test=np_utils.to_categorical(y_test,num_classes=10)
model=Sequential()#定义顺序模型
model.add(Convolution2D( #第一个卷积层
input_shape=(28,28,1), #输入平面
filters=32, #卷积核/滤波器个数
kernel_size=5, #卷积窗口大小
strides=1, #步长
padding='same', #扩充边缘以备卷积
activation='relu' #激活函数
))
model.add(MaxPooling2D( #第一个池化层
pool_size=2, #池化尺寸
strides=2, #步长,池化后由28X28变成了14X14
padding='same' #扩充边缘以备卷积
))
model.add(Convolution2D(64,5,strides=1,padding='same',activation='relu'))#第二个卷积层
model.add(MaxPooling2D(2,2,'same'))#第二个池化层变成了7X7
model.add(Flatten())#扁平化64个特征图,每个图都是7X7,一共有64*7*7这么多个一维的数据
model.add(Dense(1024,activation='relu'))#第一个全连接层,上面的3136与当前1024是全连接的
model.add(Dropout(0.5))#训练时50%的神经元不工作,或者说每个神经元有50%概率不工作
model.add(Dense(10,activation='softmax'))#第二个全连接层,10个分类(0~9)
adam=Adam(lr=1e-4)#定义优化器,下面一句是优化策略,损失估计,训练时也计算准确率
model.compile(optimizer=adam,loss='categorical_crossentropy',metrics=['accuracy'])
model.fit(x_train,y_train,batch_size=64,epochs=1)#训练,每组取64个数据,取1个周期
loss,accuracy=model.evaluate(x_test,y_test)#评估模型
print('test loss',loss,'accuracy',accuracy)
'''fit与evaluate的两个过程是有输出同步显示的
Epoch 1/1
60000/60000 [==============================] - 86s 1ms/step - loss: 0.3331 - acc: 0.9067
10000/10000 [==============================] - 5s 473us/step
test loss 0.08374340096265077 accuracy 0.9734
'''
from keras.datasets import mnist
from keras.utils import np_utils
from keras.models import Sequential
from keras.layers import Dense
from keras.layers.recurrent import SimpleRNN
from keras.optimizers import Adam
input_size=28#数据长度-一次x输入向量是28维
time_steps=28#序列长度-一串序列输入28个x
cell_size=50#隐藏层cell个数
(x_train,y_train),(x_test,y_test)=mnist.load_data()#载入数据形状是(60000,28,28),如是(60000,784)要先展开
x_train=x_train/255.0 #shape0就是60000,-1自动计算28*28
x_test=x_test/255.0
y_train=np_utils.to_categorical(y_train,num_classes=10) #换one hot格式:把输出训练成10个类
y_test=np_utils.to_categorical(y_test,num_classes=10)
model=Sequential()
model.add(SimpleRNN(units=50,input_shape=(28,28)))#循环神经网络就这么一句话
model.add(Dense(10,activation='softmax'))#再加一个全连接层输出十维即0~9
adam=Adam(lr=1e-4)#优化器
model.compile(optimizer=adam,loss='categorical_crossentropy',metrics=['accuracy'])
model.fit(x_train,y_train,batch_size=64,epochs=3)#训练
loss,accuracy=model.evaluate(x_test,y_test)#评估
print('\ntest loss',loss,'accuracy',accuracy)#输出
#最后解释一下to_categorical的作用
b = [0,1,2,3,4,5,6,7,8]#类别向量定义
b = np_utils.to_categorical(b, 9)#调用to_categorical将b按照9个类别来进行转换
print(b)
'''
[[1. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 1. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 1. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 1. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 1. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 1. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 1. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 1. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 1.]]
'''
#第二十五章:tensorflow
#主要优势是有tensorboard可视化
#下面所有的name_scope就是定义框图元素
#本章三例都是用MNIST的样本来做多分类模型训练,输入784维,输出10维
#例一:常规方法
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist=input_data.read_data_sets("MNIST_data",one_hot=True)
with tf.name_scope('input'):#输入向量维度及标签
x=tf.placeholder(tf.float32,[None,784],name='x-input')
y=tf.placeholder(tf.float32,[None,10],name='y-input')
with tf.name_scope('layer'):#权重,偏置,模型式子xW+b,激活函数
with tf.name_scope('wights'):
W=tf.Variable(tf.truncated_normal([784,10],stddev=0.1))
with tf.name_scope('biases'):
b=tf.Variable(tf.zeros([10])+0.1)
with tf.name_scope('wx_plus_b'):
wx_plus_b=tf.matmul(x,W)+b
with tf.name_scope('softmax'):
y_=tf.nn.softmax(wx_plus_b)
with tf.name_scope('loss'):#损失函数,优化器,准确率
loss=tf.losses.mean_squared_error(y,y_)
with tf.name_scope('train'):
train=tf.train.GradientDescentOptimizer(0.3).minimize(loss)
with tf.name_scope('accuracy'):
with tf.name_scope('correct_prediction'):
correct_prediction=tf.equal(tf.argmax(y,1),tf.arg_max(y_,1))
with tf.name_scope('accuracy'):
accuracy=tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
with tf.Session() as sess:
tf.global_variables_initializer().run()#初始化模型
writer=tf.summary.FileWriter('logs/',sess.graph)#生成日志文件用tensorboard观察
for i in range(1000):
batch_xs,batch_ys=mnist.train.next_batch(100)#读取样本数据100个
sess.run(train,feed_dict={x:batch_xs,y:batch_ys})#运行模型
acc=sess.run(accuracy,feed_dict={x:mnist.test.images,y:mnist.test.labels})#计算正确率
print("Iter "+ str(i)+ ".Testing Accuracy " + str(acc))#输出
#例二:CNN
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist=input_data.read_data_sets("MNIST_data",one_hot=True)
batch_size=64 #每个批次大小
n_batch=mnist.train.num_examples//batch_size #一共859批
x=tf.placeholder(tf.float32,[None,784]) #输入层28x28
y=tf.placeholder(tf.float32,[None,10]) #输出层
def weight_variable(shape): #传入shape生成权值
initial=tf.truncated_normal(shape,stddev=0.1) #形状同shpae,方差为0.1的截断张量(从正态分布片段中输出随机数值)
return tf.Variable(initial) #返回一个tf变量
def bias_variable(shape): #传入shpae生成偏置
initial=tf.constant(0.1,shape=shape) #形状同shape,初始值为常量0.1
return tf.Variable(initial) #返回一个tf变量
def conv2d(x,W): #卷积层生成函数
return tf.nn.conv2d(x,W,strides=[1,1,1,1],padding='SAME')
#x input tensor of shape=[batch,height,width,channels]
#W filter/kernel tensor of shape [filter_height,filter_width,in_channels,out_channels]
#strides[0]=strides[3]=1,strides[1]代表x方向步长,strides[2]代表y方向步长
#padding:A string from 'SAME','VALID'
#现代神经网络与LeNET-5不同之处在于第一个池化层到第二个卷积层可以全映射
#总权值个数就是filter_height*filter_width*in_channels*out_channels
def max_pool_2x2(x): #池化层生成函数,ksize[1,x,y,1]
return tf.nn.max_pool(x,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
x_image=tf.reshape(x,[-1,28,28,1])#把x变为合适的4D输入格式[batch(-1自动匹配),height,width,channels]
#初始化第一个卷积层的权值和偏置,并得到第一个卷积层,第一个池化层
w_conv1=weight_variable([5,5,1,32]) #5x5采样窗口,32个卷积核从一个平面抽取特征
b_conv1=bias_variable([32]) #每个卷积核个偏置值
h_conv1=tf.nn.relu(conv2d(x_image,w_conv1)+b_conv1) #把x_image和权值向量进行卷积,加上偏置值,应用于relu激活函数
h_pool1=max_pool_2x2(h_conv1) #生成第一个池化层
#初始化第二个卷积层的权值和偏置,并得到第二个卷积层,第二个池化层
W_conv2=weight_variable([5,5,32,64]) #5x5采样窗口,输入通道32,输出通道64
b_conv2=bias_variable([64]) #每个卷积核个偏置值
h_conv2=tf.nn.relu(conv2d(h_pool1,W_conv2)+b_conv2) #生成第二个卷积层
h_pool2=max_pool_2x2(h_conv2) #生成第二个池化层
#28x28图片第一次卷积后还是28x28,第一次池化后变成14x14,第二次卷积后是14x14,第二次池化后是7x7,至此得到64张7x7平面
w_fc1=weight_variable([7*7*64,1024]) #初始化第一个全连接层的权值,7x7x64输入,1024个输出
b_fc1=bias_variable([1024]) #初始化第一个全连接层的偏置
h_pool2_flat=tf.reshape(h_pool2,[-1,7*7*64]) #池化尾2的输出扁平化为1维
h_fc1=tf.nn.relu(tf.matmul(h_pool2_flat,w_fc1)+b_fc1) #求第一个全连接层的输出
keep_prob=tf.placeholder(tf.float32) #生成一个张量
h_fc1_drop=tf.nn.dropout(h_fc1,keep_prob) #表示每次操作中每个神经元保持有效的概率
w_fc2=weight_variable([1024,10])#初始化第二个全连接层权值
b_fc2=bias_variable([10])##初始化第二个全连接层偏置
prediction=tf.nn.softmax(tf.matmul(h_fc1_drop,w_fc2)+b_fc2) #计算输出
cross_entropy=tf.losses.softmax_cross_entropy(y,prediction) #交叉熵代价函数
train_step=tf.train.AdamOptimizer(1e-4).minimize(cross_entropy) #利用Adam最小化交叉熵训练权值
correct_prediction=tf.equal(tf.argmax(prediction,1),tf.argmax(y,1)) #得到结果预测(相同是1不同是0)
accuracy=tf.reduce_mean(tf.cast(correct_prediction,tf.float32)) #命中率张量(就是取平均)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for epoch in range(0,21,1):
for batch in range(0,2,1):#这里的2应换成batch_size,此处用2是为了好观察
batch_xs,batch_ys=mnist.train.next_batch(batch_size)
sess.run(train_step,feed_dict={x:batch_xs,y:batch_ys,keep_prob:0.7})
print(str(epoch)+" test accuracy %g"%accuracy.eval(feed_dict={x:mnist.test.images,y:mnist.test.labels,keep_prob:1.0}))
#例三:RNN
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist=input_data.read_data_sets("MNIST_data",one_hot=True)
n_inputs=28#输入一行,一行有28个数据
max_time=28#一共28行,图片是28*28,模拟逐行输入
lstm_size=100#隐层单元
n_classes=10#最终是十个分类
batch_size=64#自定义每个批次有64个样本
n_batch=mnist.train.num_examples#一共有多55000个批次
x=tf.placeholder(tf.float32,[None,784])#输出张量(RNN输入张量一次打入,运行时才区分时间段)
y=tf.placeholder(tf.float32,[None,10])#正确的标签
weights=tf.Variable(tf.truncated_normal([lstm_size,n_classes],stddev=0.1))#初始化权值
biases=tf.Variable(tf.constant(0.1,shape=[n_classes]))#初始化偏置值
def RNN(X,weights,biases):
inputs=tf.reshape(X,[-1,max_time,n_inputs])#批次自动,序列个数28行,序列维度28个像素/行
lstm_cell=tf.nn.rnn_cell.LSTMCell(lstm_size)#传入隐层单元个数进行训练
outputs,final_state=tf.nn.dynamic_rnn(lstm_cell,inputs,dtype=tf.float32)
#RNN输出张量,final_state[0]=cell_state当前,final_state[1]=hidden_state
results=tf.nn.softmax(tf.matmul(final_state[1],weights)+biases)#得到预测结果
return results#本例检测图片只用最后输出即=激活函数(最后一个隐藏层张量乘权值final_state[1]+偏置)
with tf.variable_scope(None, default_name="prediction") as scope:#如果没加这句命名就会默认用name_scope而出错
prediction=RNN(x,weights,biases)
loss=tf.losses.softmax_cross_entropy(y,prediction)#损失函数利用交叉熵获取
train_step=tf.train.AdamOptimizer(1e-3).minimize(loss)#利用Adam降低损失
correct_prediction=tf.equal(tf.argmax(y,1),tf.argmax(prediction,1))#预测与标签对比得到列表
accuracy=tf.reduce_mean(tf.cast(correct_prediction,tf.float32))#求得命中率
init=tf.global_variables_initializer()#变量初始化
with tf.Session() as sess:
sess.run(init)
for epoch in range(11):
for batch in range(100):#100是为了好观察,应改为n_batch
batch_xs,batch_ys=mnist.train.next_batch(batch_size)
sess.run(train_step,feed_dict={x:batch_xs,y:batch_ys})
print(batch)
print(str(epoch)+" accuracy %g"%accuracy.eval(feed_dict={x:mnist.test.images,y:mnist.test.labels}))
#第二十六章:tushare(超级简单)
import tushare as ts
pro = ts.pro_api('你的API')
df = pro.trade_cal(exchange='', start_date='20180901', end_date='20181001', fields='exchange,cal_date,is_open,pretrade_date', is_open='0')
print(df)
#https://tushare.pro/document/2,像微信小程序一样查看中文接口获取即可
#第二十七章:sk-learn
#(一)集成学习(感觉做股票预测用到sk-learn的话,大概率就是这个集成学习了,因为股票市场里有很多指标)
#例一
import numpy as np
import matplotlib.pyplot as plt
from sklearn import neighbors
from sklearn import datasets
from sklearn import tree
from sklearn.ensemble import BaggingClassifier
from sklearn.model_selection import train_test_split
iris=datasets.load_iris()
x_data=iris.data[:,:2]#此处只有两个特征来预测是为了观察后面正确率的差距
y_data=iris.target
x_train,x_test,y_train,y_test=train_test_split(x_data,y_data)
#第一个KNN方法
knn=neighbors.KNeighborsClassifier()
knn.fit(x_train,y_train)
def plot(model):
x_min,x_max=x_data[:,0].min()-1,x_data[:,0].max()+1
y_min,y_max=x_data[:,1].min()-1,x_data[:,1].max()+1
xx,yy=np.meshgrid(np.arange(x_min,x_max,0.02),#注意生成网络的shape是(220, 280)共61600个点
np.arange(y_min,y_max,0.02))#X,Y列表存的就是这61600个点的X,Y坐标
z=model.predict(np.c_[xx.ravel(),yy.ravel()])#把X,Y展平是为了代入预测函数,对每个点对行预测
#print(xx.shape,yy.shape,z.shape)#(220, 280) (220, 280) (61600,)
z=z.reshape(xx.shape)#把Z的形状变成X的形状,就是每个点的分类
#print(xx.shape,yy.shape,z.shape)#(220, 280) (220, 280) (220, 280)
cs=plt.contourf(xx,yy,z)#利用Z分类对网张进行绘制等高线操作,注意contourf函数会向下填充区域颜色
knn.fit(x_train,y_train)
plot(knn)
plt.scatter(x_data[:,0],x_data[:,1],c=y_data)#注意如果这行在上面plot函数之前将会被覆盖
plt.show()
print(knn.score(x_test,y_test))
#第二个决策树方法
dtree=tree.DecisionTreeClassifier()
dtree.fit(x_train,y_train)
plot(dtree)
plt.scatter(x_data[:,0],x_data[:,1],c=y_data)
plt.show()
print(dtree.score(x_test,y_test))
#第三个bagging_knn方法
bagging_knn=BaggingClassifier(knn,n_estimators=100)#100次随次抽样生成100个分类器
bagging_knn.fit(x_train,y_train)
plot(bagging_knn)
plt.scatter(x_data[:,0],x_data[:,1],c=y_data)
plt.show()
print(bagging_knn.score(x_test,y_test))
#第四个baggin_tree方法
bagging_tree=BaggingClassifier(dtree,n_estimators=100)#100次随次抽样生成100个分类器
bagging_tree.fit(x_train,y_train)
plot(bagging_tree)
plt.scatter(x_data[:,0],x_data[:,1],c=y_data)
plt.show()
print(bagging_tree.score(x_test,y_test))
#例二
from sklearn import tree
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
import numpy as np
import matplotlib.pyplot as plt
#导入数据并定义画图函数
from sklearn import tree
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
import numpy as np
import matplotlib.pyplot as plt
#导入数据并定义画图函数
data=np.genfromtxt('./sk-learn_data/LR-testSet2.txt',delimiter=',')
x_data=data[:,:-1]
y_data=data[:,-1]
x_train,x_test,y_train,y_test=train_test_split(x_data,y_data,test_size=0.5)#训练与测试样本各一半
def plot(model):
x_min,x_max=x_data[:,0].min()-1,x_data[:,0].max()+1
y_min,y_max=x_data[:,1].min()-1,x_data[:,1].max()+1
xx,yy=np.meshgrid(np.arange(x_min,x_max,0.02),
np.arange(y_min,y_max,0.02))
z=model.predict(np.c_[xx.ravel(),yy.ravel()])
z=z.reshape(xx.shape)
plt.contourf(xx,yy,z)
plt.scatter(x_test[:,0],x_test[:,1],c=y_test)
plt.show()
#法一单棵决策树
dtree=tree.DecisionTreeClassifier()
dtree.fit(x_train,y_train)
plot(dtree)
print(dtree.score(x_test,y_test))
#法二随机森林
RF=RandomForestClassifier(n_estimators=50)
RF.fit(x_train,y_train)
plot(RF)
RF.score(x_test,y_test)
print(RF.score(x_test,y_test))
#例三
import numpy as np
import matplotlib.pyplot as plt
from sklearn import tree
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import make_gaussian_quantiles
#导入数据
x1,y1=make_gaussian_quantiles(n_samples=500,n_features=2,n_classes=2)#二维正态分布500样本2特征2分类
x2,y2=make_gaussian_quantiles(mean=(3,3),n_samples=500,n_features=2,n_classes=2)#同上传是特征均值为了3
x_data=np.concatenate((x1,x2))#把x1,x2合在一起
y_data=np.concatenate((y1,-y2+1))#注意X2对应的标签
#决策树
model=tree.DecisionTreeClassifier(max_depth=3)
model.fit(x_data,y_data)
x_min,x_max=x_data[:,0].min()-1,x_data[:,0].max()+1
y_min,y_max=x_data[:,1].min()-1,x_data[:,1].max()+1
xx,yy=np.meshgrid(np.arange(x_min,x_max,0.02),
np.arange(y_min,y_max,0.02))
z=model.predict(np.c_[xx.ravel(),yy.ravel()])
z=z.reshape(xx.shape)
plt.contourf(xx,yy,z)
plt.scatter(x_data[:,0],x_data[:,1],c=y_data)
plt.show()
print(model.score(x_data,y_data))
#AdaBoost
model=AdaBoostClassifier(DecisionTreeClassifier(max_depth=3),n_estimators=10)
model.fit(x_data,y_data)
x_min,x_max=x_data[:,0].min()-1,x_data[:,0].max()+1
y_min,y_max=x_data[:,1].min()-1,x_data[:,1].max()+1
xx,yy=np.meshgrid(np.arange(x_min,x_max,0.02),
np.arange(y_min,y_max,0.02))
z=model.predict(np.c_[xx.ravel(),yy.ravel()])
z=z.reshape(xx.shape)
plt.contourf(xx,yy,z)
plt.scatter(x_data[:,0],x_data[:,1],c=y_data)
plt.show()
print(model.score(x_data,y_data))
#例四
from sklearn import datasets
from sklearn import model_selection
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from mlxtend.classifier import StackingClassifier # pip install mlxtend
iris = datasets.load_iris()# 载入数据集
x_data, y_data = iris.data[:, 1:3], iris.target # 只要第1,2列的特征
clf1 = KNeighborsClassifier(n_neighbors=1) # 定义三个不同的分类器
clf2 = DecisionTreeClassifier()
clf3 = LogisticRegression()
lr = LogisticRegression() # 定义一个次级分类器(逻辑回归)
sclf = StackingClassifier(classifiers=[clf1, clf2, clf3],meta_classifier=lr)#使用StackingClassifier
for clf,label in zip([clf1, clf2, clf3, sclf],['KNN','Decision Tree','LogisticRegression','StackingClassifier']):
scores = model_selection.cross_val_score(clf, x_data, y_data, cv=3, scoring='accuracy')#cv:选择每次测试折数;accuracy:评价指标是准确度,可省略
print("Accuracy: %0.2f [%s]" % (scores.mean(), label)) #每个分类器clf输出其命中率scores.mean()及方法名称标签label
#例五
from sklearn import datasets
from sklearn import model_selection
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import VotingClassifier
iris = datasets.load_iris() # 载入数据集
x_data, y_data = iris.data[:, 1:3], iris.target # 只要第1,2列的特征
clf1 = KNeighborsClassifier(n_neighbors=1) # 定义三个不同的分类器
clf2 = DecisionTreeClassifier()
clf3 = LogisticRegression()
sclf = VotingClassifier([('knn',clf1),('dtree',clf2), ('lr',clf3)])
for clf, label in zip([clf1, clf2, clf3, sclf],
['KNN','Decision Tree','LogisticRegression','VotingClassifier']):
scores = model_selection.cross_val_score(clf, x_data, y_data, cv=3, scoring='accuracy')
print("Accuracy: %0.2f [%s]" % (scores.mean(), label))
#(二)k-means
#例一
import numpy as np
import matplotlib.pyplot as plt
data=np.genfromtxt('./sk-learn_data/kmeans.txt',delimiter=' ') #(80,2)
def euclDistance(vector1, vector2): #计算距离
return np.sqrt(sum((vector2-vector1)**2))
def initCentroids(data, k): #初始化质心
numSamples, dim = data.shape #行数是样本数80,列数是属性数2
centroids = np.zeros((k, dim)) #生成K行DIM列全0的二维数组
for i in range(k): #赋值K个质心
index = int(np.random.uniform(0, numSamples)) #生成一个未出现过的随机值
centroids[i, :] = data[index, :] #把data的第index行(即点)赋给centroids作为第i个质心
return centroids #返回质心列表
def kmeans(data, k): #传入数据集80,2和k的值4
numSamples=data.shape[0] # 计算样本个数
clusterData=np.array(np.zeros((numSamples,2)))#样本的属性,第一列保存该样本属于哪个簇,第二列保存该样本跟它所属簇误差
clusterChanged=True # 决定质心是否要改变的变量
centroids=initCentroids(data, k) # 初始化质心
while clusterChanged:
clusterChanged = False #初始化未标记,若本轮循环完没有更新True表示没改变就跳出
for i in range(numSamples): # 循环每一个样本
minDist = 100000.0 # 最小距离初始化
minIndex = 0 # 初始化先是属于0簇
for j in range(k): # 循环计算每一个质心与该样本的距离
distance = euclDistance(centroids[j, :], data[i, :])#计算距离
if distance < minDist: # 如果计算的距离小于最小距离
minDist = distance # 更新当前循环维护的最小距离
clusterData[i, 1] = minDist# 更新最小距离属性
minIndex = j #当前点的簇更新为第j簇
if clusterData[i, 0] != minIndex: # 如果样本的所属的簇发生了变化
clusterChanged = True # 质心要重新计算
clusterData[i, 0] = minIndex# 更新样本的簇
for j in range(k): # 更新质心
cluster_index = np.nonzero(clusterData[:, 0] == j) # 获取第j个簇所有的样本所在的索引
pointsInCluster = data[cluster_index] # 第j个簇所有的样本点
centroids[j, :] = np.mean(pointsInCluster, axis = 0) # 取平均计算质心
return centroids, clusterData
def showCluster(data, k, centroids, clusterData): # 显示结果
numSamples, dim = data.shape
mark = ['or', 'ob', 'og', 'ok', '^r', '+r', 'sr', 'dr', '= max_num:#用max_num维护当前匹配到出现次数最多的单词
max_num = dic_words[c]
candidate = c
return candidate
print(correct('smoothig'))
print(correct('battl'))
print(correct('learww'))
print(correct('dagsgasdfeg'))
'''smoothing
battle
learn
dagsgasdfeg
'''
#(五)决策树
from sklearn import tree
import numpy as np
import matplotlib.pyplot as plt
data=np.genfromtxt('./sk-learn_data/LR-testSet.csv',delimiter=',')
x_data=data[:,:-1]
y_data=data[:,-1]
plt.scatter(x_data[:,0],x_data[:,1],c=y_data)
plt.show()
model=tree.DecisionTreeClassifier()
model.fit(x_data,y_data)
x_min,x_max=x_data[:,0].min()-1,x_data[:,0].max()+1
y_min,y_max=x_data[:,1].min()-1,x_data[:,1].max()+1
xx,yy=np.meshgrid(np.arange(x_min,x_max,0.02),np.arange(y_min,y_max,0.02))#生成网格
z=model.predict(np.c_[xx.ravel(),yy.ravel()])#ravel多维数据转一维
z=z.reshape(xx.shape)#改变形状为了输出
cs=plt.contourf(xx,yy,z)#画等高线
plt.scatter(x_data[:,0],x_data[:,1],c=y_data)#画散点
plt.show()
#(六)逻辑回归
#例一
import numpy as np
import matplotlib.pyplot as plt
from sklearn import linear_model
from sklearn.metrics import classification_report
data=np.genfromtxt("./sk-learn_data/LR-testSet.csv",delimiter=',')
x_data=data[:,:-1]
y_data=data[:,-1]
def plot():#画出散点
x0=[]
x1=[]
y0=[]
y1=[]
for i in range(len(x_data)):
if y_data[i]==0:
x0.append(x_data[i,0])
y0.append(x_data[i,1])
else:
x1.append(x_data[i,0])
y1.append(x_data[i,1])
scatter0=plt.scatter(x0,y0,c='b',marker='o')
scatter1=plt.scatter(x1,y1,c='r',marker='x')
plt.legend(handles=[scatter0,scatter1],labels=['label0','label1'],loc='best')
logistic=linear_model.LogisticRegression()
logistic.fit(x_data,y_data)
plot()
x_test=np.array([[-4],[3]])
y_test=(-logistic.intercept_-x_test*logistic.coef_[0][0])/logistic.coef_[0][1]
plt.plot(x_test,y_test,'k')
plt.show()
predictions=logistic.predict(x_data)
print(classification_report(y_data,predictions))
#例二
import numpy as np
import matplotlib.pyplot as plt
from sklearn import linear_model
from sklearn.datasets import make_gaussian_quantiles
from sklearn.preprocessing import PolynomialFeatures
x_data,y_data=make_gaussian_quantiles(n_samples=500,n_features=2,n_classes=2)#一、高斯分位数
plt.scatter(x_data[:,0],x_data[:,1],c=y_data)
plt.show()#由图可知500个样本,2个特征,2个分类
poly_reg=PolynomialFeatures(degree=5)#5次多项式生成器
x_poly=poly_reg.fit_transform(x_data)
logistic=linear_model.LogisticRegression()
logistic.fit(x_poly,y_data)
x_min,x_max=x_data[:,0].min()-1,x_data[:,0].max()+1#三、画图
y_min,y_max=x_data[:,1].min()-1,x_data[:,1].max()+1
xx,yy=np.meshgrid(np.arange(x_min,y_max,0.02),
np.arange(y_min,y_max,0.02))
z=logistic.predict(poly_reg.fit_transform(np.c_[xx.ravel(),yy.ravel()]))
z=z.reshape(xx.shape)
cs=plt.contourf(xx,yy,z)
plt.scatter(x_data[:,0],x_data[:,1],c=y_data)
plt.show()
#(七)线性回归
#例一
import numpy as np
import matplotlib.pyplot as plt
data=np.genfromtxt("./sk-learn_data/data.csv",delimiter=',')
x_data=data[:,0]
y_data=data[:,1]
plt.scatter(x_data,y_data)
plt.show()
lr=0.0001
b=0
k=0
epochs=50
def gradient_descent_runner(x_data,y_data,b,k,lr,epochs):
m=float(len(x_data))
for i in range(epochs):
b_grad=0
k_grad=0
for j in range(0,len(x_data)):
b_grad+=-(1/m)*(y_data[j]-((k*x_data[j])+b))
k_grad+=-(1/m)*x_data[j]*(y_data[j]-(k*x_data[j]+b))
b=b-(lr*b_grad)
k=k-(lr*k_grad)
return b,k
b,k=gradient_descent_runner(x_data,y_data,b,k,lr,epochs)
plt.plot(x_data,y_data,'b.')
plt.plot(x_data,k*x_data+b,'r')
plt.show()
#例二
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
data=np.genfromtxt("./sk-learn_data/data.csv",delimiter=',')
x_data=data[:,0,np.newaxis]#训练时要求是二维,从data读出时要升维
y_data=data[:,1]#输出升量可以是一维,也可以二维(np.newaxis可省)
model=LinearRegression()#建模并训练
model.fit(x_data,y_data)
plt.plot(x_data,y_data,'b.')#b.表示散点
plt.plot(x_data,model.predict(x_data),'r')#r无.表示线
plt.show()
#例三
import matplotlib.pyplot as plt
import numpy as np
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
data=np.genfromtxt("./sk-learn_data/job.csv",delimiter=',')
x_data=data[1:,1,np.newaxis]#训练时要求是二维,从data读出时要升维
y_data=data[1:,2,np.newaxis]#两,升维后是多行一列的二维形式(shape=10,1)
poly_reg=PolynomialFeatures(degree=3)#设置多项式次数(对比一元线性就多了这一句))
x_poly=poly_reg.fit_transform(x_data)#生成X多项式
model=LinearRegression()
model.fit(x_poly,y_data)#用X多项式进行模拟
plt.plot(x_data,y_data,'b.')
plt.plot(x_data,model.predict(x_poly),c='r')
#plt.title('title')
#plt.xlabel=('Position level')
#plt.ylabel=('Salary')
plt.show()
#(八)PCA
#例1
import numpy as np
import matplotlib.pyplot as plt
data=np.genfromtxt("./sk-learn_data/data.csv",delimiter=",")#读入
def zeroMean(dataMat):#数据中心化
meanVal=np.mean(dataMat,axis=0)#传入数据矩阵按列求平均返回均值列表,axis=0可理解为返回一行
newData=dataMat-meanVal#数据矩阵每个值减去所在列的均值得到新列表返回
return newData,meanVal
newData,meanVal=zeroMean(data)#把读入的数据data中心化
covMat=np.cov(newData,rowvar=0)#cov函数可求协方差矩阵,参数rowvar=0表示一行一个样本
eigVals,eigVects=np.linalg.eig(np.mat(covMat))#求特征值与特征向量
eigValIndice=np.argsort(eigVals)#对特征值由小到大排列
top=1#取最大的top个特征值下标
n_eigValIndice=eigValIndice[-1:-(top+1):-1]#从-1取到-2且不包括-2
n_eigVect=eigVects[:,n_eigValIndice]#最大的n个特征值对应的特征向量,行取所有行,列取下标对应的列
lowDateMat=newData*n_eigVect#降维!低维特征空间数据乘上对向的特征向量就得到了降维之后的数据
reconMat=(lowDateMat*n_eigVect.T)+meanVal#重构数据得到坐标
'''
关于最后两行要重点解释一下:
首先lowDateMat=newData*n_eigVect
假设现在的newData是(已去中心化)五行两列
[-1 -2
-1 0
0 0
2 1
0 1]
n_eigVect只有一个向量(两行一列)
[1/sqrt(2)
1/sqrt(2)]
那么相乘就得到
[-3/sqrt(2)
-1/sqrt(2)
0
3/sqrt(2)
1/sqrt(2)
]
这个降维后的矩阵中的每个值就是每个点投影到[1/sqrt(2) 1/sqrt(2)]后,从原点指向投影点的模长!
首先协相关矩阵最大的几个特征向量就是相近程度最大的方向,是一个从原点射出的向量
然后每个点看成是原点射向其的向量
最后两个向量内积,注意到协相关矩阵求出的那个向量是单位向量!标准化正交且规范化模长为1
所以得到的值就是投影到该特征向量指向的方向的投影,刚好就是模长
而重构就是把模长再分解到X,Y轴,这就得到了投影坐标
'''
'''
print(x_data.shape)#显示X数据的X,Y维大小
print(covMat)#输出协方差矩阵
print(eigVals)#输出特征值
print(eigVects)#输出特征向量
print(eigValIndice)#输出排序后的下标
print(n_eigValIndice)#输出特征值晨大的
print(n_eigVect)#输出最大的N个特征向量
print(lowDDateMat)#输出降维之后的数据
'''
x_data=data[:,0]#全部行第零列
y_data=data[:,1]#全部行第一列
plt.scatter(x_data,y_data)#画散点图
x_data=np.array(reconMat)[:,0]#全部行第零列
y_data=np.array(reconMat)[:,1]#全部行第一列
plt.scatter(x_data,y_data,c='r')#画散点图
plt.show()#显示
#例2
from sklearn.datasets import load_digits #加载数据
import numpy as np
import matplotlib.pyplot as plt
digits=load_digits() #load
x_data=digits.data #data,x_data.shape=(1797,64),1797张8*8的手写图片
y_data=digits.target #label 1797张图片对应的标签
def zeroMean(dataMat): #数据中心化
meanVal=np.mean(dataMat,axis=0) #传入数据矩阵按列求平均返回均值列表,axis=0可理解为返回一行
newData=dataMat-meanVal #数据矩阵每个值减去所在列的均值得到新列表返回
return newData,meanVal
def pca(data,top): #传入数据及要降至top维
newData,meanVal=zeroMean(data) #把读入的数据data中心化
covMat=np.cov(newData,rowvar=0) #cov函数可求协方差矩阵,参数rowvar=0表示一行一个样本
eigVals,eigVects=np.linalg.eig(np.mat(covMat)) #求特征值与特征向量
eigValIndice=np.argsort(eigVals)#对特征值由小到大排列
n_eigValIndice=eigValIndice[-1:-(top+1):-1] #从-1取到-2且不包括-2
n_eigVect=eigVects[:,n_eigValIndice] #最大的n个特征值对应的特征向量,行取所有行,列取下标对应的列
lowDateMat=newData*n_eigVect #降维!低维特征空间数据乘上对向的特征向量就得到了降维之后的数据
reconMat=(lowDateMat*n_eigVect.T)+meanVal #重构数据得到坐标
return lowDateMat,reconMat #返回降维后数据
lowDDataMat,reconMat=pca(x_data,2)#lowDDataMat.shape=(100,2)
x=np.array(lowDDataMat)[:,0]#每个样本降成二维后的一维值
y=np.array(lowDDataMat)[:,1]#每个样本降成二维后的二维值
plt.scatter(x,y,c=y_data)#把标签传给颜色c,0-9会自动分配颜色
plt.show()#显示样本,PCA功能实现,下面可以尝试用神经网络来训练观察效果
(九)感知机->见torch的神经网络
(十)KNN->纯数学逐个点判断即可
#第二十八章:opencv
import cv2
import numpy as np#其实cv2操作的就是numpy
from matplotlib import pyplot as plt
#例一:读入 显示 写出 摄像头获取
#一、读入图片
img = cv2.imread('1in.png',0)#0是灰图,默认是彩图
cv2.imshow('test1',img)#窗口名称,矩阵名
print(type(img))#
#二、用matplotlib显示
plt.imshow(img, cmap = 'gray', interpolation = 'bicubic')
plt.xticks([]), plt.yticks([]) # to hide tick values on X and Y axis
plt.show()
#三、存储图片
k = cv2.waitKey(0)
if k == 27: # wait for ESC key to exit
cv2.destroyAllWindows()
elif k == ord('s'): # wait for 's' key to save and exit
cv2.imwrite('2out.png',img)
cv2.destroyAllWindows()
#四、摄像头
cap = cv2.VideoCapture(0)#获取话柄
while(True):
ret, frame = cap.read()#读取
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)#转为灰图
cv2.imshow('frame',gray)#gray改为frame则为彩图
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
#例二:画图
img=np.zeros((512,512,3), np.uint8)
#关于传入的参数可用print(cv2.函数名.__doc__)查看
print(cv2.polylines.__doc__)
cv2.line(img,(0,0),(511,511),(255,0,0),5)
cv2.rectangle(img,(384,0),(510,128),(0,255,0),3)
cv2.circle(img,(447,63), 63, (0,0,255), -1)
cv2.ellipse(img,(256,256),(100,50),0,0,180,255,-1)
pts=np.array([[10,5],[20,30],[70,20],[50,10]], np.int32)
pts=pts.reshape((4,1,2))
cv2.polylines(img,pts,True,(255,0,0),10)#这行有只显示顶点的问题
font=cv2.FONT_HERSHEY_SIMPLEX
cv2.putText(img,'OpenCV',(10,500), font, 4,(255,255,255),2)
cv2.imshow('test2',img)
k = cv2.waitKey(0)
cv2.destroyAllWindows()
#例三:鼠标事件
drawing=False# 当鼠标按下时变为 True
mode=True# 如果 mode 为 true 绘制矩形。按下'm' 变成绘制曲线。
ix,iy=-1,-1
def draw_circle(event,x,y,flags,param):#回调函数
global ix,iy,drawing,mode
if event==cv2.EVENT_LBUTTONDOWN:#鼠标按下事件
drawing=True
ix,iy=x,y
elif event==cv2.EVENT_MOUSEMOVE and flags==cv2.EVENT_FLAG_LBUTTON:#鼠标移动事件(且按下)
if drawing==True:
if mode==True:
cv2.rectangle(img,(ix,iy),(x,y),(0,255,0),-1)
else:
cv2.circle(img,(x,y),3,(0,0,255),-1)
elif event==cv2.EVENT_LBUTTONUP:#鼠标释放左键事件
drawing==False
img=np.zeros((512,512,3),np.uint8)
cv2.namedWindow('image')
cv2.setMouseCallback('image',draw_circle)
while(1):
cv2.imshow('image',img)
k=cv2.waitKey(1)&0xFF
if k==ord('m'):
mode=not mode
elif k==27:
cv2.destroyAllWindows()
break
#例四:滑动条
def nothing(x):pass
img=np.zeros((300,512,3),np.uint8)#用np.zeros创建一副黑色图像
cv2.namedWindow('image')
cv2.createTrackbar('R','image',0,255,nothing)
cv2.createTrackbar('G','image',0,255,nothing)
cv2.createTrackbar('B','image',0,255,nothing)
switch='0:OFF\n1:ON'
cv2.createTrackbar(switch,'image',0,1,nothing)
while(1):
cv2.imshow('image',img)
k=cv2.waitKey(1)&0xFF
if k==27:break
r=cv2.getTrackbarPos('R','image')
g=cv2.getTrackbarPos('G','image')
b=cv2.getTrackbarPos('B','image')
s=cv2.getTrackbarPos(switch,'image')
if s==0:img[:]=0
else:img[:]=[b,g,r]
cv2.destroyAllWindows()
#例五:图像属性
img=cv2.imread('1in.png')
print(img.shape,img.size)#(421, 663, 3) 837369 长,宽,通道 三者乘积
print(img[100,100])#其实就是取出img这个numpy类对象下坐标是100,100的像素值
print(img[100,100,0])#就是取出这个像素值下0通道的值,三通道依然是BGR
print(type(img),type(img[100,100]),type(img[100,100,0]))#第三个输出相当于img.dtype
#
ball=img[280:340,330:390]
img[273:333,100:160]=ball
#b,g,r=cv2.split(img)#拆分,可用下面三句索引操作代替
b=img[:,:,0]
g=img[:,:,1]
r=img[:,:,2]
#img=cv2.merge(b,g,r)#合并,可用下面三句索引操作代替
img[:,:,0]=b[:,:]
img[:,:,1]=r[:,:]
img[:,:,2]=g[:,:]
#其实对通道操作可以直接img[:,:,0]=0,与b[:,:]=0等价,即实际上无必要拆分与合并
cv2.imshow('test5b',b)
cv2.imshow('test5g',g)
cv2.imshow('test5r',r)
cv2.imshow('test5',img)
k = cv2.waitKey(0)
cv2.destroyAllWindows()
#例六:算术运算
x = np.uint8([250])
y = np.uint8([10])
print(cv2.add(x,y))# [[255]] 250+10 = 260 => 255
print(x+y)#[4] 250+10 = 260 % 256 = 4
img1=cv2.imread('CJ.jpg')
img2=cv2.imread('GJL.png')
dst=cv2.addWeighted(img1,0.3,img2,0.7,0)
cv2.imshow('dst',dst)
cv2.waitKey(0)
cv2.destroyAllWindow()
#例七:性能检测
img1 = cv2.imread('1in.png')
e1 = cv2.getTickCount()
e2 = cv2.getTickCount()
print((e2 - e1)/cv2.getTickFrequency())
#例八:追踪蓝色物体(每跑一次都要restart kernal)
cap=cv2.VideoCapture(0)
while(1):
ret,frame=cap.read() # 获取每一帧
hsv=cv2.cvtColor(frame,cv2.COLOR_BGR2HSV) # 转换到 HSV
lower_blue=np.array([110,50,50])# 设定蓝色的阈值
upper_blue=np.array([130,255,255])#三个值分别为H,S,V
mask=cv2.inRange(hsv,lower_blue,upper_blue) # 根据阈值构建掩模
res=cv2.bitwise_and(frame,frame,mask=mask) # 对原图像和掩模进行位运算
cv2.imshow('frame',frame) # 显示原图像
cv2.imshow('mask',mask) # 显示掩膜图像
cv2.imshow('res',res) # 显示识别的图像
k=cv2.waitKey(5)&0xFF
if k==27:break
cv2.destroyAllWindows()# 关闭窗口
#例九:几何变换
#(缩放)
img=cv2.imread('GJL.png')
height=img.shape[0]
width=img.shape[1]
res1=cv2.resize(img,(2*width,2*height),interpolation=cv2.INTER_CUBIC)
#上面是把图出图像的尺寸传进去,下面是直接控制变换因子,结果是一样的
res2=cv2.resize(img,None,fx=2,fy=2,interpolation=cv2.INTER_CUBIC)
while(1):
cv2.imshow('img',img)
cv2.imshow('res1',res1)
cv2.imshow('res2',res2)
if cv2.waitKey(1) & 0xFF == 27:break
cv2.destroyAllWindows()
#(旋转)
img=cv2.imread('CJ.jpg',0)
rows,cols=img.shape
# 这里的第一个参数为旋转中心,第二个为旋转角度,第三个为旋转后的缩放因子
# 可以通过设置旋转中心,缩放因子,以及窗口大小来防止旋转后超出边界的问题
M=cv2.getRotationMatrix2D((cols/2,rows/2),45,0.6)
# 第三个参数是输出图像的尺寸中心
dst=cv2.warpAffine(img,M,(2*cols,2*rows))
while(1):
cv2.imshow('img',dst)
if cv2.waitKey(1)&0xFF==27:break
cv2.destroyAllWindows()
#(平移)
img=cv2.imread('CJ.jpg',0)
M = np.float32([[1,1,20],[0,1,20]])
rows,cols = img.shape[:2]
img_s=cv2.warpAffine(img,M,(cols,rows),borderValue=(155,150,200))
while(1):
cv2.imshow('img',img_s)
if cv2.waitKey(1)&0xFF==27:break
cv2.destroyAllWindows()
#(仿射变换)
img=cv2.imread('CJ.jpg',0)
rows,cols=img.shape
# 这里的第一个参数为旋转中心,第二个为旋转角度,第三个为旋转后的缩放因子
# 可以通过设置旋转中心,缩放因子,以及窗口大小来防止旋转后超出边界的问题
M=cv2.getRotationMatrix2D((cols/2,rows/2),45,0.6)
# 第三个参数是输出图像的尺寸中心
dst=cv2.warpAffine(img,M,(2*cols,2*rows))
while(1):
cv2.imshow('img',dst)#写在外面的话可以用鼠标关闭的话程序会崩掉
if cv2.waitKey(1)&0xFF==27:break
cv2.destroyAllWindows()
#(透视变换)
img=cv2.imread('GJL.png')
rows,cols,ch=img.shape
pts1 = np.float32([[56,65],[368,52],[28,387],[389,390]])
pts2 = np.float32([[0,0],[300,0],[0,300],[300,300]])
M=cv2.getPerspectiveTransform(pts1,pts2)
dst=cv2.warpPerspective(img,M,(300,300))
cv2.imshow('img',img)
cv2.imshow('dst',dst)
k=cv2.waitKey(0)
cv2.destroyAllWindows()
#例十:二值化
#(1)人工设定阈值
img=cv2.imread('GJL.png',0)
ret,thresh1=cv2.threshold(img,127,255,cv2.THRESH_BINARY)
ret,thresh2=cv2.threshold(img,127,255,cv2.THRESH_BINARY_INV)
ret,thresh3=cv2.threshold(img,127,255,cv2.THRESH_TRUNC)
ret,thresh4=cv2.threshold(img,127,255,cv2.THRESH_TOZERO)
ret,thresh5=cv2.threshold(img,127,255,cv2.THRESH_TOZERO_INV)
titles = ['Original Image','BINARY','BINARY_INV','TRUNC','TOZERO','TOZERO_INV']
images = [img, thresh1, thresh2, thresh3, thresh4, thresh5]
for i in range(6):
plt.subplot(2,3,i+1),plt.imshow(images[i],'gray')
plt.title(titles[i])
plt.xticks([]),plt.yticks([])
plt.show()
#(2)自适应阈值
img = cv2.medianBlur(img,5)#自我进行滤波平滑操作
ret,th1 = cv2.threshold(img,127,255,cv2.THRESH_BINARY)#下面11 为 Block size, 2 为 C 值
th2=cv2.adaptiveThreshold(img,255,cv2.ADAPTIVE_THRESH_MEAN_C,cv2.THRESH_BINARY,11,2)
th3=cv2.adaptiveThreshold(img,255,cv2.ADAPTIVE_THRESH_GAUSSIAN_C,cv2.THRESH_BINARY,11,2)
titles = ['Original Image', 'Global Thresholding (v = 127)','Adaptive Mean Thresholding', 'Adaptive Gaussian Thresholding']
images = [img, th1, th2, th3]
for i in range(4):
plt.subplot(2,2,i+1),plt.imshow(images[i],'gray')
plt.title(titles[i])
plt.xticks([]),plt.yticks([])
plt.show()
#例十一:滤波器
#用filter2D
img = cv2.imread('GJL.png')
kernel = np.ones((5,5),np.float32)/25#5x5的全是1的矩阵
dst1 = cv2.filter2D(img,-1,kernel)#cv.filter2D()就是二维卷积操作
dst2 = cv2.blur(img,(5,5))#当上面的filter2D传入矩阵全是1时效果与本行一样
dst3 = cv2.GaussianBlur(img,(5,5),0)#高斯
dst4 = cv2.medianBlur(img,5)
dst5 = cv2.bilateralFilter(img,9,75,75)
cv2.imshow('average',dst1)
cv2.imshow('blur',dst2)
cv2.imshow('gauss',dst3)
cv2.imshow('median',dst4)
cv2.imshow('bilateralFilter',dst5)
k=cv2.waitKey(0)
cv2.destroyAllWindows()
#例十二:形态学
img = cv2.imread('GJL.png',0)
kernel = np.ones((5,5),np.uint8)
erosion = cv2.erode(img,kernel,iterations = 1)#腐蚀(黑区扩大)
dilation = cv2.dilate(img,kernel,iterations = 1)#膨胀(白区扩大)
opening = cv2.morphologyEx(img, cv2.MORPH_OPEN, kernel)#开运算,先腐蚀膨胀
closing = cv2.morphologyEx(img, cv2.MORPH_CLOSE, kernel)#闭运算,先膨胀再腐蚀
gradient = cv2.morphologyEx(img, cv2.MORPH_GRADIENT, kernel)#形态学梯度,像膨胀与腐蚀的差
tophat = cv2.morphologyEx(img, cv2.MORPH_TOPHAT, kernel)#礼帽,原图与开运算后的图像的差
blackhat = cv2.morphologyEx(img, cv2.MORPH_BLACKHAT, kernel)#黑帽,闭运算后的图与原图的差
cv2.imshow('erosion',erosion)
cv2.imshow('dilation',dilation)
cv2.imshow('opening',opening)
cv2.imshow('closing',closing)
cv2.imshow('gradient',gradient)
cv2.imshow('tophat',tophat)
cv2.imshow('blackhat',blackhat)
k=cv2.waitKey(0)
cv2.destroyAllWindows()
#例十三:图像梯度
img=cv2.imread('CJ.jpg',0)
laplacian=cv2.Laplacian(img,cv2.CV_64F)
sobelx=cv2.Sobel(img,cv2.CV_64F,1,0,ksize=5)#1,0表示只在x方向求一阶导数,最大求二阶
sobely=cv2.Sobel(img,cv2.CV_64F,0,1,ksize=5)#0,1表示只在y方向求一阶导数,最大求二阶
plt.subplot(2,2,1),plt.imshow(img,cmap = 'gray')
plt.title('Original'), plt.xticks([]), plt.yticks([])
plt.subplot(2,2,2),plt.imshow(laplacian,cmap = 'gray')
plt.title('Laplacian'), plt.xticks([]), plt.yticks([])
plt.subplot(2,2,3),plt.imshow(sobelx,cmap = 'gray')
plt.title('Sobel X'), plt.xticks([]), plt.yticks([])
plt.subplot(2,2,4),plt.imshow(sobely,cmap = 'gray')
plt.title('Sobel Y'), plt.xticks([]), plt.yticks([])
plt.show()
#例十四:CANNY边缘检测
img = cv2.imread('CJ.jpg',0)
edges = cv2.Canny(img,100,200)
cv2.imshow('edges',edges)
k=cv2.waitKey(0)
cv2.destroyAllWindows()
#例十五:轮廓
img1 = cv2.imread('3in.png')
img = cv2.cvtColor(img1,cv2.COLOR_BGR2GRAY)
ret,thresh = cv2.threshold(img,127,255,0)#ret就是127
img,contours,hierarchy=cv2.findContours(thresh,cv2.RETR_TREE,cv2.CHAIN_APPROX_NONE)#cv2.CHAIN_APPROX_SIMPLE则只绘制顶点
imgs = cv2.drawContours(img1, contours, -1, (0,255,0), 3)
cv2.imshow('img',imgs)#绘制轮廓
k=cv2.waitKey(0)
cv2.destroyAllWindows()
cnt = contours[3]#取出第3个轮廓
print(cv2.moments(cnt))#求矩的字典
print(cv2.contourArea(cnt))#轮廓面积
print(cv2.arcLength(cnt,True))#轮廓周长
print(cv2.isContourConvex(cnt))#凸性检测bool
print(cv2.convexHull(cnt))#输入轮廓顶点得到凸包顶点
x,y,w,h = cv2.boundingRect(cnt)#直边界矩形
imgs = cv2.rectangle(img1,(x,y),(x+w,y+h),(0,255,0),2)
cv2.imshow('img',imgs)
k=cv2.waitKey(0)
cv2.destroyAllWindows()
(x,y),radius = cv2.minEnclosingCircle(cnt)#最小外接圆
center = (int(x),int(y))
radius = int(radius)
imgs = cv2.circle(img1,center,radius,(0,255,0),2)
cv2.imshow('img',imgs)
k=cv2.waitKey(0)
cv2.destroyAllWindows()
ellipse = cv2.fitEllipse(cnt)#椭圆拟合
imgs = cv2.ellipse(img1,ellipse,(0,255,0),2)
cv2.imshow('img',imgs)
k=cv2.waitKey(0)
cv2.destroyAllWindows()
print(hierarchy)#最后讲关于轮廓继承关系
#轮廓检索形式
#RETR_LIST不去创建任何父子关系
#RETR_EXTERNAL只会返回最外边的的轮廓
#RETR_TREE返回所有轮廓,并且创建一个完整的组织结构列表
#RETR_CCOMP会返回所有的轮廓并将轮廓分为两级组织结构
#即:一个对象的外轮廓为第1级组织结构。而对象内部中空洞的轮廓为第2级组织结构
# 空洞中的任何对象的轮廓又是第 1 级组织结构。空洞的组织构为第 2 级。
#下面这个仅是所取测试图的输出,不同图输出不同
#[[[-1 -1 1 -1],就是整个图作为一个轮廓480*640
# [ 3 -1 2 0],下面空心五角形的外轮廓
# [-1 -1 -1 1],上面实心五角形的轮廓
# [-1 1 -1 0]],下面空心五角形的内轮廓]
#[Next,同一级组织结构中的下一个轮廓。
# Previous,Previous,表示同一级结构中的前一个轮廓。
# First_Child,Previous,表示同一级结构中的前一个轮廓。
# Parent,表示它的父轮廓。]
#例十六:直方图
img = cv2.imread('GJL.png')
color = ('b','g','r')
for i,col in enumerate(color):
histr = cv2.calcHist([img],[i],None,[256],[0,256])
plt.plot(histr,color = col)
plt.xlim([0,256])
plt.show()
#传用掩摸
img = cv2.imread('CJ.jpg',0)
# create a mask
mask = np.zeros(img.shape[:2], np.uint8)
mask[100:300, 100:400] = 255
masked_img = cv2.bitwise_and(img,img,mask = mask)
hist_full = cv2.calcHist([img],[0],None,[256],[0,256])
hist_mask = cv2.calcHist([img],[0],mask,[256],[0,256])
plt.subplot(221), plt.imshow(img, 'gray')
plt.subplot(222), plt.imshow(mask,'gray')
plt.subplot(223), plt.imshow(masked_img, 'gray')
plt.subplot(224), plt.plot(hist_full), plt.plot(hist_mask)
plt.xlim([0,256])
plt.show()
#均衡化
img = cv2.imread('CJ.jpg',0)
hist,bins = np.histogram(img.flatten(),256,[0,256])#flatten() 将数组变成一维
cdf = hist.cumsum()# 计算累积分布图
cdf_normalized = cdf * hist.max()/ cdf.max()
plt.plot(cdf_normalized, color = 'b')
plt.hist(img.flatten(),256,[0,256], color = 'r')
plt.xlim([0,256])
plt.legend(('cdf','histogram'), loc = 'upper left')
plt.show()
#例十七:傅里叶变换
#NUMPY实现
img = cv2.imread('CJ.jpg',0)
f = np.fft.fft2(img)
fshift = np.fft.fftshift(f)
magnitude_spectrum = 20*np.log(np.abs(fshift))
plt.subplot(121),plt.imshow(img, cmap = 'gray')
plt.title('Input Image'), plt.xticks([]), plt.yticks([])
plt.subplot(122),plt.imshow(magnitude_spectrum, cmap = 'gray')
plt.title('Magnitude Spectrum'), plt.xticks([]), plt.yticks([])
plt.show()
#CV实现
img = cv2.imread('CJ.jpg',0)
dft = cv2.dft(np.float32(img),flags = cv2.DFT_COMPLEX_OUTPUT)
dft_shift = np.fft.fftshift(dft)
magnitude_spectrum = 20*np.log(cv2.magnitude(dft_shift[:,:,0],dft_shift[:,:,1]))
plt.subplot(121),plt.imshow(img, cmap = 'gray')
plt.title('Input Image'), plt.xticks([]), plt.yticks([])
plt.subplot(122),plt.imshow(magnitude_spectrum, cmap = 'gray')
plt.title('Magnitude Spectrum'), plt.xticks([]), plt.yticks([])
plt.show()
#算子比较
import cv2
import numpy as np
from matplotlib import pyplot as plt
# simple averaging filter without scaling parameter
mean_filter = np.ones((3,3))
# creating a guassian filter
x = cv2.getGaussianKernel(5,10)
#x.T 为矩阵转置
gaussian = x*x.T
# different edge detecting filters
# scharr in x-direction
scharr = np.array([[-3, 0, 3],
[-10,0,10],
[-3, 0, 3]])
# sobel in x direction
sobel_x= np.array([[-1, 0, 1],
[-2, 0, 2],
[-1, 0, 1]])
# sobel in y direction
sobel_y= np.array([[-1,-2,-1],
[0, 0, 0],
[1, 2, 1]])
# laplacian
laplacian=np.array([[0, 1, 0],
[1,-4, 1],
[0, 1, 0]])
filters = [mean_filter, gaussian, laplacian, sobel_x, sobel_y, scharr]
filter_name = ['mean_filter', 'gaussian','laplacian', 'sobel_x', \
'sobel_y', 'scharr_x']
fft_filters = [np.fft.fft2(x) for x in filters]
fft_shift = [np.fft.fftshift(y) for y in fft_filters]
mag_spectrum = [np.log(np.abs(z)+1) for z in fft_shift]
for i in range(6):
plt.subplot(2,3,i+1),plt.imshow(mag_spectrum[i],cmap = 'gray')
plt.title(filter_name[i]), plt.xticks([]), plt.yticks([])
plt.show()
#例十八:模板匹配
img = cv2.imread('CJ.jpg',0)
img2 = img.copy()
template = cv2.imread('CJ_small.jpg',0)
w, h = template.shape[::-1]
# All the 6 methods for comparison in a list
methods = ['cv2.TM_CCOEFF', 'cv2.TM_CCOEFF_NORMED', 'cv2.TM_CCORR','cv2.TM_CCORR_NORMED', 'cv2.TM_SQDIFF', 'cv2.TM_SQDIFF_NORMED']
for meth in methods:
img = img2.copy()
#exec 语句用来执行储存在字符串或文件中的 Python 语句。
# 例如,我们可以在运行时生成一个包含 Python 代码的字符串,然后使用 exec 语句执行这些语句。
#eval 语句用来计算存储在字符串中的有效 Python 表达式
method = eval(meth)
# Apply template Matching
res = cv2.matchTemplate(img,template,method)
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)
# 使用不同的比较方法,对结果的解释不同
# If the method is TM_SQDIFF or TM_SQDIFF_NORMED, take minimum
if method in [cv2.TM_SQDIFF, cv2.TM_SQDIFF_NORMED]:top_left = min_loc
else:top_left = max_loc
bottom_right = (top_left[0] + w, top_left[1] + h)
cv2.rectangle(img,top_left, bottom_right, 255, 2)
plt.subplot(121),plt.imshow(res,cmap = 'gray')
plt.title('Matching Result'), plt.xticks([]), plt.yticks([])
plt.subplot(122),plt.imshow(img,cmap = 'gray')
plt.title('Detected Point'), plt.xticks([]), plt.yticks([])
plt.suptitle(meth)
plt.show()
#例十九:霍夫变换
#直线
img = cv2.imread('CJ.jpg')
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
edges = cv2.Canny(gray,50,150,apertureSize = 3)
lines = cv2.HoughLines(edges,1,np.pi/180,200)
for rho,theta in lines[0]:
a = np.cos(theta)
b = np.sin(theta)
x0 = a*rho
y0 = b*rho
x1 = int(x0 + 1000*(-b))
y1 = int(y0 + 1000*(a))
x2 = int(x0 - 1000*(-b))
y2 = int(y0 - 1000*(a))
cv2.line(img,(x1,y1),(x2,y2),(0,0,255),2)
cv2.imwrite('houghlines3.jpg',img)
#圆
img = cv2.imread('CJ.jpg',0)
img = cv2.medianBlur(img,5)
cimg = cv2.cvtColor(img,cv2.COLOR_GRAY2BGR)
circles = cv2.HoughCircles(img,cv2.HOUGH_GRADIENT,1,20,param1=50,param2=30,minRadius=0,maxRadius=0)
circles = np.uint16(np.around(circles))
i=circles[0,0]
cv2.circle(cimg,(i[0],i[1]),i[2],(0,255,0),2)# draw the outer circle
cv2.circle(cimg,(i[0],i[1]),2,(0,0,255),3)# draw the center of the circle
cv2.imshow('detected circles',cimg)
cv2.waitKey(0)
cv2.destroyAllWindows()
#例二十:分水岭
img = cv2.imread('GJL.png')
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
ret, thresh = cv2.threshold(gray,0,255,cv2.THRESH_BINARY_INV+cv2.THRESH_OTSU)
# noise removal
kernel = np.ones((3,3),np.uint8)
opening = cv2.morphologyEx(thresh,cv2.MORPH_OPEN,kernel, iterations = 2)
# sure background area
sure_bg = cv2.dilate(opening,kernel,iterations=3)
# Finding sure foreground area
# 距离变换的基本含义是计算一个图像中非零像素点到最近的零像素点的距离,也就是到零像素点的最短距离
# 个最常见的距离变换算法就是通过连续的腐蚀操作来实现,腐蚀操作的停止条件是所有前景像素都被完全
# 腐蚀。这样根据腐蚀的先后顺序,我们就得到各个前景像素点到前景中心呗Ⅵ像素点的
# 距离。根据各个像素点的距离值,设置为不同的灰度值。这样就完成了二值图像的距离变换
#cv2.distanceTransform(src, distanceType, maskSize)
# 第二个参数 0,1,2 分别表示 CV_DIST_L1, CV_DIST_L2 , CV_DIST_C
dist_transform = cv2.distanceTransform(opening,1,5)
ret, sure_fg = cv2.threshold(dist_transform,0.7*dist_transform.max(),255,0)
# Finding unknown region
sure_fg = np.uint8(sure_fg)
unknown = cv2.subtract(sure_bg,sure_fg)
# Marker labelling
ret, markers1 = cv2.connectedComponents(sure_fg)
# Add one to all labels so that sure background is not 0, but 1
markers = markers1+1
# Now, mark the region of unknown with zero
markers[unknown==255] = 0
markers3 = cv2.watershed(img,markers)
img[markers3 == -1] = [255,0,0]
cv2.imshow('img',img)
cv2.waitKey(0)
cv2.destroyAllWindows()
#例二十一:前景提取
img = cv2.imread('CJ.jpg')
mask = np.zeros(img.shape[:2],np.uint8)
bgdModel = np.zeros((1,65),np.float64)
fgdModel = np.zeros((1,65),np.float64)
rect = (50,50,450,290)
# 函数的返回值是更新的 mask, bgdModel, fgdModel
cv2.grabCut(img,mask,rect,bgdModel,fgdModel,5,cv2.GC_INIT_WITH_RECT)
mask2 = np.where((mask==2)|(mask==0),0,1).astype('uint8')
img = img*mask2[:,:,np.newaxis]
# newmask is the mask image I manually labelled
newmask = cv2.imread('newmask.png',0)
# whereever it is marked white (sure foreground), change mask=1
# whereever it is marked black (sure background), change mask=0
mask[newmask == 0] = 0
mask[newmask == 255] = 1
mask, bgdModel, fgdModel = cv2.grabCut(img,mask,None,bgdModel,fgdModel,5,cv2.GC_INIT_WITH_MASK)
mask = np.where((mask==2)|(mask==0),0,1).astype('uint8')
img = img*mask[:,:,np.newaxis]
plt.imshow(img),plt.colorbar(),plt.show()
#例二十二:角点检测
#1 Harris
filename = 'CJ.jpg'
img = cv2.imread(filename)
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
gray = np.float32(gray)
# 输入图像必须是 float32,最后一个参数在 0.04 到 0.05 之间
dst = cv2.cornerHarris(gray,2,3,0.04)
#result is dilated for marking the corners, not important
dst = cv2.dilate(dst,None)
# Threshold for an optimal value, it may vary depending on the image.
img[dst>0.01*dst.max()]=[0,0,255]
cv2.imshow('img',img)
k=cv2.waitKey(0)
cv2.destroyAllWindows()
#2 Shi-Tomasi
img = cv2.imread('CJ.jpg')
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
corners = cv2.goodFeaturesToTrack(gray,25,0.01,10)
corners = np.int0(corners)# 返回的结果是 [[ 311., 250.]] 两层括号的数组。
for i in corners:
x,y = i.ravel()
cv2.circle(img,(x,y),3,255,-1)
plt.imshow(img),plt.show()
#例二十三:Meanshift
cap = cv2.VideoCapture('CJ.mp4')
# take first frame of the video
ret,frame = cap.read()
# setup initial location of window
r,h,c,w = 250,90,400,125 # simply hardcoded the values
track_window = (c,r,w,h)
# set up the ROI for tracking
roi = frame[r:r+h, c:c+w]
hsv_roi = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
mask = cv2.inRange(hsv_roi, np.array((0., 60.,32.)), np.array((180.,255.,255.)))
roi_hist = cv2.calcHist([hsv_roi],[0],mask,[180],[0,180])
cv2.normalize(roi_hist,roi_hist,0,255,cv2.NORM_MINMAX)
# Setup the termination criteria, either 10 iteration or move by atleast 1 pt
term_crit = ( cv2.TERM_CRITERIA_EPS | cv2.TERM_CRITERIA_COUNT, 10, 1 )
while(1):
ret ,frame = cap.read()
if ret == True:
hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
dst = cv2.calcBackProject([hsv],[0],roi_hist,[0,180],1)
# apply meanshift to get the new location
ret, track_window = cv2.meanShift(dst, track_window, term_crit)
# Draw it on image
x,y,w,h = track_window
img2 = cv2.rectangle(frame, (x,y), (x+w,y+h), 255,2)
cv2.imshow('img2',img2)
k = cv2.waitKey(60) & 0xff
if k == 27:
break
else:
cv2.imwrite(chr(k)+".jpg",img2)
else:
break
cv2.destroyAllWindows()
cap.release()
#例二十四:图像修补
img = cv2.imread('CJ.jpg')
mask = cv2.imread('GJL.png',0)
dst = cv2.inpaint(img,mask,3,cv2.INPAINT_TELEA)
cv2.imshow('dst',dst)
cv2.waitKey(0)
cv2.destroyAllWindows()
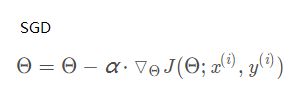









print('----没梯度-----')
import torch
x=torch.rand(2,2)
print(x)
y=torch.ones(2,3)
print(y)
z=y+9
print(z)
'''
tensor([[0.2299, 0.5370],
[0.8663, 0.1040]])
tensor([[1., 1., 1.],
[1., 1., 1.]])
tensor([[10., 10., 10.],
[10., 10., 10.]])
'''
print('----有梯度-----')
x=torch.ones(1,1,requires_grad=True)
print(x)
y=x+2
print(y)
z=torch.mean(y*2)
print(z)
z.backward()
print(x.grad)
'''
tensor([[1.]], requires_grad=True)
tensor([[3.]], grad_fn=)
tensor(6., grad_fn=)
tensor([[2.]])
'''
print('----torch.mm-----')
s=torch.tensor([[1.0,2.0]],requires_grad=True)
x=torch.ones(2,2,requires_grad=True)
for i in range(1):
s=s.mm(x)
z=torch.mean(s)
z.backward()
print(z)
print(x.grad)
'''
tensor(3., grad_fn=)
tensor([[0.5000, 0.5000],
[1.0000, 1.0000]])
'''
#torch.mul(a, b)是矩阵a和b对应位相乘,a和b的维度必须相等
#torch.mm(a, b)是矩阵a和b矩阵相乘,a列数与b行数必须相等
print('-----数学推导----')
# simple gradient
a = torch.tensor([[2.0,3.0]],requires_grad=True)
b = a + 3
c = b * b * 3
out = c.mean()
out.backward()
print(a.data)
print(b.data)
print(c.data)
print(out.data)
print(a.grad.data)
'''
tensor([[2., 3.]])
tensor([[5., 6.]])
tensor([[ 75., 108.]])
tensor(91.5000)
tensor([[15., 18.]])
'''

