clang static analyzer源码分析(番外篇):evalCall()中的inline机制
部分内容陈旧,请以最新代码为准
引子
我们在clang static analyzer源码分析(一)中介绍到,path-sensitive analysis的两种形式,一种是inline形式的分析,一种是非inline形式的分析。在静态分析的过程中,函数是否inline,属于过程间分析(interprocedural analysis)讨论的概念。对于两种形式来说,各有优劣,但基本上来说函数inline形式的分析得到的结果更为准确。
注:静态分析中的函数inline与C++中的inline关键字虽然所指不同,但是意思相近。
过程间静态分析
在做过程内静态分析(intraprocedural analysis)的时候, 针对大部分语句的分析使用符号执行都可以进行较为准确的建模(注:分支语句会涉及到约束求解),但是对于函数调用语句CallExpr(clang static analyzer使用CallEvent来表征分析过程中的函数、方法、过程调用),就无能为力了。因为CallEvent行为不是调用语句本身能够表示的,只能通过函数体,也就是的函数定义才能模拟此次调用的行为。
例如下面的代码:
extern int func(int, int);
int main()
{
// 下面这条语句,clang static analyzer可以很好的表示
// 使用nonloc::ConcreteInt::evalBinOp()就可以很好的进行模拟
int addSum = 10 + 11;
// 但是对于下面这条语句,我们就无能为力了。函数func()的逻辑是什么无从得知,num的值就只能是任意值了
int num = func(10, 10);
// ...
}
过程内分析 vs. 过程间分析
注:这一小节摘自《Compilers and Translators:
Software Verification Tools
Lecture 12: Interprocedural Analysis
October 16, 2007》
过程内分析
过程内分析每次一个过程,不会跨越多个过程进行分析。它会假设此次函数调用会更改Callee所能接触到的所有变量状态,并且可能产生任意的副作用。
如果对被调用的函数一无所知,在分析的时候碰到函数调用就必须作最保守的估计。比如,如果一个指针作为参数传给了一个函数,就必须假设所有指针可能指向的对象都被修改了。在编译优化中都是这么做的(可以参看数据流分析中的must分析和may分析),因为优化必须要保证结果的正确性。保守带来的不利之处最多就是失去优化机会,而没有其他问题。但是保守的结果会给静态分析带来非常大的不精确性,大大增加误报率。
通常来说,过程内分析相对来说比较有效但是不是很精确。
过程间分析
过程间分析会跨越多个过程进行分析,有可能一次会分析完整个程序。一个比较通用的技术技术就是尽可能的inline所调用的函数。而且指针别名分析往往是过程间分析是否精确的关键。
CallGraph
过程间分析的第一步就是创建CallGraph,我们在clang static analyzer 源码分析(一)也介绍到了,path-sensitive analysis的一种方式是通过AnalysisConsumer::handleDeclsCallGraph()来进行分析,并且这种方式在分析时是要尝试进行函数inline的。
如下图所示的CallGraph,clang静态分析是按照逆后序(其实就是拓扑序的一种,因为CallGraph不一定是DAG。可以参看文章迭代数据流分析中的逆后序(Reverse Postorder))的顺序来分析,可以通过ReversePostOrderTraversal来了解具体的细节。
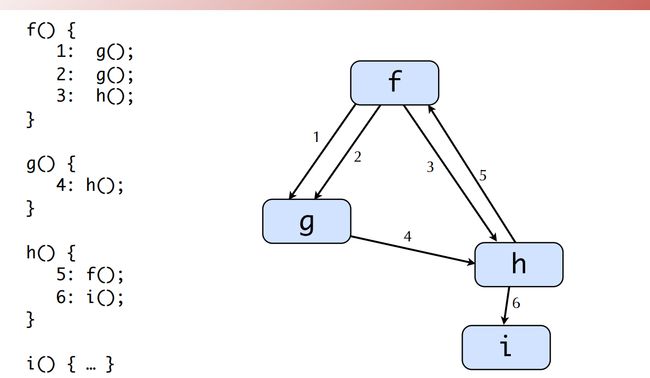
创建CallGraph的方法很简单,我们在前面的文章中没有提及,这里稍微介绍一下。创建CallGraph主体思想就是遍历TU中的所有Decl,针对每个FunctionDecl、CXXMethodDecl、CXXConstrutorDecl等,遍历其函数体遇到一个函数调用,则在Caller和Callee之间建立调用关系。
遍历TU顶层Decl的代码很简单,如下所示:
// Build the Call Graph by adding all the top level declarations to the graph.
CallGraph CG;
for (unsigned i = 0; i < LocalTUDeclsSize; ++i) {
CG.addToCallGraph(LocalTUDecls[i]);
}
由于CallGraph(使用了CRTP)是继承自的RecursiveASTVisitor<>的类,所以CallGraph具有了Traverse*()的能力,只要重写Visit*()的可以实现创建CallGraph的逻辑。
void addToCallGraph(Decl *D) {
TraverseDecl(D);
}
// 重写了VisitFunctionDecl()的逻辑,该函数比较重要一条语句是addNodeForDecl(FunctionDecl *FD)
// 该函数会遍历FunctionDecl的函数体,定位所有的CallSite,然后再Caller与Callee间建立联系。
// Part of recursive declaration visitation. We recursively visit all the
/// declarations to collect the root functions.
bool VisitFunctionDecl() {
// We skip function template definitions, as their semantics is
// only determined when they are instantiated.
if (includeInGraph(FD)) {
// 针对lambda表达式
// Add all blocks declared inside this function to the graph.
addNodesForBlocks(FD);
// 注释没看懂
addNodeForDecl(FD, FD->isGlobal());
}
}
上面我们介绍了CallGraph会遍历到所有的FunctionDecl,然后就是通过CGBuilder来遍历函数体,寻找CallSite。遍历函数体的入口函数是CallGraph::addNodeForDecl(),源码如下:
void CallGraph::addNodeForDecl(Decl *D, bool IsGlobal) {
assert(D);
/// Allocate a new node, mark it as root, and process it's calls.
/// getOrInsertNode()这里只起到创建新Node的作用
CallGraphNode *Node = getOrInsertNode(D);
// CGBuilder是继承自StmtVisitor<>的类,用于遍历函数体
// Process all the calls by this function as well.
CGBuilder builder(this, Node);
if (Stmt *Body = D->getBody())
builder.Visit(Body);
}
注:该函数的IsGlobal貌似是无用的
遍历获取到所有的CallSite就是CGBuilder的任务了,CGBuilder重写了**StmtVisitor<>的VisitCallExpr(CallExpr *CE)**函数体,该方法的逻辑如下:
void VisitCallExpr(CallExpr *CE) {
if (Decl *D = getDeclFromCall(CE))
//调用addCalledDecl()简历Caller与Callee之间的联系
addCalledDecl(D);
}
void addCalledDecl(Decl *D) {
if(G->includeInGraph(D)) {
// 获取Callee结点
CallGraphNode *CalleeNode = G->getOrInsertNode(D);
// 建立Caller与Callee之间的联系
CallerNode->addCallee(CalleeNode, G);
}
}
上面的G->includeInGraph(Decl *D),用来判断该函数是否可以添加到CallGraph中(该方法主要为了限制函数模板)。extern函数调用以及函数指针调用不会创建到CallGraph中。
如下代码所示,分别涉及到了三种类型的调用,extern函数调用,函数指针调用,以及模板函数调用。其中只有实例化模板函数调用可以添加到到CallGraph中。
注:但是对于函数指针调用,只要函数指针的值可以获知(也就是能够获取函数指针所指函数),只要满足inline要求,也是会进行inline的。毕竟CallGraph也是通过Syntax的形式创建的,不能包含函数指针调用也是可以理解的。
extern int inc(int num);
int dec(int num)
{
return --num;
}
template
T add(T lhs, T rhs)
{
dec(10);
return lhs + rhs;
}
int main()
{
// i. extern 函数调用,无法获知函数体,不会创建到CallGraph中
inc(11);
int (*funcPtr)(int);
// ii.函数指针调用,无法获知函数体,不会创建到CallGraph中
funcPtr = dec;
funcPtr(10);
// iii.模板函数调用,在编译期可以获知进行模板实例化,会添加到CallGaph中
add(1, 2);
}
// ------------------CallGraph如下----------------------
E:\test>clang -cc1 -analyze -analyzer-checker=debug.DumpCallGraph test.cpp
--- Call graph Dump ---
Function: < root > calls: dec main add
Function: main calls: add
Function: add calls:
Function: dec calls:
注意,虽然模板函数调用了**dec(int)**函数,但是并没有创建这种调用关系。
注: -analyzer-checker=debug.DumpCallGraph可以文字显示的CallGraph 或者 使用debug.ViewCallGraph打印图片格式的CallGraph
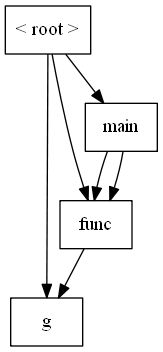
如下代码:
extern int a;
int global = 10;
void g(int);
void func(int num)
{
g(num);
}
int main()
{
if(a > 10)
{
func(10);
}
else
{
func(11);
}
}
void g(int num)
{
global = num;
}
打印出的CallGraph如下,clang会隐式添加一个根节点,该根节点会调用所有的Top-Level函数。
函数inline
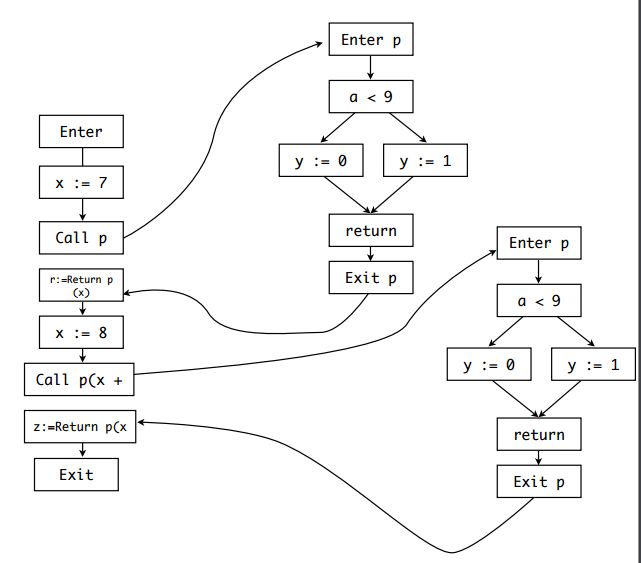
要实现过程间分析,最直观的方法就是通过函数inline。这种方法基本上是遇到函数调用就要inline展开,转变为过程内分析,但是这种方式有两个问题。
- 状态指数级增长,例如***p() {q(); q();} q() {r(); r()}***等
- 无法处理递归调用,直接或间接递归调用
函数inline的图示如下所示:
函数inline另一方面的问题,就是有可能退化成函数非inline的形式。如果函数调用都是指针调用,模板实例化调用以及extern函数调用,那么基本上对Callee是哪一个函数体都无从得知,此时就变成了过程内分析。
对于extern函数调用的函数inline,就需要跨文件的信息,这些函数调用的分析有可能需要推迟到link-time进行,或者在link-time进行再分析。
为了解决指数级爆炸的问题,函数inline有很多改进版本。一种比较常见的方法就是进行有限的函数内嵌法,这种方法**《C程序的静态分析》**中有介绍,我这里摘过来。
有限的函数inline法的核心,就是限制inline深度,如果函数inline的栈过深就终止此条线路上的inline分析。首先人为规定一些入口函数,入口函数的选择比较重要,需要参照CallGraph来进行,因为CallGraph不一定是一个图,有可能是图集合,如果人为选择的入口函数遗漏了一些函数,同时这些函数又不会被其他函数调用,那么就会丢失该函数的分析。
该方法的伪代码如下所示:

clang的函数inline机制选择了与有限函数内嵌法有三方面的不同。
- 入口函数的选择,除了模板函数其他都可以作为root函数,就是入口函数,参见includeInGraph()
- 如果函数被inline过,就不会将其作为入口函数进行单独分析
- 限制inline stack的深度以及**“大函数”的inline次数,inline stack默认最大深度为5层(也就是顶多inline 4**次)
注:我们可以使用"clang -cc1 -analyzer-display-progress -analyze test.c"来查看分析引擎的整个过程
关于clang如何建立CallGraph并使用逆后序(拓扑序)分析的源码在**handleDeclsCallGraph()**中有所展示。
void AnalysisConsumer::HandleDeclsCallGraph(const unsigned LocalTUDeclsSize) {
// ...
// Skip the functions which have been processed already or previously
// inlined.
if (shouldSkipFunction(D, Visited, VisitedAsTopLevel))
continue;
// ...
}
采用这种方法会有一方面的bug,详见clang static analyzer源码分析(一)中的例子。
clang static analyzer函数inline机制
-----------------------------更新 2016-11-28--------------------------------
关于clang static analyzer,clang有详细的文档clang/docs/analyzer/IPA.txt,这个文档比我介绍的更宏观,建议首先阅读IPA.txt,然后再阅读下面的内容。有问题的话,还望多多交流!
-----------------------------更新 2016-11-28--------------------------------
在介绍clang static analyzer函数inline机制之前,先介绍与clang过程间分析紧密相关的一系列预设选项。这些可设置的选项主要存放在AnalyzerOptions.h中。
AnalyzerOptions
这里只介绍和过程间分析相关的选项,其他的(例如清除DeadSymbol的频率等选项)我们后面有机会再介绍。
注:这里有两个选项需要特别注意,AnalysisConstraints和AnalysisDiagClients
AnalysisInlingMode - InliningMode
第一个选项是函数inline的选择标准,如下:
enum AnalysisInlingMode {
All, // Analyze all functions as top level
NoRedundancy, // Do not analyze a function which has been previously inlined
NumInliningModes
}
有三种模式,第一种模式分析所有顶层的函数(猜测:无论如何都要分析所有顶层的函数,无论是否曾经inline过),第二种模式没有冗余的分析(如果函数inline过,就不会再分析),第三种模式还没搞懂(了解者,请告知)。。。
CXXInlineableMemberKind - CXXMemberInliningMode
第二个选项是C++成员的inline类型,如下:
/// \brief Describes the different kinds of C++ member functions which can be
/// considered for inlining by the analyzer.
/// 设置其中一种kind,那么较低enum值的kind也会被设置
enum CXXInlineableMemberKind {
// Uninitialized = 0
/// A dummy mode in which no C++ inlining is enabled.
CIMK_None = 1,
/// Refers to regular member function and operator calls.
CINK_MemberFunctions,
/// Refers to constructors will not be inlined if the corresponding
/// destructor is non-trivial.
CIMK_Constructors,
/// Refers to destructors (implicit or explicit).
CIMK_Destructors
};
有四种模式,第一种是C++任何一种inline模式都没有指定,第二种是普通的成员函数都可以作为inline的候选函数, 第三种是构造函数可以作为inline的候选函数(隐含着第二种模式),第四种是析构函数可以作为inline的候选函数(隐含第二种以及第三种模式)。
IPAKind - IPAMode
第三个选项用于描述过程间分析(inter-procedural analysis)的几种模式。
/// \brief Describes the different modes of inter-procedural analysis.
enum IPAKind {
IPAK_NorSet = 0;
/// Perform only intra-procedural analysis.
IPAK_None = 1,
/// Inline C functions and blocks when their definitions are available.
IPAK_BasicInling = 2,
/// Inline callees(C, C++, ObjC) when their definitions are available.
IPAK_Inlining = 3,
/// Enable inling of dynamically dispatched methods.
IPAK_DynamicDispatch = 4,
/// Enable inlining of dynamically dispatched methods, bifurcate paths when
/// exact type info is unavailable.
IPAK_DynamicDispatchBifurcate = 5
};
第一种模式就是没有设置IPAKind;第二种模式仅仅进行过程内分析;第三种模式仅仅可能对C语言中有函数体的函数进行inline;第四种模式可能对C/C++/ObjC中有函数体的函数进行inline;第五种模式开启动态分派方法的inline(例如虚函数多态调用);第六种模式不仅对动态分派方法进行inline;而且还会进行二分估计(bifurcate,这里我不太懂,了解的请告知)。
一系列琐碎的选项
/// \sa includeTemporaryDtorsInCFG
Optional IncludeTemporaryDtorsInCFG;
/// \sa mayInlineCXXStandardLibrary
Optional InlineCXXStandardLibrary;
/// \sa mayInlineTemplateFunctions
Optional InlineTemplateFunctions;
/// \sa mayInlineCXXAllocator
Optional InlineCXXAllocator;
/// \sa mayInlineCXXContainerMethods
Optional InlineCXXContainerMethods;
/// \sa mayInlineCXXSharedPtrDtor
Optional InlineCXXSharedPtrDtor;
// Cache of the "ipa-always-inline-size" setting.
Optional AlwaysInlineSize;
/// \sa shouldSuppressNullReturnPaths
Optional SuppressNullReturnPaths;
// \sa getMaxInlinableSize
Optional MaxInlinableSize;
/// \sa getGraphTrimInterval
Optional GraphTrimInterval;
/// \sa getMaxTimesInlineLarge
Optional MaxTimesInlineLarge;
/// \sa getMinCFGSizeTreatFunctionsAsLarge
Optional MinCFGSizeTreatFunctionsAsLarge;
/// \sa getMaxNodesPerTopLevelFunction
Optional MaxNodesPerTopLevelFunction;
/// \sa shouldInlineLambdas
Optional InlineLambdas;
/// \sa shouldWidenLoops
Optional WidenLoops;
AnalyzerOptions各个选项的默认值
| 选项 | 默认值 |
|---|---|
| AnalysisConstraintsOpt | RangeConstraintsModel,采用基于Range的约束求解器 |
| AnalysisPurgeOpt | 清除DeadSymbol的粒度为单个Stmt |
| InliningMode | NoRedundancy,inline过,就不会再分析 |
| IPAMode | IPAK_NotSet,不设置过程间分析类型。注:构造函数中虽然设置的是IPAK_NotSet,但是在AnalyzerOptions::getIPAMode()中还是会根据UserMode(UMK_Deep)来设置为IPAK_DynamicDispatchBifurcate |
| InlineMaxStackDepth | 5,默认inline的栈深度为5,也就是inline 4次 |
| IncludeTemporaryDtorsInCFG | false,默认在CFG中不模拟临时对象的析构函数。但是可以使用"-cc1 -cfg-add-implicit-dtors"将临时对象的析构函数添加到CFG中 |
| InlineCXXStandardLibrary | true, 默认inline C++的库函数 |
| InlineTemplateFunctions | true,默认inline 模板函数 |
| InlineCXXAllocator | false, 默认不inline C++中的Allocator函数,例如new |
| InlineCXXContainerMethods | false, 默认不inline容器方法 |
| InlineCXXSharedPtrDtor | false, 默认不inline shared_ptr的析构函数 |
| SuppressNullReturnPaths | true,还没搞懂 |
| MaxInlinableSize | 50,默认能作为inline候选函数的函数体中基本块的个数上限 |
| GraphTrimInterval | 1000, 为了回收ExplodedGraph中的结点,设置ExplodedGraph图节点的大小 |
| MaxTimesInlineLarge | 32,大函数最多inline次数 |
| MinCFGSizeTreatFunctionsAsLarge | 14, 基本块个数大于14被认为是大函数 |
| MaxNodesPerTopLevelFunction | 150000, 顶层函数所能创建出的ExplodedNode的个数上限 |
| InlineLambdas | true, 默认inline lambda方法 |
| WidenLoops | false,静态分析默认loop模拟次数为4,但是这个选项暂时没有搞懂 |
clang函数inline入口
clang实现函数inline的源码在clang/lib/StaticAnalyzer/Core/ExprEngineCallAndReturn.cpp中,这里我们分析的入口函数是ExprEngine::evalCall(),该函数是分析引擎分析函数调用时的方法。
void ExprEnginge::evalCall(ExplodedNodeSet &Dst, ExplodedNode *Pred,
const CallEvent &Call) {
// Run any pre-call checks using the generic call interface
ExplodedNodeSet dstPreVisit;
getCheckerManager().runCheckersForPreCall(dstPreVisit, Pred, Call, *this);
// Actually evaluate the function call. We try each of the checkers
// to see if the can evaluate the function call, and get a callback at
// defaultEvalCall if all of them fail.
ExplodedNodeSet dstCallEvaluated;
getCheckerManager().runCheckersForEvalCall(dstCallEvaluated, dstPreVisit,
Call, *this);
// Finally, run any post-call checks.
getCheckerManager().runCheckersForPostCall(Dst, dstCallEvaluated,
Call, *this);
}
该函数主要分为三个部分,调用runCheckersForPreCall(),调用runCheckersForEvalCall(),调用runCheckersForPostCall()。其中函数runCheckersForEvalCall(),首先检查注册的checkers中是否存在能够对当前调用进行evaluate的checker,如果没有特定的checker对函数调用进行evaluate,那么就使用默认的evaluate机制defaultEvalCall()。
下面是**runCheckerForEvalCall()**主要逻辑:
- 遍历当前ExplodedGraph的边界,对每一个结点ExplodedNode进行evalCall()
- 针对一个ExplodedNode,遍历EvalCallCheckers,执行第一个注册的**evalCall()**回调函数
- 如果没有一个checker执行了evalCall()回调函数,那么执行defaultEvalCall()
defaultEvalCall()是clang static analyzer默认的函数evaluate机制,主要包括以下两个步骤:
- 第一步,判断函数调用能否进行inline
- 第二步,根据判断的结果,调用inlineCall()或者conservativeEvalCall()
判断函数是否可以inline
判断函数是否inline主要依赖于Callee本身的属性以及分析引擎当前的状态。如果Callee本身很复杂或者是extern的函数调用,那么不可能进行inline。如果分析引擎当前已经inline了过多的函数,stack的深度超过一定阈值,也会终止函数inline的过程。
函数本身属性
在函数defaultEvalCall()中,首先判断是否曾经尝试对当前函数进行过inline。如果曾经判断当前函数不能进行inline,那么就不会再尝试对当前函数进行inline,直接调用对该函数进行保守估计,亦即调用**conservativeEvalCall()**函数。
然后就会分析函数本身的性质来判断,当前函数是否适合inline,进行这一判断的方法是ExprEngine::shouldInlineCall(),下面是该函数的主体逻辑。
bool ExprEngine::shouldInlineCall(const CallEvent &Call, const Decl *D,
const ExplodedNode *Pred) {
// 1.首先判断Decl是否为空,为空则直接返回
if (!D)
return false;
// 2.获取一系列的辅助对象
AnalysisManager &AMgr = getAnalysisManager();
AnalyzerOptions &Opts = AMgr.options;
AnalysisDeclContextManager &ADCMgr = AMgr.getAnalysisDeclContextManager();
AnalysisDeclContext *CalleeADC = ADCMge.getContext(D);
// 3.进行一系列简单的判断
// Temporary object destructor processing is currently broken, so we never
// inline them.
// FIXME: Remove this once temp destructors are working.
if (isa) {
if ((*currBldrCtx->getBlock())[currStmtIdx].getAs())
return false;
}
// The auto-synthesized bodies are essential to inline as they are
// usually small and commonly used.
if (CalleeADC->isBodyAutosynthesized())
return true;
if (!AMgr.shouldInlineCall())
return false;
// 4.根据函数的summary信息来判断函数能否被inline。这里主要检查函数是否过于复杂
// Check if this function has been marked as non-inlinable
Optional MayInline = Engine.FunctionSummaries->mayInline(D);
if (MayInline.hasValue()) {
if (!MayInline.getValue())
return false;
}
else {
// We haven't actually checked the static properties of this function yet.
// Do that now, and record our decision in the function summaries.
// 这里的mayInlineDecl()主要用于检查函数体的静态属性
if (mayInlineDecl(CalleeADC, Opts)) {
// 可能被inline,将该信息存储到函数summary信息中
Engine.FunctionSummaries->markMayInline(D);
} else {
// 不能被inline,将该信息存储到函数summary信息中,并返回
Engine.FunctionSummaries->markShouldNotInline(D);
return false;
}
}
// 5.检查当前分析引擎的状态是否适合继续inline
// ...
}
上面分别有三种检查,我们依次介绍一下。
第一种就是简单的判断Decl是否为空,不多介绍。
第二种进行两个简单的判断,判断当前调用是否是C++临时对象的析构函数调用,如果是的话则直接返回(其实前面AnalyzerOptions中有一个选项,IncludeTemporaryDtorsInCFG,默认在CFG中不模拟临时对象的析构函数);然后判断是函数体是否是合成的isBodyAutosynthesized(),暂时还没搞懂!
第三种检查判断该函数调用是否曾经尝试过inline,如果曾经尝试inline并且inline失败,那么就放弃继续尝试。如果是第一次尝试inline,那么调用mayInlineDecl()来进行判断是否适合inline。该检查函数的逻辑如下:
static bool mayInlineDecl(AnalysisDeclContext *CalleeADC,
AnalyzerOptions &Opts) {
// FIXME: Do not inline variadic calls
// i.如果是变参函数调用,则不能进行inline
// 注:为什么不能实现变参函数inline,难道是无法正确模拟调用时C++的语义或者是
// 模拟栈内存?
if (CallEvent::isVariadic(CalleeADC->getDecl()))
return false;
// Check certain C++-related inlining policies.
// ii.判断C++相关的一系列inline选项
ASTContext &Ctx = CalleeADC->getASTContext();
if (Ctx.getLangOpts().CPlusplus) {
// Conditionally control the inlining of template functions.
// 判断AnalyzerOpts是否允许对模板函数进行inline,默认是允许的。
// 如果不允许且当前是模板函数调用,则返回false
if (!Opts.mayInlineTemplateFunctions())
if (FD->getTemplateKind() != FunctionDecl::TK_NonTemplate)
return false;
// Conditionally control the inlining of C++ standard library functions.
// 判断AnalyzerOpts是否允许inline C++库函数,默认是允许的。
// 如果不允许,当前函数位于系统头文件并且是std名称空间,则返回false
if (!Opts.mayInlineCXXStandardLibrary())
if (Ctx.getSourceManager().isInSystemHeader(FD->getLocation()))
if (AnalysisDeclContext::isInStdNamespace(FD))
return false;
// Conditionally control the inlining of methods on objects that look
// like C++ containers.
// 同上,判断是否允许inline C++容器函数,默认是不允许的
// Conditionally control the inlining of the destructor of C++ shared_ptr.
// We don't currently do a good job modeling shared_ptr because we can't
// see the reference count, so treating as opaque is probably the best
// idea.
// 注:这个信息很重要,说明clang static analyzer由于引用计数的原因,不能模拟出shared_ptr的语义
}
// iii. 如果CFG不能被正确创建,则返回false
// ...
// iv. 如果函数过于复杂,则不inline。如果函数内基本块个数大于上限,则不inline,默认上限是50.
// Do not inline large functions.
if (CalleeCFG->getNumBlockIDs() > Opts.getMaxInlinableSize())
return false;
// v. 如果不能进行变量活跃性分析,那么返回。虽然我认为这个说法有些鬼扯!
if (!CalleeADC->getAnalysis())
return false;
}
第四种涉及到分析引擎当前的状态,在下一小节进行介绍。
分析引擎当前状态
上面介绍的第四种检查就是需要通过当前分析引擎的状态,来判断是否适合继续进行inline。
// 4.检查当前分析引擎的状态是否适合继续inline
// Do not inline if recursive or weve reached max stack frame count.
bool IsRecursive = false;
unsigned StackDepth = 0;
// 4.1 通过当前的StackFrameContext,检查当前函数调用是否是递归调用以及栈深度是否过深
examineStackFrames(D, Pred->getLocationContext(), IsRecursive, StaclDepth);
if ((StackDepth >= Opts.InlineMaxStackDepth) &&
((CalleeCFG->getNumBlockIDs() > Opts.getAlwaysInlineSize())
|| IsRecursive))
return false;
// 4.2 如果当前函数是“大函数”,并且inline次数很多,则不会进行inline。
// “大函数”默认标准是14个基本块,“大函数”inline次数上限是32
// Do not inline large functions too many times.
if ((Engine.FunctionSummaries->getNumTimesInlined(D) >
Opts.getMaxTimesInlinedLarge()) &&
CalleeCFG->getNumBlockIDs() >=
Opts.getMinCFGSizeTreatFunctionsAsLarge()) {
NumReachedInlineCountMax++;
return false;
}
// 4.3 如果只是栈深度过深,但是当前函数非常小,属于"AlwaysInline"的类型
// 默认"AlwaysInline"的类型的基本块个数必须不大于3
if (HowToInline == Inline_Minimal &&
(CalleeCFG->getNumBlockIDs() > Opts.getAlwaysInlineSize()
|| IsRecursive))
return false;
Engine.FunctionSummaries->bumpNumTimesInlined(D);
return true;
至此判断函数是否能够inline的逻辑已经介绍完了,总结如下。
- 临时对象的析构函数调用,一定不会inline(暂时还没有实现)
- 如果AnalyzerOpts设置IPAMode为IPAK_None,则不会inline。默认是 IPAK_DynamicDispatchBifurcate
- 如果函数是合成函数,则永远inline。PS:暂时还不知道什么意思
- 如果当前函数是模板函数,且AnalyzerOpts设置InlineTemplateFunctions为false,则不inline。默认值为true
- 如果当前函数是库函数,且AnalyzerOpts设置InlineCXXStandardLibrary为false,则不inline。默认设置为true
- 如果当前函数C++容器方法,且AnalyzerOpts设置InlineCXXContainerMethods为false,则不inline。默认设置为false
- 如果当前函数是C++11中shared_ptr<>的析构函数,则不inline。由于分析引擎不知道确切的引用计数,所以不能对析构函数进行inline
- 如果函数CFG创建失败,则不能inline
- 如果函数过于复杂,则不会inline。复杂标准,基本块个数默认上限50
- 如果不能对该函数进行变量活跃性分析(live vairable analysis),则不能inline
- 如果当前inline栈存在递归,则不inline
- 如果当前inline栈深度过深,并且当前函数不属于**"AlwaysInline"类型,则不inline**。栈深度最大值默认是5层。如果函数基本块个数不大于3(默认值),则认为是**“AlwaysInline”**类型。
- 如果当前是**“大函数”,inline次数超过上限,则不inline**。“大函数”标准是基本块大于14,inline次数上限默认是32。
inlineCall
inlineCall是clang static analyzer进行过程间分析的主体,虽然clang static analyzer现在计划将函数摘要添加到clang static analyzer中,但是现在还没有实现。
理解inlineCall最直观的方式,就是将其看作一次普通的函数调用过程。或者是使用llvm的解释器来进行对照,两者再处理CallEvent的过程很相似,都需要模拟栈帧,都需要进行参数的传递。
我们首先看一下LLVM解释器在处理函数调用时的几个重要的步骤,LLVM解释器源码在llvm/lib/ExecutionEngine/Interpreter/Execution.cpp,下面是函数**Interpreter::visitCallSite(CallSite CS)**的主要代码。
void Interpreter::visitCallSite(CallSite CS) {
// 1.获取当前函数所处的栈帧
ExecutionContext &SF = ECStack.back();
// ...
// 2.设置当前函数调用所处的调用点,联想StackFrameContext中也有一个数据成员是CallSite
SF.Caller = CS;
// 3.获取此次函数调用所需要的实参的值
std::vector ArgVals;
const unsigned NumArgs = SF.Caller.arg_size();
ArgVals.reserve(NumArgs);
// 循环获取实参值
for ()
{
// ArgVals.push_back(getOperandValue(V, SF));
}
// 3.获取函数地址,传递实参值进行调用
GenericValue SRC = getOperandValue(SF.Caller.getCalledValue(), SF);
// 此处进行真正的调用过程
callFunction((Function*)GVTOP(SRC), ArgVals);
}
void Interpreter::callFunction(Function *F, ArrayRef ArgVals) {
// 4. 简历新的栈帧,new ExecutionContext
// Make a new stack frame.. and fill it in
ECStack.emplace_back();
// 新的栈帧
ExecutionContext &StackFrame = ECStack.back();
StackFrame.CurFunction = F;
// 5.获取Callee的第一条指令
// Get pointers to first LLVM BB & Instruction in function.
StackFrame.CurBB = &F->front();
StackFrame.CurInst = StackFrame.CurBB->begin();
// 6.将实参的值,传递到Callee栈帧中
// Handle non-varargs arguments...
unsigned i = 0;
for (Function::arg_iterator AI = F->arg_begin(), E = F->arg_end();
AI != E; ++AI, ++i)
SetValue(&*AI, ArgVals[i], StackFrame);
// Handle varargs argument...
// 有些不同的是clang static analyzer不能处理变参函数调用inline
}
从上面LLVM解释器的几个步骤我们可以类推出inlineCall需要完成以下几个工作。
- 获取当前StackFrameContext,并CallSite相关信息,例如调用语句等。
- 获取当前CallEvent需要的实参值
- 创建新的栈帧StackFrameContext
- 将实参值传递到Callee的栈帧StackFrameContext
- 获取Callee的入口语句进行分析
按照上面几个工作,我们对应着分析一下**inlineCall()的逻辑。函数inlineCall()**的主体代码如下:
bool ExprEngine::inlineCall(const CallEvent &Call, const Decl *D,
NodeBuilder &Bldr, ExplodedNode *Pred,
ProgramStateRef State) {
// 1.获取当前函数栈帧,并设置当前CallSite
const LocationContext *CurLC = Pred->getLocationContext();
// 获取Caller栈帧
const StackFrameContext *CallerSFC = CurLC->getCurrentStateFrame();
// 设置调用语句
const LocationContext *ParentOfCallee = CallerSFC;
// 2.创建新的栈帧StackFrameContext
// Construct a new stack frame for the callee.
AnalysisDeclContext *CalleeADC = AMgr.getAnalysisDeclContext(D);
const StackFrameContext *CalleeSFC =
CalleeADC->getStackFrame(ParentOfCallee, CallE,
currBldrCtx->getBlock(),
currStmtIdx);
// 3.创建新的ProgramState,表示进入新的函数调用状态,并将实参值传递到CalleeStaclFrame中。
// 其中enterStackFrame()会完成获取实参值并将其传递到Callee栈帧的步骤。
State = State->enterStackFrame(Call, CalleeSFC);
// 4.创建新的ExplodedNode,并将该Node放入WorkList工作队列,此时就可以开始新的过程内分析。
if (ExplodedNode *N = G.getNode(Loc, State, false, &isNew)) {
N->addPredecessor(Pred, G);
if (isNew)
Engine.getWorkList()->enqueue(N);
}
// 5.设置分析引擎inline相关的信息,例如自增分析引擎总共的inline次数
NumInlinedCalls++;
}
上面我们列出了inlineCall()的几个步骤,除了创建新的ExplodedNode以外,其余的和LLVM解释器处理CallEvent的几个步骤相同。只是上面我们忽略了实参值如何传递到Callee栈帧的过程,该过程由**enterStackFrame()**完成。下面我们大致分析一下该函数。
ProgramStateRef ProgramState::enterStackFrame(const CallEvent &Call,
const StackFrameContext *CalleeCtx) const {
// 获取实参值,更新OldStore得到NewStore
const StoreRef &NewStore =
getStateManager().StoreMgr->enterStackFrame(getStore(), Call, CalleeCtx);
// 将新的Store更新到当前ProgramState中
return makeWithStore(NewStore);
}
// 下面我们分析一下StoreManager::enterStackFrame()函数
StoreRef StoreManager::enterStackFrame(Store OldStore,
const CallEvent &Call,
const StackFrameContext *LCtx) {
StoreRef Store = StoreRef(OldStore, *this);
// 声明InitialBindings用来存储实参值,其中FrameBindingTy是std::pair
// 类似LLVM中的std::vector ArgVals
SmallVector InitialBindings;
// 通过CallEvent从原有Store中获取到实参的值
Call.getInitalStackFrameContents(LCtx, InitalBindings);
// 将获取到的实参值SVal,绑定在Callee栈帧对应的位置(Loc)
for (CallEvent::BindingsTy::iterator I = InitialBindings.begin(),
E = InitialBindings.end();
I != E; ++I) {
// I->first是新的函数栈帧ParmDecl对应的内存VarRegion
// I->second对应的是实参的值SVal
Store = Bind(Store.getStore(), I->first, I->second);
}
// 返回新的Store
return Store;
}
至此我们算是搞清楚了inlineCall()需要的几个步骤,但是还有一个疑问,就是实参值的到底存储到了哪里,我们怎么获取到的。该疑问对应着上面代码中最后的I-first以及I->second。下面我们分析一下**getInitialStackFrameContents()**函数,里面有对于该疑问的解答。
void AnyFunctionCall::getInitalStackFrameContents(
const StackFrameContext *CallCtx,
BindingsTy &Bindings) const {
// 前面两条语句提供不了有价值的信息,我们继续分析addParameterValuesToBindings()函数
const FunctionDecl *D = cast(CalleeCtx->getDecl());
SValBuilder &SVB = getState()->getStateManager().getSValBuilder();
addParameterValuesToBindings(CalleeCtx, Bindings, SVB, *this,
D->parameters());
}
// addParameterValuesToBindings()函数不是很复杂,但是传入的参数很多,我们一一说明
// (1)CalleeCtx,前面我们在介绍MemRegion时提到过,Region对应LocationContext,此处的CalleeCtx用于创建VarRegion
// (2)Bindings,这个用于存储ParmVarDecl的MemRegion,以及Caller实参的值
// (3)SVB,在分析引擎中,地址也是一种SVal(loc类型),需要SValBuilder创建ParmVarRegion对应的地址
// (4)Call,用于获取实参值SVal
// (5)parameters,创建新的ParmVarRegion的时候,我们会用到ParmVarDecl
static void addParameterValuesToBindings(const StackFrameContext *CalleeCtx,
CallEvent::BindingsTy &Bindings,
SValBuilder &SVB,
const CallEvent &Call,
Array parameters) {
// 获取参数个数
unsigned NumArgs = Call.getNumArgs();
unsigned Idx = 0;
ArrayRef::iterator I = parameters.begin(), E = parameters.end();
for (; I != E && Idx < NumArgs; ++I, ++Idx) {
const ParmVarDecl *ParamDecl = *I;
// 获取实参的SVal值
SVal ArgVal = Call.getArgSVal(Idx);
if (!ArgVal.isUnknown()) {
// 根据StackFrameContext,创建新的VarRegion。并使用SValBuilder创建新的SVal地址。
Loc ParamLoc = SVB.makeLoc(MRMgr.getVarRegion(ParamDecl, CalleeCtx));
// 将CalleeStackFrameContext中Parm对应的地址SVal,以及实SVal参值存放在Bindings,注意此处并没有进行Bind
Bindings.push_back(std::make_pair(ParamLoc, ArgVal));
}
}
// 不支持变参调用
}
后面会介绍分析引擎evalCall时所采用的另外两种方法,保守估计ConservativeEvalCall()以及二分估计BifurcateCall()。