swift对象存储
swift对象存储
简介
OpenStack Object Storage(Swift)是OpenStack开源云计算项目的子项目之一,被称为对象存储,提供了强大的扩展性、冗余和持久性。对象存储,用于永久类型的静态数据的长期存储。
Swift 最初是由 Rackspace 公司开发的高可用分布式对象存储服务,并于 2010 年贡献给 OpenStack 开源社区作为其最初的核心子项目之一,为其 Nova 子项目提供虚机镜像存储服务。Swift 构筑在比较便宜的标准硬件存储基础设施之上,无需采用 RAID(磁盘冗余阵列),通过在软件层面引入一致性散列技术和数据冗余性,牺牲一定程度的数据一致性来达到高可用性和可伸缩性,支持多租户模式、容器和对象读写操作,适合解决互联网的应用场景下非结构化数据存储问题。
基本原理
1.一致性散列(Consistent Hashing)
面对海量级别的对象,需要存放在成千上万台服务器和硬盘设备上,首先要解决寻址问题,即如何将对象分布到这些设备地址上。Swift 是基于一致性散列技术,通过计算可将对象均匀分布到虚拟空间的虚拟节点上,在增加或删除节点时可大大减少需移动的数据量;虚拟空间大小通常采用 2 的 n 次幂,便于进行高效的移位操作;然后通过独特的数据结构 Ring(环)再将虚拟节点映射到实际的物理存储设备上,完成寻址过程。 
以逆时针方向递增的散列空间有 4 个字节长共 32 位,整数范围是[0~232-1];将散列结果右移 m 位,可产生 232-m个虚拟节点,例如 m=29 时可产生 8 个虚拟节点。在实际部署的时候需要经过仔细计算得到合适的虚拟节点数,以达到存储空间和工作负载之间的平衡。
2.数据一致性模型
按照 Eric Brewer 的 CAP(Consistency,Availability,Partition Tolerance)理论,无法同时满足 3 个方面,Swift 放弃严格一致性(满足 ACID 事务级别),而采用最终一致性模型(Eventual Consistency),来达到高可用性和无限水平扩展能力。为了实现这一目标,Swift 采用 Quorum 仲裁协议(Quorum 有法定投票人数的含义):
(1)定义:N:数据的副本总数;W:写操作被确认接受的副本数量;R:读操作的副本数量
(2)强一致性:R+W>N,以保证对副本的读写操作会产生交集,从而保证可以读取到最新版本;如果 W=N,R=1,则需要全部更新,适合大量读少量写操作场景下的强一致性;如果 R=N,W=1,则只更新一个副本,通过读取全部副本来得到最新版本,适合大量写少量读场景下的强一致性。
(3)弱一致性:R+W<=N,如果读写操作的副本集合不产生交集,就可能会读到脏数据;适合对一致性要求比较低的场景。
Swift 针对的是读写都比较频繁的场景,所以采用了比较折中的策略,即写操作需要满足至少一半以上成功 W >N/2,再保证读操作与写操作的副本集合至少产生一个交集,即 R+W>N。Swift 默认配置是 N=3,W=2>N/2,R=1 或 2,即每个对象会存在 3 个副本,这些副本会尽量被存储在不同区域的节点上;W=2 表示至少需要更新 2 个副本才算写成功;当 R=1 时意味着某一个读操作成功便立刻返回,此种情况下可能会读取到旧版本(弱一致性模型);当 R=2 时,需要通过在读操作请求头中增加 x-newest=true 参数来同时读取 2 个副本的元数据信息,然后比较时间戳来确定哪个是最新版本(强一致性模型);如果数据出现了不一致,后台服务进程会在一定时间窗口内通过检测和复制协议来完成数据同步,从而保证达到最终一致性。 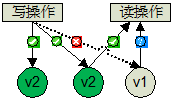
3.环的数据结构
环是为了将虚拟节点(分区)映射到一组物理存储设备上,并提供一定的冗余度而设计的,其数据结构由以下信息组成:
存储设备列表、设备信息包括唯一标识号(id)、区域号(zone)、权重(weight)、IP 地址(ip)、端口(port)、设备名称(device)、元数据(meta)。
分区到设备映射关系(replica2part2dev_id 数组)
计算分区号的位移(part_shift 整数,即图 1 中的 m)
以查找一个对象的计算过程为例: 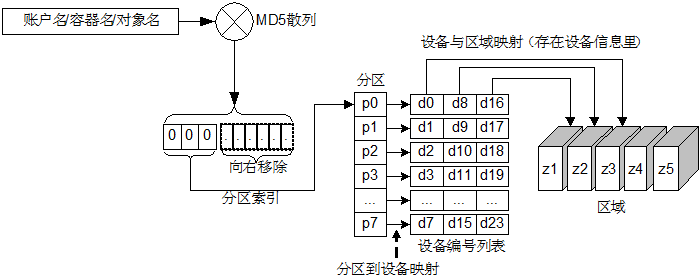
使用对象的层次结构 account/container/object 作为键,使用 MD5 散列算法得到一个散列值,对该散列值的前 4 个字节进行右移操作得到分区索引号,移动位数由上面的 part_shift 设置指定;按照分区索引号在分区到设备映射表(replica2part2dev_id)里查找该对象所在分区的对应的所有设备编号,这些设备会被尽量选择部署在不同区域(Zone)内,区域只是个抽象概念,它可以是某台机器,某个机架,甚至某个建筑内的机群,以提供最高级别的冗余性,建议至少部署 5 个区域;权重参数是个相对值,可以来根据磁盘的大小来调节,权重越大表示可分配的空间越多,可部署更多的分区。
Swift 为账户,容器和对象分别定义了的环,查找账户和容器的是同样的过程。
4.数据模型
Swift 采用层次数据模型,共设三层逻辑结构:Account/Container/Object(即账户/容器/对象),每层节点数均没有限制,可以任意扩展。这里的账户和个人账户不是一个概念,可理解为租户,用来做顶层的隔离机制,可以被多个个人账户所共同使用;容器代表封装一组对象,类似文件夹或目录;叶子节点代表对象,由元数据和内容两部分组成,如图 4 所示: 
5.系统架构
Swift 采用完全对称、面向资源的分布式系统架构设计,所有组件都可扩展,避免因单点失效而扩散并影响整个系统运转;通信方式采用非阻塞式 I/O 模式,提高了系统吞吐和响应能力。 
代理服务(Proxy Server):对外提供对象服务 API,会根据环的信息来查找服务地址并转发用户请求至相应的账户、容器或者对象服务;由于采用无状态的 REST 请求协议,可以进行横向扩展来均衡负载。 认证服务(Authentication Server):验证访问用户的身份信息,并获得一个对象访问令牌(Token),在一定的时间内会一直有效;验证访问令牌的有效性并缓存下来直至过期时间。 缓存服务(Cache Server):缓存的内容包括对象服务令牌,账户和容器的存在信息,但不会缓存对象本身的数据;缓存服务可采用 Memcached 集群,Swift 会使用一致性散列算法来分配缓存地址。 账户服务(Account Server):提供账户元数据和统计信息,并维护所含容器列表的服务,每个账户的信息被存储在一个 SQLite 数据库中。 容器服务(Container Server):提供容器元数据和统计信息,并维护所含对象列表的服务,每个容器的信息也存储在一个 SQLite 数据库中。 对象服务(Object Server):提供对象元数据和内容服务,每个对象的内容会以文件的形式存储在文件系统中,元数据会作为文件属性来存储,建议采用支持扩展属性的 XFS 文件系统。 复制服务(Replicator):会检测本地分区副本和远程副本是否一致,具体是通过对比散列文件和高级水印来完成,发现不一致时会采用推式(Push)更新远程副本,例如对象复制服务会使用远程文件拷贝工具 rsync 来同步;另外一个任务是确保被标记删除的对象从文件系统中移除。 更新服务(Updater):当对象由于高负载的原因而无法立即更新时,任务将会被序列化到在本地文件系统中进行排队,以便服务恢复后进行异步更新;例如成功创建对象后容器服务器没有及时更新对象列表,这个时候容器的更新操作就会进入排队中,更新服务会在系统恢复正常后扫描队列并进行相应的更新处理。 审计服务(Auditor):检查对象,容器和账户的完整性,如果发现比特级的错误,文件将被隔离,并复制其他的副本以覆盖本地损坏的副本;其他类型的错误会被记录到日志中。 账户清理服务(Account Reaper):移除被标记为删除的账户,删除其所包含的所有容器和对象。
特性
1.极高的数据持久性
数据持久性和系统可用性不同,指的是数据的可靠性,数据存储到系统后,到某一天丢失的可能性。AS3的数据持久性是11个9,即如果存储1万个(4个0)文件到S3中,1千万(7个0)年之后,可能会丢失1个文件。
我们从理论上测算过,Swift在5个Zone、5×10个存储节点的环境下,数据复制份是为3,数据持久性的SLA能达到10个9。
2.完全对称的系统架构
“对称”意味着Swift中各节点可以完全对等,能极大地降低系统维护成本。
无限的可扩展性
(1)数据存储容量无限可扩展;(2)Swift性能(如QPS、吞吐量等)可线性提升
Swift是完全对称的架构,扩容只需简单地新增机器,系统会自动完成数据迁移等工作,使各存储节点重新达到平衡状态。
3.无单点故障
元数据问题,Swift的元数据存储是完全均匀随机分布的,并且与对象文件存储一样,元数据也会存储多份。
4.简单、可依赖
设计简单
应用场景
最典型的应用是网盘类的存储引擎,比如Dropbox背后使用的就是AS3。在OpenStack中还可以与镜像服务Glance结合,为其存储镜像文件。另外,由于Swift的无限扩展能力,非常适合用于存储日志文件和数据备份仓库。
架构概述
Swift主要有三个组成部分:Proxy Server、Storage Server和Consistency Server。其架构如图1所示,其中Storage和Consistency服务均允许在Storage Node上。Auth认证服务目前已从Swift中剥离出来,使用OpenStack的认证服务Keystone,目的在于实现统一OpenStack各个项目间的认证管理。
API接口
Swift 通过 Proxy Server 向外提供基于 HTTP 的 REST 服务接口,对账户、容器和对象进行 CRUD 等操作。在访问 Swift 服务之前,需要先通过认证服务(keystone)获取访问令牌,然后在发送的请求中加入头部信息 X-Auth-Token。下面是请求返回账户中的容器列表的示例:
GET /v1/ HTTP/1.1
Host: storage.swift.com
X-Auth-Token: eaaafd18-0fed-4b3a-81b4-663c99ec1cbb
响应头部信息中包含状态码 200,容器列表包含在响应体中:
HTTP/1.1 200 Ok
Date: Thu, 07 Jan 2013 18:57:07 GMT
Server: Apache
Content-Type: text/plain; charset=UTF-8
Content-Length: 32
images
movies
documents
backups 
结束语
OpenStack Swift 作为稳定和高可用的开源对象存储被很多企业作为商业化部署,如新浪的 App Engine 已经上线并提供了基于 Swift 的对象存储服务,韩国电信的 Ucloud Storage 服务。有理由相信,因为其完全的开放性、广泛的用户群和社区贡献者,Swift 可能会成为云存储的开放标准,从而打破 Amazon S3 在市场上的垄断地位,推动云计算在朝着更加开放和可互操作的方向前进。
一切才是开始
看完swift,发现原来云计算领域更为庞大。。。一切学习都是开始啊!
基于Quorum投票的冗余控制算法
1.简介
Quorom 机制,是一种分布式系统中常用的,用来保证数据冗余和最终一致性的投票算法,其主要数学思想来源于鸽巢原理。
在有冗余数据的分布式存储系统当中,冗余数据对象会在不同的机器之间存放多份拷贝。但是同一时刻一个数据对象的多份拷贝只能用于读或者用于写。
该算法可以保证同一份数据对象的多份拷贝不会被超过两个访问对象读写。
算法来源于[Gifford, 1979][3][1]。 分布式系统中的每一份数据拷贝对象都被赋予一票。每一个操作必须要获得最小的读票数(Vr)或者最小的写票数(Vw)才能读或者写。如果一个系统有V票(意味着一个数据对象有V份冗余拷贝),那么这最小读写票必须满足:
Vr + Vw > V
Vw > V/2
第一条规则保证了一个数据不会被同时读写。当一个写操作请求过来的时候,它必须要获得Vw个冗余拷贝的许可。而剩下的数量是V-Vw 不够Vr,因此不能再有读请求过来了。同理,当读请求已经获得了Vr个冗余拷贝的许可时,写请求就无法获得许可了。
第二条规则保证了数据的串行化修改。一份数据的冗余拷贝不可能同时被两个写请求修改。
2.应用
在分布式系统中,冗余数据是保证可靠性的手段,因此冗余数据的一致性维护就非常重要。一般而言,一个写操作必须要对所有的冗余数据都更新完成了,才能称为成功结束。比如一份数据在5台设备上有冗余,因为不知道读数据会落在哪一台设备上,那么一次写操作,必须5台设备都更新完成,写操作才能返回。
对于写操作比较频繁的系统,这个操作的瓶颈非常大。Quorum算法可以让写操作只要写完3台就返回。剩下的由系统内部缓慢同步完成。而读操作,则需要也至少读3台,才能保证至少可以读到一个最新的数据。
Quorum的读写最小票数可以用来做为系统在读、写性能方面的一个可调节参数。写票数Vw越大,则读票数Vr越小,这时候系统写的开销就大。反之则写的开销就小。
文章参考如下两篇文章:
http://www.ibm.com/developerworks/cn/cloud/library/1310_zhanghua_openstackswift/
http://www.cnblogs.com/netfocus/p/3622184.html