Twitter Data Analysis – Text Mining on President Trump Tweets Behavior
Twitter Data Analysis – Text Mining on President Trump Tweets Behavior
Abstract
Social media have played an important role nowadays. Twitter is one of the most popular social platform for people to express their emotions or opinions and it is also a good place to get information. There are large amounts of contents produced by users. It not only produces massive unstructured textual data but also real-time opinions. As a result, this paper describes a case study which applies text mining to analyze contents on President Donald Trump ‘s Twitter. This study applies different text mining techniques to to analyze Donald Trump’s tweets. The study reveals that President Trump tended to post more tweets around last quarter of 2017 and during the same period of time, President Trump’s tweets are slightly more positive than other quarters. Furthermore, the Android tweets are more negative than iPhone tweets and the Android tweets are more emotional than iPhone tweets because it goes up and down frequently.
Keywords: Twitter, Donald Trump, text mining, frequency, correlation, sentiment analysis
1. Introduction
Social media have played an important role nowadays. Most people like to use social media to connect with one another, share the information. Twitter is one of the most popular social platform for people to express their emotions or opinions and it is also a good place to get information. Even American President Donald Trump has tweeted: “I love Twitter… it’s like owning your own newspaper— without the losses.” The central focus of this project is to analyze Donald Trump’s Twitter activity using different methods of text mining. I am going to analyze what President Trump is posting on Twitter and find out the relationship of those tweets. It is interesting to know President Trump’s Twitter behavior by taking advantage of text mining.
The data is extracted from Twitter. There are 3195 tweets that posted by President Donald Trump from 01/09/2017 to 04/24/2018. There is a lot of clean-up with social media data. It includes:
1. Removing punctuations
2. Turn every word to lowercase
3. Removing numbers
4. Removing Hyperlinks
5. Removing Stop words
6. Removing White Space
In the exploratory data analysis, term document matrix has been made in order to find the frequencies of words. Word Cloud and Bar Chart are used to present the result of word frequency. Moreover, word correlations technique is applied in order to know what word is most likely to be with tax, healthcare, border and fake news in a document and to have a better opinion among these issues that Trump has mentioned during his election. Furthermore, I take advantage of sentiment analysis to plot Trump’s sentiment scale. It uses the sentiment score as the y-axis and time as the x-axis to find out whether Trump’s sentiment has changed on Twitter. In addition, I also apply sentiment analysis to compare tweets sent from iPhone and Android phone.
2. Data retrieval and data preparation
R is a programming language and software environment intended for deep statistical computing and graphics. It is now used in a variety of applications including visualizations and data mining. The data is extracted from Twitter by using the twitteR package. In this project, userTimeline function is used to access the twitter API. By searching for the user “realDonaldTrump” Twitter, this function will return 3195 tweets that posted by President Donald Trump from 01/09/2017 to 04/24/2018. Each case in the dataset represents one tweet. In the dataset, there are 16 variables. However, in this project, we only keep columns text, created, source. Text represents all the tweets that posted by President Donald Trump. Created is the variable records the time this tweet had been posted. Source is the variable indicates whether this tweet is sent from iPhone or Android phone.

Because the data is retrieved from Twitter where People have a different way of writing, it is difficult to do text mining without cleaning it. There is a lot of clean-up with social media data. In the figure 1, we can see there are URL’s links and symbols in the text. First of all, the URL’s won’t be helpful if we want to do text mining. URL should be removed first. In addition, if we attempt to create a list of unique words, we should be aware that uppercase of a word is different from lowercase of the word. In this case, we need to transfer all the words into lowercase. Moreover, sometimes punctuations are useful in the sentiment analysis. However, it is really complicated so that we will remove all the punctuations. Furthermore, numbers are meaningless in the text mining so all numbers will be removed as well. We will also eliminate extra white spaces and anything other than English letters or space in each tweet. Last but not least, some commonly used words such as “a”, “the”, “this” will be ignored from text analysis because they are used to compose a sentence not so that they are not meaningful at all. These words are usually called “Stop Words”.
3. Basic Exploratory data analysis
First of all, the term document matrix represents the text as a table whose columns are binary variables that correspond to the words used in the analysis (Jurafsky & Martin, 2017). Each row represents one of the tweets, and each column represents one of the words by taking a value of 1 when the word is present in the text and a value of 0 when it is not. So in the matrix, each entry (i, j) represents term i frequency in document j. For example, if we have three documents:
d1 = I like eating.
d2 = I like camping.
d3 = I dislike eating.
The document-term matrix is shown in table 1.
The reason we build the document-term matrix is it will return the term frequency if we sum the row. Based on the term-document matrix, we are able to build the word cloud, which is a way to visualize the importance of each word. The bigger of the word font size is, the more frequent the appears in the document. In the figure 2, those big words are: “fake”, “news”, “big”, “tax”, “American”, “border”, “today”, “thank”.
Even tough word cloud is simple and fancy. However, not all people like it because word cloud sometimes is not accurate and may lose some information. Instead of using word cloud, people take advantage of histogram to show the frequency of word.

In the figure 3, the histogram presents all the words that their frequencies are over 100. There are “great”, “honor”, “years”, “time”, “country”, “amp”, “more”, “jobs”, “America” etc. in the diagram. The histogram is more accurate than word cloud but it can only show some of the words in the diagram.

4. Word Correlation by Topic
In order to know what word is most likely to be with the given words in a document, and to have a better opinion among some specific issues that Trump has mentioned during his election, I take advantage of word correlations technique. The correlation is a quantitative measure of the co-occurrence of words in multiple documents (Kumar & Paul, 2016). It is a measure of frequency with search and result term show up together in documents. A correlation of 0.4 means that the terms and search term have co-occurrence of 40%. In this project, we focus on the 4 topics that President Trump have mentioned: tax, healthcare, border and fake news. It is interesting to know what kind of words are associated with these four topics when President Trump tweeted.
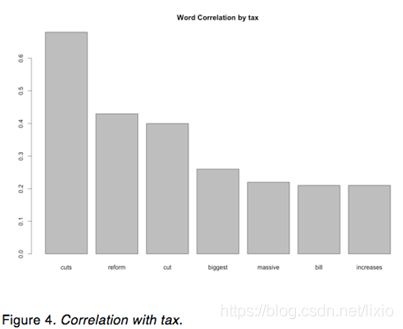
In figure 4, when President Trump talks about Tax on Twitter, “Cut”, “reform”, “biggest”, “massive”, “bill”, and “increase” are more likely to associate with “Tax”.
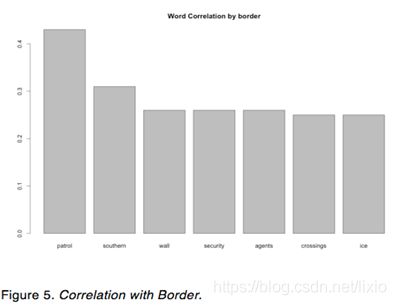
In figure 5, when President Trump talks about Border on Twitter, “Patrol”, “southern”, “wall”, “security”, “agents”, “crossings”, “ice” are more likely to associate with “Border”.
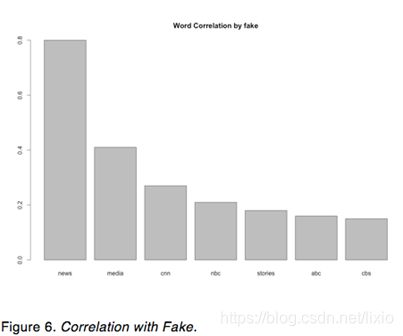
In figure 6, when President Trump talks about fake on Twitter, “News”, “media”, “cnn”, “nbc”, “stories”, “abc”, “cbs” are more likely to associate with “Fake”.
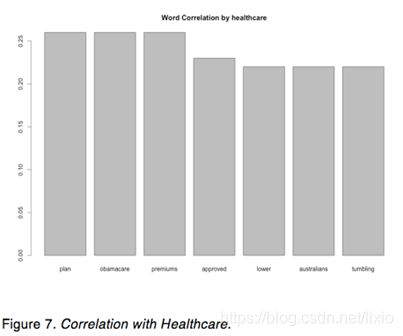
In figure 7, when President Trump talks about healthcare on Twitter, “Plan”, “obamacare”, “premiums”, “approved”, “lower”, “Australians”, “tumbling” are more likely to associate with “Healthcare”.
5. Sentiment data analysis
Recently, sentiment analysis is becoming more and more popular in industry and the media. Many companies are using sentiment analysis to find out what people talk about them on social media. Sentiment analysis is the computational task of automatically determining what feelings a writer is expressing in text (Tatman, 2017). There are many ways to do sentiment analysis, which includes different machine learning method to classify the words. However, most approaches use the same general idea (Tatman, 2017):
- Create a list of words that has strongly positive or negative sentiment. This list of words associated with a specific sentiment is called “sentiment lexicon”. People have used different classifiers to determine the sentiment lexicon. These classifiers include: keyword-based, Naive Bayes, maximum entropy, and support vector machines.
- Count the number of positive and negative words in the text.
- Analyze the document with mix of positive and negative words. If document has many positive words and few negative words, the document is determined to be positive sentiment. On the contrary, if it has many negative words and few positive words then it is negative sentiment.
Even though sentiment analysis has been widely used. There are some challenges in sentiment analysis (Go, Bhayani & Huang): - People have a different way of writing and while posting on Twitter, misspelling of words or using slangs are sometimes difficult for sentiment analysis.
- There are emoticons that can express positive emotion and negative emotion. For example, ?.
In this project, I use sentiment140 package in R to perform sentiment analysis. This package has already used training data to train the classifier, which is Maximum Entropy classifier. I am using this package to determine whether the term is positive, negative or neutral. After deciding the word polarity, I assign the score to positive, negative and neutral. For example, 1 is assigned to Positive; -1 is assigned to Negative; 0 is assigned to Neutral. To decide the polarity of the tweet, I simply add up the scores of words. If the score is greater 0, the tweet is positive. If it is smaller than 0, then the tweet is negative. For instance: we have a document “I like apple”. The scores of “I” and “apple” are 0. The score of “like” is 1. Thus, the score of this document is 0 + 1 + 0 = 1, which means the document is positive.
I calculate the sentiment score of each day from 01/09/2017 to 04/24/2018 and build the line plot in figure 8. And figure 9 presents the bar plot of the total number of tweets in each month.
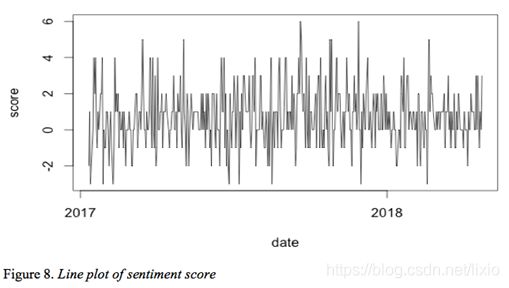

By comparing figure 8 and 9, the bar plot indicates that President Trump tends to post more tweets around last quarter of 2017. The line plot of sentiment score of tweets shows that during the same time President Trump’s tweets are slightly more positive than other quarters.
In 2016, Data scientist David Robinson. By using different method, he concluded that the Android and iPhone tweets are clearly from different people, posting during different times of day and using hashtags, links, and retweets in distinct ways (Robinson, 2016). Inspired by his work, I am using sentiment analysis on my data to see if there is a difference between tweets sent from iPhone and Android.
However, because the device, Samsung Galaxy S3, has serious security problems, there is no tweets posted from Android phone after March 25th 2017. In order to compare the tweets sent from two kinds of phones, I use the tweets that sent from Android and iPhone between 01/09/17 and 03/25/17.
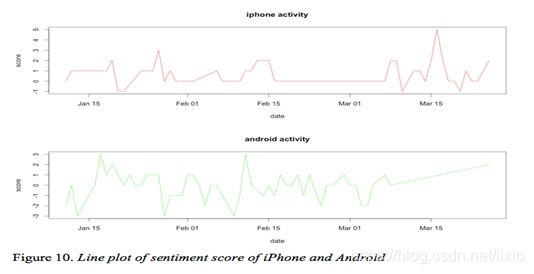
In figure 10, the Android tweets are more negative than iPhone tweets. The score of iPhone tweets is between -1 and 5 while the score of Android tweet is between -3 and 3. Moreover, The Android tweets are more emotional than iPhone tweets because it goes up and down frequently.
6. Conclusion
According to the bar plot, the words “great”, “honor”, “years”, “time”, “country”, “amp”, “more”, “jobs”, “America” have highest frequency in President Trump’s tweets. In addition, when President Trump talks about Tax on Twitter, “Cut”, “reform”, “biggest”, “massive”, “bill”, and “increase” are more likely to associate with “Tax”; when President Trump talks about Border on Twitter, “Patrol”, “southern”, “wall”, “security”, “agents”, “crossings”, “ice” are more likely to associate with “Border”; when President Trump talks about fake on Twitter, “News”, “media”, “cnn”, “nbc”, “stories”, “abc”, “cbs” are more likely to associate with “Fake”; when President Trump talks about healthcare on Twitter, “Plan”, “obamacare”, “premiums”, “approved”, “lower”, “Australians”, “tumbling” are more likely to associate with “Healthcare”. Moreover, President Trump tended to post more tweets around last quarter of 2017 and during the same period of time, President Trump’s tweets are slightly more positive than other quarters. Furthermore, the Android tweets are more negative than iPhone tweets and the Android tweets are more emotional than iPhone tweets because it goes up and down frequently.
7. Reference
Jurafsky, D., & Martin, J. (2017). Speech and Language Processing. Retrieved April 24, 2018,
from https://web.stanford.edu/~jurafsky/slp3/15.pdf
Kumar, A., & Paul, A. (2016). Mastering text mining with R. Birmingham, UK: Packt Publishing
Limited.
Robinson, D. (2016, August 9). Text analysis of Trump’s tweets confirms he writes only the
(angrier) Android half. Retrieved April 24, 2018, from http://varianceexplained.org/r/trump-tweets/
Tatman, R. (2017, October 05). Data Science 101: Sentiment Analysis in R Tutorial. Retrieved
April 24, 2018, from http://blog.kaggle.com/2017/10/05/data-science-101-sentiment-analysis-in-r-tutorial/
Go, A., Bhayani, R., & Huang, L. (n.d.). Twitter Sentiment Classification using Distant
Supervision. Retrieved April 24, 2018, from https://www.bing.com/cr?IG=6A7F4EE517FA4BCBB96699D9C2141479&CID=36BD7446279A618930127F9B2697608D&rd=1&h=q76wdcSxY_0wjF2kLz6W53FDUe6853yX76e97OWpmFs&v=1&r=https://cs.stanford.edu/people/alecmgo/papers/TwitterDistantSupervision09.pdf&p=DevEx.LB.1,5495.1