【操作系统】Oranges学习笔记(四) 第五章 内核雏形
文章目录
- 5.1 在Linux下用汇编写HelloWord
- 5.2 再进一步,汇编和C同步使用
- 5.3 ELF(Executable and Linkable Format)
- 1. ELF Header
- 2. Program header
- 5.4 从Loader到内核
- 1. 用Loader加载ELF
- 2. 跳入保护模式
- 3. 重新放置内核
- 4. 向内核交出控制权
- 5.5 扩充内核
- 1. 切换堆栈和GDT
- 2. 整理我们的文件夹
- 3. Makefile
- 4. 添加中断处理
- 5. 说明
- 5.6 小结
5.1 在Linux下用汇编写HelloWord
Loader需要完成从实模式向保护模式的跳转,还是应该把GDT、LDT、8259A等内容都准备完毕?
在Linux下写汇编:(chapter5/a/hello.asm)
; 编译链接方法
; (ld的'-s'选项意为"strip all", 去掉符号表等, 减少生成的可执行代码的文件大小)
; $ nasm -f elf hello.asm -o hello.o
; $ ld -s hello.o -o hello
; $ ./hello
; Hello, world!
; $
[section .data] ; 数据在此
strHello db "Hello, world!", 0Ah
STRLEN equ $ - strHello
[section .text] ; 代码在此
global _start ; 我们必须导出 _start 这个入口,以便让链接器识别
_start:
mov edx, STRLEN
mov ecx, strHello
mov ebx, 1
mov eax, 4 ; sys_write
int 0x80 ; 系统调用
mov ebx, 0
mov eax, 1 ; sys_exit
int 0x80 ; 系统调用
代码中定义了两个节,数据节和代码节。需要注意的是:入口点默认是 _start ,既要定义它,还要用 global 将 _start 导出,这样链接程序才可以找到它。
代码本身调用了两个系统调用,不重要,书中的OS里根本用不到Linux的系统调用。
执行步骤如下:
$ ls
hello.asm
$ nasm -f elf hello.asm -o hello.o
a$ ls
hello.asm hello.o
$ ld -s hello.o -o hello
$ ls
hello hello.asm hello.o
$ ./hello
Hello, world!
5.2 再进一步,汇编和C同步使用
用C写程序,和汇编链接在一起……这是我以前从未接触的领域。
下面的例子中,整个程序的过程是:
- 入口
_start在foo.asm中;一开始程序从入口进入,将后面的参数先压入栈中;调用extern声明的bar.c中的函数choose(); choose比较两个传入的参数,根据不同的结果打印出不同的参数;- 打印字符串的工作却是由
bar.c开头声明的、foo.asm中用global导出的myprint()完成的。

这个例子中,包含了汇编和C的相互调用:
- 由于
bar.c中用到myprint()函数,所以foo.asm中要用global将其导出; - 由于
foo.asm中要用到外面定义的函数choose,因此需要用extern声明; myprint和choose,遵循的都是C Calling Convention,后面的参数先入栈,并由调用者来清理堆栈。
代码如下:(chapter/5/b/foo.asm)
; 编译链接方法
; (ld的'-s'意味"strip all")
; $ nasm -f elf foo.asm -o foo.o
; $ gcc -c bar.c -o bar.o
; $ ld -s foo.o bar.o -o foobar
; $ ./foobar
; the 2nd one
; $
extern choose ;int choose(int a, int b);
[section .data] ;数据在此
num1st dd 3
num2nd dd 4
[section .text] ;代码在此
global _start ;我们必须导出_start这个入口, 以便让链接器识别
global myprint ;导出这个函数是为了让bar.c使用
_start:
push dword [num2nd]
push dword [num1st]
call choose ;choose(num1st, num2nd);
add esp, 8
mov ebx, 0
mov eax, 1 ;sys_exit
int 0x80 ;系统调用
;void myprint(char *msg, int len)
myprint:
mov edx, [esp + 8] ;len
mov ecx, [esp + 4] ;msg
mov ebx, 1
mov eax, 4 ;sys_write
int 0x80 ;系统调用
ret
chapter5/b/bar.c 的内容如下:
void myprint(char* msg, int len); //函数声明
int choose(int a, int b) { //函数定义
if (a >= b) {
myprint("the 1st one\n", 13);
} else {
myprint("the 2nd one\n", 13);
}
return 0;
}
编译链接过程如下:
$ nasm -f elf foo.asm -o foo.o
$ gcc -c bar.c -o bar.o
$ ld -s foo.o bar.o -o foobar
$ ./foobar
the 2nd one
$ ls
bar.c bar.o foo.asm foobar foo.o Makefile
总的来说,关键点在于 extern 和 global 这两个关键字,有了它们就可以在汇编和C之间自由变换。
5.3 ELF(Executable and Linkable Format)
ELF 文件由四部分构成:ELF头 ELF Header,程序头表 Program Header Table ,节 Sections ,节头表 Section Header Table 。、除了ELF头的位置是固定的,包含其他部分的位置、大小等重要信息外,文件中不一定要包含其他三部分内容,位置也不一定按照下面的顺序安排;大小也不固定:

1. ELF Header
ELF文件力求支持从8位到32位不同架构的处理器,所以有了下面的数据类型:

下面的代码定义了一个 ELF Header 结构:
#define EI_NIDENT 16
typedef struct {
unsigned char e_ident [EI_NIDENT]; //16字节的e_ident,包含表示ELF文件的字符及其他信息
Elf32_Half e_type; //
Elf32_Half e_machine;
Elf32_word e_version;
Elf32_Addr e_entry;
Elf32_Off e_phoff;
Elf32_Off e_shoff;
Elf32_Word e_flags;
Elf32_Haif e_ehsize;
Elf32_Haif e_phentsize;
Elf32_Haif e_phnum;
Elf32_Haif e_shentsize;
Elf32_Haif e_shnum;
Elf32_Haif e_shstrndx;
} Elf32_Ehdr;
以 foobar 为例:
$ xxd -a -u -g 1 -c 16 -l 80 foobar
0000000: 7F 45 4C 46 01 01 01 00 00 00 00 00 00 00 00 00 .ELF............
0000010: 02 00 03 00 01 00 00 00 A0 80 04 08 34 00 00 00 ............4...
0000020: D0 01 00 00 00 00 00 00 34 00 20 00 03 00 28 00 ........4. ...(.
0000030: 07 00 06 00 01 00 00 00 00 00 00 00 00 80 04 08 ................
0000040: 00 80 04 08 6C 01 00 00 6C 01 00 00 05 00 00 00 ....l...l.......
关于大端小端:它们取决于CPU架构,powerpc,aix、SPARC等是大端;x86架构处理器(Intel、AMD,PC)、arm架构处理器(arm,手机)是小端 ]
- 采用大小模式对数据进行存放的主要区别在于在存放的字节顺序,若数字的高位在内存中的低地址则是大端(即数字在内存中的二进制形式的第一字节是数字的高位),否则是小端。
- 采用小端方式进行数据存放利于计算机处理,因此计算机的内部处理较多用小端字节序;关于字符串需要注意的是,
char *ch ="12345",没有大端小端之分,'5'一定是在高地址存放的;- 采用大端方式进行数据存放符合人类的正常思维,除了计算机的内部处理,其他的场合几乎都是大端字节序,比如网络传输和文件储存。
- 最开始的是
16字节的e_ident,其中开头4个字节固定不变,第一个字节为0x7F,后面3个字节为ELF三个字符(从低到高,顺序存放),表明这个文件是ELF文件; e_type表示文件类型,foobar的e_type是0x0002,表示是一个可执行文件Executable File;e_machine,foobar中此项的值是0x0003,表示运行该程序的体系结构要求是Intel 80386;e_version这个成员确定文件的版本,这里是0x00000001;e_entry程序的入口地址,foobar入口地址是0x080480A0(高地址存放高字节,小端法);e_phoff是Program header table在文件中的偏移量,字节计数。这里是0x00000034;e_shoff是Section header table在文件中的偏移量,字节计数。这里是0x000001C0;e_flags对IA32来说,此项为零;e_ehsize是ELF header大小,字节计数。这里是0x0034;e_phentsize是Program header table中每个条目(一个Program header)的大小。这里值是0x0020;e_phnum是Program header table中的条目数量。这里有0x0003个;e_shentsize是Section header table中的条目大小(一个Section header的大小)。这里是0x0028;e_shnum是Section header table中的条目数量。这里有0x0006个;e_shstrndx包含节名称的字符串表是第几个节(从零开始)。这里值为0x0005,表示第五个节包含节名称。
上面, Program header table 在文件中的偏移量 e_phoff = 0x34 ,而 ELF header 的大小 e_ehsize = 0x34 ,说明ELF头后是程序头表。
2. Program header
定义了一个 Program header 的代码如下:
typedef struct {
ELF32_Word p_type;
ELF32_Off p_offset;
ELF32_Addr p_vaddr;
ELF32_Addr p_paddr;
ELF32_Word p_filesz;
ELF32_Word p_memsz;
ELF32_Word p_flags;
ELF32_Word p_align;
} ELF32_Phdr;
Program header 描述的是系统准备运行程序时需要的一个段 Segment 的相关信息:(如在文件中的位置、大小和放入内存后的位置和大小等)
p_type:当前程序头描述的段的类型;p_offset:段的第一个字节在文件中的偏移;p_vaddr:段的第一个字节在内存中的虚拟地址;p_paddr:在物理地址定位相关的系统中,此项为物理地址保留(不太明白);p_filesz:段在文件中的长度;p_memsz:段在内存中的长度;p_flags:与段相关的标志;p_align:根据此项值确定段在文件以及内存中如何对齐。
如果我们想把一个文件加载入内存的话,需要的就是这些信息。 以 foobar 为例:(程序头表在文件中的偏移量是 0x34;每个程序头的大小是 0x20 ;程序头表中的条目数量是 0x3 个):
$ xxd -a -u -g 1 -c 16 -s +0x34 -l 0x60 foobar
0000034: 01 00 00 00 00 00 00 00 00 80 04 08 00 80 04 08 ................
0000044: 6C 01 00 00 6C 01 00 00 05 00 00 00 00 10 00 00 l...l...........
0000054: 01 00 00 00 6C 01 00 00 6C 91 04 08 6C 91 04 08 ....l...l...l...
0000064: 08 00 00 00 08 00 00 00 06 00 00 00 00 10 00 00 ................
0000074: 51 E5 74 64 00 00 00 00 00 00 00 00 00 00 00 00 Q.td............
0000084: 00 00 00 00 00 00 00 00 07 00 00 00 04 00 00 00 ................
三个程序头取值如下:

由此,可以得出 foobar 加载入内存后的情况:

到这里为止,书中对 ELF 文件的探索就结束了,没有对节头表进行描述。下面直接就开始扩充Loader了。
5.4 从Loader到内核
Loader要做的工作如下:
- 加载内核到内存;
- 跳入保护模式;
1. 用Loader加载ELF
加载内核到内存,和引导扇区加载Loader到内存的工作非常相似,只是我们这里需要根据 Program header table 中的值,把内核中相应的段放到正确的位置。
书上的做法是:先像引导扇区处理Loader一样把内核放入内存,然后在保护模式下挪动它的位置。过程依旧是寻址文件、定位文件、读入内存。
boot.asm, loader.asm 之间共享的一些常量中、与FAT12文件有关的内容写进了一个单独文件 fat12hdr.inc :

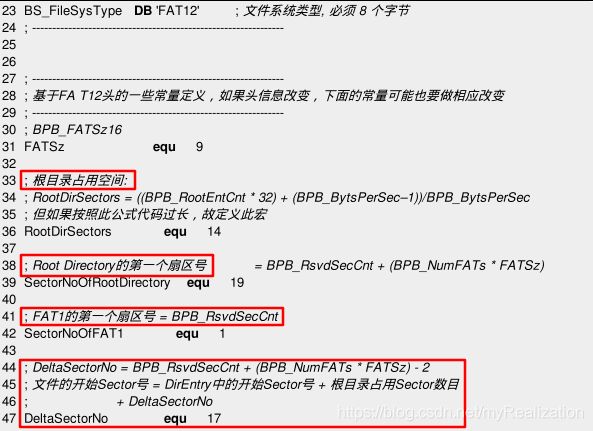
于是,使用 fat12hdr.inc 的代码如下:
jmp short LABEL_START
nop
; 下面是FAT12 磁盘的头,包含它是因为下面用到了磁盘的一些信息
%include "fat12hdr.inc"
LABEL_START:
下面修改 loader.asm ,让它把内核先放进内存:



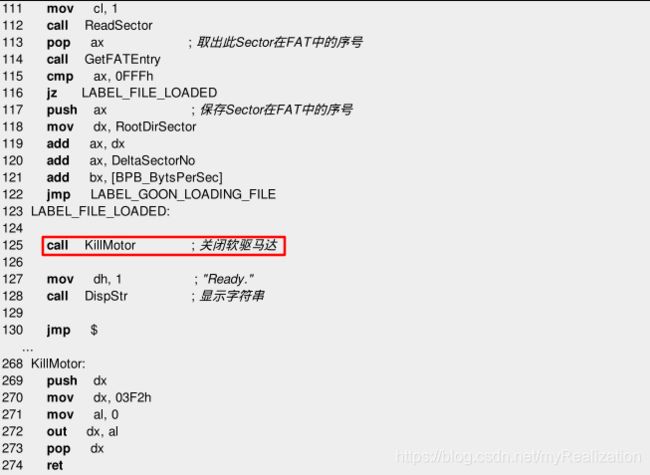
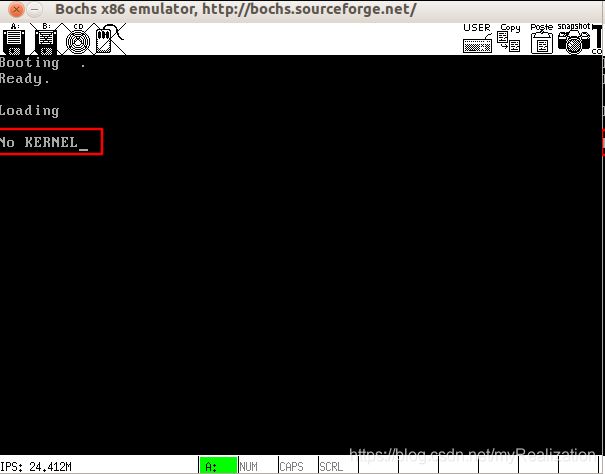
加载内核的代码已经写好了,可是我们还没有内核,如果现在运行,就会出现下面的情况:(光盘源代码有KERNEL,不过我没有把它写入软盘)
先上一个最简单的内核,kernel.asm ,显示一个字符,不过显示字符时涉及到内存操作,要用到GDT,假设Loader中段寄存器 gs 就已经指向显存的开始。之后的内核就在它的基础上进行扩充:(chapter5/c/kernel.asm 还算不上内核的内核扩充)
; 编译链接方法
; $ nasm -f elf kernel.asm -o kernel.o
; $ ld -s kernel.o -o kernel.bin
[section .text] ; 代码在此
global _start ; 导出_start
_start: ; 跳到这里时我们假设gs指向显存
mov ah, 0Fh ; 0000: 黑底 1111: 白字
mov al, 'K'
mov [gs:((80 * 1 + 39) * 2)], ax ; 屏幕第1行,第39列
jmp $
现在编译内核并写入软盘映像(之前已经写入过 loader.bin 了;这里可以直接执行 make ):
nasm -f elf -o kernel.o kernel.asm
ld -s -o kernel.bin kernel.o
sudo mount -o loop a.img /mnt/floppy/
sudo cp kernel.bin /mnt/floppy/ -v
sudo umount /mnt/floppy/
执行后,不是 No KERNEL 而是在 Loading 后面出现一个圆点,说明Loader读了一个扇区,我们只是加载内核到内存而没有做其他工作,所以没有其他现象出现:

2. 跳入保护模式
Loader是我们自己加载的,段地址就是 BaseOfLoader ,因此 Loader 中出现的标号的物理地址可以表示为:标号的物理地址=BaseOfLoader * 10h + 标号的偏移 。
然后,将 BaseOfLoader 的相关声明写在同一个文件中 load.inc 中,其中 BaseOfLoaderPhyAddr 是用来代替 BaseOfLoader * 10h 的, 在 boot.asm, loader.asm 中分别以一句 %include "load.inc" 将其包含:

接下来,定义三个描述符,分别是一个 0~4GB 的可执行段,一个 0~4GB 的可读写段,一个指向显存开始地址的段,然后在GdtPtr中, 用 BaseOfLoader * 10h 来计算GDT的基址:

下面是Loader的32位代码段,打印一个字符 'P' :

进入保护模式:

运行,结果如下,看到 'P' 说明进入了保护模式:

然后,初始化各个寄存器 ds,es,fs,ss,esp :

其中,TopOfStack 定义如下,1KB 的堆栈:
StackSpace: times 1024 db 0
TopOfStack equ BaseOfLoaderPhyAddr + $ ; 栈顶
接着,在Loader开头添加一些内容,先得到可用内存的信息,下面的的代码都可以从第三章复制过来,包含在32位代码段中:


得到内存信息后,定义页目录和页表:(节自 chapter5/d/loader.asm )
; 页目录和页表的位置
PageDirBase equ 100000h ; 页目录开始地址: 1M
PageTblBase equ 101000h ; 页表开始地址: 1M + 4K
还有些字符串和变量的定义,保护模式下的地址都加上了Loader的基地址:

打开分页机制,这也是第三章的内容:


现在,我们来调用它们:

运行代码,结果如下:

现在,这已经成为我们操作系统的一部分了,而不再是一个实验。
3. 重新放置内核
接下来,我们要整理内存中的内核并将控制权交给它。做法是:根据内核的 Program header table 的信息进行如下的内存复制:
memcpy(p_vaddr, BaseOfLoaderPhyAddr + p_offset, p_filesz);
每一个Program header都描述一个段,p_offset 为段在文件中的偏移,p_filesz 为段在文件中的长度,p_vaddr 为段在内存中的虚拟地址。如果Program header有 n 个,复制就进行 n 次。
另外,有 ld 生成的可执行文件中,p_vaddr 的值似乎太大了,类似于 0x8048XXX ,这显然已经超出了128MB的内存范围。我们不能允许编译器来决定内核的加载地址,所以需要修改 ld 的选项来让它生成的可执行代码中 p_vaddr 的值变小。因此,将编译链接时的命令改为:
nasm -f elf -o kernel.o kernel.asm
ld -s -Ttext 0x30400 -o kernel.bin kernel.o
这样程序的入口地址变为 0x30400 ,ELF header 等信息位于 0x30400 之前,此时的 ELF header 和 Program header table 的情况如下:
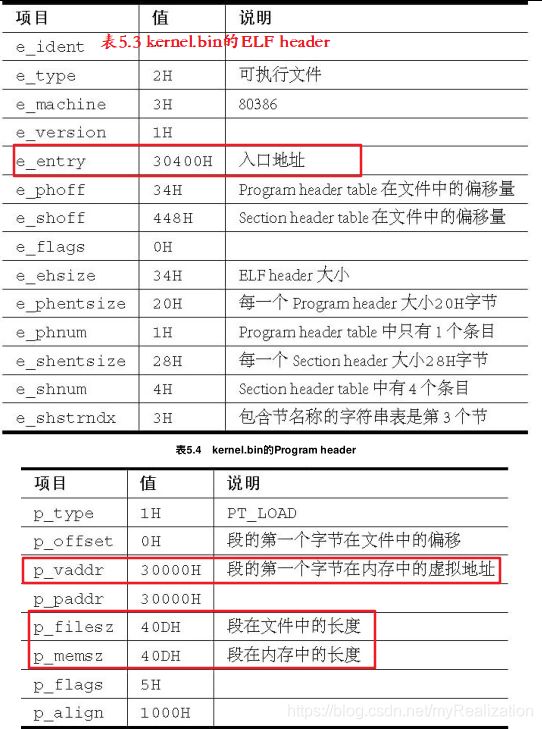
所以,我们应该这样放置内核:
memcpy(30000h, 90000h + 0, 40Dh);
即,我们应该把文件开始的 40Dh 字节内容放到内存 30000h 处。由于程序入口在 30400h ,所以代码只有 0Dh + 1 个字节。
看一下 chapter5/e/kernel.bin 的内容,发现从 400h ~ 40Dh 是仅有的代码,0xEBFE 就是 jmp $ (反汇编出来就是 jmp short 0x40b) :
$ xxd -a -u -c 16 -g 1 kernel.bin
0000000: 7F 45 4C 46 01 01 01 00 00 00 00 00 00 00 00 00 .ELF............
0000010: 02 00 03 00 01 00 00 00 00 04 03 00 34 00 00 00 ............4...
0000020: 20 04 00 00 00 00 00 00 34 00 20 00 01 00 28 00 .......4. ...(.
0000030: 03 00 02 00 01 00 00 00 00 00 00 00 00 00 03 00 ................
0000040: 00 00 03 00 0D 04 00 00 0D 04 00 00 05 00 00 00 ................
0000050: 00 10 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
0000060: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
*
0000400: B4 0F B0 4B 65 66 A3 EE 00 00 00 EB FE 00 2E 73 ...Kef.........s
0000410: 68 73 74 72 74 61 62 00 2E 74 65 78 74 00 00 00 hstrtab..text...
0000420: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
0000430: 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
0000440: 00 00 00 00 00 00 00 00 0B 00 00 00 01 00 00 00 ................
0000450: 06 00 00 00 00 04 03 00 00 04 00 00 0D 00 00 00 ................
0000460: 00 00 00 00 00 00 00 00 10 00 00 00 00 00 00 00 ................
0000470: 01 00 00 00 03 00 00 00 00 00 00 00 00 00 00 00 ................
0000480: 0D 04 00 00 11 00 00 00 00 00 00 00 00 00 00 00 ................
0000490: 01 00 00 00 00 00 00 00 ........
$ ndisasm kernel.bin <- 反汇编; 复制时省了一段
.........
000003F9 0000 add [bx+si],al
000003FB 0000 add [bx+si],al
000003FD 0000 add [bx+si],al
000003FF 00B40FB0 add [si-0x4ff1],dh
00000403 4B dec bx
00000404 6566A3EE00 mov [gs:0xee],eax
00000409 0000 add [bx+si],al
0000040B EBFE jmp short 0x40b
下面的代码实现将 kernel.bin 根据ELF文件信息转移到正确的位置,找到每个Program header,根据其信息进行内存复制即可:

接下来解释为什么要设置入口地址是 0x30400 。甚至于前面存放Loader.bin和Kernel.bin的位置也不是随便指定的,看一下内核被加载之后内存的使用情况,可能就明白了:
09FC00h ~ 09FFFFh不能被用作常规使用,而是作为BIOS参数区保护起来;- 我们真正可以使用的内存是
0500h ~ 09FBFFh这一段; - 另外,将入口地址放到
0x30400而不是直接放在0500h是出于调试的方便,把内核加载到这里,即使用DOS调试也不会覆盖掉DOS内存,因为DOS一般不会占用0x30000上面的内存地址; 0x90000开始的63KB留给了loader.bin,因为它本质上是一个.COM文件,不会太大;kernel.bin加载到内存方法和加载loader.bin一样,也是放在一个段中,所以也不能够超过64KB;Boot Sector将给我们的空闲地址分为了两块,但是引导扇区完成使命后就没有用了,所以可以把它也作为空内存来使用。

4. 向内核交出控制权
向内核跳转即可:(chapter5/3/loader.asm)
; *************************
jmp SelectorFlatC : KernelEntryPointPhyAddr`; 正式进入内核
; *************************
KernelEntryPointPhyAddr 定义在头文件 load.inc 中,值就是 0x30400 ,它必须和 ld 的参数 -Ttext 指定的值一致。如果我们想把内核放在别的地方,就只需改变这两个地方。
运行效果如下,出现 'K' 就说明操作系统内核开始运行了:

回顾内核获得控制权之时各个寄存器的状况,内核中我们需要这些信息:
cs, ds, es, fs, ss表示的段都指向内存地址0h,gs表示的段指向显存,这些都是进入保护模式后设置的;esp, GDT等内容都在Loader中;- 对内核进行扩充时,它们都会被移入内核中,方便控制;

5.5 扩充内核
1. 切换堆栈和GDT
现在,我们可以用C语言了,只要能用C,我们就避免用汇编。下面先看一些变量和函数的定义。
type.h中定义了 u8, u16, u32 这些类型,代表8位、16位、32位的数据类型,让我们一目了然:

const.h中定义了 PUBLIC, PRIVATE 等,用于区分全局和局部的符号,还有, GDT_SIZE 是GDT中描述符的个数:

protect.h中定义了 Descriptor 来表示描述符,类似前面 pm.inc 中的宏,不过更加清晰明了:

start.c中定义了全局变量 gdt_ptr (六个字节的数组)和全局函数 cstart 。cstart 首先把位于Loader中的原GDT全部复制给新的gdt (是一个 GDT_SIZE 的 Descriptor 结构体数组) ,用到的函数是 string.asm 中定义的 memcpy ,然后把新的gdt的界限和基地址写入原来的 gdt_ptr 中,以便 kernel.asm 中使用:
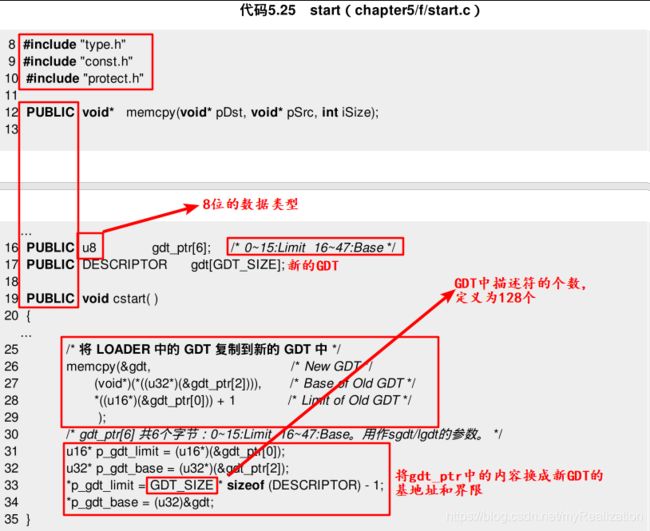
这里用4个语句就完成了切换堆栈和更换GDT的任务,StackTop 是大小为2KB的堆栈段 .bss 的栈顶指针:

用了C,代码理解起来舒服多了(这次没有显示字符 P, K 的代码)。下面我们编译链接:
$ nasm boot.asm -o boot.bin
$ nasm loader.asm -o loader.bin
$ nasm -f elf -o kernel.o kernel.asm
$ nasm -f elf -o string.o string.asm
$ gcc -c -o start.o start.c
$ ld -s -Ttext 0x30400 -o kernel.bin kernel.o string.o start.o
$ bximage
$ dd if=boot.bin of=a.img bs=512 count=1 conv=notrunc
$ sudo mount -o loop a.img /mnt/floppy/
$ sudo cp loader.bin /mnt/floppy/ -v
$ sudo cp kernel.bin /mnt/floppy/ -v
$ sudo umount /mnt/floppy/
gcc min.c:gcc编译器会对源文件min.c进行预处理、编译、以及链接,最后生成可执行文件,默认可执行文件名为a.out;
gcc -c min.c:gcc编译器会对源文件min.c进行预处理、编译、不进行链接,最后生成的是object file(目标文件),此处为min.o,这属于编译过程的中间阶段。再经过链接,才能最终生成可执行文件;
gcc -o min.out min.c:给生成的可执行文件命名,否则生成默认名称a.out文件;
gcc -c -o min.o min.c:给生成的中间文件命名。
链接的过程中,出了错误——start.c中的 cstart 函数中存在未定义的引用 disp_str :
start.o: In function `cstart':
start.c:(.text+0xe): undefined reference to `disp_str'
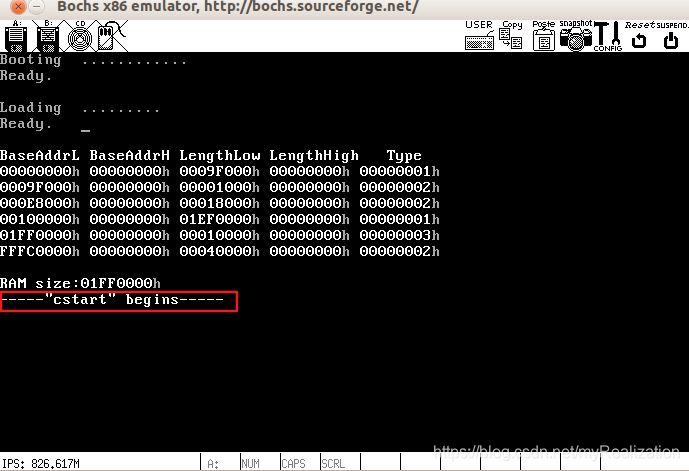
看了看代码,发现这是定义在 kliba.asm 中的,现在还没有用到它,因此修改 start.c ,将这句注释掉,就可以链接了:
//disp_str("\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n"
// "-----\"cstart\" begins-----\n");
运行结果如下:
把第三章的代码复制过来,放到 kliba.asm 中:

现在,取消之前start.c中注释掉的和 disp_str 相关的语句,打印字符串。然后进行编译链接:(gcc 加上 -fno-builtin 是为了防止编译器认为 memcpy 是一个 built-in function)
$ nasm -f elf -o kernel.o kernel.asm
$ nasm -f elf -o string.o string.asm
$ nasm -f elf -o kliba.o kliba.asm
$ gcc -c -fno-builtin -o start.o start.c
$ ld -s -Ttext 0x30400 -o kernel.bin kernel.o string.o start.o kliba.o
运行:
2. 整理我们的文件夹
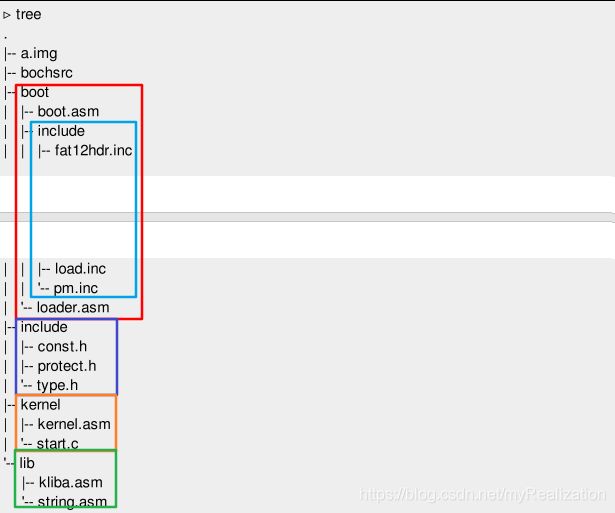
代码文件太多了,各种类型的文件混着一起,看着很不舒服。我们整理一下目录。
boot.asm, loader.asm和需要的头文件单独放在目录/boot中;const.h, protect.h, type.h放在/include中,作为头文件;kliba.asm和string.asm放在/lib中,作为库;kernel.asm, start.c放在/kernel中;
3. Makefile
书中这里才介绍了Makefile,因为随着源代码的增多,编译链接它们的命令也在增多,而且现在文件放入不同的文件夹中,要编译就更麻烦了。有了Makefile,每次只需要一行命令就可以完成全部过程。
Makefile内容很多,我们边学边用。先看一个简单的Makefile:chapter5/g/boot/Makefile
# Makefile for boot
# Programs, flags, etc.
ASM = nasm
ASMFLAGS = -I include/
# This Program
TARGET = boot.bin loader.bin
# All Phony Targets
.PHONY: everything clean all
# Default starting position
everything: $(TARGET)
clean:
rm -f $(TARGET)
all: clean everything
boot.bin : boot.asm include/load.inc include/fat12hdr.inc
$(ASM) $(ASMFLAGS) -o $@ $<
loader.bin : loader.asm include/load.inc include/fat12hdr.inc include/pm.inc
$(ASM) $(ASMFLAGS) -o $@ $<
上面的程序中:
#开头的是注释;=用来定义变量,ASM, ASMFLAGS就是变量,使用它们的时候需要$(ASM), $(ASMFLAGS);- Makefile最重要的语法:
表示:target : prerequisites command-
要想得到
target,需要执行命令command; -
target依赖于prerequisites;当prerequisites中至少有一个文件比target新的时候,command才被执行。 -
以最后两行为例,其意义为:
- 要得到
loader.bin,需要执行$(ASM) $(ASMFLAGS) -o $@ $<; loader.bin依赖于loader.asm, include/load.inc, include/pm.inc, include/fat12hdr.inc;当这些文件中至少有一个比loader.bin新的时候,command执行。
- 要得到
-
$@表示target;$<表示prerequisites的第一个名字。 -
$(ASM) $(ASMFLAGS) -o $@ $<等价于nasm -o loader.bin loader.asm;
-
不过,boot.bin, loader.bin 之外,everything, clean, all 后面也有目标,但是它们不是文件,而是3个动作名称:
- 如果运行
make clean就会执行rm -f $(TARGET),即rm -f boot.bin loader.bin; - 如果运行
make everything就会执行:nasm -I include/ -o boot.bin boot.asm nasm -I include/ -o loader.bin loader.asm all后面跟着clean, everything,表示如果执行make all,clean, everything表示的动作会分别被执行:$ make all rm -f boot.bin loader.bin nasm -I include/ -o boot.bin boot.asm nasm -I include/ -o loader.bin loader.asm.PHONY的作用就在于此,表示它后面的名字不是文件,而仅仅是一种行为的标号。
如果直接输入 make ,整个Makefile就会从第一个名字所代表的动作开始执行,这里第一个标号是 everything ,所以 make 和 make everything 的结果一样:
$ make
nasm -I include/ -o boot.bin boot.asm
nasm -I include/ -o loader.bin loader.asm
运行一个 make 之后,立即运行又一次 make ,由于 make 会自动比较目标和源文件的新旧程度,而此时所有的文件都是新的,就不会做什么动作。这样,我们每次 make 时就不会把每个源文件都编译一遍,在大型程序中会节省很多编译时间:
$ make :
Nothing to be done for 'everything'.
总的来说,make程序的原则是:由果寻因,先看要生成什么,再找生成它需要的条件。
接下来,对这个Makefile进行改造和扩充,就可以用于编译和链接整个操作系统工程了。先把Makefile移动到 /boot 的父目录中,然后修改一下——主要是把文件都加上了路径 boot/ :
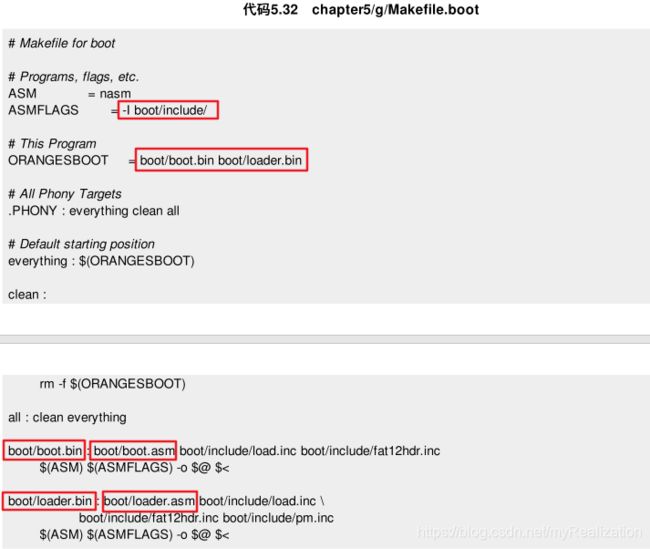
此时运行时,由于文件名是 Makefile.boot ,所以需要用 -f 进行指定。运行 make 如下:

在 Makefile.boot 的基础上加以改进,这里我们把GCC的选项也增加了对头文件目录的指定 -I include :chapter5/g/Makefile
#########################
# Makefile for Orange'S #
#########################
# Entry point of Orange'S
# It must have the same value with 'KernelEntryPointPhyAddr' in load.inc!
ENTRYPOINT = 0x30400
# Offset of entry point in kernel file
# It depends on ENTRYPOINT
ENTRYOFFSET = 0x400
# Programs, flags, etc.
ASM = nasm
DASM = ndisasm
CC = gcc
LD = ld
ASMBFLAGS = -I boot/include/
ASMKFLAGS = -I include/ -f elf
CFLAGS = -I include/ -c -fno-builtin
LDFLAGS = -s -Ttext $(ENTRYPOINT)
DASMFLAGS = -u -o $(ENTRYPOINT) -e $(ENTRYOFFSET)
# This Program
ORANGESBOOT = boot/boot.bin boot/loader.bin
ORANGESKERNEL = kernel.bin
OBJS = kernel/kernel.o kernel/start.o lib/kliba.o lib/string.o
DASMOUTPUT = kernel.bin.asm
# All Phony Targets
.PHONY : everything final image clean realclean disasm all buildimg
# Default starting position
everything : $(ORANGESBOOT) $(ORANGESKERNEL)
all : realclean everything
final : all clean
image : final buildimg
clean :
rm -f $(OBJS)
realclean :
rm -f $(OBJS) $(ORANGESBOOT) $(ORANGESKERNEL)
disasm :
$(DASM) $(DASMFLAGS) $(ORANGESKERNEL) > $(DASMOUTPUT)
# We assume that "a.img" exists in current folder
buildimg :
dd if=boot/boot.bin of=a.img bs=512 count=1 conv=notrunc
sudo mount -o loop a.img /mnt/floppy/
sudo cp -fv boot/loader.bin /mnt/floppy/
sudo cp -fv kernel.bin /mnt/floppy
sudo umount /mnt/floppy
boot/boot.bin : boot/boot.asm boot/include/load.inc boot/include/fat12hdr.inc
$(ASM) $(ASMBFLAGS) -o $@ $<
boot/loader.bin : boot/loader.asm boot/include/load.inc \
boot/include/fat12hdr.inc boot/include/pm.inc
$(ASM) $(ASMBFLAGS) -o $@ $<
$(ORANGESKERNEL) : $(OBJS)
$(LD) $(LDFLAGS) -o $(ORANGESKERNEL) $(OBJS)
kernel/kernel.o : kernel/kernel.asm
$(ASM) $(ASMKFLAGS) -o $@ $<
kernel/start.o : kernel/start.c include/type.h include/const.h include/protect.h
$(CC) $(CFLAGS) -o $@ $<
lib/kliba.o : lib/kliba.asm
$(ASM) $(ASMKFLAGS) -o $@ $<
lib/string.o : lib/string.asm
$(ASM) $(ASMKFLAGS) -o $@ $<
这个Makefile长得多,但是没有多么困难——如果能够画出一棵目标依赖树,可能容易看一些——功能上面确实强大太大了。
make disasm可以反汇编内核到一个文件;make buildimg把引导扇区、loader.bin、kernel.bin写到虚拟软盘;make image:先realclean删除一切.o文件、boot.bin, loader.bin, kernel.bin,再做everything,再clean一切.o文件,再buildimg写到虚拟软盘。
运行 make clean 试试看:

在 kernel/start.c 的 cstart( ) 的结束处添加一行语句:

make image 一下,运行:

这说明Makefile运行正常。以后,我们完全可以自行定义Makefile,添加功能如复制内核文件等,用 make 来轻松完成这些任务。
4. 添加中断处理
进程是一个操作系统最基本也最重要的东西,我们的下一个目标就是实现一个进程,再进一步,我们应该拥有多个进程进程本身不过是一段代码,但它却涉及到进程和操作系统间执行的切换——这种控制权转换机制,就是中断。下面,我们将中断处理添加到OS中。
要做的工作是:设置8259A和建立IDT。下面的函数 init_8259A( ) 设置8259A,它和第三章的代码完全一致:

上面的代码涉及到的宏是:

写端口的 out_byte 位于 kliba.asm 中,此外还有读端口的操作。空操作是为了延迟,以便完成端口的读写:

它们的原型位于 include/proto.h (用于存放函数声明) 中,start.c 中 disp_str 的声明也放到了里面,另外,我们把 memcpy 放到了 string.h 中:

最后,修改Makefile,添加新的目标和修改原来的依赖关系:

确认依赖关系,更方便的做法是:gcc -M ,它会自动生成依赖关系。然后直接复制即可:
$ gcc -M kernel/start.c -I include
start.o: kernel/start.c include/type.h include/const.h include/protect.h \
include/proto.h include/string.h include/global.h
现在我们已经可以 make 一下了,测试自己的工作有没有错误。接下来,我们要初始化IDT。
-
首先修改
start.c,和之前初始化GDT一样:

-
gdt[ ], gdt_ptr[ ], idt[ ], idt_ptr[ ]都放在了global.h中:

-
EXTERN定义在const.h中,它一般被定义为extern,不过在global.h中,如果定义了宏GLOBAL_VARIABLES_HERE的话,取消之前定义的EXTERN (=extern),然后定义EXTERN为空值。 -
通过宏
GLOBAL_VARIABLES_HERE的使用,我们可以让global.h中的所有变量只出现一次,同时,预编译结束后,global.c和其他.c文件的结果不同——global.c中变量前面没有extern关键字,而其他.c文件中变量前面都有extern关键字。

-
GATE定义在protect.h中:

-
kernel.asm中加入几句以导入idt_ptr这个符号并加载IDT。然后,将处理器可以处理的中断和异常列表及其处理程序都添加上:
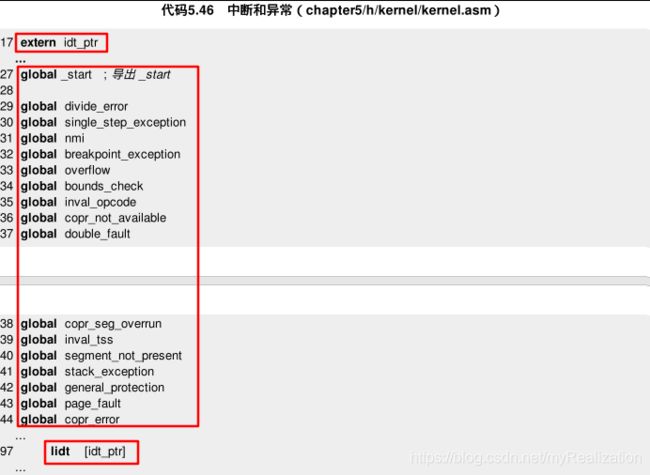

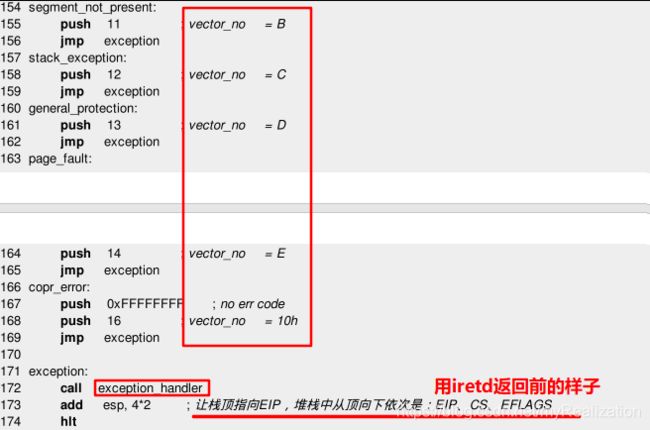
-
上个程序中,最后栈顶被调整为指向
eip,堆栈中从顶向下依次是:eip、cs、eflags,这就是用iretd返回前的样子。 -
exception_handler( )在新建的protect.c中,原型为void exception_handler(int vec_no, int err_code, int eip, int cs, int eflags);,它不会破坏堆栈中的eip, cs, eflags,因为C调用约定让调用者恢复堆栈。这个函数的实现如下——它打印空格清空屏幕前5行,然后打印堆栈中的参数:


-
打印字符串使用
disp_color_str( ),这个函数新增加了一个设置颜色的参数:
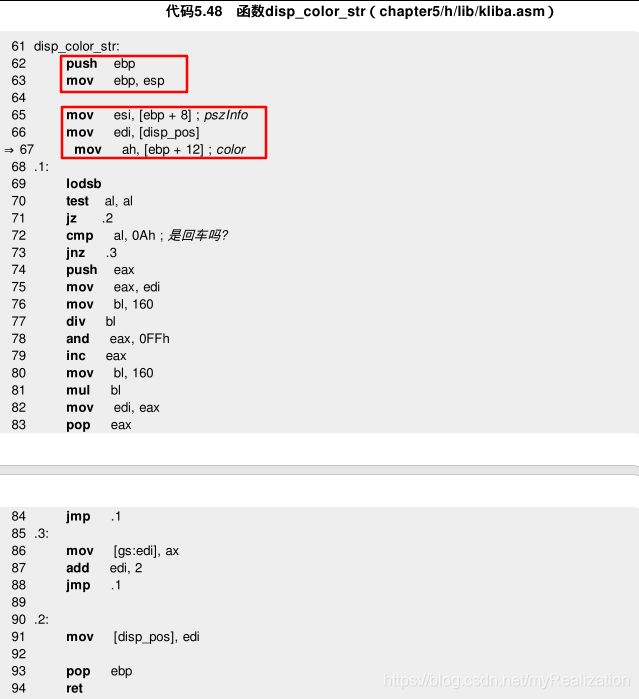
-
显示整数用到新的函数
disp_int( ),它被定义在新增文件klib.c中,用itoa( )将整数(一个32位的数值)转换为(十六进制)字符串后显示:


-
设置IDT的代码在函数
init_prot( )中,位于protect.c中,protect.c几乎会调用一个函数init_idt_desc( ),它用来初始化一个门描述符。其中使用的函数指针指向返回值为void的函数:

下面的所有异常处理程序都和上面的函数指针类型声明一致。并且,init_prot( )中所有描述符都初始化为中断门。其中使用的若干个宏:INT_VECTOR_开头的表示中断向量,DA_386IGate表示中断门,在定义protect.h中定义,PRIVILEGE_KRNL, PRIVILEGE_USER定义在const.h中:


上面就是大部分的设置IDT的代码,下面调用 init_prot( ) :

修改Makefile后,先 make 然后运行,没有任何效果。因为我们有异常处理程序,但是没有异常发生,于是在 kernel.asm 中用 ud2 产生一个 #UD 异常:

再次 make ,链接时出错:

发现在 klib.c 中的 disp_int 报错,在 Makefile 中的 $(CFLAGS) 后面加上 -fno-stack-protector ,即不需要栈保护。之后,编译链接就可以正常完成了。
lib/klib.o : lib/klib.c
$(CC) $(CFLAGS) -fno-stack-protector -o $@ $<
进行验证,将 char output[16]; 改为 char* output, ,编译不报错,说明问题出在定义数组的栈操作。
为了进行说明,使用代码 test.c :
int main() {
char str[16];
return 0;
}
① 编译链接:gcc -o test test.c ;然后 gdb test :
(gdb)disas main
(gdb) disas main
Dump of assembler code for function main:
0x08048404 <+0>: push %ebp
0x08048405 <+1>: mov %esp,%ebp
0x08048407 <+3>: and $0xfffffff0,%esp
0x0804840a <+6>: sub $0x20,%esp
0x0804840d <+9>: mov %gs:0x14,%eax
0x08048413 <+15>: mov %eax,0x1c(%esp)
0x08048417 <+19>: xor %eax,%eax
0x08048419 <+21>: mov $0x0,%eax
0x0804841e <+26>: mov 0x1c(%esp),%edx
0x08048422 <+30>: xor %gs:0x14,%edx
0x08048429 <+37>: je 0x8048430 <main+44>
0x0804842b <+39>: call 0x8048320 <__stack_chk_fail@plt>
0x08048430 <+44>: leave
0x08048431 <+45>: ret
End of assembler dump.
② 编译链接:gcc -fno-stack-protector -o test test.c ;然后 gdb test :
(gdb)disas main
(gdb) disas main
Dump of assembler code for function main:
0x080483b4 <+0>: push %ebp
0x080483b5 <+1>: mov %esp,%ebp
0x080483b7 <+3>: sub $0x10,%esp
0x080483ba <+6>: mov $0x0,%eax
0x080483bf <+11>: leave
0x080483c0 <+12>: ret
End of assembler dump.
发现我的电脑上,这个版本的 gcc 默认要进行栈检查的应该调用 __stack_chk_fail ,加了 -fno-stack-protector 就不用栈检查,无需调用 __stack_chk_fail 。
运行,效果如下。可以看到异常的助记符、名字、eflags, cs, eip 的值:

这是个没有错误码的异常,我们这里产生一个有错误码的异常,将 ud2 这个指令改为 jmp 0x40:0 。运行并显示错误码:

初始化 8259A 和设置 IDT 这两项任务完成后,我们就有了异常处理机制,今后,即便出了错,我们能方便地知道错误的类型和出现的地方。与 Bochs 的调试功能结合起来,让开发更方便。
8259A 虽然已经设置完成,但我们还没有真正开始使用它。由于两片级联的 8259A 可以挂接 15 个不同的外部设备,应有 15 个中断处理程序。为简单起见,先用两个带参数的宏作为中断处理程序。下面的代码就是8259A的中断例程:

所有中断都会触发一个函数 spurios_irq( ) ,定义如下:

设置IDT:


然后,需要修改 IP 位,并在 init_8259A( ) 中打开对应中断:
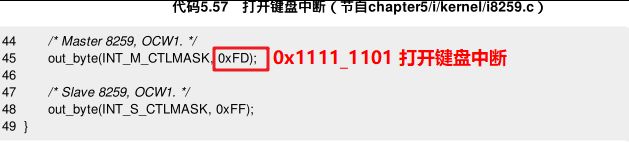

make 后(这里同样有 __stack_chk_fail 的问题,用上面的方法解决即可)运行,没有特殊情况,但是敲击键盘的任意键时,就会打印 spurios_irq: 0x1 。这表明IRQ是1,即键盘中断:

5. 说明
我们多次用到 disp_str( )、disp_color_str( )、disp_int( ) 等函数。但 Minix 或者 Linux 的代码中没有与之相类似的函数。这些函数既不强大也不优美,所以在可预见的将来,当我们的控制台等模块完善之时,会写一个漂亮的 printf( ) 。只是现在先将就着用它们吧。
5.6 小结
回过头来,发现自己居然已经走出这么远了。 学习了保护模式,还知道了如何调试,甚至于还学习了ELF文件格式、Makefile的编写等一系列内容。还有了异常处理,设置了8259A并可以接收外部中断。
更重要的是,接下来的工作是在已经搭建好的框架上完成,并且大部分将使用可读性较好的C语言编写,而不是晦涩的汇编代码。
最困难的日子已经过去,虽然眼前的路仍然很长,但是我们不再感觉是在无边的黑暗中摸索,眼前是一条光明大道,等待我们踏入新的征程。