WebServer
最近在学习网络协议,因此看了一些相关的资料,发现了几个比较不错的资料,很有启发性,因此记录下来,以备后续的复习查看。
HTTP协议概述
HTTP基于TCP协议,服务器端通常使用的是80号端口,其基本的操作机制是:客户端向服务器发出请求,服务器收到请求后做出响应。

HTTP有几个基本特点:
- 无状态。每一个HTTP请求都是独立的,服务器不会保留以前的请求或者会话的历史纪录。
- 双向传输。通常是客户端向服务器请求web页面,但是也允许客户端向服务器提交数据。
- 支持协商。允许协商数据使用的编码方式等一些细节。
- 高速缓存。浏览器会把收到的每一个web页面副本都存储在高速缓存中,如果用户再一次请求该页面,浏览器可以直接从缓存中获取。
支持中介。允许在客户端和服务器之间设置代理服务器,用来转发客户端的请求,也可以设置高速缓存存放web页。
HTTP的请求方式
GET方法和POST方法
请求一个web页,也可以用于向某个页面附加资源。POST用于向某个页面添加附加资源。比如登陆CSDN的时候输入的用户名和密码。
使用GET方法的时候附加的数据会体现在URL中,比如再用Google查询的时候可以仔细观察一下输入查询内容之后的URL变化。而POST附加的数据不会体现在URL中,而是隐藏在报文里HEAD方法
用于读取某一个Web页面的头部,可以用来:
【1】测试URL的有效性。
如果要测试某一个URL指向的页面是否存在,只需要获取头部就可以了,这样可以节省通信量。
【2】用于搜索引擎。
搜索引擎根据页面的头部信息进行筛选,可以节约时间
补充:web页面的头部到底可以包含那些信息呢?,参考这篇博客
PUT方法
请求上传一个web页DELETE方法
请求删除一个web页LINK方法
链接两个已有的页面UNLINK方法
把两个页面之间的链接断开
HTTPServer原理及工作过程
在最一开始的那张图中,我们通过URL告诉了浏览器它所需要发现并连接的网络服务器地址,以及获取服务器上的页面路径。不过在浏览器发送HTTP请求之前,它首先要与目标网络服务器建立TCP连接。然后,浏览器再通过TCP连接发送HTTP请求至服务器,并等待服务器返回HTTP响应。当浏览器收到响应的时候,就会在页面上显示响应的内容。
首先来看一下URL的结构

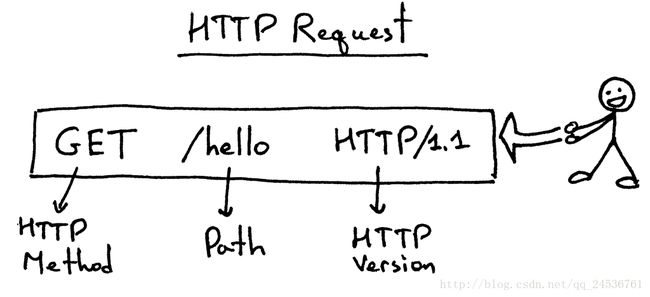
然后是request的结构
然后是reponse结构
一个简单的WebServer
from http.server import BaseHTTPRequestHandler
from http.server import HTTPServer
class RequestHandler(BaseHTTPRequestHandler):
full_path = ""
Cases = [case_no_file(),
case_existing_file(),
case_directory_index_file(),
case_directory_no_index_file(),
case_always_fail()]
def do_GET(self):
try:
self.full_path = os.getcwd()+self.path
print("os.getcwd():" + os.getcwd())
print("self.path:" + self.path)
for case in self.Cases:
handler = case
if handler.test(self):
print(handler)
handler.act(self)
break
except Exception as msg:
self.handle_error(msg)
def handle_error(self, msg):
content = Error_Page.format(path=self.path, msg=msg)
self.send_content(content, 404)
def send_content(self, content, status=200,):
self.send_response(status)
self.send_header("Content-Type", "image/jpeg")
self.send_header("Content-Length", str(len(content)))
self.end_headers()
self.wfile.write(bytes(content, "utf-8"))
serverAddress = ("", 8080)
server = HTTPServer(serverAddress, RequestHandler)
server.serve_forever()
这段代码主要是参考《500 Lines》中的一篇编写的。其基本思路是借助了python的http.server库。其中do_GET 函数是重载了BaseHTTPRequestHandler中的方法。其中send_content 方法首先发送一个status_code,当status_code=200时表示正常。
其中Cases 用于增强可拓展性,当我们需要增加新的功能的时候只需要添加一个新的Case就可以了。case的写法参考:
import os
from specialPages import *
class base_case:
def test(self, handler):
assert False, 'Not implemented'
def act(self, handler):
assert False, 'Not implemented'
def index_path(self, handler):
return os.path.join(handler.full_path, "index.html")
def handle_file(self, handler, full_path):
try:
with open(full_path, 'r') as reader:
content = reader.read()
handler.send_content(content)
except IOError as msg:
handler.handle_error(msg)
def list_dir(self, handler, full_path):
try:
entries = os.listdir(full_path)
bullets = ['{0} '.format(e) for e in entries if not e.startswith('.')]
page = Listing_Page.format('\n'.join(bullets))
handler.send_content(page)
except OSError as msg:
msg = "'{0}' cannot be listed: {1}".format(handler.path, msg)
handler.handle_error(msg)
class case_no_file(base_case):
def test(self, handler):
return not os.path.exists(handler.full_path)
def act(self, handler):
raise Exception("'{0}' not found".format(handler.path))
class case_existing_file(base_case):
def test(self, handler):
print(handler.full_path)
return os.path.isfile(handler.full_path) and not str(handler.full_path).endswith(".jpg")
def act(self, handler):
self.handle_file(handler, handler.full_path)
class case_always_fail(base_case):
def test(self, handler):
return True
def act(self, handler):
raise Exception("Unknown object '{0}'".format(handler.path))
class case_directory_index_file(base_case):
def test(self, handler):
return os.path.isdir(handler.full_path) and \
os.path.isfile(self.index_path(handler))
def act(self, handler):
self.handle_file(handler, self.index_path(handler))
class case_directory_no_index_file(base_case):
def test(self, handler):
return os.path.isdir(handler.full_path) and \
not os.path.isfile(self.index_path(handler))
def act(self, handler):
self.list_dir(handler, handler.full_path)每一个Case 对应的是一种操作。
参考资料
- 自己动手实现一个网络服务器
- 《500 Lines ——a simple web server》
- Header中有哪些信息