深度学习入门之PyTorch学习笔记:多层全连接网络
深度学习入门之PyTorch学习笔记
- 绪论
- 1 深度学习介绍
- 2 深度学习框架
- 3 多层全连接网络
- 3.1 PyTorch基础
- 3.2 线性模型
- 3.2.1 问题介绍
- 3.2.2 一维线性回归
- 3.2.3 多维线性回归
- 3.2.4 一维线性回归的代码实现
- 3.2.5 多项式回归
- 3.3 分类问题
- 3.3.1 问题介绍
- 3.3.2 Logistic 起源
- 3.3.3 Logistic 分布
- 3.3.4 二分类的Logistic回归
- 3.3.5 模型的参数估计
- 3.3.6 Logistic回归的代码实现
- 3.4 简单的多层全连接前向网络
- 3.5 深度学习的基石:反向传播算法
- 3.5.1 链式法则
- 3.5.2 反向传播算法
- 3.5.3 Sigmoid 函数举例
- 3.6 各种优化算法的变式
- 3.7 处理数据和训练模型的技巧
- 3.8 多层全连接神经网络实现MNIST手写数字分类
绪论
- 深度学习如今已经称为科技领域最炙手可热的技术,帮助你入门深度学习。
- 本文从机器学习与深度学习的基础理论入手,从零开始学习
PyTorch以及如何使用PyTorch搭建模型。 - 学习机器学习中的线性回归、
Logistic回归、深度学习的优化方法、多层全连接神经网络、卷积神经网络、循环神经网络、以及生成对抗网络,最后通过实战了解深度学习前沿的研究成果。 - 将理论与代码结合,帮助更好的入门机器学习。
1 深度学习介绍
https://hulin.blog.csdn.net/article/details/107733777
2 深度学习框架
https://hulin.blog.csdn.net/article/details/107746239
3 多层全连接网络
- 深度学习的前身是多层全连接神经网络,神经网络领域最开始主要是用来模拟人脑神经元系统,随后逐渐发展成为一项机器学习技术。
- 先从
PyTorch基础入手,介绍PyTorch的处理对象、运算操作、自动求导、以及数据处理方法,接着从线性模型开始进入机器学习的内容,然后由Logistic回归引入分类问题,介绍多层全连接神经网络、反向传播算法、各种基于梯度的优化算法、数据预处理和训练技巧,最后用PyTorch实现多层全连接神经网络。
3.1 PyTorch基础
https://hulin.blog.csdn.net/article/details/107797807
3.2 线性模型
3.2.1 问题介绍
- 线性模型就是给定很多个数据点,找到一个函数来拟合这些数据点,使其误差最小。
- 线性模型就是试图学习一个通过属性的线性组合来进行预测的函数。
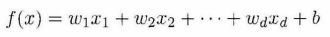
- 一般可以用向量形式表达。
- 线性模型形式简单,易于建模,却孕育着机器学习领域最重要的基本思想,同时线性模型还具有特别好的解释性,因为权重的大小就直接可以表示这个属性的重要程度。
3.2.2 一维线性回归
- 给定数据集 D = {(x1,y1), (x2,y2), (x3,y3), (x4,y4)…(xm,ym)},线性回归希望能够优化出一个好的函数f(x),使得f(xi) = w*xi + b能够与yi尽可能接近。
- w和b的最优解

3.2.3 多维线性回归
- 多元线性回归模型,可以使用梯度下降法求解这个问题。

- 数据集D

3.2.4 一维线性回归的代码实现
import matplotlib.pyplot as plt
import numpy as np
import torch.nn as nn
import torch.optim as optim
from torch.autograd.variable import *
x_train = np.array(
[[3.3], [4.4], [5.5], [6.71], [6.93], [4.168], [9.779], [6.128], [7.59], [2.167], [7.042], [10.791], [5.313],
[7.997], [3.1]], dtype=np.float32)
y_train = np.array(
[[1.7], [2.76], [2.09], [3.19], [1.694], [1.573], [3.366], [2.596], [2.53], [1.221], [2.827], [3.465], [1.65],
[2.904], [1.3]], dtype=np.float32)
x_train = torch.from_numpy(x_train)
y_train = torch.from_numpy(y_train)
class LinearRegression(nn.Module):
def __init__(self):
super(LinearRegression, self).__init__()
self.linear = nn.Linear(1, 1) # input and output is 1 dimension
def forward(self, x):
out = self.linear(x)
return out
if torch.cuda.is_available():
model = LinearRegression().cuda()
else:
model = LinearRegression()
criterion = nn.MSELoss() # 使用均方差作为优化函数
optimizer = optim.SGD(model.parameters(), lr=1e-3) # 梯度下降进行优化
# 开始训练模型
num_epochs = 1000 # 迭代次数
for epoch in range(num_epochs): # 将数据变成Variable并放入计算图
if torch.cuda.is_available():
inputs = Variable(x_train).cuda()
target = Variable(y_train).cuda()
else:
inputs = Variable(x_train)
target = Variable(y_train)
# forward
out = model(inputs) # 得到网络前向传播得到的结果
loss = criterion(out, target) # 得到损失函数
# backward
# 每次做反向传播之前都要归零梯度,不然梯度会累加起来,造成结果不收敛
optimizer.zero_grad()
loss.backward() # 做反向传播和更新参数
optimizer.step()
# 在训练的过程中,各一段时间将损失函数的值打印出来,确保误差越来越小
if (epoch + 1) % 20 == 0:
# print('Epoch[{} / {}],loss:{:.6f}'.format(epoch + 1, num_epochs, loss.data[0]))
print('Epoch[{} / {}]'.format(epoch + 1, num_epochs))
print(loss.data)
# 预测结果
model.eval() # 将模型变成测试模式
predict = model(Variable(x_train)) # 将测试数据放入网络做前向传播得到结果
predict = predict.data.numpy()
plt.plot(x_train.numpy(), y_train.numpy(), 'ro', label='Original Data')
plt.plot(x_train.numpy(), predict, label='Fitting Line')
plt.show()
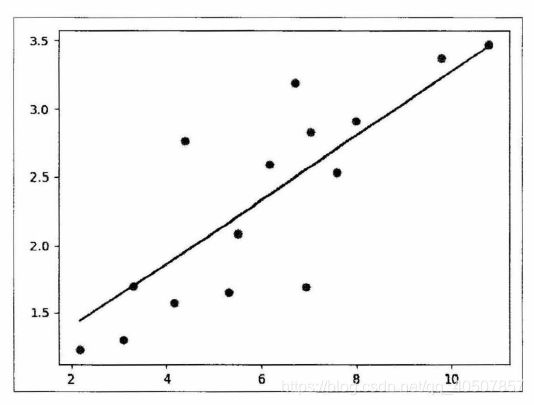
3.2.5 多项式回归
- 对于一般的线性回归,由于该函数拟合出来的是一条直线,所以精度欠佳。可以考虑多项式回归,提高每个属性的次数,而不再是只使用一次回归目标函数。
- 想要拟合的方程
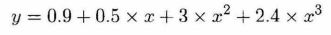
- 设置参数方程

import torch
from torch.autograd.variable import Variable
import torch.nn as nn
import torch.optim as optim
def make_features(x):
"""
Builds features i.e a matrix with columns [x,x^2,x^3]
:param x:
:return:
"""
x = x.unsqueeze(1)
# torch.cat()实现Tensor的拼接
return torch.cat([x ** i for i in range(1, 4)], 1)
# unsqueeze(1) 是将原来的tensor大小由3变成(3,1)
w_target = torch.FloatTensor([0.5, 3, 2.4]).unsqueeze(1)
b_target = torch.FloatTensor([0.9])
def f(x):
"""
Approximated function
每次输入一个x,得到一个y的真实函数
:param x:
:return:
"""
return x.mm(w_target) + b_target[0] # x.mm(w_target) 做矩阵乘法
# 在进行训练的时候需要采样一些点,可以随机生成一些数来得到每次的训练集
def get_batch(batch_size=32):
"""
Build a batch i.e. (x,f(x)) pair.
:param batch_size:
:return:
"""
random = torch.randn(batch_size)
x = make_features(random)
y = f(x)
if torch.cuda.is_available():
return Variable(x).cuda(), Variable(y).cuda()
else:
return Variable(x), Variable(y)
# define model
class poly_model(nn.Module):
def __init__(self):
super(poly_model, self).__init__()
self.poly = nn.Linear(3, 1) # 输入3维,输出1维
def forward(self, x):
out = self.poly(x)
return out
if torch.cuda.is_available():
model = poly_model().cuda()
else:
model = poly_model()
criterion = nn.MSELoss() # 损失函数
optimizer = optim.SGD(model.parameters(), lr=1e-3) # 优化器
# 使用均方误差来衡量模型的好坏,使用随机梯度下降来优化模型
epoch = 0
while True:
# Get Data
batch_x, batch_y = get_batch()
# Forward Pass
output = model(batch_x)
loss = criterion(output, batch_y)
print_loss = loss.data
# Reset gradients
optimizer.zero_grad()
# Backward Pass
loss.backward()
# update parameters
optimizer.step()
epoch += 1
# 取出的32个点的均方误差小于0.001
if print_loss < 1e-3:
break
3.3 分类问题
3.3.1 问题介绍
- 机器学习中的监督学习主要分为回归问题和分类问题,回归问题希望预测的结果是连续的,分类问题希望预测的结果是离散的。监督学习从数据中学习一个分类模型或者决策函数被称为分类器(Classifier)。
- 分类器对新的输入进行输出预测,这个过程即称为分类(classification)。同时分类问题包括二分类和多分类问题,最著名的二分类算法:Logistic回归。
3.3.2 Logistic 起源
- Logistic起源于对人口数量增长情况的研究,后来被应用到微生物生长情况的研究,以及解决经济学相关的问题,现在作为回归分析的一个分支来处理分类问题。
3.3.3 Logistic 分布
- 设X是连续的随机变量,服从Logistic分布是指X的积累分布和密度函数如下。

- 其中u影响中心对称点的位置,r越小,中心点附近的增长速度越快
- Logistic(Sigmoid)函数的表达式如下。

- Sigmoid函数图像

3.3.4 二分类的Logistic回归
- Logistic回归不仅可以解决二分类问题,也可以解决多分类问题,但是二分类问题最常见,同时也具有良好的解释性。对于二分类问题,Logistic回归的目标是希望找到一个区分度足够好的决策边界,能够将两类很好的分开。
- 一个事件发生的几率(
odds)是指该事件发生的概率和不发生的概率的比值,比如一个事件发生的概率是P,那么该事件发生的几率是p/(1-p),该事件的对数几率或logit函数是:
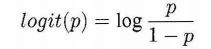
- 在Logistic回归模型中,输出Y=1的对数几率是输入x的线性函数,这也就是Logistic回归名称的原因。
- 线性函数的值越接近正无穷,概率值就越接近1;线性函数的值越接近负无穷,概率值越接近0。因此Logistic回归的思路是先拟合决策边界,这里的决策边界不局限于线性,还可以是多项式,在建立这个边界和分类概率的关系,从而得到二分类情况下的概率。
3.3.5 模型的参数估计
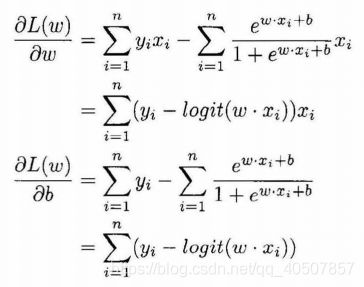
3.3.6 Logistic回归的代码实现
- 先从data.txt文件中读取数据,然后通过Matplotlib将数据点画出来
import matplotlib.pyplot as plt
# 每个数据点是一行,每行中前面两个数据表示x坐标和y坐标,最后一个数据表示其类别
with open('data.txt', 'r') as f:
data_list = f.readlines()
data_list = [i.split('\n')[0] for i in data_list]
data_list = [i.split(',') for i in data_list]
data = [(float(i[0]), float(i[1]), float(i[2])) for i in data_list]
x0 = list(filter(lambda x: x[-1] == 0.0, data))
x1 = list(filter(lambda x: x[-1] == 1.0, data))
plot_x0_0 = [i[0] for i in x0]
plot_x0_1 = [i[1] for i in x0]
plot_x1_0 = [i[0] for i in x1]
plot_x1_1 = [i[1] for i in x1]
plt.plot(plot_x0_0, plot_x0_1, 'ro', label='x_0')
plt.plot(plot_x1_0, plot_x1_1, 'bo', label='x_1')
plt.legend(loc='best')
plt.show()
- 这些数据点被分为两类,一类是红色的点,一类是蓝色的点,希望通过Logistic回归将其分开
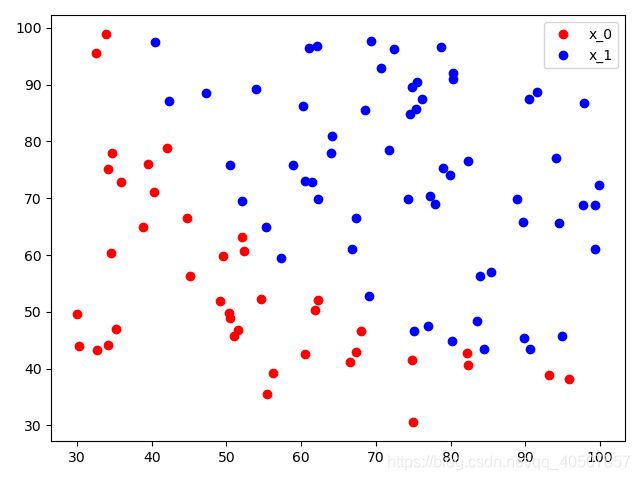
- 定义Logistic回归的模型,以及二分类问题的损失函数和优化方法。
import torch
from torch.autograd.variable import Variable
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
# 每个数据点是一行,每行中前面两个数据表示x坐标和y坐标,最后一个数据表示其类别
with open('data.txt', 'r') as f:
data_list = f.readlines()
data_list = [i.split('\n')[0] for i in data_list]
data_list = [i.split(',') for i in data_list]
data = [(float(i[0]), float(i[1]), float(i[2])) for i in data_list]
# 分类
x0 = list(filter(lambda x: x[-1] == 0.0, data))
x1 = list(filter(lambda x: x[-1] == 1.0, data))
plot_x0_0 = [i[0] for i in x0]
plot_x0_1 = [i[1] for i in x0]
plot_x1_0 = [i[0] for i in x1]
plot_x1_1 = [i[1] for i in x1]
plt.plot(plot_x0_0, plot_x0_1, 'ro', label='x_0')
plt.plot(plot_x1_0, plot_x1_1, 'bo', label='x_1')
plt.legend(loc='best')
x_data = [i[0] for i in data]
y_data = [i[1] for i in data]
x_data=torch.tensor(x_data)
y_data=torch.tensor(y_data)
# 定义Logistic回归模型
class LogisticRegression(nn.Module):
def __init__(self):
super(LogisticRegression, self).__init__()
self.lr = nn.Linear(2, 1)
self.sm = nn.Sigmoid()
def forward(self, x):
x = self.lr(x)
x = self.sm(x)
return x
logistic_model = LogisticRegression()
if torch.cuda.is_available():
logistic_model.cuda()
criterion = nn.BCELoss() # 二分类的损失函数
# 随机梯度下降优化函数
optimizer = torch.optim.SGD(logistic_model.parameters(), lr=1e-3, momentum=0.9)
# 训练模型
num_epochs = 50000
for epoch in range(num_epochs):
if torch.cuda.is_available():
x = Variable(x_data).cuda()
y = Variable(y_data).cuda()
else:
x = Variable(x_data)
y = Variable(y_data)
# forward
out = logistic_model(x)
loss = criterion(out, y)
print_loss = loss.data[0]
# 判断输出结果,如果大于0.5就等于1,小于0.5就等于0,通过这个来计算模型分类的准确率
mask = out.ge(0.5).float()
correct = (mask == y).sum()
acc = correct.data[0] / x.size(0)
# backward
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (epoch + 1) % 1000 == 0:
print('*' * 10)
print('epoch {}'.format(epoch + 1))
print('loss is {:.4f}'.format(print_loss))
print('acc is {:.4f}'.format(acc))
3.4 简单的多层全连接前向网络
https://hulin.blog.csdn.net/article/details/107816060
3.5 深度学习的基石:反向传播算法
- 反向传播算法就是一个有效的求解梯度的算法,本质上就是一个链式求导法则的应用,然而这个如此简单且显而易见的方法,却是在Roseblatt提出感知器算法后近30年才被发明和普及的。
3.5.1 链式法则
- 考虑一个简单的函数
f(x,y,z)=(x+y)*z,当然可以直接求出这个函数的微分,但是这里要使用链式法则,令q=x+y,那么f=q*z,对于这两个算式,分别求出它们的微分。

- 通过链式法则知道,如果需要对其中的元素求导,可以一层一层求导,最后将结果乘起来,这就是链式法则的核心,也是反向传播算法的核心。
3.5.2 反向传播算法
- 本质上反向传播算法只是链式法则的一个应用,使用之前的例子:
q=x+y,f=qz,通过计算图可以将这个过程表达出来。
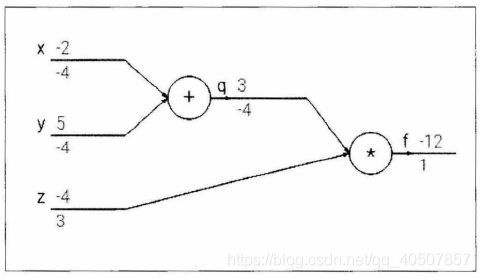
- 上面的数字表示数值,下面的数字表示求出的梯度。
- 直观上看,反向传播算法是一个优雅的局部过程,每次求导只是对当前的运算求导,求解每层网络的参数都是通过链式法则,将前面的结果求出不断迭代到这一层,所以说这是一个传播过程。
3.5.3 Sigmoid 函数举例
- 通过Sigmoid函数来演示反向传播过程在一个复杂函数上是如何进行的。

- 首先将这个函数抽象成一个计算图表示。
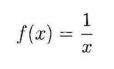

3.6 各种优化算法的变式
https://hulin.blog.csdn.net/article/details/107815873
3.7 处理数据和训练模型的技巧
https://hulin.blog.csdn.net/article/details/107824845
3.8 多层全连接神经网络实现MNIST手写数字分类
https://hulin.blog.csdn.net/article/details/107825032