day10 函数的嵌套
day10 函数的嵌套
文章目录
- day10 函数的嵌套
- 今日内容概要
- 昨日回顾
- 今日内容详细
- 函数的动态参数
- 动态位置参数
- 动态关键字参数(动态默认参数)
- 函数参数总结
- 函数参数补充
- 万能传参
- 聚合与打散
- 函数的注释
- 函数的名称空间
- 函数名的第一类对象及使用
- 函数的嵌套
- `global`和`nonlocal`
- `global`方法
- `nonlocal`方法
- `global`和`nonlocal`方法总结
今日内容概要
- 函数的动态参数
- 函数的注释
- 函数的名称空间
- 函数的嵌套 # 非常重要
- global和nonlocal
- 函数名的第一类对象及使用
昨日回顾
-
函数初识
- 封装代码
- 减少重复
-
函数的定义
def 函数名(): 函数体 -
函数的调用
函数名()- 调用函数
- 获取返回值
-
函数的返回值
- 函数执行完成后,函数体开辟的空间会被销毁
- 函数体中存放的只是代码,只有当程序被调用时,函数体中的代码才会被执行
- return – 返回
- return会终止当前函数,return下方的代码不会被执行
- 不写return默认返回None,写了return不写值也是返回None
- return可以返回任意数据类型
- return可以返回多个值,以元组的形式返回储存
- return是将返回值返回给调用者
- 可以写多个return,但是只执行要给return
-
函数的参数
- 形参:定义阶段的参数叫做形参
- 位置参数:必须一一对应
- 默认参数:可以不传,可以传,传的时候会将默认值覆盖
- 混合参数:位置参数 > 默认参数
- 实参:调用阶段的参数叫做实参
- 位置参数:必须一一对应
- 关键字参数:指名道姓传参
- 混合参数:位置参数 > 关键字参数
- 传参:将实参传递给形参的过程就是传参
- 形参:定义阶段的参数叫做形参
今日内容详细
函数的动态参数
我们已经学到了函数的两种参数:位置参数和默认参数。但是对这两种参数而言,我们传入函数的数据不能多于参数的总个数。但是有些时候,参数的数量是不能很好控制的,这时候,我们就需要应用到动态参数。
动态参数的作用主要有两个:
- 能够接收不固定长度的参数
- 位置参数过多时,可以使用动态参数
动态位置参数
我们可以通过下面的方法定义一个动态的位置参数:
def func(*c):
print(c)
func(1,2,3,4,5,6,7,8,9,0)
输出的结果为:(1, 2, 3, 4, 5, 6, 7, 8, 9, 0)
这个方法得到的数据类型是一个元组。
动态位置参数以*形参的形式表示。相信大家已经发现,这种方式跟切片时十分相似。
事实上,同切片时将多余数据打包的原理一样,在形参位置上的*就是聚合。同样,我们可以在函数体中使用*将聚合后得到的元组打散:
def func(*c): # 形参位置上的*是聚合
print(*c) # 函数体中的*就是打散
func(1,2,3,4,5,6,7,8,9,0)
输出的结果为:1 2 3 4 5 6 7 8 9 0
因为动态位置参数会将多余的位置参数全都打包起来,所以一个函数中只需要一个动态位置参数就足够了。一般情况下,动态位置参数会被命名为*args。当然也可以自定义参数名,但是不建议修改,因为这时程序员约定俗成的共识。
如果动态位置参数后面还有位置参数,那么后面的位置参数将永远无法获取到值,程序会直接报错:
def eat(*args,a,b):
print(a,b,args)
eat("面条","米饭","馒头","包子","煎饼")
程序报错,错位内容为:
Traceback (most recent call last):
File "C:/Users/Sure/PyProject/day10/exercise.py", line 12, in <module>
eat("面条","米饭","馒头","包子","煎饼")
TypeError: eat() missing 2 required keyword-only arguments: 'a' and 'b'
因为参数a和b永远也无法得到值,尽管我们输入很多内容,依旧无济于事。
一个比较标准的参数设置方法是这样的:
def eat(a,b,*args): # 位置参数,动态位置参数
print(a,b,args)
eat("面条","米饭","馒头","包子","煎饼")
输出的结果为:面条 米饭 ('馒头', '包子', '煎饼')
位置参数一一对应获得参数,动态位置参数将剩余的参数打包成一个元组。
动态关键字参数(动态默认参数)
当我们在实参中传入的关键字参数在形参中存在时,会成功传递进入。可是如果形参中没有我们传入的实参,就会报错。
动态关键字参数就是用来接收这些没有被定义过的关键字参数。
我们可以在形参中使用**参数名的形式定义一个动态关键字参数。同样地,参数名可以随意选取,但是程序员间约定俗成的动态关键字参数名为**kwargs:
def func(a,b,*args,**kwargs):
print(a,b,args,kwargs)
func(1,2,3,4,5,6,76,87,8,c=100)
输出的结果为:1 2 (3, 4, 5, 6, 76, 87, 8) {'c': 100}
前两个位置参数分别传给了a和b,剩余的位置参数打包成元组传给了args,而关键字参数则以字典的形式传给了kwargs。
当我们需要设置多种参数时,推荐使用的顺序是:位置参数,动态位置参数,默认参数,动态关键字参数:
def func(a,b,*args,m=8,**kwargs,):
# 位置参数,动态位置,默认参数,动态关键字参数
print(a,b,m,args,kwargs)
func(1,2,4,5,m=10,c=11,d=12)
输出的结果为:1 2 10 (4, 5) {'c': 11, 'd': 12}
函数参数总结
- 优先级:位置参数 > 动态位置参数(可变位置参数)> 默认参数 > 动态关键字参数(可变关键字参数)
*args和**kwargs是程序员之间约定俗成的命名法(可以更换但是不建议更换)*args获取的是一个元组**kwargs获取的是一个字典*args只接收多余的位置参数**kwargs只接收多余的关键字参数
函数参数补充
万能传参
因为动态位置参数和动态关键字参数可以接受所有的位置参数和关键字参数,所以在设置形参时,我们甚至可以只设置*args和**kwargs两个形参,这种传参方法被称作万能传参:
def func(*args,**kwargs): # 万能传参
print(args,kwargs)
func(12,2,121,12,321,3,a=1,b=2)
输出的结果为:(12, 2, 121, 12, 321, 3) {'a': 1, 'b': 2}
聚合与打散
在前面的动态位置参数部分已经讨论过,形参中的*args是将多于变量聚合为元组,函数体中的*args是将元组打散。其实对于**kwargs来说也很类似:形参中的**kwargs是将key=1, key2=2这样类型的语句转化为字典,而函数体中*kwargs是获取字典中所有的键,**kwargs是将字典打散为key=1, key2=2的语句。
除了函数中,我们可以在python的很多地方灵活运用打散和聚合的操作:
lst = [1,2,3,4,6,7]
def func(*args): # 聚合
print(*args) # 打散
func(*lst) # 打散 func(1,2,3,4,6,7)
dic = {"key":1,"key2":2}
def func(**kwargs): # 聚合
print(kwargs) # 打散
func(**dic) # 打散 func(key=1,key2=2)
输出的结果为:
1 2 3 4 6 7
{'key': 1, 'key2': 2}
函数的注释
在协同操作的过程中,大家或许会查看和使用彼此的代码。但是如果没有任何提示性的内容的话,从头开始看起会有很大的理解困难。如果我们将函数的一些功能、参数要求等信息在函数中写出来,别人阅读时就会节省很多时间,也更容易理解调用和修改我们的函数。
标准的函数注释应该是这样的:
def add(a,b):
"""
数字的加法运算
:param a: int
:param b: int
:return: int
"""
return a + b
print(add(1,2))
函数中使用三对",就是代表注释。也可以使用'表示,但是不推荐。
另外一种比较流行的注释方法是在形参后加入:数据类型,例如:
def add(a:int,b:int): # 提示,没有做到约束
"""
加法
:param a:
:param b:
:return:
"""
return a + b
add(1,2)
add("1","2")
需要注意的是,参数的作用只是起到提示的作用,并不会进行判断,约束我们传入变量的数据类型。
我们可以通过函数名.__doc__的方法查看函数的注释;通过函数名.__name__的方法查看函数的名字。
函数的名称空间
函数的名称空间一共有三种:
- 内置空间,用来存放python自带的一些函数,python程序运行时会首先加载
- 全局空间,当前py文件顶格编写的代码开辟的空间
- 局部空间,函数开辟的空间
程序的加载顺序是:内置空间 > 全局空间 > 局部空间
程序的取值顺序是:局部空间 > 全局空间 > 内置空间
程序取值顺序示例:
a = 10
def func():
a = 5
print(a)
func()
输出的结果为:5
变量取值时会优先查看局部空间,找到变量a,值为5,打印了出来。
函数的作用域有两个:
- 全局作用域:内置空间 + 全局空间,使用
globals()方法查看全局作用域 - 局部作用域:局部空间,使用
locals()方法查看当前作用域(全局和局部作用域都可以查看,建议用此方法查看局部作用域)
a = 10
def func():
b = 5
print(locals())
print(globals())
func()
print(globals())
print(locals())
函数名的第一类对象及使用
函数名的第一类对象只是一种称呼,是相对于第二类对象而言的。我们目前用到的函数基本都是第一类对象。
函数名的第一类对象主要有四个方面的应用:
- 函数名可以当作值赋值给一个变量
- 函数名可以当做另一个函数的参数来使用
- 函数名可以当做另一个函数的返回值
- 函数名可以当作元素放在容器中
示例一:
def func():
print(1)
a = func
print(func) # 函数的内存地址
print(a)
a()
输出的结果为:
<function func at 0x00000197E2D41EA0>
<function func at 0x00000197E2D41EA0>
1
func和a同样都是指向函数的内存地址,当我们调用a时,得到了同调用func相同的结果。
示例二:
def func():
print(1)
def foo(a):
print(a)
foo(func)
输出的结果为:<function func at 0x0000021FD82C1EA0>
示例三:
def func():
return 1
def foo(a):
return a
cc = foo(func)
print(cc)
输出的结果是:<function func at 0x000002261A231EA0>
示例四:
有这样一个需求:用户选择需要相应的序号进行选择接下来的操作,比如选择1会调用注册的函数,选择2会调用登陆的函数……从前我们会通过流程控制语句的方式实现:
def login():
print("登录")
def register():
print("注册")
def shopping():
print("逛")
def add_shopping_car():
print("加")
def buy_goods():
print("买")
msg ="""
1.注册
2.登录
3.逛
4.加
5.买
请输入您要选择的序号:
"""
while True:
choose = input(msg)
if choose.isdecimal():
if choose == "1":
register()
elif choose == "2":
login()
elif choose == "3":
shopping()
elif choose == "4":
add_shopping_car()
elif choose == "5":
buy_goods()
else:
print("滚")
通过将函数装到字典里,我们可以大量减少重复的代码:
def login():
print("登录")
def register():
print("注册")
def shopping():
print("逛")
def add_shopping_car():
print("加")
def buy_goods():
print("买")
msg ="""
1.注册
2.登录
3.逛
4.加
5.买
请输入您要选择的序号:
"""
func_dic = {"1":register,
"2":login,
"3":shopping,
"4":add_shopping_car,
"5":buy_goods}
while True:
choose = input(msg) # "5"
if choose in func_dic:
func_dic[choose]()
else:
print("滚")
这种使用字典调用函数的方式是一种很重要的编程思想,以后将经常用到。
函数的嵌套
函数的嵌套有两种方式:
- 交叉嵌套
- 回环嵌套
交叉嵌套的方式是在本函数中调用同一级或上一级函数的嵌套方法:
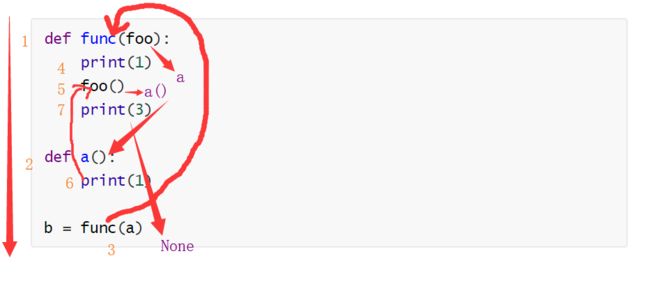
def func(foo):
print(1)
foo()
print(3)
def a():
print(1)
b = func(a)
print(b)
输出的结果为:
1
1
3
None
首先,程序会将python文件中顶格的代码运行。函数func和a都是先开辟内存空间存储起来,但不会被执行。当程序走到赋值操作时,会先执行等号右边的代码。函数func被调用,函数a作为参数被传到func中。func函数被执行,顺序也是从上往下,显示把1打印出来,然后调用参数foo。需要注意的是,foo是形参,实参是a。调用foo在此时的意思是调用函数a。函数a被调用,又打印出一个1来。函数a运行完毕,返回至函数func,继续执行下面的代码,打印出3来。最后,函数默认返回None,赋值给b。程序运行结束。
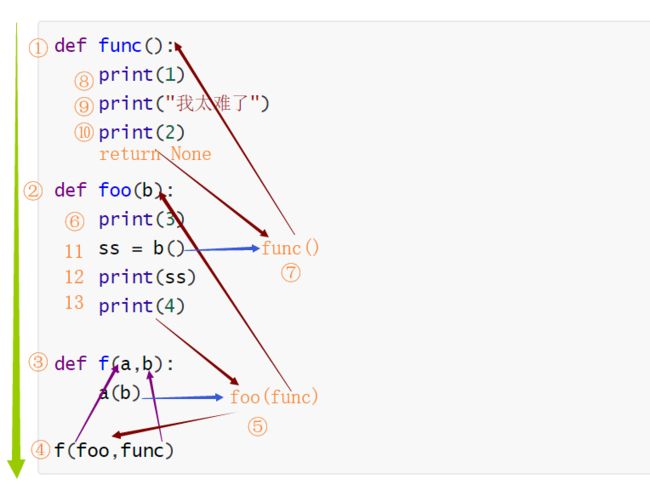
再看下面的代码:
def func():
print(1)
print("我太难了")
print(2)
def foo(b):
print(3)
ss = b()
print(ss)
print(4)
def f(a,b):
a(b)
f(foo,func)
输出的结果为:
3
1
我太难了
2
None
4
跟上面一样,先将函数全都加载到新开辟的内存空间中,但不执行。到最后f函数被调用,foo和func两个函数作为参数被传到函数f中。在函数f中,foo函数被调用,参数为func函数。进入到foo函数,先打印3。到赋值语句,先执行等号右边的代码,函数func被调用。在函数func中,打印三个内容1、我太难了和2。函数默认返回值为None,被赋值给ss。打印ss就是打印None。最后打印4,然后返回到函数f,再返回到全局空间。执行结束。
回环函数就是在函数中调用下级函数的嵌套方法:
def func(a,b):
def foo(b,a):
print(b,a)
return foo(a,b) #先执行函数调用
a = func(4,7)
print(a)
输出的结果为:
4 7
None
函数依然先存储在新开辟的空间中不会被调用。运行到赋值语句时,还是先执行等号右边的代码,将两个数字传到函数func中。在函数内部,依然是先开辟空间把函数foo放进去。运行到return不会马上终止函数,而是先运行return后面的代码。foo函数被调用,传进去的值是4和7,然后打印出来。需要注意的是,函数foo的形参与函数func的形参是相同的,不要给搞混了。日常写代码时不建议这样使用。打印出4和7之后,运行到函数最后一行,函数默认返回None。然后再赋值给a,打印出来。

global和nonlocal
global方法
我们来看下面这段代码:
b = 100
def func():
b = b + 1
return b
print(func())
这段代码看上去中规中矩,似乎没有什么问题,但是程序运行后确报错。
这是因为在Python中,不允许直接在局部空间修改全局变量。b = b + 1是一个冲突的语句:等式右边的b是要调用一个全部变量,而等号右边却是要定义一个局部变量。

如果将b视作一个全局变量依然不合适。在函数中修改全局变量会对其他调用相同变量的函数造成影响,除非万不得已或者十分确定的情况下,不建议在函数中修改全局变量。
当我们确定需要在函数中修改全局变量时,可以通过global方法来实现:
b = 100
def func():
global b
b = b + 1
return b
print(func())
输出的结果为:101
如果global声明的变量在全局空间中不存在,将会在全局空间中新建一个变量:
def func():
global a
a = 10
a = a + 12
print(a)
func()
print(a)
输出的结果为:
22
22
nonlocal方法
对于回环嵌套的函数来说,也会有类似的问题。当尝试使用内层函数修改外层函数的变量时会报错:
a = 15
def func():
a = 10
def foo():
a = a + 1
foo()
print(a)
func()
print(a)
类似地,也不建议在内层函数中修改外层函数的变量。如果一定要修改的话,可以使用nonlocal方法:
a = 15
def func():
a = 10
def foo():
nonlocal a
a = a + 1
foo()
print(a)
func()
print(a)
输出的结果为:
11
15
nonlocal方法只修改离它最近的一层函数的变量,如果这一层没有就往上一层查找,只能在局部查找。另外,外层函数不能调用内层函数的变量,即便用nonlocal方法也不行。如果外层所有函数中都没有声明的变量,即便全局空间中有也不行,而且nonlocal不能创建变量。如果找不到,就会报错:
a = 15
def func():
def foo():
nonlocal a
a = a + 1
foo()
func()
print(a)
其实想来这个设定也是合理的:如果外面套了很多层函数,这个变量该在哪一层创建呢?
global和nonlocal方法总结
global只修改全局空间中的变量
- 在局部空间中可以使用全局中的变量,但是不能修改。如果要强制修改,需要使用
global声明 - 当变量在全局存在时,
global就是声明我要修改全局的变量 - 当变量在全局中不存在时,
global则是声明要在全局创建一个变量
nonlocal只修改局部空间中的变量,最多只能到达最外层函数
- 在内层函数中可以使用外层函数中的变量,但是不能修改。如果要强制修改,需要使用
nonlocal声明 - 只修改离
nonlocal最近的一层,如果这一层没有就往上一层查找,不能找到全局中 nonlocal不能创建变量,如果其声明的变量在外层函数中找不到,即便全局空间中有,也会报错
对函数的传参有一点补充,传参的时候相当于在当前函数体中进行了赋值操作:
def func(a):
# 相当于在func函数体中写了这么一个 a = 100 操作
print(locals())
func(100)
最后来一道思考题,请确定下列函数输出的结果:
a = 10
def func():
a = 5
def foo():
a = 3
def f():
nonlocal a
a = a + 1
def aa():
a = 1
def b():
global a
a = a + 1
print(a)
b()
print(a)
aa()
print(a)
f()
print(a)
foo()
print(a)
func()
print(a)