部分问题记录
1、数据倾斜解决、hive join优化!!!https://blog.csdn.net/u013760453/article/details/88600841
2、 多线程、多进程 https://blog.csdn.net/u013760453/article/details/88605530
3、java线程池原理,常见线程池 https://blog.csdn.net/u013760453/article/details/88981180
3、多线程控制场景 https://blog.csdn.net/u013760453/article/details/89049247
3、akka并发通信、actor模型的理解 https://blog.csdn.net/u013760453/article/details/89049691
3、hive数据压缩 https://blog.csdn.net/u013760453/article/details/89056700
3、数据仓库建模、kimball https://blog.csdn.net/u013760453/article/details/89063448
3、拉链表 https://blog.csdn.net/u013760453/article/details/88997386
3、hive查询示例、执行计划 https://blog.csdn.net/u013760453/article/details/89067682
3、ETL调度
3、阻塞队列、读写锁、生产者消费者模型
https://blog.csdn.net/u013760453/article/details/89063721
https://blog.csdn.net/u013760453/article/details/89165842
4、spark常用算子!!!https://blog.csdn.net/u013760453/article/details/88671231
5、hiveSQL窗口函数、函数!!!
https://blog.csdn.net/u013760453/article/details/88705072
https://blog.csdn.net/Abysscarry/article/details/81408265
https://blog.csdn.net/haramshen/article/details/52668586
6、设计模式:https://blog.csdn.net/u013760453/article/details/88560134
7、jvm、gc、优化、类加载:https://blog.csdn.net/u013760453/article/details/88563931
7、hadoop(shuffle、环形缓冲区、执行流程)、spark(执行流程)!!!https://blog.csdn.net/u013760453/article/details/88629242
8、二叉树翻转、序列化反序列化二叉树、二叉树遍历!!!
9、hive如何解析为MR、hiveUDF https://blog.csdn.net/u013760453/article/details/88760097
10、快排、栈实现队列、MR实现矩阵乘法、
11、zookeeper算法
12、HashMap、ConcurrentHashMap相关内容 https://blog.csdn.net/u013760453/article/details/88760464
13、父类子类加载顺序
大前提:静态》非静态,
小前提:父类》子类
类内部:变量》代码块》构造函数
静态父类变量
静态父类代码块(若有多个按代码先后顺序执行)
静态子类变量
静态子类代码块(若有多个按代码先后顺序执行)
非静态父类变量
非静态父类代码块(若有多个按代码先后顺序执行)
父类构造函数
非静态子类变量
非静态子类代码块(若有多个按代码先后顺序执行)
子类构造函数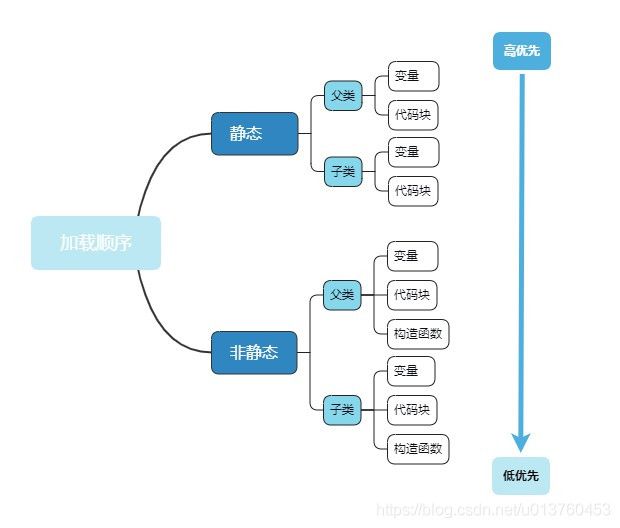
14、B树、B+树、红黑树
| B树 | B+树(Mysql索引) | 红黑树 | |
| 结构 | 多叉树 | 在B树的叶子节点间加上指针,使其能范围查找 | 二叉树 |
| 特点 | 深度小 | 深度大 | |
| 存储在外存时 | IO少,快 | IO多,慢 | |
| 存储在内存时 | 效率低,慢 | 效率高,快 | |
15、排序算法

18、聚焦索引、非聚焦索引
聚焦索引:树的叶节点包含着实际数据。
非聚焦索引:树的叶节点包含的是实际数据的地址。
- innodb表文件本身就是聚焦索引,数据存储也是聚焦索引的顺序。
- innodb表必有一个聚焦索引,默认顺序为:主键>第一个非空的唯一索引>隐藏的自增rowid
| 聚焦索引 | 非聚焦索引 | |
| 实质 | 树的叶节点包含着实际数据 | 树的叶节点包含的是实际数据的地址 |
| 数目 | 一张表一个 | 一张表多个 |
| 位置 | 表文件本身就是索引 | 索引存在单独的文件中 |
| 特点 | 聚焦索引中索引的顺序就是数据存放的顺序,索引相邻则数据存放位置就相邻; 利于范围查找; 不利于更新; |
索引顺序与数据存放位置无关; |
19、脏读、不可重复读、幻读
- 脏读: 一个事务读到了其他事务未提交的数据变动。
- 不可重复读:两个事务并发,一个事务修改(update/delete)了记录,使得另一个事务中,同一条记录两次读取获得不同结果。(可以使用行级锁避免)
- 幻读: 两个事务并发,一个事务增删( insert /delete)了记录,使得另一个事务中,同一条记录两次读取获得相同结果,但整体来看增加或减少了记录。(可以使用范围锁避免)