队列
先入先出的数据结构
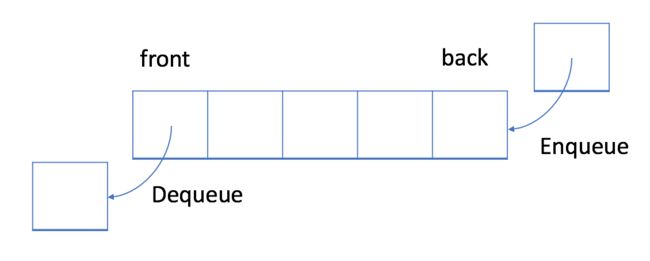
在 FIFO 数据结构中,将首先处理添加到队列中的第一个元素。
如上图所示,队列是典型的 FIFO 数据结构。插入(insert)操作也称作入队(enqueue),新元素始终被添加在队列的末尾。 删除(delete)操作也被称为出队(dequeue)。 你只能移除第一个元素。
示例 - 队列
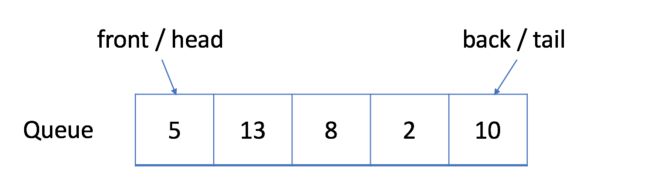
- 入队:您可以单击下面的
Enqueue以查看如何将新元素 6 添加到队列中。

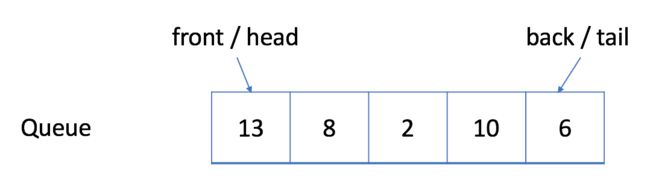
- 出队:您可以单击下面的
Dequeue以查看将删除哪个元素。

队列-实现
为了实现队列,我们可以使用动态数组和指向队列头部的索引。
如上所述,队列应支持两种操作:入队和出队。入队会向队列追加一个新元素,而出队会删除第一个元素。 所以我们需要一个索引来指出起点。
这是一个供你参考的实现:
#include
#include
using namespace std;
class MyQueue {
private:
// store elements
vector data;
// a pointer to indicate the start position
int p_start;
public:
MyQueue() {p_start = 0;}
/** Insert an element into the queue. Return true if the operation is successful. */
bool enQueue(int x) {
data.push_back(x);
return true;
}
/** Delete an element from the queue. Return true if the operation is successful. */
bool deQueue() {
if (isEmpty()) {
return false;
}
p_start++;
return true;
};
/** Get the front item from the queue. */
int Front() {
return data[p_start];
};
/** Checks whether the queue is empty or not. */
bool isEmpty() {
return p_start >= data.size();
}
};
int main() {
MyQueue q;
q.enQueue(5);
q.enQueue(3);
if (!q.isEmpty()) {
cout << q.Front() << endl;
}
q.deQueue();
if (!q.isEmpty()) {
cout << q.Front() << endl;
}
q.deQueue();
if (!q.isEmpty()) {
cout << q.Front() << endl;
}
} 缺点
上面的实现很简单,但在某些情况下效率很低。 随着起始指针的移动,浪费了越来越多的空间。 当我们有空间限制时,这将是难以接受的。

让我们考虑一种情况,即我们只能分配一个最大长度为 5 的数组。当我们只添加少于 5 个元素时,我们的解决方案很有效。 例如,如果我们只调用入队函数四次后还想要将元素 10 入队,那么我们可以成功。
但是我们不能接受更多的入队请求,这是合理的,因为现在队列已经满了。但是如果我们将一个元素出队呢?

实际上,在这种情况下,我们应该能够再接受一个元素。
循环队列
此前,我们提供了一种简单但低效的队列实现。
更有效的方法是使用循环队列。 具体来说,我们可以使用固定大小的数组和两个指针来指示起始位置和结束位置。 目的是重用我们之前提到的被浪费的存储。
让我们通过一个示例来查看循环队列的工作原理。 你应该注意我们入队或出队元素时使用的策略。

仔细检查动画,找出我们用来检查队列是空还是满的策略。
下一个练习,我们将让你自己尝试实现循环队列,之后会提供给你一个解决方案。
设计循环队列
设计你的循环队列实现。 循环队列是一种线性数据结构,其操作表现基于 FIFO(先进先出)原则并且队尾被连接在队首之后以形成一个循环。它也被称为“环形缓冲器”。
循环队列的一个好处是我们可以利用这个队列之前用过的空间。在一个普通队列里,一旦一个队列满了,我们就不能插入下一个元素,即使在队列前面仍有空间。但是使用循环队列,我们能使用这些空间去存储新的值。
你的实现应该支持如下操作:
MyCircularQueue(k): 构造器,设置队列长度为 k 。Front: 从队首获取元素。如果队列为空,返回 -1 。Rear: 获取队尾元素。如果队列为空,返回 -1 。enQueue(value): 向循环队列插入一个元素。如果成功插入则返回真。deQueue(): 从循环队列中删除一个元素。如果成功删除则返回真。isEmpty(): 检查循环队列是否为空。isFull(): 检查循环队列是否已满。
示例:
MyCircularQueue circularQueue = new MycircularQueue(3); // 设置长度为 3
circularQueue.enQueue(1); // 返回 true
circularQueue.enQueue(2); // 返回 true
circularQueue.enQueue(3); // 返回 true
circularQueue.enQueue(4); // 返回 false,队列已满
circularQueue.Rear(); // 返回 3
circularQueue.isFull(); // 返回 true
circularQueue.deQueue(); // 返回 true
circularQueue.enQueue(4); // 返回 true
circularQueue.Rear(); // 返回 4
提示:
- 所有的值都在 0 至 1000 的范围内;
- 操作数将在 1 至 1000 的范围内;
- 请不要使用内置的队列库。
#include
#include
using namespace std;
/// One more space implementation
/// Time Complexity: O(1)
/// Space Complexity: O(n)
class MyCircularQueue
{
private:
int front, tail;
vector data;
public:
MyCircularQueue(int k)
{
front = tail = 0;
data.clear();
for (int i = 0; i <= k; i++) //这里多分配了一个空间
data.push_back(-1);
}
bool enQueue(int value)
{
if (isFull())
return false;
data[tail] = value;
tail = (tail + 1) % data.size();
return true;
}
bool deQueue()
{
if (isEmpty())
return false;
front = (front + 1) % data.size();
return true;
}
int Front(){
if(isEmpty())
return -1;
return data[front];
}
int Rear()
{
if (isEmpty())
return -1;
int index = tail - 1;
if (index < 0)
index += data.size();
return data[index];
}
bool isEmpty()
{
return front == tail;
}
bool isFull()
{
return (tail + 1) % data.size() == front;
}
}; 循环队列-实现
在循环队列中,我们使用一个数组和两个指针(head 和 tail)。 head 表示队列的起始位置,tail 表示队列的结束位置。
这里我们提供了代码供你参考:
class MyCircularQueue {
private:
vector data;
int head;
int tail;
int size;
public:
/** Initialize your data structure here. Set the size of the queue to be k. */
MyCircularQueue(int k) {
data.resize(k);
head = -1;
tail = -1;
size = k;
}
/** Insert an element into the circular queue. Return true if the operation is successful. */
bool enQueue(int value) {
if (isFull()) {
return false;
}
if (isEmpty()) {
head = 0; //第一次入队,下标将从0开始。
}
tail = (tail + 1) % size; //之后只需调整队尾指针。
data[tail] = value;
return true;
}
/** Delete an element from the circular queue. Return true if the operation is successful. */
bool deQueue() {
if (isEmpty()) {
return false;
}
if (head == tail) { //这里与下面的判断方式不同
head = -1;
tail = -1;
return true;
}
head = (head + 1) % size;
return true;
}
/** Get the front item from the queue. */
int Front() {
if (isEmpty()) {
return -1;
}
return data[head];
}
/** Get the last item from the queue. */
int Rear() {
if (isEmpty()) {
return -1;
}
return data[tail];
}
/** Checks whether the circular queue is empty or not. */
bool isEmpty() {
return head == -1; //这不是用head == tail判断
}
/** Checks whether the circular queue is full or not. */
bool isFull() {
return ((tail + 1) % size) == head;
}
};
/**
* Your MyCircularQueue object will be instantiated and called as such:
* MyCircularQueue obj = new MyCircularQueue(k);
* bool param_1 = obj.enQueue(value);
* bool param_2 = obj.deQueue();
* int param_3 = obj.Front();
* int param_4 = obj.Rear();
* bool param_5 = obj.isEmpty();
* bool param_6 = obj.isFull();
*/ 队列-用法
大多数流行语言都提供内置的队列库,因此您无需重新发明轮子。
如前所述,队列有两个重要的操作,入队 enqueue 和出队 dequeue。 此外,我们应该能够获得队列中的第一个元素,因为应该首先处理它。
下面是使用内置队列库及其常见操作的一些示例:
#include
int main() {
// 1. Initialize a queue.
queue q;
// 2. Push new element.
q.push(5);
q.push(13);
q.push(8);
q.push(6);
// 3. Check if queue is empty.
if (q.empty()) {
cout << "Queue is empty!" << endl;
return 0;
}
// 4. Pop an element.
q.pop();
// 5. Get the first element.
cout << "The first element is: " << q.front() << endl;
// 6. Get the last element.
cout << "The last element is: " << q.back() << endl;
// 7. Get the size of the queue.
cout << "The size is: " << q.size() << endl;
} 我们在本文之后提供了练习,以帮助你熟悉这些操作。请记住,当你想要按顺序处理元素时,使用队列可能是一个很好的选择。
数据流中的移动平均值
*到了这一题,发现要开会员才能看到题目-_-b,于是我就去百度找题目了。*
Given a stream of integers and a window size, calculate the moving average of all integers in the sliding window.
For example,
MovingAverage m = new MovingAverage(3);
m.next(1) = 1
m.next(10) = (1 + 10) / 2
m.next(3) = (1 + 10 + 3) / 3
m.next(5) = (10 + 3 + 5) / 3
给一个整数流和一个窗口,计算在给定大小的窗口里的数字的平均值。
解法:队列queue,用一个queue记录进入窗口的整数。当流进窗口的整数不足时,计算所有窗口内的数字和返回,当进入窗口的整数多于窗口大小时,移除最先进入窗口的整数,新的整数进入queue,然后计算窗口内的整数和。#include
#include
using namespace std;
/// Using Queue
/// Time Complexity: O(1)
/// Space Complexity: O(size)
class MovingAverage
{
private:
queue q;
int sz, sum;
public:
MovingAverage(int size)
{
sz = size;
sum = 0;
}
double next(int val)
{
if (q.size() == sz)
{
sum -= q.front();
q.pop();
}
sum += val;
q.push(val);
return (double)sum / q.size();
}
} 队列和广度优先搜索
队列和BFS
广度优先搜索(BFS)的一个常见应用是找出从根结点到目标结点的最短路径。在本文中,我们提供了一个示例来解释在 BFS 算法中是如何逐步应用队列的。
示例
这里我们提供一个示例来说明如何使用 BFS 来找出根结点 A 和目标结点 G 之间的最短路径。

洞悉
观看上面的动画后,让我们回答以下问题:
1. 结点的处理顺序是什么?
在第一轮中,我们处理根结点。在第二轮中,我们处理根结点旁边的结点;在第三轮中,我们处理距根结点两步的结点;等等等等。
与树的层序遍历类似,越是接近根结点的结点将越早地遍历。
如果在第 k 轮中将结点 X 添加到队列中,则根结点与 X 之间的最短路径的长度恰好是 k。也就是说,第一次找到目标结点时,你已经处于最短路径中。
2. 队列的入队和出队顺序是什么?
如上面的动画所示,我们首先将根结点排入队列。然后在每一轮中,我们逐个处理已经在队列中的结点,并将所有邻居添加到队列中。值得注意的是,新添加的节点不会立即遍历,而是在下一轮中处理。
结点的处理顺序与它们添加到队列的顺序是完全相同的顺序,即先进先出(FIFO)。这就是我们在 BFS 中使用队列的原因。
广度优先搜索-模板
之前,我们已经介绍了使用 BFS 的两个主要方案:遍历或找出最短路径。通常,这发生在树或图中。正如我们在章节描述中提到的,BFS 也可以用于更抽象的场景中。
在本文中,我们将为你提供一个模板。然后,我们在本文后提供一些习题供你练习。
在特定问题中执行 BFS 之前确定结点和边缘非常重要。通常,结点将是实际结点或是状态,而边缘将是实际边缘或可能的转换。
模板I
在这里,我们为你提供伪代码作为模板:
/**
* Return the length of the shortest path between root and target node.
*/
int BFS(Node root, Node target) {
Queue queue; // store all nodes which are waiting to be processed
int step = 0; // number of steps neeeded from root to current node
// initialize
add root to queue;
// BFS
while (queue is not empty) {
step = step + 1;
// iterate the nodes which are already in the queue
int size = queue.size();
for (int i = 0; i < size; ++i) {
Node cur = the first node in queue;
return step if cur is target;
for (Node next : the neighbors of cur) {
add next to queue;
}
remove the first node from queue;
}
}
return -1; // there is no path from root to target
} - 如代码所示,在每一轮中,队列中的结点是
等待处理的结点。 - 在每个更外一层的
while循环之后,我们距离根结点更远一步。变量step指示从根结点到我们正在访问的当前结点的距离。
模板 II
有时,确保我们永远不会访问一个结点两次很重要。否则,我们可能陷入无限循环。如果是这样,我们可以在上面的代码中添加一个哈希集来解决这个问题。这是修改后的伪代码:
/**
* Return the length of the shortest path between root and target node.
*/
int BFS(Node root, Node target) {
Queue queue; // store all nodes which are waiting to be processed
Set used; // store all the used nodes
int step = 0; // number of steps neeeded from root to current node
// initialize
add root to queue;
add root to used;
// BFS
while (queue is not empty) {
step = step + 1;
// iterate the nodes which are already in the queue
int size = queue.size();
for (int i = 0; i < size; ++i) {
Node cur = the first node in queue;
return step if cur is target;
for (Node next : the neighbors of cur) {
if (next is not in used) {
add next to queue;
add next to used;
}
}
remove the first node from queue;
}
}
return -1; // there is no path from root to target
} 有两种情况你不需要使用哈希集:
- 你完全确定没有循环,例如,在树遍历中;
- 你确实希望多次将结点添加到队列中。
墙与门
转载自https://www.cnblogs.com/grandyang/p/5285868.html
You are given a m x n 2D grid initialized with these three possible values.
-1- A wall or an obstacle.0- A gate.INF- Infinity means an empty room. We use the value231 - 1 = 2147483647to representINFas you may assume that the distance to a gate is less than2147483647.
Fill each empty room with the distance to its nearest gate. If it is impossible to reach a gate, it should be filled with INF.
For example, given the 2D grid:
INF -1 0 INF
INF INF INF -1
INF -1 INF -1
0 -1 INF INFAfter running your function, the 2D grid should be:
3 -1 0 1
2 2 1 -1
1 -1 2 -1
0 -1 3 4这道题类似一种迷宫问题,规定了-1表示墙,0表示门,让求每个点到门的最近的曼哈顿距离,这其实类似于求距离场Distance Map的问题,那么我们先考虑用DFS来解,思路是,我们搜索0的位置,每找到一个0,以其周围四个相邻点为起点,开始DFS遍历,并带入深度值1,如果遇到的值大于当前深度值,我们将位置值赋为当前深度值,并对当前点的四个相邻点开始DFS遍历,注意此时深度值需要加1,这样遍历完成后,所有的位置就被正确地更新了,参见代码如下:
解法一:
class Solution {
public:
void wallsAndGates(vector>& rooms) {
for (int i = 0; i < rooms.size(); ++i) {
for (int j = 0; j < rooms[i].size(); ++j) {
if (rooms[i][j] == 0) dfs(rooms, i, j, 0);
}
}
}
void dfs(vector>& rooms, int i, int j, int val) {
if (i < 0 || i >= rooms.size() || j < 0 || j >= rooms[i].size() || rooms[i][j] < val) return;
rooms[i][j] = val;
dfs(rooms, i + 1, j, val + 1);
dfs(rooms, i - 1, j, val + 1);
dfs(rooms, i, j + 1, val + 1);
dfs(rooms, i, j - 1, val + 1);
}
}; 那么下面我们再来看BFS的解法,需要借助queue,我们首先把门的位置都排入queue中,然后开始循环,对于门位置的四个相邻点,我们判断其是否在矩阵范围内,并且位置值是否大于上一位置的值加1,如果满足这些条件,我们将当前位置赋为上一位置加1,并将次位置排入queue中,这样等queue中的元素遍历完了,所有位置的值就被正确地更新了,参见代码如下:
解法二:
class Solution {
public:
void wallsAndGates(vector>& rooms) {
queue> q;
vector> dirs{{0, -1}, {-1, 0}, {0, 1}, {1, 0}};
for (int i = 0; i < rooms.size(); ++i) {
for (int j = 0; j < rooms[i].size(); ++j) {
if (rooms[i][j] == 0) q.push({i, j});
}
}
while (!q.empty()) {
int i = q.front().first, j = q.front().second; q.pop();
for (int k = 0; k < dirs.size(); ++k) {
int x = i + dirs[k][0], y = j + dirs[k][1];
if (x < 0 || x >= rooms.size() || y < 0 || y >= rooms[0].size() || rooms[x][y] < rooms[i][j] + 1) continue;
rooms[x][y] = rooms[i][j] + 1;
q.push({x, y});
}
}
}
}; 岛屿数量
给定一个由 '1'(陆地)和 '0'(水)组成的的二维网格,计算岛屿的数量。一个岛被水包围,并且它是通过水平方向或垂直方向上相邻的陆地连接而成的。你可以假设网格的四个边均被水包围。
示例 1:
输入:
11110
11010
11000
00000
输出: 1示例 2:
输入:
11000
11000
00100
00011
输出: 3思路:只需判断陆地有没有跟已发现的岛屿相邻,如果没有相邻,则是新的岛屿。
/// Source : https://leetcode.com/problems/number-of-islands/description/
/// Author : liuyubobobo
/// Time : 2018-08-25
#include
#include
#include
#include
using namespace std;
/// Floodfill - BFS
/// Time Complexity: O(n*m)
/// Space Complexity: O(n*m)
class Solution {
private:
int d[4][2] = {{0, 1}, {1, 0}, {0, -1}, {-1, 0}}; //分别表示上、右、下、左
int m, n;
public:
int numIslands(vector>& grid) {
m = grid.size();
if(m == 0)
return 0;
n = grid[0].size();
if(n == 0)
return 0;
vector> visited(m, vector(n, false));
int res = 0;
for(int i = 0 ; i < m ; i ++)
for(int j = 0 ; j < n ; j ++)
if(grid[i][j] == '1' && !visited[i][j]){
bfs(grid, i, j, visited);
res ++;
}
return res;
}
private:
void bfs(vector>& grid, int x, int y, vector>& visited){
queue> q;
q.push(make_pair(x, y));
visited[x][y] = true;
while(!q.empty()){
int curx = q.front().first;
int cury = q.front().second;
q.pop();
for(int i = 0; i < 4; i ++){
int newX = curx + d[i][0];
int newY = cury + d[i][1];
if(inArea(newX, newY) && !visited[newX][newY] && grid[newX][newY] == '1'){
q.push(make_pair(newX, newY));
visited[newX][newY] = true;
}
}
}
return;
}
bool inArea(int x, int y){
return x >= 0 && x < m && y >= 0 && y < n;
}
};
int main() {
vector> grid1 = {
{'1','1','1','1','0'},
{'1','1','0','1','0'},
{'1','1','0','0','0'},
{'0','0','0','0','0'}
};
cout << Solution().numIslands(grid1) << endl;
// 1
// ---
vector> grid2 = {
{'1','1','0','0','0'},
{'1','1','0','0','0'},
{'0','0','1','0','0'},
{'0','0','0','1','1'}
};
cout << Solution().numIslands(grid2) << endl;
// 3
return 0;
} 打开转盘锁
你有一个带有四个圆形拨轮的转盘锁。每个拨轮都有10个数字: '0', '1', '2', '3', '4', '5', '6', '7', '8', '9' 。每个拨轮可以自由旋转:例如把 '9' 变为 '0','0' 变为 '9' 。每次旋转都只能旋转一个拨轮的一位数字。
锁的初始数字为 '0000' ,一个代表四个拨轮的数字的字符串。
列表 deadends 包含了一组死亡数字,一旦拨轮的数字和列表里的任何一个元素相同,这个锁将会被永久锁定,无法再被旋转。
字符串 target 代表可以解锁的数字,你需要给出最小的旋转次数,如果无论如何不能解锁,返回 -1。
示例 1:
输入:deadends = ["0201","0101","0102","1212","2002"], target = "0202"
输出:6
解释:
可能的移动序列为 "0000" -> "1000" -> "1100" -> "1200" -> "1201" -> "1202" -> "0202"。
注意 "0000" -> "0001" -> "0002" -> "0102" -> "0202" 这样的序列是不能解锁的,
因为当拨动到 "0102" 时这个锁就会被锁定。示例 2:
输入: deadends = ["8888"], target = "0009"
输出:1
解释:
把最后一位反向旋转一次即可 "0000" -> "0009"。示例 3:
输入: deadends = ["8887","8889","8878","8898","8788","8988","7888","9888"], target = "8888"
输出:-1
解释:
无法旋转到目标数字且不被锁定。示例 4:
输入: deadends = ["0000"], target = "8888"
输出:-1提示:
- 死亡列表
deadends的长度范围为[1, 500]。 - 目标数字
target不会在deadends之中。 - 每个
deadends和target中的字符串的数字会在 10,000 个可能的情况'0000'到'9999'中产生。
思路:等价于八领域的迷宫问题,并绕过死锁区域。字符和数字的转换通过加 '0' 实现。
/// Source : https://leetcode.com/problems/open-the-lock/description/
/// Author : liuyubobobo
/// Time : 2017-12-23
#include
#include
#include
#include
#include
using namespace std;
/// BFS
/// Time Complexity: O(charset^N)
/// Space Complexity: O(charset^N)
class Solution {
public:
int openLock(vector& deadends, string target) {
set dead;
for(string s: deadends)
dead.insert(s);
if(dead.find(target) != dead.end() || dead.find("0000") != dead.end())
return -1;
set visited;
queue> q;
q.push(make_pair("0000", 0));
visited.insert("0000");
while(!q.empty()){
string cur = q.front().first;
int step = q.front().second;
q.pop();
vector next = getNext(cur, dead);
for(string next_s: next)
if(visited.find(next_s) == visited.end()){
if(next_s == target)
return step + 1;
visited.insert(next_s);
q.push(make_pair(next_s, step + 1));
}
}
return -1;
}
private:
vector getNext(const string& s, const set& dead){
vector res;
assert(s.size() == 4);
for(int i = 0 ; i < 4 ; i ++){
int num = s[i] - '0';
int d = num + 1;
if(d > 9) d = 0;
string t = s;
t[i] = ('0' + d);
if(dead.find(t) == dead.end())
res.push_back(t);
d = num - 1;
if(d < 0) d = 9;
t = s;
t[i] = ('0' + d);
if(dead.find(t) == dead.end())
res.push_back(t);
}
return res;
}
};
int main() {
vector dead1 = {"0201","0101","0102","1212","2002"};
string target1 = "0202";
cout << Solution().openLock(dead1, target1) << endl;
vector dead2 = {"8888"};
string target2 = "0009";
cout << Solution().openLock(dead2, target2) << endl;
vector dead3 = {"8887","8889","8878","8898","8788","8988","7888","9888"};
string target3 = "8888";
cout << Solution().openLock(dead3, target3) << endl;
vector dead4 = {"1002","1220","0122","0112","0121"};
string target4 = "1200";
cout << Solution().openLock(dead4, target4) << endl;
return 0;
} 完全平方数
给定正整数 n,找到若干个完全平方数(比如 1, 4, 9, 16, ...)使得它们的和等于 n。你需要让组成和的完全平方数的个数最少。
示例 1:
输入: n = 12
输出: 3
解释: 12 = 4 + 4 + 4.示例 2:
输入: n = 13
输出: 2
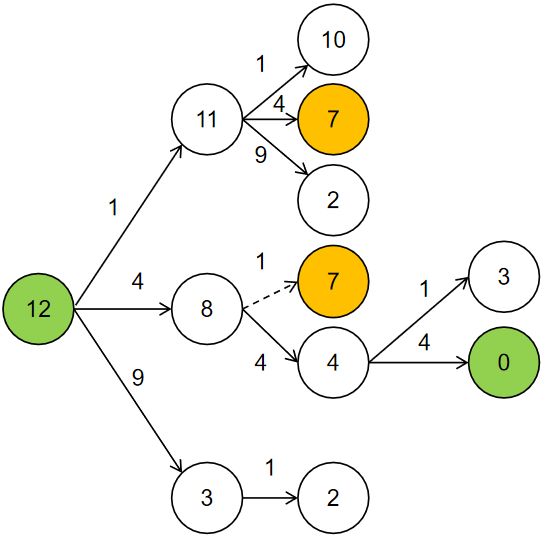
解释: 13 = 4 + 9.思路:该问题可转化为求图的无权最短路径,即正整数n到0间是否存在一条最短路径,路径上节点数目最少。因此采用BFS,率先抵达0的路径即为所求。此外,重复出现的节点,可不加入图中。如下图中第一个7若能到达0,则之后再出现的7也能抵达0,并且第一次出现的7所历经的层数一定比之后的7要少,无需重复计算。
/// Source : https://leetcode.com/problems/perfect-squares/description/
/// Author : liuyubobobo
/// Time : 2017-11-17
#include
#include
#include
#include
using namespace std;
/// BFS
/// Time Complexity: O(n)
/// Space Complexity: O(n)
class Solution {
public:
int numSquares(int n) {
if(n == 0)
return 0;
queue> q;
q.push(make_pair(n, 0));
vector visited(n + 1, false);
visited[n] = true;
while(!q.empty()){
int num = q.front().first;
int step = q.front().second;
q.pop();
for(int i = 1; num - i * i >= 0; i ++){
int a = num - i * i;
if(!visited[a]){
if(a == 0) return step + 1;
q.push(make_pair(a, step + 1));
visited[a] = true;
}
}
}
throw invalid_argument("No Solution.");
}
};
int main() {
cout << Solution().numSquares(12) << endl;
cout << Solution().numSquares(13) << endl;
return 0;
} 栈
后入先出的数据结构
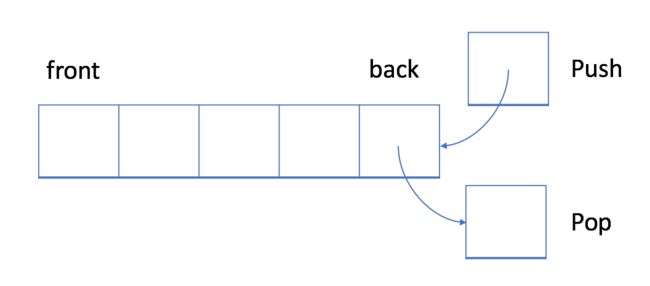
在 LIFO 数据结构中,将首先处理添加到队列中的最新元素。
与队列不同,栈是一个 LIFO 数据结构。通常,插入操作在栈中被称作入栈 push 。与队列类似,总是在堆栈的末尾添加一个新元素。但是,删除操作,退栈 pop ,将始终删除队列中相对于它的最后一个元素。
示例 - 栈
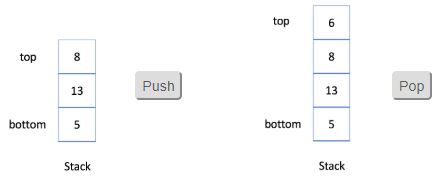
入栈:你可以单击下面的
Push按钮查看如何将新元素 6 添加到栈中。退栈:你可以单击下面的
Pop按钮查看当你从栈中弹出一个元素时将移除哪个元素。
实现 - 栈
#include
class MyStack {
private:
vector data; // store elements
public:
/** Insert an element into the stack. */
void push(int x) {
data.push_back(x);
}
/** Checks whether the queue is empty or not. */
bool isEmpty() {
return data.empty();
}
/** Get the top item from the queue. */
int top() {
return data.back();
}
/** Delete an element from the queue. Return true if the operation is successful. */
bool pop() {
if (isEmpty()) {
return false;
}
data.pop_back();
return true;
}
};
int main() {
MyStack s;
s.push(1);
s.push(2);
s.push(3);
for (int i = 0; i < 4; ++i) {
if (!s.isEmpty()) {
cout << s.top() << endl;
}
cout << (s.pop() ? "true" : "false") << endl;
}
} 栈-用法
大多数流行的语言都提供了内置的栈库,因此你不必重新发明轮子。除了初始化,我们还需要知道如何使用两个最重要的操作:入栈和退栈。除此之外,你应该能够从栈中获得顶部元素。下面是一些供你参考的代码示例:
#include
int main() {
// 1. Initialize a stack.
stack s;
// 2. Push new element.
s.push(5);
s.push(13);
s.push(8);
s.push(6);
// 3. Check if stack is empty.
if (s.empty()) {
cout << "Stack is empty!" << endl;
return 0;
}
// 4. Pop an element.
s.pop();
// 5. Get the top element.
cout << "The top element is: " << s.top() << endl;
// 6. Get the size of the stack.
cout << "The size is: " << s.size() << endl;
} 从现在开始,我们可以使用内置的栈库来更方便地解决问题。 让我们从一个有趣的问题(最小栈)开始,帮助你复习有用的操作。 然后我们将看一些经典的栈问题。 当你想首先处理最后一个元素时,栈将是最合适的数据结构。
最小栈
设计一个支持 push,pop,top 操作,并能在常数时间内检索到最小元素的栈。
- push(x) -- 将元素 x 推入栈中。
- pop() -- 删除栈顶的元素。
- top() -- 获取栈顶元素。
- getMin() -- 检索栈中的最小元素。
示例:
MinStack minStack = new MinStack();
minStack.push(-2);
minStack.push(0);
minStack.push(-3);
minStack.getMin(); --> 返回 -3.
minStack.pop();
minStack.top(); --> 返回 0.
minStack.getMin(); --> 返回 -2.思路:有两个栈:最小栈和普通栈。最小栈的元素个数和普通栈一样,最小栈中的元素为普通栈对应位置前所有元素的最小值。
class MinStack
{
private:
stack normalStack;
stack minStack;
public:
MinStack()
{
while (!normalStack.empty())
normalStack.pop();
while (!minStack.empty())
minStack.pop();
}
void push(int x)
{
normalStack.push(x);
if (minStack.empty())
minStack.push(x);
else
minStack.push(min(minStack.top(), x));
}
int pop()
{
assert(normalStack.size() > 0);
int v = normalStack.top();
normalStack.pop();
minStack.pop();
return v;
}
int top()
{
assert(normalStack.size() > 0);
return normalStack.top();
}
int getMin()
{
assert(normalStack.size() > 0);
return minStack.top();
}
}; 有效的括号
给定一个只包括 '(',')','{','}','[',']' 的字符串,判断字符串是否有效。
有效字符串需满足:
- 左括号必须用相同类型的右括号闭合。
- 左括号必须以正确的顺序闭合。
注意空字符串可被认为是有效字符串。
示例 1:
输入: "()"
输出: true示例 2:
输入: "()[]{}"
输出: true示例 3:
输入: "(]"
输出: false示例 4:
输入: "([)]"
输出: false示例 5:
输入: "{[]}"
输出: true#include
#include
#include
using namespace std;
// Using Stack
// Time Complexity: O(n)
// Space Complexity: O(n)
class Solution
{
public:
bool isValid(string s)
{
stack stack;
for (int i = 0; i < s.size(); i++)
if (s[i] == '(' || s[i] == '{' || s[i] == '[')
stack.push(s[i]);
else
{
if (stack.size() == 0)
return false;
char c = stack.top();
stack.pop();
char match;
if (s[i] == ')')
match = '(';
else if (s[i] == ']')
match = '[';
else
{
assert(s[i] == '}');
match = '{';
}
if (c != match)
return false;
}
if (stack.size() != 0)
return false;
return true;
}
};
void printBool(bool res){
cout << (res? "True" : "False") << endl;
}
int main() {
printBool(Solution().isValid("()"));
printBool(Solution().isValid("()[]{}"));
printBool(Solution().isValid("(]"));
printBool(Solution().isValid("([)]"));
return 0;
} 每日温度
根据每日 气温 列表,请重新生成一个列表,对应位置的输入是你需要再等待多久温度才会升高的天数。如果之后都不会升高,请输入 0 来代替。
例如,给定一个列表 temperatures = [73, 74, 75, 71, 69, 72, 76, 73],你的输出应该是 [1, 1, 4, 2, 1, 1, 0, 0]。
提示:气温 列表长度的范围是 [1, 30000]。每个气温的值的都是 [30, 100] 范围内的整数。
思路:从后往前遍历每个节点,用一个栈stack来存放值比自身大 且 离自己最近的节点下标
/// Source : https://leetcode.com/problems/daily-temperatures/description/
/// Author : liuyubobobo
/// Time : 2018-08-28
#include
#include
#include
using namespace std;
/// Using Stack
/// Time Complexity: O(n)
/// Space Complexity: O(n)
class Solution {
public:
vector dailyTemperatures(vector& temperatures) {
vector res(temperatures.size(), 0);
stack stack;
for(int i = temperatures.size() - 1; i >= 0 ; i --){
while(!stack.empty() && temperatures[stack.top()] <= temperatures[i])
stack.pop();
if(!stack.empty())
res[i] = stack.top() - i;
stack.push(i);
}
return res;
}
};
void printVec(const vector& vec){
for(int e: vec)
cout << e << " ";
cout << endl;
}
int main() {
vector vec = {73, 74, 75, 71, 69, 72, 76, 73};
printVec(Solution().dailyTemperatures(vec));
// 1 1 4 2 1 1 0 0
return 0;
} 逆波兰表达式求值
根据逆波兰表示法,求表达式的值。
有效的运算符包括 +, -, *, / 。每个运算对象可以是整数,也可以是另一个逆波兰表达式。
说明:
- 整数除法只保留整数部分。
- 给定逆波兰表达式总是有效的。换句话说,表达式总会得出有效数值且不存在除数为 0 的情况。
示例 1:
输入: ["2", "1", "+", "3", "*"]
输出: 9
解释: ((2 + 1) * 3) = 9示例 2:
输入: ["4", "13", "5", "/", "+"]
输出: 6
解释: (4 + (13 / 5)) = 6示例 3:
输入: ["10", "6", "9", "3", "+", "-11", "*", "/", "*", "17", "+", "5", "+"]
输出: 22
解释:
((10 * (6 / ((9 + 3) * -11))) + 17) + 5
= ((10 * (6 / (12 * -11))) + 17) + 5
= ((10 * (6 / -132)) + 17) + 5
= ((10 * 0) + 17) + 5
= (0 + 17) + 5
= 17 + 5
= 22#include
#include
#include
using namespace std;
/// Two stacks
/// Time Complexity: O(n)
/// Space Complexity: O(n)
class Solution
{
public:
int evalRPN(vector &tokens)
{
stack nums;
stack ops;
for(const string& s: tokens){
if(s == "+" || s=="-" || s=="*" || s=="/"){
int a = nums.top();
nums.pop();
int b = nums.top();
nums.pop();
if(s == "+")
nums.push(b + a);
else if(s == "-")
nums.push(b- a);
else if(s=="*")
nums.push(b*a);
else if(s=="/")
nums.push(b/a);
}
else
nums.push(atoi(s.c_str()));
}
return nums.top();
}
};
int main(){
return 0;
} 栈和深度优先搜索
栈和DFS
与 BFS 类似,深度优先搜索(DFS)也可用于查找从根结点到目标结点的路径。在本文中,我们提供了示例来解释 DFS 是如何工作的以及栈是如何逐步帮助 DFS 工作的。
示例
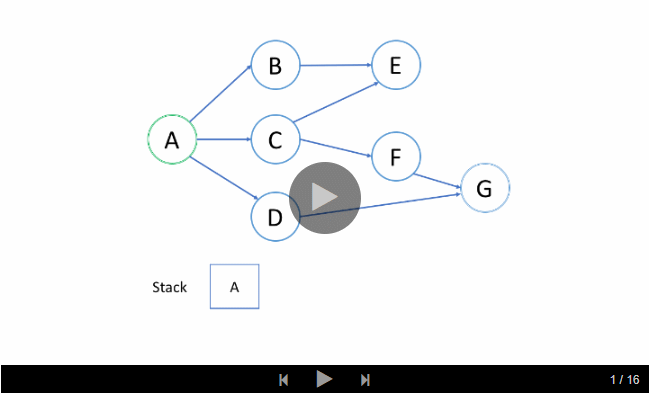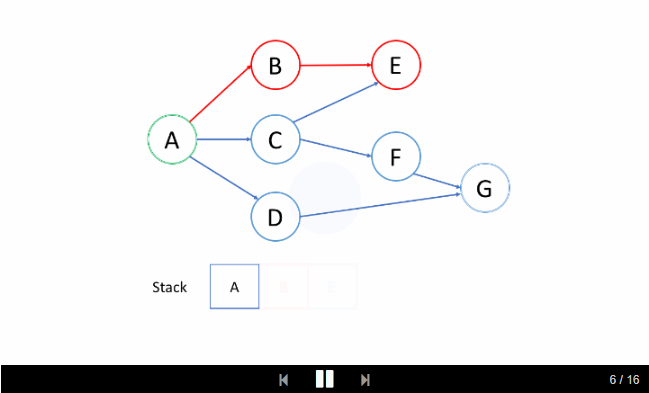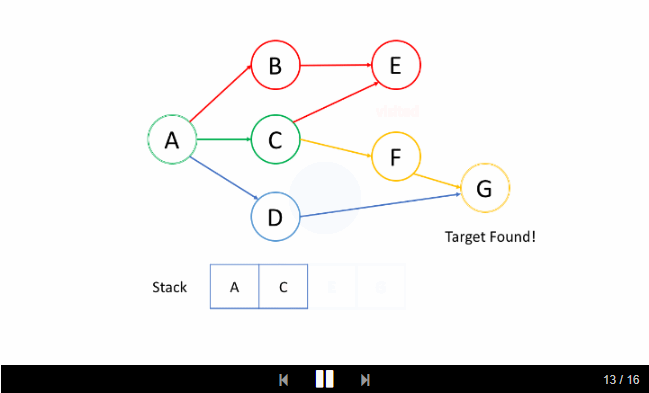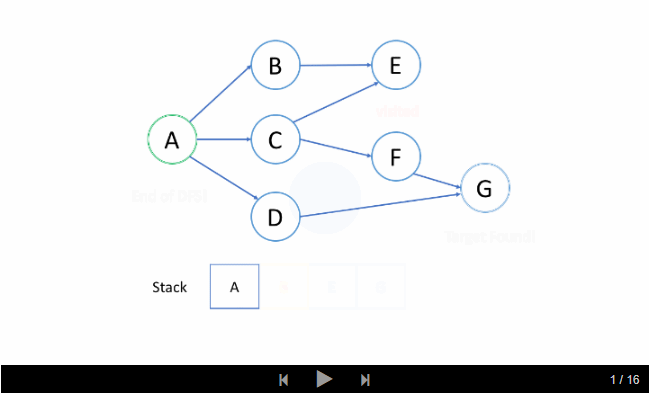
我们来看一个例子吧。我们希望通过 DFS 找出从根结点 A 到目标结点 G 的路径。
洞悉
观看上面的动画后,让我们回答以下问题:
1. 结点的处理顺序是什么?
在上面的例子中,我们从根结点 A 开始。首先,我们选择结点 B 的路径,并进行回溯,直到我们到达结点 E,我们无法更进一步深入。然后我们回溯到 A 并选择第二条路径到结点 C 。从 C 开始,我们尝试第一条路径到 E但是 E 已被访问过。所以我们回到 C 并尝试从另一条路径到 F。最后,我们找到了 G。
总的来说,在我们到达最深的结点之后,我们只会回溯并尝试另一条路径。
因此,你在 DFS 中找到的第一条路径并不总是最短的路径。例如,在上面的例子中,我们成功找出了路径
A-> C-> F-> G并停止了 DFS。但这不是从A到G的最短路径。
2. 栈的入栈和退栈顺序是什么?
如上面的动画所示,我们首先将根结点推入到栈中;然后我们尝试第一个邻居 B 并将结点 B 推入到栈中;等等等等。当我们到达最深的结点 E 时,我们需要回溯。当我们回溯时,我们将从栈中弹出最深的结点,这实际上是推入到栈中的最后一个结点。
结点的处理顺序是完全相反的顺序,就像它们被添加到栈中一样,它是后进先出(LIFO)。这就是我们在 DFS 中使用栈的原因。
DFS - 模板I
正如我们在本章的描述中提到的,在大多数情况下,我们在能使用 BFS 时也可以使用 DFS。但是有一个重要的区别:遍历顺序。
与 BFS 不同,更早访问的结点可能不是更靠近根结点的结点。因此,你在 DFS 中找到的第一条路径可能不是最短路径。
在本文中,我们将为你提供一个 DFS 的递归模板,并向你展示栈是如何帮助这个过程的。在这篇文章之后,我们会提供一些练习给大家练习。
模板-递归
有两种实现 DFS 的方法。第一种方法是进行递归,这一点你可能已经很熟悉了。这里我们提供了一个模板作为参考:
/*
* Return true if there is a path from cur to target.
*/
boolean DFS(Node cur, Node target, Set visited) {
return true if cur is target;
for (next : each neighbor of cur) {
if (next is not in visited) {
add next to visted;
return true if DFS(next, target, visited) == true;
}
}
return false;
} 示例
让我们看一个例子。我们希望在下图中找到结点 0 和结点 3 之间的路径。我们还会在每次调用期间显示栈的状态。
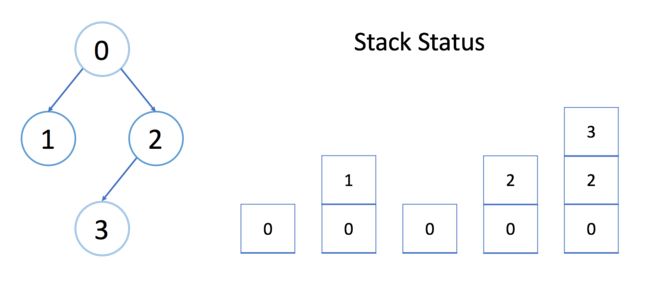
在每个堆栈元素中,都有一个整数 cur,一个整数 target,一个对访问过的数组的引用和一个对数组边界的引用,这些正是我们在 DFS 函数中的参数。我们只在上面的栈中显示 cur。
每个元素都需要固定的空间。栈的大小正好是 DFS 的深度。因此,在最坏的情况下,维护系统栈需要 O(h),其中 h 是 DFS 的最大深度。在计算空间复杂度时,永远不要忘记考虑系统栈。
在上面的模板中,我们在找到
第一条路径时停止。如果你想找到
最短路径呢?提示:再添加一个参数来指示你已经找到的最短路径。
岛屿数量
给定一个由 '1'(陆地)和 '0'(水)组成的的二维网格,计算岛屿的数量。一个岛被水包围,并且它是通过水平方向或垂直方向上相邻的陆地连接而成的。你可以假设网格的四个边均被水包围。
示例 1:
输入:
11110
11010
11000
00000
输出: 1示例 2:
输入:
11000
11000
00100
00011
输出: 3#include
#include
#include
using namespace std;
/// Floodfill - DFS
/// Recursion implementation
///
/// Time Complexity: O(n*m)
/// Space Complexity: O(n*m)
class Solution
{
private:
int d[4][2] = {{0, 1}, {1, 0}, {0, -1}, {-1, 0}};
int m, n;
vector> visited;
bool inArea(int x, int y)
{
return x >= 0 && x < m && y >= 0 && y < n;
}
void dfs(vector> &grid, int x, int y)
{
visited[x][y] = true;
for (int i = 0; i < 4; i++)
{
int newx = x + d[i][0];
int newy = y + d[i][1];
if (inArea(newx, newy) && !visited[newx][newy] && grid[newx][newy] == '1')
dfs(grid, newx, newy);
}
return ;
}
public:
int numIslands(vector>& grid){
m = grid.size();
if(m == 0)
return 0;
n = grid[0].size();
if(n == 0)
return 0;
for(int i=0; i(n, false));
int res = 0;
for(int i=0; i> grid1;
for(int i = 0 ; i < 4 ; i ++)
grid1.push_back( vector(g1[i], g1[i] + sizeof( g1[i])/sizeof(char)));
cout << Solution().numIslands(grid1) << endl;
// 1
// ---
char g2[4][5] = {
{'1','1','0','0','0'},
{'1','1','0','0','0'},
{'0','0','1','0','0'},
{'0','0','0','1','1'}
};
vector> grid2;
for(int i = 0 ; i < 4 ; i ++)
grid2.push_back(vector(g2[i], g2[i] + sizeof( g2[i])/sizeof(char)));
cout << Solution().numIslands(grid2) << endl;
// 2
return 0;
} 克隆图
给定无向连通图中一个节点的引用,返回该图的深拷贝(克隆)。图中的每个节点都包含它的值 val(Int) 和其邻居的列表(list[Node])。
示例:
输入:
{"$id":"1","neighbors":[{"$id":"2","neighbors":[{"$ref":"1"},{"$id":"3","neighbors":[{"$ref":"2"},{"$id":"4","neighbors":[{"$ref":"3"},{"$ref":"1"}],"val":4}],"val":3}],"val":2},{"$ref":"4"}],"val":1}
解释:
节点 1 的值是 1,它有两个邻居:节点 2 和 4 。
节点 2 的值是 2,它有两个邻居:节点 1 和 3 。
节点 3 的值是 3,它有两个邻居:节点 2 和 4 。
节点 4 的值是 4,它有两个邻居:节点 1 和 3 。提示:
- 节点数介于 1 到 100 之间。
- 无向图是一个简单图,这意味着图中没有重复的边,也没有自环。
- 由于图是无向的,如果节点 p 是节点 q 的邻居,那么节点 q 也必须是节点 p 的邻居。
- 必须将给定节点的拷贝作为对克隆图的引用返回。
#include
#include
#include
using namespace std;
struct UndirectedGraphNode
{
int label;
vector neighbors;
UndirectedGraphNode(int x) : label(x){};
};
/// DFS
/// Time Complexity: O(V+E)
/// Space Complexity: O(V)
class Solution
{
public:
UndirectedGraphNode *cloneGraph(UndirectedGraphNode *node)
{
if (node == NULL)
return NULL;
unordered_map nodeMap;
return dfs(node, nodeMap);
}
private:
UndirectedGraphNode *dfs(UndirectedGraphNode *node,
unordered_map &nodeMap)
{
if (nodeMap.count(node))
return nodeMap[node];
nodeMap[node] = new UndirectedGraphNode(node->label);
for (UndirectedGraphNode *next : node->neighbors)
nodeMap[node]->neighbors.push_back(dfs(next, nodeMap));
return nodeMap[node];
}
}; 目标和
给定一个非负整数数组,a1, a2, ..., an, 和一个目标数,S。现在你有两个符号 + 和 -。对于数组中的任意一个整数,你都可以从 + 或 -中选择一个符号添加在前面。
返回可以使最终数组和为目标数 S 的所有添加符号的方法数。
示例 1:
输入: nums: [1, 1, 1, 1, 1], S: 3
输出: 5
解释:
-1+1+1+1+1 = 3
+1-1+1+1+1 = 3
+1+1-1+1+1 = 3
+1+1+1-1+1 = 3
+1+1+1+1-1 = 3
一共有5种方法让最终目标和为3。注意:
- 数组的长度不会超过20,并且数组中的值全为正数。
- 初始的数组的和不会超过1000。
- 保证返回的最终结果为32位整数。
#include
#include
#include
using namespace std;
/// Backtracking
/// Time Complexity: O(2^n)
/// Space Complexity: O(n)
class SolutionA
{
public:
int findTargetSumWays(vector &nums, int S)
{
return dfs(nums, 0, 0, S);
}
private:
int dfs(const vector& nums, int index, int res, int S){
if(index == nums.size())
return res==S;
int ret = 0;
ret += dfs(nums, index+1, res-nums[index], S);
ret += dfs(nums, index+1, res+nums[index],S);
return ret;
}
};
/// Backtracking
/// Using Stack - Non-recursion solution
///
/// Time Complexity: O(2^n)
/// Space Complexity: O(2^n)
class SolutionB
{
public:
int findTargetSumWays(vector &nums, int S)
{
stack indexStack, sumStack;
indexStack.push(0);
sumStack.push(0);
int res = 0, index, sum;
while (!indexStack.empty())
{
index = indexStack.top();
sum = sumStack.top();
indexStack.pop();
sumStack.pop();
if (index + 1 == nums.size())
res += (sum + nums[index] == S) + (sum - nums[index] == S);
else
{
indexStack.push(index + 1);
sumStack.push(sum + nums[index]);
indexStack.push(index + 1);
sumStack.push(sum - nums[index]);
}
}
return res;
}
};
int main()
{
vector nums = {18, 1};
cout << SolutionA().findTargetSumWays(nums, 3) << endl;
return 0;
} DFS - 模板II
递归解决方案的优点是它更容易实现。 但是,存在一个很大的缺点:如果递归的深度太高,你将遭受堆栈溢出。 在这种情况下,您可能会希望使用 BFS,或使用显式栈实现 DFS。
这里我们提供了一个使用显式栈的模板:
/*
* Return true if there is a path from cur to target.
*/
boolean DFS(int root, int target) {
Set visited;
Stack s;
add root to s;
while (s is not empty) {
Node cur = the top element in s;
return true if cur is target;
for (Node next : the neighbors of cur) {
if (next is not in visited) {
add next to s;
add next to visited;
}
}
remove cur from s;
}
return false;
} 该逻辑与递归解决方案完全相同。 但我们使用 while 循环和栈来模拟递归期间的系统调用栈。 手动运行几个示例肯定会帮助你更好地理解它。
二叉树的中序遍历
给定一个二叉树,返回它的中序 遍历。
示例:
输入: [1,null,2,3]
1
\
2
/
3
输出: [1,3,2]进阶: 递归算法很简单,你可以通过迭代算法完成吗?
#include
#include
#include
using namespace std;
struct TreeNode{
int val;
TreeNode* left;
TreeNode* right;
TreeNode(int x):val(x), left(NULL), right(NULL){}
};
// Recursive
// Time Complexity: O(n), n is the node number in the tree
// Space Complexity: O(h), h is the height of the tree
class SolutionA{
public:
vector inorderTraversal(TreeNode* root){
vector res;
__inorderTraversal(root, res);
return res;
}
private:
void __inorderTraversal(TreeNode* node, vector & res){
if(node){
__inorderTraversal(node->left, res);
res.push_back(node->val);
__inorderTraversal(node->right, res);
}
}
};
// Classic Non-Recursive algorithm for inorder traversal
// Time Complexity: O(n), n is the node number in the tree
// Space Complexity: O(h), h is the height of the tree
class SolutionB{
public:
vector inorderTraversal(TreeNode* root){
vector res;
if(root == NULL)
return res;
stack stack;
TreeNode* cur = root;
while(cur != NULL || !stack.empty()){
while(cur != NULL){
stack.push(cur);
cur = cur->left;
}
cur = stack.top();
stack.pop();
res.push_back(cur->val);
cur = cur->right;
}
return res;
}
};
int main(){
return 0;
} 小结
用栈实现队列
使用栈实现队列的下列操作:
- push(x) -- 将一个元素放入队列的尾部。
- pop() -- 从队列首部移除元素。
- peek() -- 返回队列首部的元素。
- empty() -- 返回队列是否为空。
示例:
MyQueue queue = new MyQueue();
queue.push(1);
queue.push(2);
queue.peek(); // 返回 1
queue.pop(); // 返回 1
queue.empty(); // 返回 false说明:
- 你只能使用标准的栈操作 -- 也就是只有
push to top,peek/pop from top,size, 和is empty操作是合法的。 - 你所使用的语言也许不支持栈。你可以使用 list 或者 deque(双端队列)来模拟一个栈,只要是标准的栈操作即可。
- 假设所有操作都是有效的 (例如,一个空的队列不会调用 pop 或者 peek 操作)。
用队列实现栈
使用队列实现栈的下列操作:
- push(x) -- 元素 x 入栈
- pop() -- 移除栈顶元素
- top() -- 获取栈顶元素
- empty() -- 返回栈是否为空
注意:
- 你只能使用队列的基本操作-- 也就是
push to back,peek/pop from front,size, 和is empty这些操作是合法的。 - 你所使用的语言也许不支持队列。 你可以使用 list 或者 deque(双端队列)来模拟一个队列 , 只要是标准的队列操作即可。
- 你可以假设所有操作都是有效的(例如, 对一个空的栈不会调用 pop 或者 top 操作)。
#include
#include
#include
using namespace std;
/// Naive Implementation
/// Time Complexity: init: O(1)
/// push: O(1)
/// pop: O(n)
/// top: O(n)
/// empty: O(1)
/// Space Complexity: O(n)
class MyStack{
private:
queue q;
public:
MyStack(){}
void push(int x){
q.push(x);
}
int pop(){
assert(!empty());
queue q2;
while(q.size() > 1){
q2.push(q.front());
q.pop();
}
int ret = q.front();
q.pop();
while(!q2.empty()){
q.push(q2.front());
q2.pop();
}
return ret;
}
int top(){
assert(!empty());
queue q2;
while(q.size() > 1){
q2.push(q.front());
q.pop();
}
int ret = q.front();
q2.push(ret);
q.pop();
while(!q2.empty()){
q.push(q2.front());
q2.pop();
}
return ret;
}
bool empty(){
return q.empty();
}
}; 字符串解码
给定一个经过编码的字符串,返回它解码后的字符串。
编码规则为: k[encoded_string],表示其中方括号内部的 encoded_string 正好重复 k 次。注意 k 保证为正整数。
你可以认为输入字符串总是有效的;输入字符串中没有额外的空格,且输入的方括号总是符合格式要求的。
此外,你可以认为原始数据不包含数字,所有的数字只表示重复的次数 k ,例如不会出现像 3a 或 2[4] 的输入。
示例:
s = "3[a]2[bc]", 返回 "aaabcbc".
s = "3[a2[c]]", 返回 "accaccacc".
s = "2[abc]3[cd]ef", 返回 "abcabccdcdcdef".#include
#include
#include
using namespace std;
/// Using Stack - non recursion algorithm
/// Time Complexity: O(n)
/// Space Complexity: O(n)
class Solution
{
public:
string decodeString(string s)
{
vector stack;
vector nums;
stack.push_back("");
for (int i = 0; i < s.size();)
if (isalpha(s[i]))
stack.back() += s[i++];
else if (isdigit(s[i]))
{
int j;
for (j = i + 1; j < s.size() && isdigit(s[j]); j++)
;
nums.push_back(atoi(s.substr(i, j - i).c_str()));
stack.push_back("");
assert(s[j] == '[');
i = j + 1;
}
else
{
assert(s[i] == ']');
string tres = stack.back();
stack.pop_back();
int num = nums.back();
nums.pop_back();
while (num--)
stack.back() += tres;
i++;
}
return stack.back();
}
};
int main()
{
string s1 = "3[a]2[bc]";
cout << Solution().decodeString(s1) << endl;
// "aaabcbc"
string s2 = "3[a2[c]]";
cout << Solution().decodeString(s2) << endl;
// "accaccacc"
string s3 = "2[abc]3[cd]ef";
cout << Solution().decodeString(s3) << endl;
// "abcabccdcdcdef"
return 0;
} 图像渲染
有一幅以二维整数数组表示的图画,每一个整数表示该图画的像素值大小,数值在 0 到 65535 之间。
给你一个坐标 (sr, sc) 表示图像渲染开始的像素值(行 ,列)和一个新的颜色值 newColor,让你重新上色这幅图像。
为了完成上色工作,从初始坐标开始,记录初始坐标的上下左右四个方向上像素值与初始坐标相同的相连像素点,接着再记录这四个方向上符合条件的像素点与他们对应四个方向上像素值与初始坐标相同的相连像素点,……,重复该过程。将所有有记录的像素点的颜色值改为新的颜色值。
最后返回经过上色渲染后的图像。
示例 1:
输入:
image = [[1,1,1],[1,1,0],[1,0,1]]
sr = 1, sc = 1, newColor = 2
输出: [[2,2,2],[2,2,0],[2,0,1]]
解析:
在图像的正中间,(坐标(sr,sc)=(1,1)),
在路径上所有符合条件的像素点的颜色都被更改成2。
注意,右下角的像素没有更改为2,
因为它不是在上下左右四个方向上与初始点相连的像素点。注意:
image和image[0]的长度在范围[1, 50]内。- 给出的初始点将满足
0 <= sr < image.length和0 <= sc < image[0].length。 image[i][j]和newColor表示的颜色值在范围[0, 65535]内。
#include
#include
#include
using namespace std;
/// DFS - Using Stack
///
/// Time Complexity: O(n*m)
/// Space Complexity: O(n*m)
class Solution
{
private:
int d[4][2] = {{1, 0}, {-1, 0}, {0, 1}, {0, -1}};
int n, m;
public:
vector> floodFill(vector> &image,
int sr, int sc, int newColor)
{
n = image.size();
m = image[0].size();
int oldColor = image[sr][sc];
vector> visited(n, vector(m, false));
stack> stack;
stack.push(make_pair(sr, sc));
visited[sr][sc] = true;
while (!stack.empty())
{
int x = stack.top().first, y = stack.top().second;
stack.pop();
image[x][y] = newColor;
for (int i = 0; i < 4; i++)
{
int newX = x + d[i][0], newY = y + d[i][1];
if (inArea(newX, newY) && !visited[newX][newY] && image[newX][newY] == oldColor)
{
visited[newX][newY] = true;
stack.push(make_pair(newX, newY));
}
}
}
return image;
}
private:
bool inArea(int x, int y)
{
return x >= 0 && x < n && y >= 0 && y < m;
}
};
void printImage(const vector> & image){
for(vector row:image){
for(int pixel: row)
cout << pixel<<"\t";
cout << endl;
}
}
int main(){
vector> image = {{1,1,1}, {1,1,0}, {1,0,1}};
printImage(Solution().floodFill(image, 1, 1, 2));
return 0;
} 01矩阵
给定一个由 0 和 1 组成的矩阵,找出每个元素到最近的 0 的距离。
两个相邻元素间的距离为 1 。
示例 1:
输入:
0 0 0
0 1 0
0 0 0输出:
0 0 0
0 1 0
0 0 0示例 2:
输入:
0 0 0
0 1 0
1 1 1输出:
0 0 0
0 1 0
1 2 1注意:
- 给定矩阵的元素个数不超过 10000。
- 给定矩阵中至少有一个元素是 0。
- 矩阵中的元素只在四个方向上相邻: 上、下、左、右。
#include
#include
#include
#include
using namespace std;
/// BFS
/// Put all zero position in queue and only make one pass BFS :-)
///
/// Time Complexity: O(m*n)
/// Space Complexity: O(m*n)
class Solution
{
private:
const int d[4][2] = {{0, 1}, {0, -1}, {1, 0}, {-1, 0}};
int m, n;
public:
vector> updateMatrix(vector> &matrix)
{
if (matrix.size() == 0 || matrix[0].size() == 0)
return matrix;
m = matrix.size();
n = matrix[0].size();
queue q;
vector> res(m, vector(n, INT_MAX));
for (int i = 0; i < m; i++)
for (int j = 0; j < n; j++)
if (matrix[i][j] == 0)
{
res[i][j] = 0;
q.push(i * n + j);
}
bfs(matrix, q, res);
return res;
}
void bfs(const vector> &matrix, queue &q,
vector> &res)
{
while (!q.empty())
{
int x = q.front() / n;
int y = q.front() % n;
q.pop();
for (int k = 0; k < 4; k++)
{
int newX = x + d[k][0], newY = y + d[k][1];
if (inArea(newX, newY) && res[x][y] + 1 < res[newX][newY])
{
res[newX][newY] = res[x][y] + 1;
q.push(newX * n + newY);
}
}
}
}
bool inArea(int x, int y)
{
return x >= 0 && x < m && y >= 0 && y < n;
}
}; 钥匙和房间
有 N 个房间,开始时你位于 0 号房间。每个房间有不同的号码:0,1,2,...,N-1,并且房间里可能有一些钥匙能使你进入下一个房间。
在形式上,对于每个房间 i 都有一个钥匙列表 rooms[i],每个钥匙 rooms[i][j] 由 [0,1,...,N-1] 中的一个整数表示,其中 N = rooms.length。 钥匙 rooms[i][j] = v 可以打开编号为 v 的房间。
最初,除 0 号房间外的其余所有房间都被锁住。
你可以自由地在房间之间来回走动。
如果能进入每个房间返回 true,否则返回 false。
示例 1:
输入: [[1],[2],[3],[]]
输出: true
解释:
我们从 0 号房间开始,拿到钥匙 1。
之后我们去 1 号房间,拿到钥匙 2。
然后我们去 2 号房间,拿到钥匙 3。
最后我们去了 3 号房间。
由于我们能够进入每个房间,我们返回 true。示例 2:
输入:[[1,3],[3,0,1],[2],[0]]
输出:false
解释:我们不能进入 2 号房间。提示:
1 <= rooms.length <= 10000 <= rooms[i].length <= 1000- 所有房间中的钥匙数量总计不超过
3000。
class Solution{
public:
bool canVisitAllRooms(vector>& rooms){
int V = rooms.size();
vector visited(V, false);
return dfs(rooms, 0, visited) == V;
}
private:
int dfs(const vector>& rooms, int v, vector& visited){
visited[v] = true;
int res = 1;
for(int next: rooms[v])
if(!visited[next])
res += dfs(rooms, next, visited);
return res;
}
};