基于Huffman和LZ77压缩(三)LZ77思路分析
Huffman压缩详细分析
LZ77: 基于重复语句的压缩
1 什么是LZ77
1977年两个以色列人提出的基于重复语句上的通用的压缩算法--------将重复语句替换成更短的<长度, 距离, 下个字符串首字母>对的方式。 真正的LZ77用的是一个三元组(长度距离对 + 下一个语句的首字母 )

为什么叫基LZ77算法的压缩?
上边介绍了 原LZ77 的处理方式:
<长度, 距离, 下个字符串首字母> 三字节
我们发现:下个字符串的首字母对压缩目的来说没什么帮助,放大看却占了很多空间,因此 我们采用<长度, 距离>的方式
长度距离对 我们仍采用三个字节
长度 :1字节表示
距离 :2字节表示
实现思想:
要压缩文件,必然需要将待压缩文件读到程序的缓冲区中,因此我们需要在程序中维护一段缓冲区
LZ77 :缓冲区的大小 :64K
那么我们也用64K
我们将缓冲区等分为两部分:
查找缓冲区32K:
1 存放已经压缩完成的数据,
2 待压缩的数据中的每个字符串(语句)需要在该区域中找是否重复
3 随着压缩的不断进行,查找缓冲区不断增大
先行缓冲区32K:
1 存放待压缩的数据
2 每次取出一个字符串(语句)去查找缓冲区中匹配
3 随着压缩的不断进行,先行缓冲区的大小不断变小
压缩核心是将重复语句替换为长度距离对:
那么重复字符串的长度为几的时候进行长度距离对的替换?
1 确定长度:
用1字节表示
首先 :匹配字符串的长度我们用一个字节存储:范围【0,255】
为什么用一个字节存储:
1: 一个字节能表示的最大长度已经比较大了,
2: 用更长的长度来存储时对压缩率有一定影响,因为匹配串的距离大部分小于255。
2 确定距离
怎么确定距离:
距离是先行缓冲区离查找缓冲区的最远距离
线性缓冲区:32K 查找缓冲区:32K
那么极端距离为64K —> 2^16
所以2字节就能表示
1 确定距离受缓冲区的影响:
查找缓冲区越大,能查找到匹配的概率越大,但匹配查找的时间代价也增大了真正查找长度不会超过32K
2。距离再过远 ,存储长度就得用更多的字节,又浪费了压缩空间。
所以真正查找匹配的范围不会超过32K(一半长度)==>2^3 * K —>2^15 那么我们用两个字节来进行保存长度(2^16)
确定压缩条件
长度为1个字节的语句 : 不压缩
长度为2个字节的语句 : 没必要(长度距离对是3个字节,那么肯定不划算)
所以 :
长度 >=3 时开始匹配替换:
Min_Match_Len =3;
Max_Match_Len =258 (利用了0 ,1,2 用不到的空间)
技术才是硬道理
问题1:如何快速查找匹配?
(查找匹配的时间严重影响压缩时间)
暴力匹配太慢
我们用哈希的思想
哈希 :
首先需要一个哈希表,每次是3个字符进行存储,哈希表中将来保存的是从查找缓冲区中取到的三个字符中首字符 在查找缓冲区中的下标

问题2 :你可能会想,想要匹配必须先构建哈希彪表 , 构建哈希表肯定得需要遍历一趟来存储哈希表中,这不是又影响了时间吗?
遇到凡事------不要慌~~~
我们让在哈希表中匹配位置和哈希表的构造进行同步进行就可以了。
什么意思呢?
边走边构造:哈希表中存0那就是该位置没保存,那么保存在该位置就行了,哈希表中存1的位置就是存在冲突了,冲突那我们一会再来解决冲突。
需要确定哈希函数
字符串哈希函数我们可以网上查一下
哈希表中匹配位置则需要确定哈希函数,该字符串哈希函数只起将字符串转为唯一整形数字的作用,我们可以网上查这个哈希函数
LZ77 哈希函数:
A(4,5) +b(6,7,8)^B(1,2,3) + B(4,5) + B(6,7,8)^C(1,2,3)+ C(4,5,6,7,8)
A B C 代表第一、二、三个位置
12345678 代表字符的比特位
+是连接起来的意思
^优先于+
由哈希函数可以确定 哈希地址最大有15个比特位。
举个栗子理思路:
:
1 从先行缓冲区中拿到一个字符串abc,
2 通过哈希函数计算在哈希表中的位置
3 到哈希表中取匹配字符串在查找缓冲区的位置
只要三个字符(字符串)相同,那么计算出的哈希地址一定相同,然后就相当于知道了查找缓冲区的位置,于是就可以确定一个长度距离对了
三个字符的组合数量256* 256* 256 ;
哈希表的大小,因为组合方式不一样,哈希函数计算结果必须一一映射
那这样的话?
哈希表必须有2^24个位置,
每个位置存储的是在64K窗口中的下标
64K窗口的下标范围 :【0,2^16】;
每个下标2个字节存储
那么就需要两个字节表示距离.2^24 * 2 ==>32M
**其实查了下资料,还真不是这样搞的。。。**
因为32M的哈希表太大,随着压缩的进行,哈希表中的内容要不断更新,更不好维护。
因此 实际LZ77算法哈希表中的位置个数给2^15 —>32K(其实之前的哈希函数可以推出来哈希地址的范围)
干货来了~
32K的哈希表表必然会存在哈希冲突,那么怎么解决冲突的?
实际缓冲区:64K=32K + 32K
开辟一个同样大的Prev作为处理哈希冲突的空间(32K)
1 为什么Prev和Head一样大?
因为当匹配暂停时,需要将右窗WSIZE数据导入到左窗中
2 什么时候匹配会暂停?
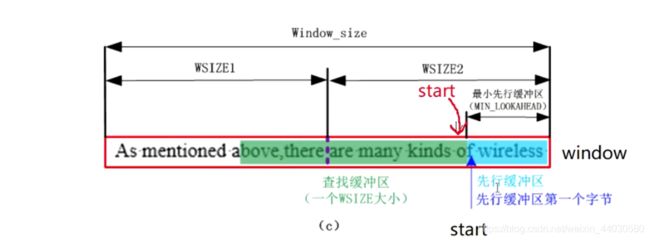
匹配暂停发生在线性缓冲区的末尾,当先行缓冲区中剩余的字符数量不足最大匹配长度时,我们认为这次匹配不够完全,因此暂不进行。
怎么做?
1 将先行缓冲区中的32K数据全部导入到查找缓冲区,相当于更新了查找缓冲区
2 从文件中接着读取32K(Wsize )的文件
那么继续从start位置(上次匹配串进行的位置)开始匹配查找
这样存在一个小误区 :你可能会认为这样查找缓冲区不足32K了,会不会出错?
答案是不会的!!
此时查找缓冲区的确是变小了,但倘若在此小区间找不到,那么久默认此串不存在重复,那么就把这个新字符串加入到哈希表中就行了,不用向更远的地方找,损失但性能也是微乎其微的,甚至是有益的!
为什么损失性能微乎其微甚至有益?
首先 查找缓冲区变小,那么查找的更快。
倘若向前接着找的话,也不一定能找到匹配串,这下你明白了吗?
暂时小结一下:
当前存在问题1: 32K的哈希表必然存在哈希冲突
**当前存在问题2:**对于长度大于64K的文件仍无法进行压缩
下一篇:我们来展开探究这两个问题,欢迎持续关注。
点我跳转下一篇