浅谈java集合(2020.7.17更新中)
目录
- java集合概述
- Collection和Iterator接口
- 集合的遍历方式
- 使用Iterator接口遍历集合元素
- 使用foreach遍历集合
- set接口
- HashSet
- LinkedHashSet
- TreeSet
- 自然排序
- 定制排序
参考自: 疯狂Java讲义
Java的集合类是一种特别有用的工具类,它可以用于存储数量不等的多个对象,并可以实现常用数据结构,如栈、队列等。除此之外,Java集合还可用于保存具有映射关系的关联数组。Java的集合大致上可分为: Set、List 和Map三种体系,其中Set代表无序、不可重复的集合; List 代表有序、重复的集合;而Map则代表具有映射关系的集合。从JDK1.5以后,Java 又增加了Queue体系集合,代表一种队列集合实现。
Java集合就像一种容器,我们可以把多个对象(实际上是对象的引用,但习惯上都称对象)“丢进”该容器中。在JDK1.5之前,Java 集合就会丢失容器中所有对象的数据类型,把所有对象都当成Object类型处理,从JDK1.5增加了泛型以后,Java 集合可以记住容器中对象的数据类型,从而可以编写更简洁、健壮的代码。本章不会介绍泛型的知识,本章重点介绍Java的四种集合体系的功能和用法。本章将详细介绍Java四种集合体系的常规功能,并深入介绍各集合实现类所提供的独特功能,并深入分析各实现类的实现机制,以及用法上的细微差别,并给出不同应用场景选择哪种集合实现类的建议。
java集合概述
在编程时,常常需要集中存放多个数据,例如前一章(疯狂java讲义第六章)习题中梭哈游戏里剩下的牌。当然我们可以使用数组来保存多个对象。但数组长度不可变化,一旦在初始化数组时指定了数组长度,则这个数组长度是不可变的,如果需要保存个数变化的数据,数组就有点无能为力了;而且数组无法保存具有映射关系的数据,如成绩表:语文-79,数学-80,这种数据看上去像两个数组,但这两个数组的元素之间有一定的关联关系。
为了保存数量不确定的数据,以及保存具有映射关系的数据(也被称为关联数组),Java 提供集合类。集合类主要负责保存、盛装其他数据,因此集合类也被称为容器类。所有集合类都位于java.util包下。
集合类和数组不一样,数组元素既可以是基本类型的值,也可以是对象(实际上保存的是对象的引用变量);而集合里只能保存对象(实际上也是保存对象的引用变量,但通常习惯上认为集合里保存的是对象),基本类型会自动装箱。
java的集合类主要由两个接口派生而出:Collection和Map,Collection和Map是java集合的根接口,这两个接口又包含了一些子接口或实现类。下图是继承体系:
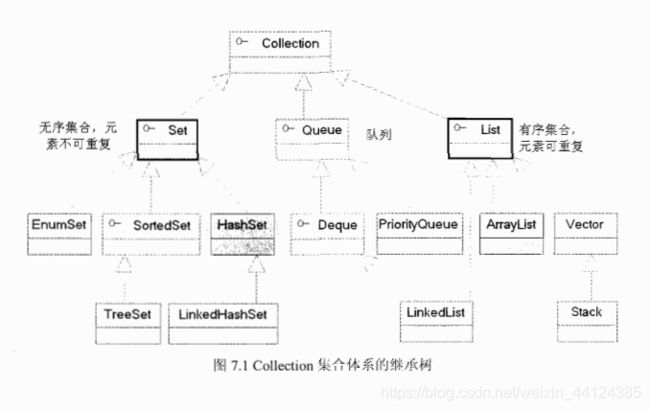
图7.1显示了Collection体系里的集合,图7.1中粗线圈出的Set和List接口是Collection接口派生的两个子接口,它们分别代表了无序集合和有序集合; Queue 是Java提供的队列实现,有点类似于List,后面章节还会有更详细的介绍,此处不再赘述。
图7.2是Map体系的继承树,所有的Map实现类用于保存具有映射关系的数据(也就是前面介绍的关联数组)。
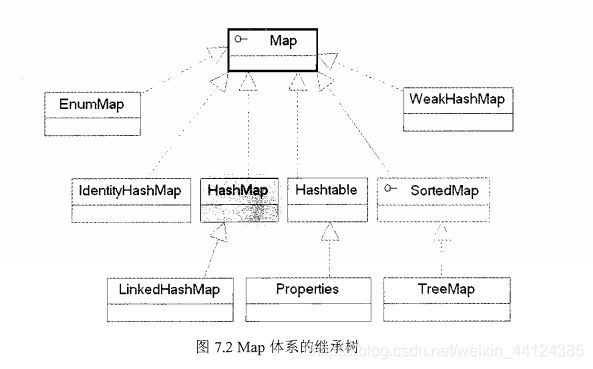
图7.2中显示了Map接口的众多实现类,这些实现类在功能、用法上存在一定的差异,但它们都有一个功能特征: Map保存的每项数据都是key-value对,也就是由key和value 两个值组成。就像前面介绍的成绩单:语文-79,数学-80,每项成绩都由2个值组成:科目名和成绩。对于一张成绩表而言,科目通常不会重复,而成绩是可重复的,通常习惯根据科目来查阅成绩,而不会根据成绩来查阅科目。Map也与此类似,Map里的key是不可重复的,key用于标识集合里每项数据,如果需要查阅Map中数据时,总是根据Map的key来获取。
根据图7.1和图7.2中粗线标识的3个接口,我们可以把Java的所有集合分成三大类,其中Set集合类似于一个罐子,把一个对象添加到Set 集合时,Set 集合无法记住添加这个元素的顺序,所以Set里的元素不能重复(否则系统无法准确识别这个元素); List 集合非常像一个数组,它可以记住每次添加元素的顺序,只是List 的长度可变。Map集合也像一个罐子,只是它里面的每项数据都由两个值组成。图7.3显示了这三种集合的示意图: .
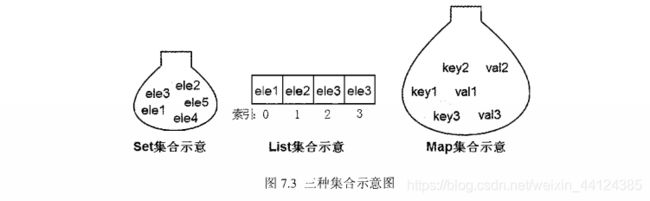
从图7.3中可以看出,如果访问List 集合中的元素,可以直接根据元素的索引来访问:如果需要访问Map集合中的元案,可以根据每项元素的key来访问其value;如果希望访问Set集合中的元素,则只能根据元素本身来访问(这也是Set集合里元素不允许重复的原因)。
对于Set、List和Map三种集合,最常用的实现类在图7.1.7.2中以灰色区域覆盖,分别是HashSet、ArrayList和HashMap三个实现类。
注: 本章主要讲解没有实现并发控制的集合类,对于JDK1.5新增的具有并发控制的集合类,本书将在第16章与多线程一起介绍。
Collection和Iterator接口
Collction接口是List、Set和Qucue接口的父接口,该接口里定义的方法既可用于操作Set集合,也可用于操作List和Queue集合。Collection 接口里定义了如下操作集合元素的方法:
➢boolean add(Object o):该方法用于向集合里添加一个元素。如果集合对象被添加操作改变
了则返回true。
➢boolean addll(Collection c):该方法把集合C里的所有元素添加到指定集合里。如果集合
对象被添加操作改变了则返回true。
➢void clear():清除集合里的所有元素,将集合长度变为0。
➢boolean contains(Object o):返回集合里是否包含指定元素。
➢boolean containsAll(Collection c);返回集合里是否包含集合C里的所有元素。
➢boolean isEmpty():返回集合是否为空。当集合长度为0时返回true,否则返回false.
➢Iterator iterator():返回一个Iterator 对象,用于遍历集合里的元素。
➢boolean remove(Object o);删除集合中指定元素o,当集合中包含了一个或多个元素o时,
这些元素将被删除,该方法将返回true.
➢boolean removeAll(Collection c):从集合中删除集合C里包含的所有元素(相当于用调用该
方法的集合减集合c),如果删除了一个或一个以上的元素,该方法返回true。
➢boolean retainAll(Collection c): 从集合中删除集合c里不包含的元素(相当于取得把调用该方法的集合变成该集合和集合c的交集),如果该操作改变了调用该方法的集合,该方法返回true。
➢int size():该方法返回集合里元素的个数(不是长度)。
➢Object[] toArray():该方法把集合转换成-一个数组,所有集合元素变成对应的数组元素。
上面这些方法完全来自于 JavaAPI文档,读者应该自行参考API文档来查阅这些方法的详细信息,此处列出这些方法仅仅作为快速参考清单。
下面程序将示范如何通过上面方法来操作Collection集合里的元素。
package array;
import java.util.ArrayList;
import java.util.Collection;
import java.util.HashSet;
public class TestCollection{
public static void main(String[] args){
Collection c = new ArrayList();
//添加元素
c. add ("孙悟空") ;
//虽然集合里不能放基本类型的值,但Java支持自动装箱
c.add(6);
System.out.println("c集合的元素个数为:"+ c.size());
//删除指定元素
c.remove(6);
System.out.println("c集合的元索个数为:"+ c.size()) ;
//判断是否包含指定字符串
System.out.println("c集合的是否包含孙悟空字符串:"+ c.contains("孙悟空"));
c.add("轻量级J2EE企业应用实战") ;
System.out.println("c集合的元素:"+ c);
Collection books = new HashSet();
books.add("轻量级J2EE企业应用实战") ;
books.add("Struts2权威指南") ;
System.out.println("c集合是否完全包含books集合? " + c.containsAll(books)) ;
//用c集合减去books集合里的元素
c.removeAll(books);
System.out.println("c集合的元素:"+ c);
//删除c集合里所有元素
c.clear() ;
System.out.println("c集合的元素:"+ c);
//books集合里只剩下c集合里也同时包含的元素
books.retainAll(c);
System.out.println("books集合的元素:" + books) ;
}
}
上面程序中 创建了两个Collection对象,一个是c集合,一个是books集合,其中c集合是ArrayList, 而books集合是HashSet, 虽然它们使用的实现类不同。当把它们当成Collection来使用时,使用add、remove、 clear等方法来操作集合元素时没有任何区别。
编译和运行上面程序,看到如下运行结果:
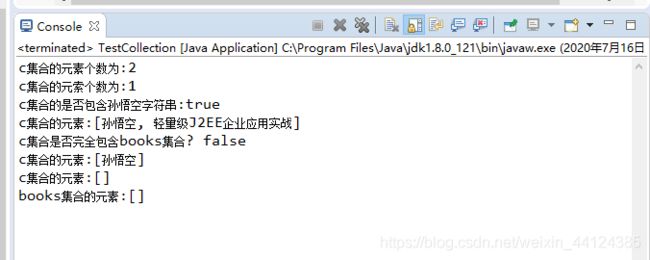
当使用System.ou的println方法来输出集合对象时,将输出[ele1,ele2… .]的形式,这显然是因为Collection的实现类重写了toString()方法,所有Collction 集合实现类都重写了toString()方法,该方法可以一次性地输出集合中的所有元素。
如果想依次访问集合里的每一个元素,则需要使用某种方式来遍历集合元素,下面介绍遍历集合元素的两种方法。
普通情况下,当我们把一个对象“丢进”集合中后,集合会忘记这个对象的类型一也就是说,系统把所有集合元素都当成Object类的实例进行处理。从JDKI.5以后,这种状态得到了改进:可以使用泛型来限制集合里元素的类型,并让集合记住所有集合元素的类型。关于泛型的介绍,请参考第8章介绍。或者我的另外一篇博客链接: 泛型小解.
集合的遍历方式
普遍分为 普通for循环、增强fore循环、迭代器(Iterator),但是像set、map之类的集合,不能使用普通for循环,set无序,没有提供get方法获取元素。map的话,集合是键值对形式存储值的,所以遍历Map集合无非就是获取键和值,根据实际需求,进行获取键和值。
使用Iterator接口遍历集合元素
Iterator接口也是Java集合框架的成员,但它与Collection系列、Map系列的集合不一样:Collection系列集合、Map 系列集合主要用于盛装其他对象,而Iterator则主要用于遍历(即迭代访问) Collection集合中的元素,Iterator对象也被称为迭代器。
Iterator接口隐藏了各种Collection实现类的底层细节,向应用程序提供了遍历Collection集合元素的统一编程接口,Iterator接口里定义了如下三个方法:
➢boolean hasNext():如果被迭代的集合元素还没有被遍历,则返回true.
➢Object next():返回集合里下一个元素。
➢void remove():删除集合里上一次next方法返回的元素。
下面程序示范了通过Iterator 来遍历集合的元素:
package array;
import java.util.Collection;
import java.util.HashSet;
import java.util.Iterator;
public class TestIterator {
public static void main(String[] args) {
//创建一个集合
Collection books = new HashSet();
books.add("轻量级J2EE企业应用实战");
books.add("Struts2权威指南");
books.add("基于J2EE的Ajax宝典");
//获取books集合对应的选代器
Iterator it = books.iterator();
while (it.hasNext()) {
//it. next ()方法返回的数据类型是object类型,需要强制类型转换
String book = (String) it.next();
System.out.println(book);
if (book.equals("Struts2权威指南")) {
//从集合中删除上一次next方法返回的元素
it.remove();
}
//对book变量赋值,不会改变集合元素本身
book = "测试字符串";//①
}
System.out.println(books);
}
}
从上面代码中可以看出: Iterator 仅用于遍历集合,Iterator 本身并不提供盛装对象的能力。如果需要创建Iterator对象,则必须有一个被迭代的集合。没有集合的Iterator仿佛无根之木,没有存在的价值。
Iterator必须依附于Collection对象。有一个
Iterator对象,则必然有一个与之关联的Collection对象。Iterator 提供了2个方法来迭代访问Collection 集合里的元素,并可通过remove方法来删除集合中上一次next方法返回的集合元素。
上面代码的①行代码对迭代变量book进行赋值,但当我们再次输出books集合时,看到集合里的元素没有任何改变。这就可以得到一一个结论:当使用lterator 对集合元素进行迭代时,Iterator 并不是把集合元素本身传给了迭代变量,而是把集合元素的值传给了迭代变量,所以修改迭代变量的值对集合元素本身没有任何改变。
解释: 这里用的是String类型,无论是包装类型定义的字符串String s=new String("123"),还是直接定义的String s="123",迭代得到的对象可以特殊理解为新建了一个对象, book = "测试字符串";//①只是变量指向改变了,所以原来的值并没有修改。而如果存的是一个对象,例如:
package array;
import java.util.Collection;
import java.util.HashSet;
import java.util.Iterator;
class Dog{
private String name;
private int age;
public Dog(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Dog{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
public class TestIterator {
public static void main(String[] args) {
//创建一个集合
Collection dogs = new HashSet();
dogs.add(new Dog("藏獒",18));
dogs.add(new Dog("狮子狗",18));
dogs.add(new Dog("二哈",18));
System.out.println(dogs);
System.out.println("----------------");
Iterator i = dogs.iterator();
while (i.hasNext()){
Dog d= (Dog) i.next();
if ("狮子狗".equals(d.getName())){
d.setAge(16);
}
}
System.out.println(dogs);
}
}
则可以改变其属性值,指向(地址值没有改变)
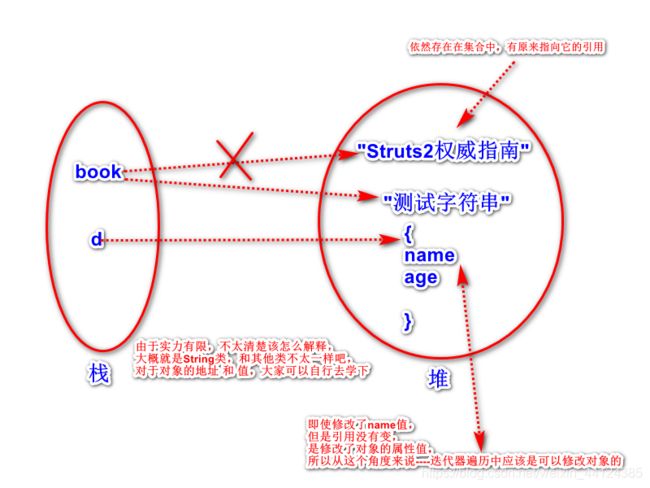
当使用Iterator 来迭代访问Collection 集合元素时,Collection 集合果的元素不能被改变,只有通过Iterator 的remove方法来删除上一次next 方法返回的集合元素才可以。否则将公引发java.util.ConcurrentModificationException异常。下 面程序示范了这点:
package array;
import java.util.Collection;
import java.util.HashSet;
import java.util.Iterator;
class Dog{
private String name;
private int age;
public Dog(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Dog{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
public class TestIterator {
public static void main(String[] args) {
//创建一个集合
Collection dogs = new HashSet();
dogs.add(new Dog("藏獒",18));
dogs.add(new Dog("狮子狗",18));
dogs.add(new Dog("二哈",18));
System.out.println(dogs);
System.out.println("----------------");
Iterator i = dogs.iterator();
while (i.hasNext()){
Dog d= (Dog) i.next();
if ("狮子狗".equals(d.getName())){
d.setAge(16);
}
// i.remove();可以通过这个方法删除
dogs.remove(d);①//报错:java.util.ConcurrentModificationException
}
System.out.println(dogs);
}
}
上面程序中①处的代码位于Iterator 迭代块内,也就是在Iterator迭代Collection 集合过程中修改了Collection 集合,所以程序将在运行时引发异常。
上面错误在多线程编程时尤其容易发生:程序的一条线程正在迭代访问Collection集合元素时,另一条线程修改了Collection 集合,这就会导致发生异常。
Iterator迭代器采用的是快速失败( fail-fast)机制,一旦在迭代过程中检测到该集合已经被修改(通常是程序中其他线程修改),程序立即引发ConcurrentModifcationException异常,而不是显示修改后的结果,这样可以避免共享资源而引发的潜在问题。
当然了,有个例外的情况,基本上可以忽略,看下面代码:
package array;
import java.util.Collection;
import java.util.HashSet;
import java.util.Iterator;
public class TestIterator {
public static void main(String[] args) {
//创建一个集合
Collection books = new HashSet();
books.add("轻量级J2EE企业应用实战");
books.add("Struts2权威指南");
// books.add("基于J2EE的Ajax宝典");
//获取books集合对应的选代器
System.out.println(books);
Iterator it = books.iterator();
while (it.hasNext()) {
//it. next ()方法返回的数据类型是object类型,需要强制类型转换
String book = (String) it.next();
System.out.println(book);
if (book.equals("轻量级J2EE企业应用实战")) {
//从集合中删除最后一个next方法返回的元素
books.remove(book); //结果是可以的 ,当然了 除非你能十分肯定知道它是最后一个元素,不然,删除其他的都会报错
}
//对book变量赋值,不会改变集合元素本身
book = "测试字符串";//①
}
System.out.println(books);
}
}
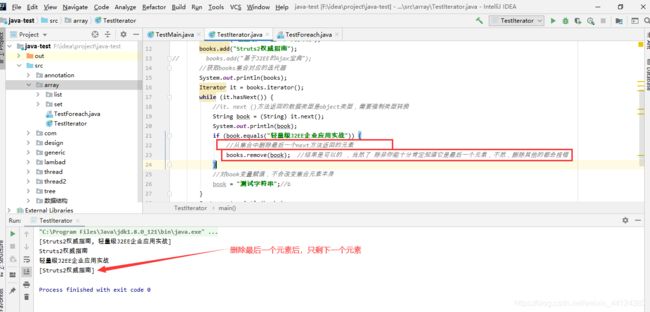
从上图运行结果可知,从集合中删除最后一个next方法返回的元素,结果是可以的 ,当然了,除非你能十分肯定知道它是最后一个元素,不然,删除其他的都会报错。读者如果有兴趣,可以去看下源码。水平有限,就暂时不解释了。
使用foreach遍历集合
除了可以使用Iterator接口迭代访问Collection集合里的元素之外,使用JDK1.5提供的foreach循环来迭代访问集合元素更加便捷,如下程序示范了使用foreach循环来迭代访问集合元素。
package array;
import java.util.Collection;
import java.util.HashSet;
import java.util.Iterator;
public class TestForeach {
public static void main(String[] args) {
//创建一个集合
//创建一个集合
Collection books = new HashSet();
books.add("轻量级J2EE企业应用实战");
books.add("Struts2权威指南");
books.add("基于J2EE的Ajax宝典");
System.out.println(books);
for (Object o : books) {
String b = (String) o;
// if ("Struts2权威指南".equals(b)) {
// System.out.println("删除失败");
// books.remove(b);
// }
if ("基于J2EE的Ajax宝典".equals(b)) {
System.out.println("删除最后一个对象成功" + b);
books.remove(b);
}
}
}
}
上面代码使用foreach 循环来迭代访问Collection集合的元素更加简洁,这正是JDK1.5的foreach循环带来的优势。与使用Iterator 迭代访问集合元素类似的是,foreach 循环中的迭代变量也不是集合元素本身,系统只是依次把集合元素的值赋给迭代变量,因此在foreach循环中修改迭代变量的值也没有任何实际意义。
同样,当使用foreach 循环迭代访问集合元素时,该集合也不能被改变,否则将引发ConcurrentModificationException异常,所以上面程序中`注释的代码处将引发该异常。
注释的代码会提示删除失败,java.util.ConcurrentModificationException异常,删除最后一个成功,刚才用Iterator一样。其实增强for循环也是通Iterator,可以看下编译后的文件,内容一模一样!
set接口
前面已经介绍过Set集合,它类似于一个罐子,一旦把对象“丢进”Set集合,集合里多个对象之间没有明显的顺序。Set 集合与Collection基本上完全一样,它没有提供任何额外的方法。实际上Set就是Collection,只是行为不同(Set 不允许包含重复元素)。
Set集合不允许包含相同的元素,如果试图把两个相同元素加入同一个Set集合中,则添加操作失败,add 方法返回false,且新元素不会被加入。
Set判断两个对象相同不是使用== 运算符,而是根据equals 方法。也就是说,如果只要两个对象用equals方法比较返回true, Set 就不会接受这两个对象;反之,只要两个对象用equals方法比较返回false,Set 就会接受这两个对象(甚至这两个对象是同一个对象,Set 也可把它们当成两个对象处理,后面程序可以看到这种极端的情况)。下面是使用普通Set的示例程序。
package array;
import java.util.HashSet;
import java.util.Set;
public class TestSet {
public static void main(String[] args) {
Set s=new HashSet();
s.add(new String("Struts2权威指南"));
//因为两个字符串对象通过equals方法比较相等,所以添加失败,返回false
boolean b = s.add(new String("Struts2权威指南"));
System.out.println(b);
//下面输出看到集合只有一个元素
System.out.println(s);
}
}
从上面程序中可以看出,books 集合两次添加的字符串对象明显不是同一个对象(因为两次都调用了new关键字来创建字符串对象),这两个字符串对象使用==运算符判断肯定返回false,但它们通过equals方法比较将返回true,所以添加失败。最后输出bocks集合时,将看到输出结果只有一个元素。
上面介绍的是Set集合的通用知识,因此完全适合后面介绍的HashSet、TreeSet 和EnumSet三个实现类,只是三个实现类还各有特色。
HashSet
HashSet是Set接口的典型实现,大多数时候使用Set集合时就是使用这个实现类。HashSet按Hash算法来存储集合中的元素,因此具有很好的存取和查找性能。
HashSet具有以下的特点:
➢不能保证元素的排列顺序,顺序有可能发生变化。
➢HashSet不是同步的,如果多个线程同时访问一个HashSet,如果有2条或者2条以上线程同时修改了HashSet集合时,必须通过代码来保证其同步。
➢集合元素值可以是null,也是唯一一个。
补充: null值是所有引用类型的默认值,可以强制转换为任一对象类型猜想:java中存在一个潜在的Null类概念,是所有引用类型的变量的子类,String a = (String)null;说明存在一个潜在Null.toString方法。
当向HashSet集合中存入一个元素时,HashSet 会调用该对象的hashCode()方法来得到该对象的hashCode值,然后根据该HashCode值来决定该对象在HashSet中存储位置。如果有两个元素通过equals方法比较返回true,但它们的hashCode()方法返回值不相等,HashSet 将会把它们存储在不同位置,也就可以添加成功。,
简单地说,HashSet 集合判断两个元素相等的标准是两个对象通过equals方法比较相等,并且两个对象的hashCode()方法返回值也相等。
关于==、equals和hashcode,可以参考这篇链接: 智造官.
下面程序分别提供了三个类A、B和C,它们分别重写了equals、 hashCode 两个方法的一个或全部,通过下面程序可以让读者看到HashSet判断集合元素相同的标准。
package array.set;
import com.fjl.Main;
import java.util.HashSet;
import java.util.Objects;
import java.util.Set;
//类A的equals方法总是返回true,但没有重写其hashCode ()方法
class A{
@Override
public boolean equals(Object o){
return true;
}
}
//类B的hashCode()方法总是返回1,但没有重写其equals()方法
class B{
String a;
public B(String a) {
this.a = a;
}
@Override
public int hashCode(){
return 1;
}
}
//类C的hashCode()方法总是返回2,且有重写其equals()方法
class C{
@Override
public boolean equals(Object o){
return true;
}
@Override
public int hashCode(){
return 2;
}
}
public class TestSet {
public static void main(String[] args) {
Set set=new HashSet<>();
A a1 = new A();
A a2 = new A();
B b1 = new B("123");
B b2 = new B("234");
C c1 = new C();
C c2 = new C();
set.add(a1);
set.add(a2);
set.add(b1);
set.add(b2);
set.add(c1);
set.add(c2);
System.out.println(set);
}
}
上面程序中set集合中分别添加了2个A对象、2个B对象和2个C对象,其中C类重写了equals()方法总是返回true、 hashCode()方法总是返回2,这将导致HashSet将会把2个C对象当成同一个对象。运行上面程序,看到如下运行结果: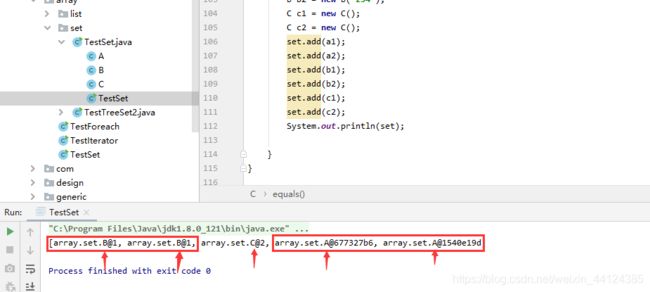
从上面程序可以看出,即使2个A对象通过equals比较返回true,但HashSet依然把它们当成2个对象;即使2个B对象的hashCode()返回相同值(都是1),但HashSet依然把它们当成2个对象。
这里有一个问题需要注意:如果需要把一个对象放入HashSet 中时,如果重写该对象对应类的equals()方法,也应该重写其hashCode(方法,其规则是:如果2个对象通过equals方法比较返回true时,这两个对象的hashCode也应该相同。
如果两个对象通过equals方法比较返回true,但这两个对象的hashCode0方法返回不同的hashCode时,这将导致HashSet将会把这两个对象保存在HashSet的不同位置,从而两个对象都可以添加成功,这与Set集合的规则有点出入。但是看下hashset的定义:只有hashcode和equals都相等,才认为对象相等。所以咱们要自己去理解下含义。 如果两个对象的hashCode(方法返回的hashCode相同,但它们通过equals方法比较返回false时将更麻烦:因为两个对象的hashCode 值相同,HashSet 将试图把它们保存在同一个位置,但实际上又不行(否则将只剩下一个对象),所以处理起来比较复杂;而且HashSet访问集合元素时也是根据元素的hashCode值来访问的,如果HashSet中包含两个元素有相同的hashCode值,将会导致性能下降。可以参考下面的话语来理解:
(1)如果两个对象根据equals()方法比较是相等的,那么调用这两个对象中任意一个对象的hashCode方法都必须产生同样的整数结果。
(2)如果两个对象根据equals()方法比较是不相等的,那么调用这两个对象中任意一个对象的hashCode方法,则不一定要产生相同的整数结果。
(3)从而在集合操作的时候有如下规则:
将对象放入到集合中时,首先判断要放入对象的hashcode值与集合中的任意一个元素的hashcode值是否相等,如果不相等直接将该对象放入集合中。如果hashcode值相等,然后再通过equals方法判断要放入对象与集合中的任意一个对象是否相等,如果equals判断不相等,直接将该元素放入到集合中,否则不放入。
回过来说get的时候,HashMap也先调key.hashCode()算出数组下标,然后看equals如果是true就是找到了,所以就涉及了equals。
小结: 如果需要某个类的对象保存到HashSet集合中,重写这个类的equals()方法和 hashCode()方法时,应该尽量保证两个对象通过equals比较返回true时,它们的hashCode 方法返回值也相等。
HashSet中每个能存储元素的“槽位(slot)” 通常称为“桶”(bucket),如果有多个元素的hashCode
相同,化它们通过equals方法比较返回false,就需要在一个“桶”里放多个元素,从而导致性能下降。
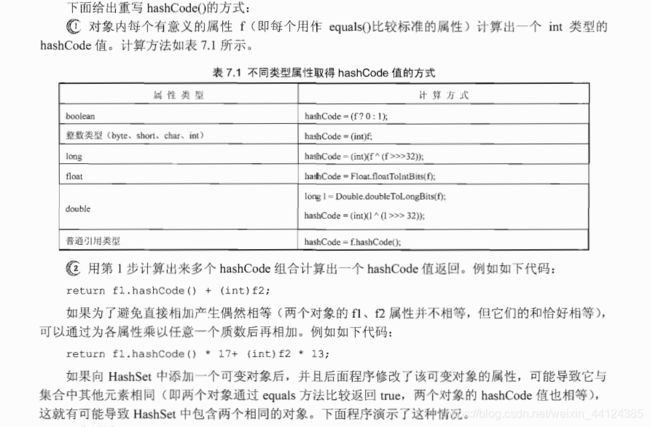
前而介绍了hasCod()方法对于HashSet 的重要性(实际上,对象的hashCode 值对于后面的HashMap同样重要),下面给出重写hashCode0方法的基本规则:
➢当两个对象通过equals方法比较返回true时,这两个对象的hashCode应该相等。
➢对象中用作equals比较标准的属性,都应该用来计算hashCode值。

package array.set;
import java.util.HashSet;
import java.util.Iterator;
class R {
int count;
public R(int count) {
this.count = count;
}
@Override
public String toString() {
return "R(" +
"count属性:" + count +
')';
}
@Override
public boolean equals(Object o) {
if(o instanceof R){
R r= (R) o;
if (r.count==this.count){
return true;
}
}
return false;
}
@Override
public int hashCode() {
return this.count;
}
}
public class TestHashSet2 {
public static void main(String[] args) {
HashSet hs = new HashSet();
hs.add(new R(5));
hs.add(new R(-3));
hs.add(new R(9));
hs.add(new R(-2));
//打印HashSet集合,集合元素没有重复
System.out.println(hs);
//取出第一个元素
Iterator it = hs.iterator();
R first = (R) it.next();
// hs.remove(first);
// first = (R) it.next(); //再取元素 就会报这个老异常:java.util.ConcurrentModificationException
//为第一个元素的count属性賦值
first.count = -3;//①
//再次输出HashSet集合,集合元素有重复元素
System.out.println(hs);
//删除count为-3的R对象
hs.remove(new R(-3)); //
//可以看到被删除了一个R元素
System.out.println(hs);
//输出false
System.out.println("hs是否包含count为-3的R对象?" + hs.contains(new R(-3)));
//输出false
System.out.println("hs是否包含count为-2的R对象?" + hs.contains(new R(-2)));
}
}
上面程序中提供了R类,R类重写了equals(Object obj)方法和hashCode0方法, 这两个方法都是 根据R对象的count属性来判断的。上面程序的①行代码处改变了Set集合中第一个R对象的count 属性,这将导致该R对象与集合中其他对象相同。程序运行结果如下图所示:
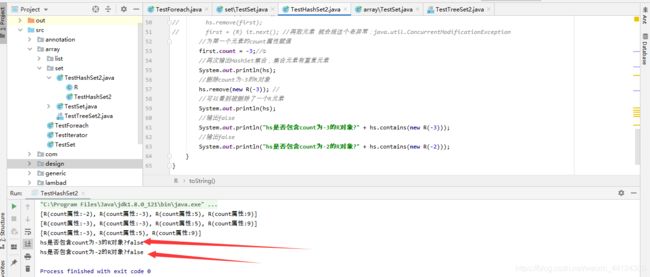
正如上图中所见到的,HashSet 集合中第一个元素和第二个元素完全相同,这表明两个元素已经重复,但因为HashSet在添加它们时已经把它们添加到了不同地方,所以HashSet完全可以容纳两个相同的元素。
但此时HashSet将会比较混乱:当试图删除count 为-3的R对象时,HashSet 会计算出该对象的hashCode值,从而找出该对象在集合中的保存位置(寻找该hash值处是否有值),如果有值,然后把此处的对象与传递过来的count为-3的R对象通过equals方法进行比较,如果相等则删除该对象一一HashSet 只有第2个元素才满足该条件(第1个元素它实际上保存在count为-2的R对象对应的位置,hashcode的位置上),所以第2个元素被删除。至于第1个count为-3的R对象,它保存在count为-2的R对象对应的位置,但即使使用equals方法拿它和count为-2的R对象比较依然返回false,这将导致HashSet不可能准确访问该元素。
当向HashSet中添加可变对象时,必须十分小心。如果修改HashSet集合中的对象, 有可能导致该对象与集合中其他对象相等,从而导致HashSet无法准确访问该对象。
LinkedHashSet
HashSet还有一个子类LinkedHashSet, LinkedHashSet 集合也是根据元素hashCode值来决定元素存储位置,但它同时使用链表维护元素的次序,这样使得元素看起来是以插入的顺序保存的。也就是说,当遍历LinkedHashSet集合里元素时,HashSet 将会按元素的添加顺序来访问集合里的元素。LinkedHashSet需要维护元素的插入顺序,因此性能略低于HashSet的性能,但在迭代访问Set里的全部元素时将有很好的性能,因为它以链表来维护内部顺序。
package array.set;
import java.util.LinkedHashSet;
public class TestLinkedHashSet {
public static void main(String[] args) {
LinkedHashSet books = new LinkedHashSet();
books.add("Struts2权威指南");
books.add("轻量级J2EE企业应用实战");
System.out.println("第一次输出:"+books);
//删除Struts2权威指南
books.remove("Struts2权威指南");
//重新添加Struts2 权威指南
books.add("Struts2权威指南");
System.out.println("第二次输出:"+books);
}
}
编译、运行上面程序,看到如下输出:
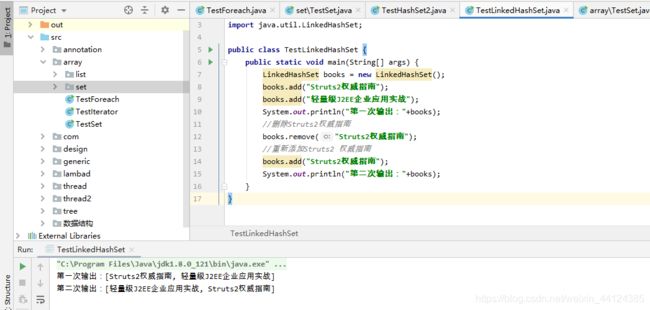
上面的集合里,元素的顺序正好与添加顺序一致。
TreeSet
TreeSet是SortedSet接口的唯一实现,正如SortedSet名字所暗示的,TreeSet可以确保集合元素处于排序状态。与前面HashSet集合相比,TreeSet 还提供了如下几个额外的方法:
➢Comparator comparator():返回当前Set使用的Comparator,或者返回null,表示以自然方式排序。
➢Object first():返回集合中的第一个元素。
➢Object last():返回集合中的最末一个元素。
➢Object lower(Object e):返回集合中位于指定元素之前的元素(即小于指定元素的最大元素,参考元素不需要是TreeSet的元素)。
➢Object higher (Object e):返回集合中位于指定元素之后的元索(即大于指定元素的最小元素,参考元素不需要是TreeSet的元素)。
➢SortedSet subSet(fromElement, toElement):返回此Set的子集合,范围从fromElement(包含)到toElement (不包含) .
➢SortedSet headSet(toElement):返回此Set的子集,由小于toElement的元素组成。
➢SortedSet tailSet(fromElement):返回此Set的子集,由大于或等于fromElement的元索组成。
下面程序测试了TreeSet 的通用用法:
package array.set;
import java.util.TreeSet;
public class TestTreeSetCommon {
public static void main(String[] args) {
TreeSet nums = new TreeSet();
//向TreeSet中添加四个Integer对象
nums.add(5);
nums.add(2);
nums.add(10);
nums.add(-9);
//输出集合元素,看到集合元素已经处于排序状态
System.out.println(nums);
//输出集合里的第一个元素
System.out.println(nums.first());
//输出集合里的最后一个元素
System.out.println(nums.last());
//返回小于4的子集,不包含4
System.out.println(nums.headSet(4));
//返回大于5的子集,如果Set中包含5,子集中还包含5
System.out.println(nums.tailSet(5));
//返回大于等于-3,小于4的子集。
System.out.println(nums.subSet(-3, 4));
}
}
编译、运行上面程序,看到如下运行结果:
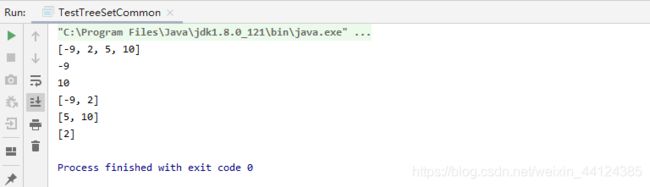
根据上面程序的运行结果即可看出,TreeSet 并不是根据元素的插入顺序进行排序,而是根据元素实际值来进行排序的。
与HashSet集合采用hash算法来决定元素的存储位置不同,TreeSet采用红黑树的数据结构对元素进行排序。那么TreeSet进行排序的规则是怎样的呢? TreeSet 支持两种排序方法:自然排序和定制排序。默认情况下,TreeSet 采用自然排序。
自然排序
TreeSet会调用集合元素的compareTo(Object obj)方法来比较元素之间大小关系,然后将集合元素按升序排列,这种方式就是白然排列。
Java提供了一个Comparable接口,该接口果定义了一个compareTo(Object obj)方法,该方法返回一个整数值,实现该接口的类必须实现该方法,实现了该接口的类的对象就可以比较大小。当一个对象调用该方法与另一个对象进行比较,例如obj1.compareTo(obj2),如果该方法返回0,则表明这两个对象相等:如果该方法返四一个正整数,则表明obj1大于obj2;如果该方法返回一个负整数,则表明obj1小于obj2。
Java 的一些常用类已经实现了Comparable 接口,并提供了比较大小的标准。下面是实现了Comparable接口的常用类:
➢BigDecimal. BigInteger 以及所有数值型对应包装类:按它们对应的数值的大小进行比较。
➢Character:按字符的UNICODE值进行比较。
➢Boolean: true 对应的包装类实例大于false对应的包装类实例。
➢String:按字符串中字符的UNICODE值进行比较。
➢Date、Time:后面的时间、日期比前面的时间、日期大。
如果试图把一个对象添加进TreeSet 时,则该对象的类必须实现Comparable接口,否则程序将会抛出异常,如下程序示范了这个错误。
package array.set;
import jdk.internal.dynalink.beans.StaticClass;
import java.io.*;
import java.util.Set;
import java.util.TreeSet;
import java.util.zip.GZIPOutputStream;
class Err {
String msg;
public String getMsg() {
return msg;
}
public void setMsg(String msg) {
this.msg = msg;
}
}
public class TestTreeSetErr {
public static void main(String[] args) {
TreeSet ts=new TreeSet();
ts.add(new Err());//2
ts.add(new Err());//1
}
}
上面程序试图向TreeSet集合中添加2个Err对象,添加第一个对象时,TreeSet 里没有任何元素,所以不会出现任何问题;当添加第二个Err对象时,TreeSet 就会调用该对象的compare To(Object obj)方法与集合中其他元素进行比较一一如果其对应的类没有实现Comparable 接口,则会引发ClassCastException异常。因此,上面程序将会在①代码处引发该异常。
本文参考自疯狂java讲义(2),不知道是不是版本的问题,网上也有好多说添加第一个元素时不比较。实际上,试图向TreeSet集合中添加第1个Err对象就报了异常
java.lang.ClassCastException: array.set.Err cannot be cast to java.lang.Comparable,跟踪了源码,它是和自身进行了比较,返回值为0;源码如下:
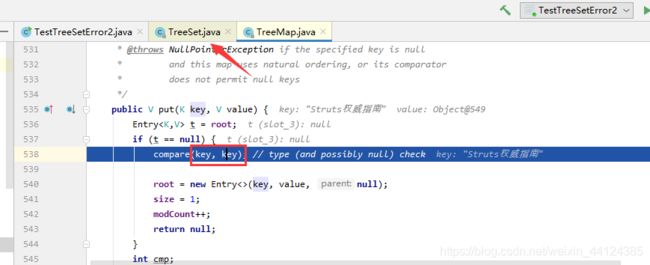
还有一点必须指出:大部分类在实现compareTo(Object obj)方法,都需要将被比较对象obj强制类型转换成相同类型,因为只有相同类的两个实例才会比较大小。当试图把一个对象添加到TreeSet 集合时,TreeSet 公调用该对象的compareTo(Object obj)方法与集合中其他元素进行比较一这 就要求集合中其他元素与该元素是同一个类的实例。也就是说,向TreeSet中添加的应该是同一个类的对象,否则也会引发ClassCastException异常。如下程序示范了这个错误。
package array.set;
import java.util.Date;
import java.util.TreeSet;
public class TestTreeSetError2 {
public static void main(String[] args) {
TreeSet ts=new TreeSet();
//向TreeSet集合中添加两个Err对象
ts.add(new String("Struts权威指南"));
ts.add(new Date()); //①
}
}
结果:
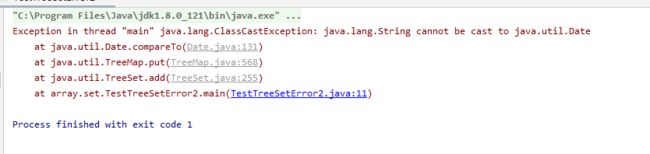
上面程序先向TreeSet集合中添加了一个字符串对象,这个操作完全正常。当添加第二个Date对象时,TreeSet就会调用该对象compareTo(Object obj)方法与集合中其他元素进行比较一Date对象的compareTo(Object obj)方法无法与字符串对象比较大小,所以上面程序将在①代码处引发异常。
如果向TreeSet中添加对象时,如果该对象是程序员自定义类的对象,则可以向TreeSet中添加多种类型的对象,前提是用户自定义类实现了Comparable接口,实现该接口时实现compareTo(Object obj)方法时没有进行强制类型转换。但当试图操作TreeSet里的集合数据时,不同类型的元素依然会发生ClassCastException异常。
当把一个对象加入TreeSet集合中时, TreeSet调用该对象的compareTo(Objet obj)方法与容器中的其他对象比较大小,然后根据红黑树算法决定它的存储位置。如果两个对象通过compareTo(Object obj)比较相等,TreeSet 即认为它们应存储同一位置。
对于TreeSet 集合而言,它判断两个对象不相等的标准是:两个对象通过equals方法比较返回false ,或通过compareTo(Object obj)比较没有返回0(经过验证好像是和equals方法返回值无关)一一即使两个对象是同一个对象,TreeSet 也会把它当成两个对象进行处理。下面程序同一个对象添加到TreeSet中时,TreeSet也把它当成2个对象。
package array.set;
import java.util.Objects;
import java.util.TreeSet;
class Z implements Comparable {
int age;
public Z(int age) {
this.age = age;
}
@Override
public boolean equals(Object o) {
return false;
}
@Override
public int compareTo(Object o) {
return 1;
}
}
public class TestTreeSet {
public static void main(String[] args) {
TreeSet set = new TreeSet();
Z z=new Z(6);
set.add(z);
//输出true,表明添加成功
System.out.println(set.add(z));//①
//下面输出set集合,将看到有两个元素
System.out.println(set);
//修改set集合的第一个元素的age属性
((Z) (set.first())) .age = 9;
//输出set集合的最后一个元素的age属性,将看到也变成了9
System.out.println(((Z) (set.last())).age);
}
}
结果如下:
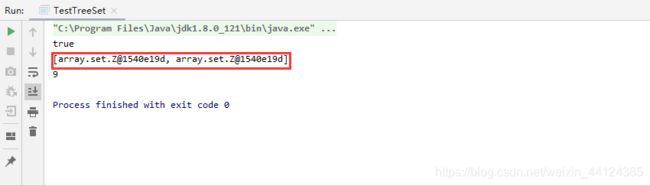
这里是引用程序中①代码行把同一个对象再次添加到TreeSet集合中,因为z对象的equals()方法总是返回false,而且compareTo(Object obj)方法总是返回1(满足一个就行),这样TreeSet会认为z对象和它自己也不相同,因此TreeSet中添加两个z对象。
经过验证,发现只要compareTo(Object obj)方法返回值不为0即认为是不同的对象,和equals方法的返回值好像无关
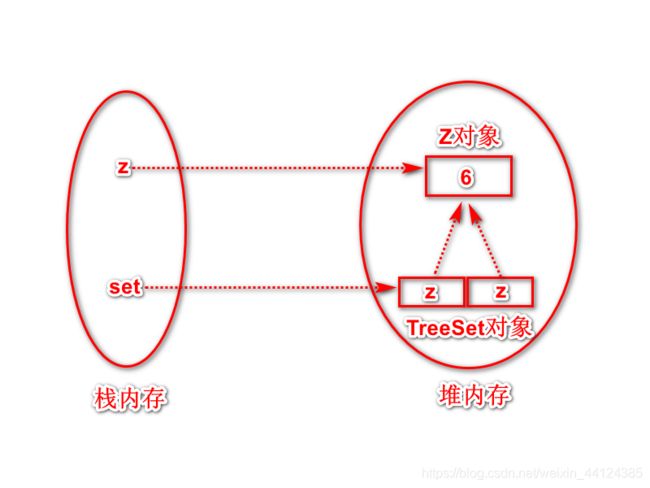
图7.5显示了TreeSet在内存中的存储示意。
定制排序