Linux笔记 Day05---(history用法、命令别名、变量、特殊符号、文件描述符、管道及重定向)
文章目录
- 一、history用法(续):
- (一) -p 和 -s 选项
- 1.history -p 命令
- 2.history -s 命令
- 3.有关历史命令的几个变量:
- ①$HISTSIZE
- ②$HISTTIMEFORMAT
- ③$HISTFILE
- ④$HISTFILESIZE
- ⑤$HISTCONTROL
- (二)相关其他用法
- ①!#
- ②!!
- ③!STRING
- ④快捷键
- ⑤!$
- 二、命令别名
- 1.alias
- 2.定义别名
- 3.撤销别名
- 4.查看命令是否有别名
- 三、Linux bash变量
- (一)本地变量
- (二)局部变量
- (三)环境(全局)变量
- 四、Linux bash 特殊重要符号
- ①. 点号
- ②.. 双点号
- ③; 分号
- ④&&
- ⑤||
- ⑥``反单引号
- ⑦'' 单引号
- ⑧" "双引号
- ⑨{} 花括号
- ⑩* 星号
- 五、Linux管道及重定向
- (一)进程的概念
- (二)文件描述符
- 1.查看进程所打开的文件描述符有哪些
- 2.Linux系统对文件描述符的限制级别:系统级别和用户级别
- 3.查看系统当前打开的文件描述符数量
- 4.查看某个进程打开的文件描述符数量
- (三)| 管道
- 1.进程管道
- 2.tee管道
- (四)输入输出重定向
- 1.标准输入,标准输出,标准错误
- 2.输出重定向(覆盖,追加)
- 3.错误输出重定向: 2> 2>>
- 4.输入重定向 <
- 5.正确输出和错误输出都重定向到一个地方
- 6.实践
一、history用法(续):
[dxk@admin ~]$ help history
history: history [-c] [-d 偏移量] [n] 或 history -anrw [文件名] 或 history -ps 参数 [参数...]
显示或操纵历史列表。
带行号显示历史列表,将每个被修改的条目加上前缀 `*'。
参数 N 会仅列出最后的 N 个条目。
选项:
-c 删除所有条目从而清空历史列表。(保存历史命令的文件.bash_history中记录的历史命令并不会受到影响,而且仅对当前bash有效,重新登录后还会显示出之前的)
-d 偏移量 删除历史列表中指定的历史命令。(仅删除历史列表中指定行号的,历史文件中相应的并不会删除,同样仅对当前bash有效)
-a 将当前内存中的历史追加到历史文件中(本次登陆后所输入的命令【本次登录所输入的所有命令是存在内存中的】会在退出后才写入历史命令文件中,使用 history -a命令后直接手动将内存中的历史命令追加到.bash_history文件中)
-n 从历史文件中读取所有未被读取的行(在历史列表中没有的命令将从历史文件中加载到当前历史列表中)
-r 读取历史文件并将内容追加到历史列表中(将历史文件中的所有命令追加到当前历史列表中)
中
-w 将当前历史写入到历史文件中并追加到历史列表中(相当于是将历史列表中的历史命令和历史文件中的历史命令全部整合同时写入到文件和当前历史列表中)
-p 对每一个 ARG 参数展开历史并显示结果而不存储到历史列表中
-s 以单条记录追加 ARG 到历史列表中
如果给定了 FILENAME 文件名,则它将被作为历史文件。否则
如果 $HISTFILE 变量有值的话使用之,不然使用 ~/.bash_history 文件。
如果 $HISTTIMEFORMAT 变量被设定并且不为空,它的值会被用于
strftime(3) 的格式字符串来打印与每一个显示的历史条目想关联的时
间戳,否则不打印时间戳。
退出状态:
返回成功,除非使用了无效的选项或者发生错误
(一) -p 和 -s 选项
1.history -p 命令
相当于 echo命令,可以打印字符串和变量,同时可以显示输出到终端的命令的执行结果。但不会保存到历史列表和命令历史文件中。
#打印字符串效果如下:
#history -p 后面的参数写什么就会原封不动的打印出什么(变量除外,但如果变量是用单引号强引用括起来也是一样 ),即使是命令
[root@admin ~]# history -p Welcome to my CSDN!
Welcome
to
my
CSDN!
[root@admin ~]# history -p ls
ls
[root@admin ~]# history -p 'Welcome to my CSDN'
Welcome to my CSDN
[root@admin ~]# history -p "Welcome to my CSDN"
Welcome to my CSDN
#打印变量效果如下:
[root@admin ~]# history -p $PS1
[\u@\h
\W]\$
[root@admin ~]# history -p '$PS1' #这里因为是单引号,为强引用(即所见即所得)
$PS1
[root@admin ~]# history -p "$PS1"
[\u@\h \W]\$
如果history -p 后面的参数为使用反引号(反引号的作用就是将反引号内的Linux命令先执行,然后将执行结果赋予变量。)括起来要执行的命令(注意:这里所说的命令必须是执行后输出结果输出到控制台的,例如:ls、pwd、cat等等,vi、vim等不行)
如果反引号中的命令是vim,那么就是这样的:
[root@admin ~]# history -p `vim test.sh`
Vim: 警告: 输出不是到终端(屏幕)
#这个情况下会死机,即使 Ctrl + c 也没用,只能关掉重启(无论是远程连接工具还是虚拟机)
看看输出是到终端的命令执行出来是什么样的:
[root@admin ~]# history -p `echo Welcome to my CSDN`
Welcome
to
my
CSDN
[root@admin ~]# history -p `echo $PS1`
[\u@\h
\W]\$
[root@admin ~]# history -p `ls`
anaconda-ks.cfg
date.txt
error.txt
etc.tar.ga
file
file1
ip.txt
list.txt
test.sh
[root@admin ~]# history -p `pwd`
/root
[root@admin ~]# history -p `cat test.sh`
name=zhangsan
echo
$name
[root@admin ~]#
敲黑板划重点:只要是以history -p开始执行的命令,后面参数无论跟什么,都不会添加到历史列表和历史文件中
2.history -s 命令
请看实际操作:
[root@admin ~]# history -c
[root@admin ~]# history -s hello world
[root@admin ~]# history -s 'hello world'
[root@admin ~]# history -s "hello world"
[root@admin ~]# history -s ls
[root@admin ~]# history -s 'ls'
[root@admin ~]# history -s "ls"
[root@admin ~]# history -s `ls` #这个是反引号
[root@admin ~]# history -s $PS1
[root@admin ~]# history
1 hello world
2 ls
3 anaconda-ks.cfg date.txt error.txt etc.tar.ga file file1 ip.txt list.txt test.sh
4 [\u@\h \W]\$
5 history
总结 :
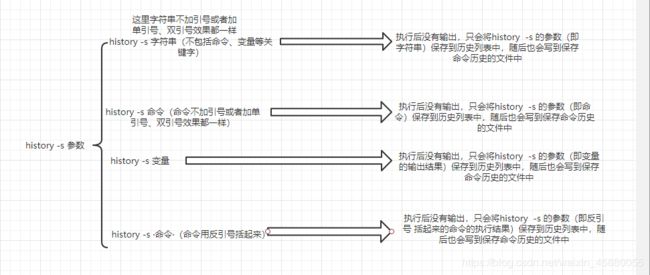
3.有关历史命令的几个变量:
①$HISTSIZE
用于设置历史列表的显示数目,不会影响到文件中存储的历史命令数量
[root@admin ~]# echo $HISTSIZE
1000
[root@admin ~]# HISTSIZE=10 #这里对该变量进行临时修改,要想修改后一直有效必须写入环境变量文件中(下同)
[root@admin ~]# echo $HISTSIZE
10
[root@admin ~]# history #对该变量设置为10,所以历史列表中显示的历史命令只有10条
347 cat -n .bash_history
348 echo $HISTSIZE
349 vim .bash_history
350 vim /etc/profile
351 echo $HISTSIZE
352 source /etc/profile
353 echo $HISTSIZE
354 HISTSIZE=10
355 echo $HISTSIZE
356 history
[root@admin ~]#
②$HISTTIMEFORMAT
给历史命令打印时间戳
这里打印的时间只会在历史列表中显示,历史文件中并不会有
[root@admin ~]# echo $HISTTIMEFORMAT #默认历史命令没有添加时间戳
[root@admin ~]# HISTTIMEFORMAT="%Y-%m-%d %H:%M:%S " #这里我们进行临时修改,并指定要显式的时间格式
[root@admin ~]# echo $HISTTIMEFORMAT
%Y-%m-%d %H:%M:%S
[root@admin ~]# history #查看效果
355 2020-07-09 09:42:07 HISTTIMEFORMAT=""
356 2020-07-09 09:42:18 echo HISTTIMEFORMAT
357 2020-07-09 09:42:26 echo $HISTTIMEFORMAT
358 2020-07-09 09:43:18 HISTTIMEFORMAT="%Y-%m-%d %H:%M:%S "
359 2020-07-09 09:43:24 echo $HISTTIMEFORMAT
360 2020-07-09 09:43:34 history
③$HISTFILE
指定存放命令历史的目录文件
每个用户都会拥有各自的存放历史命令的文件,系统默认这个文件是各用户家目录下的.bash_history文件
[root@admin ~]# echo $HISTFILE
/root/.bash_history
[root@admin ~]# cd /etc
[root@admin etc]# touch histfile #自行创建一个文件,目的是将历史命令保存到这个文件中去
[root@admin ~]# HISTFILE="/etc/historyfile" #将次变量临时修改为我们刚创建的/etc/historyfile文件,这样后面的历史命令都会保存到这个文件中去
[root@admin ~]# echo $HISTFILE #这里是为了查看我们修改是否成功
/etc/historyfile
[root@admin ~]# history -a #将当前内存中的历史命令写入到我们指定的存储历史命令的文件中去
[root@admin ~]# cat -b /etc/historyfile #查看效果
1 #1594259004
2 echo $HISTTIMEFORMAT
3 #1594259014
4 history
5 #1594259204
6 echo $HISTFILE
7 #1594259229
8 cd /etc/file
9 #1594259243
10 cd /etc
11 #1594259257
12 touch histfile
13 #1594259259
14 cd
15 #1594259292
16 HISTFILE="/etc/historyfile"
17 #1594259316
18 echo $HISTFILE
19 #1594259334
20 history -w
④$HISTFILESIZE
用于设置命令历史文件的大小;超出设置的数量会删除旧的
通俗地讲:用于设置在变量$HISTFIZE定义的文件(默认为.bash_history) 中保存命令的记录总数,可以理解为.bash_history文件中最多只有HISTFILESIZE行
[root@admin ~]# echo $HISTFILESIZE #改变量系统默认设置为 1000
1000
[root@admin ~]# HISTFILESIZE=3 #这里临时修改大小为3
[root@admin ~]# cat -n .bash_history #我们查看保存命令历史文件中的历史命令只剩下3条
1 vim /etc/profile
2 source /etc/profile
3 exit
[root@admin ~]# history #历史列表中不只是3条,因为这次登陆后用过的命令在缓存中存在
1 source /etc/profile
2 cat -n .bash_history
3 vim /etc/profile
4 source /etc/profile
5 exit
6 cat -n .bash_history
7 HISTFILESIZE=3
8 cat -n .bash_history
9 echo HISTFILESIZE
10 echo $HISTFILESIZE
11 history
⑤$HISTCONTROL
控制命令历史记录的方式
该变量有三个选项可供选择:
- ignoredups:忽略重复的命令(重复的命令只记录一次,仅限于连续输入相同的命令)
- ignorespace:忽略以空白字符开头的命令(以空白符开头输入的命令将不予以记录)
- ignoreboth:以上两者同时生效
# 系统默认为ignoredups
[root@admin ~]# echo $HISTCONTROL
ignoredups
可自行修改变量的值:
NAME=VALUE
[root@admin ~]# HISTCONTROL=ignoredups
[root@admin ~]# HISTCONTROL=ignorespace
[root@admin ~]# HISTCONTROL=ignoreboth
以上就是有关history的相关变量,这里要注意的是要想永久生效必须将变量写入到环境变量文件中。
(二)相关其他用法
调用命令历史列表中的命令:
①!#
执行历史列表中的第#条命令
[root@admin ~]# history
21 ls
22 cd
23 cat -n /etc/historyfile
24 echo $PS1
25 history
26 ls
27 HISTSIZE=8
28 history
[root@admin ~]# !26
ls
anaconda-ks.cfg error.txt file ip.txt test.sh
date.txt etc.tar.ga file1 list.txt
[root@admin ~]#
②!!
再一次执行上一条命令
[root@admin ~]# pwd
/root
[root@admin ~]# !!
pwd
/root
③!STRING
执行命令历史列表中最近一个以STRING开头的命令
[root@admin ~]# history
21 ls
22 cd
23 cat -n /etc/historyfile
24 echo $PS1
25 history
26 ls
27 HISTSIZE=8
28 history
[root@admin ~]# !ec
echo $PS1
[\u@\h \W]\$
[root@admin ~]#
④快捷键
Esc键 + . :将缓存中的历史命令的最后一个参数取出到当前命令输入行
说明:如果你执行过的命令是这样的:
[root@admin ~]# history
30 echo $PS1
31 .
32 ls
33 pwd
34 ls -a /
35 cd /etc/sysconfig/
36 cd
37 history
那么,第一次输入此快捷键,在命令行显示 history
第二次输入此快捷键,在命令行显示 cd
第三次输入此快捷键,在命令行显示 /etc/sysconfig/
第四次输入此快捷键,在命令行显示 /
第五次输入此快捷键,在命令行显示 pwd
……
⑤!$
类似于④的功能,但是只能取前一次命令的最后一个参数
[root@admin ~]# ls -a /etc/sysconfig/
[root@admin ~]# cd !$
cd /etc/sysconfig/
[root@admin sysconfig]# pwd
/etc/sysconfig
[root@admin sysconfig]# cd;!$
cd;pwd
/root
[root@admin ~]#
[root@admin ~]# history -a
[root@admin ~]# ls !$
ls -a
. .cshrc .lesshst
.. date.txt list.txt
anaconda-ks.cfg error.txt .tcshrc
[root@admin ~]#
二、命令别名
1.alias
获取所有可用别名的定义
[root@admin ~]# alias
alias cp='cp -i'
alias egrep='egrep --color=auto'
alias fgrep='fgrep --color=auto'
alias grep='grep --color=auto'
alias l.='ls -d .* --color=auto'
alias ll='ls -l --color=auto'
alias ls='ls --color=auto'
alias mv='mv -i'
alias rm='rm -i'
alias which='alias | /usr/bin/which --tty-only --read-alias --show-dot --show-tilde'
2.定义别名
格式:alias NAME=‘COMMAND’
例如:
#这里我们给修改网卡配置文件自定义命令别名为setIP
[root@admin ~]# alias setIP="vim /etc/sysconfig/network-scripts/ifcfg-ens32"
[root@admin ~]# setIP
注意:这样做仅对当前shell进程有效,临时有效。永久生效需写入环境变量文件中,对当前用户生效写入该用户家目录下的.bashrc文件或bash_profile文件中,如果需要对所有用户生效(全局生效),需写入/etc/profile或/etc/.bashrc(最好选用这个)文件中。要注意环境变量文件的加载顺序和覆盖问题
3.撤销别名
[root@nebulalinux03 ~]# unalias NAME
[root@admin ~]# unalias setIP
[root@admin ~]# setIP
-bash: setIP: 未找到命令
ls命令是ls --color=auto的别名
4.查看命令是否有别名
type -a command 或者 which command
[root@admin ~]# type -a ls
ls 是 `ls --color=auto' 的别名
ls 是 /usr/bin/ls
[root@admin ~]# which ls
alias ls='ls --color=auto'
/usr/bin/ls
所以我们也可以用原名来执行:
[root@admin ~]# ls --color=auto
anaconda-ks.cfg error.txt file ip.txt test.sh
date.txt etc.tar.ga file1 list.txt
[root@admin ~]# ls
anaconda-ks.cfg error.txt file ip.txt test.sh
date.txt etc.tar.ga file1 list.txt
三、Linux bash变量
变量是计算内存的单元,其中存放的值可以改变,当Shell脚本需要保存一些信息时,如一个文件名或是一个数字,就把它存放在一个变量中。每个变量有一个名字,所以很容易引用它。使用变量可以保存有用的信息,是系统获知用户相关设置,变量也可以用于保存暂时信息。
在Linux系统中变量分为了本地变量,局部变量,环境变量
(一)本地变量
生效范围(作用域)为当前shell进程中的某代码片段,通常指函数
例如:我们们在bash脚本中设置一个变量
[root@admin ~]# vim test.sh
name=xiaoming
~
~
:wq
在当前shell中直接查看改变量无法查看到,说明本地变量的作用域仅限于该脚本中
[root@admin ~]# echo $name
[root@admin ~]#
我们可以在脚本中输出该变量,并在外部查看:
[root@admin ~]# vim test.sh
name=xiaoming
echo $name
~
~
:wq
[root@admin ~]# sh test.sh
xiaoming
(二)局部变量
又称标准变量或普通变量,指生效范围为当前shell进程;对当前shell之外的其它shell进程,包括当前shell的子shell进程均无效
举例:
在当前shell中声明一个变量并查看:
[root@admin ~]# name=zhangsan
[root@admin ~]# echo $name
zhangsan
而当我们退出当前shell将会实效,在其他shell中也不会生效,包括子shell
(三)环境(全局)变量
生效范围为当前shell进程及其子进程
有关子进程这里先不进行讲解
环境变量的声明要加关键字export,如下:
[root@admin ~]# export name=lisi
[root@admin ~]# echo $name
lisi
注意:无论定义为什么变量,只要退出当前shell便会失效,而且当变量在pts0上被声明之后,在pts1……中均不能使用(因为已经超出任何变量的作用域)。当声明一个变量后,要查看需要加$字符。要想变量在任何时候任何地方生效,必须将变量写入到环境配置文件中,比如/etc/profile文件等
环境变量文件加载顺序:
/etc/profile → /etc/profile.d/*.sh → ~/.bash_profile → ~/.bashrc → [/etc/bashrc]
四、Linux bash 特殊重要符号
在Linux中有一些比较重要的特殊符号,代表不同的意义。
①. 点号
在Linux中点号代表当前目录
②… 双点号
双点号代表上一级目录
有关命令拼接的符号
③; 分号
在执行多条命令时,用分号分开,顺序地独立执行各条命令。不存在逻辑判断,彼此之间不关心是否失败, 所有命令都会执行
[root@admin ~]# ls;pwd
anaconda-ks.cfg file ping-baidu.log test.sh
/root
[root@admin ~]# ls -T;pwd #为了测试,这里故意给定一个无效的参数
ls:选项需要一个参数 -- T
Try 'ls --help' for more information.
/root
④&&
在执行多条命令时,用&&符号分开,存在逻辑判断,前一个命令执行成功,后一个命令才会执行
[root@admin ~]# ls && pwd
anaconda-ks.cfg file ping-baidu.log test.sh
/root
[root@admin ~]# ls -T && pwd #第一条命令执行失败,第二条也不会执行
ls:选项需要一个参数 -- T
Try 'ls --help' for more information.
⑤||
在执行多条命令时,用||符号分开,不存在逻辑判断前一个执行失败,后一个也会执行,直执行第一个对的命令
[root@admin ~]# ls || pwd #如果多条命令都正确均可以执行,只执行第一个对的
anaconda-ks.cfg file ping-baidu.log test.sh
[root@admin ~]# pwd -a || pwd || pwd -s #多条命令有对有错,还是只执行第一个对的而且显示结果在最后一行,但是错误的命令会有提示
-bash: pwd: -a: 无效选项
pwd: 用法:pwd [-LP]
/root
⑥``反单引号
命令替换,解析shell命令。在执行一条命令时,会先将其中的 ``中的语句当作命令执行一遍,再将结果加入到原命令中重新执行。
[root@admin ~]# echo `world`
-bash: world: 未找到命令
[root@admin ~]# echo `$HISTSIZE`
-bash: 1000: 未找到命令
[root@admin ~]# echo `date` #解析命令
2020年 07月 09日 星期四 15:59:58 CST
[root@admin ~]# echo `'date'`
2020年 07月 09日 星期四 16:00:17 CST
[root@admin ~]# echo `"date"`
2020年 07月 09日 星期四 16:00:30 CST
#以下两个例子想说明的是强引用单引号确实很强
[root@admin ~]# echo '`date`'
`date`
[root@admin ~]# echo '"date"'
"date"
⑦’’ 单引号
强引用,不做变量替换,所写即所得,在单引号里写的是什么原样输出什么
为了保护文本不被转换,除了它本身,就是说除去单引号本身之外,在单引号内的所有文本都是原样输出。
[root@admin ~]# echo 'hello world' #普通字符串原样输出
hello world
[root@admin ~]# echo '$PS1' #变量原样输出
$PS1
[root@admin ~]# echo 'ls' #命令原样输出
ls
[root@admin ~]# echo '''' #这里要注意的是单引号无法输出其本身
[root@admin ~]# echo 'hello \n world' #转义字符\n ,换行
hello \n world
[root@admin ~]# echo -e ' hello \n world'
hello
world
[root@admin ~]# echo '`date`' #单引号无法解析命令
`date`
[root@admin ~]# echo "`date`" #双引号可以解析命令
2020年 07月 09日 星期三 15:53:17 CST
⑧" "双引号
弱引用,可以实现变量和命令的替换。除了双引号本身、反引号内的函数、$开头的变量以外,其余的都可以直接输出
[root@admin ~]# echo """" #本身不能输出
[root@admin ~]# echo "hello world" #普通字符串原样输出
hello world
[root@admin ~]# echo "ls" #命令原样输出
ls
[root@admin ~]# echo "$PS1" #变量会保留自己的特殊含义并会输出
[\u@\h \W]\$
[root@admin ~]# echo " hello \n world" #转义字符
hello \n world
[root@admin ~]# echo -e " hello \n world"
hello
world
[root@admin ~]# echo '`date`' #单引号无法解析命令
`date`
[root@admin ~]# echo "`date`" #双引号可以解析命令
2020年 07月 09日 星期三 15:53:17 CST
以上结果得出:用 echo 命令输出时,对于转义字符不受强引弱引的限制,只和 echo 的选项 -e 有关
⑨{} 花括号
做扩展,或者构建代码块
花括号用来匹配一组用逗号分隔的字符串中的任一个。左花括号之前的所有字符称为前文(preamble),右花括号之后的所有字符称为后文(preamble)。前文和后文都是可选的。花括号中不能包含不加引号的空白符。
例子:
(1)[root@dxk ~]$ mkdir /usr/local/src/bash/{old,new,dist,bugs}
在/usr/local/src/bash目录下创建4个新目录,它们分别为:old,new,dist和bugs
(2)[root@dxk ~]$ echo {mam,pap,ba}a
mama papa baa
(3)[root@dxk ~]$ echo post{script,office,ure}
postscript postoffice posture
(4)复制文件时:
#正常拷贝时:
[root@admin ~]# cp demo.txt demo.txt.bak
[root@admin ~]# ls
anaconda-ks.cfg demo.txt.bak test.sh
#还可以这样:
[root@admin ~]# cp demo.txt{,.bak1}
[root@admin ~]# ls
anaconda-ks.cfg demo.txt.bak file
demo.txt demo.txt.bak1 test.sh
#也可以这样:
[root@admin ~]# cp demo{.txt,.txt.bak2}
[root@admin ~]# ls
anaconda-ks.cfg demo.txt.bak1 test.sh
demo.txt demo.txt.bak2
demo.txt.bak file
⑩* 星号
表示通配的作用
ls a*
因为星号表示一个或者多个字符,所以可以找到a开头的文件。
[root@admin ~]# ls a*
acd.txt anaconda-ks.cfg app.list asd.txt
ls *a 显示以a结尾的文件
[root@admin ~]# ls *a
lisa
ls *.txt 显示后缀名为txt的文件
[root@admin ~]# ls *.txt
acd.txt asd.txt edf.txt
ls a 利用星号也可以找到文件名中间段含有a的文件
[root@admin ~]# ls *a*
acd.txt app.list lisa
anaconda-ks.cfg asd.txt ping-baidu.log
五、Linux管道及重定向
在这之前,需要了解一些相关的概念:
(一)进程的概念
进程是操作系统的概念,每当我们执行一个程序时候,对于操作系统来讲就创建了一个进程,在这个过程中,伴随着资源的分配和释放。可以认为进程是一个程序的一次执行过程。
进程通信的概念
进程用户空间是相互独立的,一般而言是不能相互访问的。但是很多情况下进程间需要互相通信,来完成系统的某项功能。进程通过与内核及其他进程之间的互相通信来协调他们的行为。
进程通信的应用场景
数据传输:一个进程需要把他的数据发送给另外一个进程,发送的数据量在一个字节到几兆字节之间。
共享数据:多个进程想要操作共享数据,一个进程对数据的修改,其他进程应该立即看到。
通知时间:一个进程需要向一个进程或一组进程发送消息,通知他们发生了某种事件(如进程终止时要通知父进程)。
资源共享:多个进程之间共享同样的资源。为了做到这一点,需要内核提供锁和同步机制。
进程控制:有些进程希望完全控制另一个进程的执行,此时控制进程希望能够拦截另一个进程的所有陷入和异常,并能够及时知道他的状态变化。
进程通信的方式:信号、信号量、共享内存、消息队列、socket套接字、管道
(二)文件描述符
文件描述符FD(File Descriptors 或 Process I/O channels)
进程使用文件描述符来管理打开的文件文件描述符,本质是非负整数,通常是小整数;它是一个索引,通过该索引可以找到对应的文件。
例如,标准输入、标准输出、标准错误的文件描述符默认是 0、1、2 。当进程需要从标准输入中读取数据时,就会通过 0 索引找到标准输入所对应的内存缓冲区来读取数据。
最前面的三个文件描述符(0,1,2)分别与标准输入(stdin),标准输出(stdout)和标准错误(stderr)对应。除了这三类以外都是其他
文件描述符和文件句柄有什么区别?
文件描述是Linux/Unix操作系统中特有的概念。相当于windows系统中的文件句柄。
Linux系统中,每当打开一个进程,系统就为其分配一个唯一的整型文件描述符,用来标识这个文件,标准C中每个进程默认打开的有三个文件,标准输入,标准输出,标准错误,分别用一个FILE结构的指针来表示,即stdin,stdout,sterr,这三个结构分别对应着三个文件描述符0、1、2
1.查看进程所打开的文件描述符有哪些
这里我们以 Linux 中httpd服务为例,httpd是Apache超文本传输协议(HTTP)服务器的主程序,直接执行程序即可启动该服务。
①先进行下载安装
[root@admin ~]# yum install httpd -y
②启动该服务(启动程序相当于开启一个进程)
[root@admin ~]# systemctl start httpd
③查看该进程的信息
[root@admin ~]# ps -ef | grep httpd
#第二列数字为对应进程的进程号
root 1746 1 0 10:08 ? 00:00:00 /usr/sbin/http -DFOREGROUND
apache 1747 1746 0 10:08 ? 00:00:00 /usr/sbin/http -DFOREGROUND
apache 1748 1746 0 10:08 ? 00:00:00 /usr/sbin/http -DFOREGROUND
apache 1749 1746 0 10:08 ? 00:00:00 /usr/sbin/http -DFOREGROUND
apache 1750 1746 0 10:08 ? 00:00:00 /usr/sbin/http -DFOREGROUND
apache 1751 1746 0 10:08 ? 00:00:00 /usr/sbin/http -DFOREGROUND
root 1759 1621 0 10:11 pts/0 00:00:00 grep --color=auto httpd #此进程不属于httpd,它是刚才我们执行ps命令的进程
④ 每个进程在对应的目录 /procx/ 下都会有一个该进程号的文件夹
[root@admin ~]# ls /proc/17
17/ 1738/ 1747/ 1749/ 1751/ 1761/
1703/ 1746/ 1748/ 1750/ 1760/
⑤查看对应进程所打开的文件描述符
ls /proc/进程号/fd/
[root@admin ~]# ls /proc/1746/fd/
0 1 2 3 4 5 6 7
[root@admin ~]# ls /proc/1747/fd/
0 1 2 3 4 5 6 7 8
[root@admin ~]# ls /proc/1748/fd/
0 1 2 3 4 5 6 7 8
[root@admin ~]# ls /proc/1749/fd/
0 1 2 3 4 5 6 7 8
[root@admin ~]# ls /proc/1750/fd/
0 1 2 3 4 5 6 7 8
[root@admin ~]# ls /proc/1751/fd/
0 1 2 3 4 5 6 7 8
如果一个进程所打开的文件描述符越多那么相应的打开的文件就越多。
文件描述是一个简单的整数,用以标明每一个被进程所打开的文件和socket。第一个打开的文件是0,第二个是1,以此类推。Linux操作系统通常对每个进程能打开的文件数量有一个限制。
2.Linux系统对文件描述符的限制级别:系统级别和用户级别
系统级别:
使用cat /proc/sys/fs/file-max查看,默认值是根据内存大小,系统自动设置的,一般为内存大小(KB)的10%,shell下可以这样计算 grep -r MemTotal /proc/meminfo | awk ‘{printf("%d",$2/10)}’ (可能有其他原因导致file-max没有设置为内存的10%)
[root@admin ~]# cat /proc/sys/fs/file-max
180821
[root@admin ~]# grep -r MemTotal /proc/meminfo | awk '{printf("%d",$2/10)}'
186304
用户级别:
默认是1024,使用ulimit -n查看
[root@admin ~]# ulimit -n
1024
为什么要限制打开的文件描述符?
原因一:资源问题,每次打开文件都需要消耗内存来管理,而内存是有限的
原因二:安全问题,如果不限制的话,有不怀好心的人启动一个进程来无限的创建和打开新的文件,会让服务器崩溃。
所以限制文件描述符的数量对于Linux系统的稳定性是非常重要的。
配置文件:
限制资源使用的配置文件是 /etc/security/limits.conf 和 /etc/security/limits.d/ 目录,/etc/security/limits.d/里面配置会覆盖/etc/security/limits.conf 的配置
#修改此配置文件进行限制
[root@admin ~]# vim /etc/security/limits.conf
可以限制的资源类型如下:
所创建的内核文件的大小、进程数据块的大小、Shell进程创建文件的大小、内存锁住的大小、常驻内存集的大小、打开文件描述符的数量、分配堆栈的大小、CPU时间、单个用户的最大线程数、Shell进程所能使用的最大虚拟内存。同时,它支持硬件资源和软件资源的限制
#* soft core 0
#* hard rss 10000
#@student hard nproc 20
#@faculty soft nproc 20
#@faculty hard nproc 50
#ftp hard nproc 0
#@student - maxlogins 4
第一列表示用户和用户组(@开头)
第二列表示软限制还是硬限制
第三列表示限制的资源类型
第四列表示限制的最大值
hard和soft的区别:soft是一个警告值,而hard则是一个真正意义上的阀值,超过就会报错,一般情况下都是设为同一个值
core是内核文件,nofile是文件描述符,nproc是进程,一般情况下只限制文件描述符数就够了
也可以查看该配置文件的帮助文档:
[root@admin 1692]# man /etc/security/limits.conf
3.查看系统当前打开的文件描述符数量
cat /proc/sys/fs/file-nr
[root@admin ~]# cat /proc/sys/fs/file-nr
1376 0 180821
其中第一个数表示当前系统分配后以使用的文件描述符,第二个数表示分配后未使用的(看到这个值总是为0,这并不是一个错误,它意味着已经分配的文件描述符总会被使用),第三个数等于最大值file-max。
4.查看某个进程打开的文件描述符数量
lsof -p 进程号
这里我们还是查看httpd进程:
[root@admin ~]# lsof -p 1746
执行后我们发现有很多,我们可以进行统计汇总
lsof -p 进程号 | wc -l
[root@admin ~]# lsof -p 1746 | wc -l
122
看下哪些进程占用的文件描述符比较多,进行排序:
lsof -n | awk '{print $10}' | sort |uniq -c | sort -nr | head -10
每一个文件描述符会与一个打开文件相对应,同时,不同的文件描述符也会指向同一个文件。相同的文件可以被不同的进程打开也可以在同一个进程中被多次打开。系统为每一个进程维护了一个文件描述符表,该表的值都是从0开始的,所以在不同的进程中你会看到相同的文件描述符,这种情况下相同文件描述符有可能指向同一个文件,也有可能指向不同的文件。
对shell有一定了解的人都知道,管道和重定向是 Linux 中非常实用的 IPC 机制。在shell中,我们通常使用符合‘|’来表示管道,符号‘>’和‘<’表示重定向
(三)| 管道
管道的定义
管道就是一个进程与另一个进程之间通信的通道,是Linux中很重要的一种通信方式。它通常是用作把一个进程的输出通过管道连接到另一个进程的输入。它是半双工运作的,想要同时双向传输需要使用两个管道。管道又可以分为匿名管道和命名管道,而shell中使用到的是匿名管道,匿名管道只能用于具有亲缘关系的进程之间
1.进程管道
管道的本质是内存中的缓冲区,可以看作是打开到内存中的文件。所以需要使用两个文件描述符来索引它,一个表示读端,一个表示写端。并且规定,数据只能从读端读取、只能往写端写入。

用法: 命令1 | 命令2 |命令3
作用是把命令1的输出变为第二个命令的输入,把第二条命令的输出变为第三个命令的输入,之后屏幕将显示最后一条命令的运行结果。
例如命令ip a | grep ‘net’ 使用了管道来连接了两条命令来执行。
[dxk@admin ~]$ ip a | grep 'inet' #将ip a命令执行后的内容作为grep的输入进行筛选
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
inet 192.168.126.4/24 brd 192.168.126.255 scope global noprefixroute ens32
inet6 fe80::20c:29ff:fe2c:8e17/64 scope link
#grep 指令用于查找内容包含指定的范本样式的文件,如果发现某文件的内容符合所指定的范本样式,预设 grep 指令会把含有范本样式的那一列显示出来。
#若不指定任何文件名称,或是所给予的文件名为 -,则 grep 指令会从标准输入设备读取数据
2.tee管道
在数据流的处理过程中将某段信息保存下来,使其既能输出到屏幕又能保存到某一个文件中。

tee命令格式:
tee [OPTION]... [FILE]...
①从man文件的定义了解 tee从标准输入流读取数据,所以这里我们使用一个简单的命令产生输出流作为tee的输入流,这里就选用ping命令
[root@admin ~]# ping baidu.com
PING baidu.com (39.156.69.79) 56(84) bytes of data.
64 bytes from 39.156.69.79 (39.156.69.79): icmp_seq=1 ttl=128 time=31.3 ms
64 bytes from 39.156.69.79 (39.156.69.79): icmp_seq=2 ttl=128 time=30.5 ms
64 bytes from 39.156.69.79 (39.156.69.79): icmp_seq=3 ttl=128 time=31.4 ms
64 bytes from 39.156.69.79 (39.156.69.79): icmp_seq=4 ttl=128 time=31.1 ms
64 bytes from 39.156.69.79 (39.156.69.79): icmp_seq=5 ttl=128 time=31.2 ms
②现在我们希望输出到控制台的同时,将输出到控制台的内容保存到另外的文件,以便其他的用途,那么这时候tee命令就可以发挥作用了
[root@admin ~]# ping baidu.com | tee ping-baidu.log #输出到控制台的同时,将内容保存到ping-baidu.log文件中
PING baidu.com (220.181.38.148) 56(84) bytes of data.
64 bytes from 220.181.38.148 (220.181.38.148): icmp_seq=1 ttl=128 time=38.7 ms
64 bytes from 220.181.38.148 (220.181.38.148): icmp_seq=2 ttl=128 time=38.4 ms
64 bytes from 220.181.38.148 (220.181.38.148): icmp_seq=3 ttl=128 time=37.8 ms
64 bytes from 220.181.38.148 (220.181.38.148): icmp_seq=4 ttl=128 time=38.7 ms
64 bytes from 220.181.38.148 (220.181.38.148): icmp_seq=5 ttl=128 time=38.0 ms
③上面的操作中,输出到ping-baidu.log,如果这个文件存在,则先将文件里面的内容全部清除,然后再输入内容,对于某些场景下这种方式则不适合,我们希望每次的输出是追加到文件里面,这时我们可以通过-a参数来指定
tee [-a] file
-a : 以累加的方式,将数据加入file中
ping baidu.com | tee -a ping-baidu.log
(四)输入输出重定向
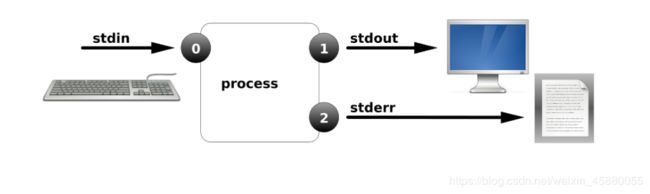
Linux提供了三种I/O设备:
标准输入(STDIN)-0默认接受来自键盘的输入
标准输出(STDOUT)-1默认输出到终端窗口
标准错误(STDERR)-2默认输出到终端窗口
1.标准输入,标准输出,标准错误

重定向就是不适用系统的标准输入端口,标准输出端口和标准错误输出端口,而进行重新的指定,所以重定向分为输入、输出和错误重定向,通常情况下重定向到一个文件。
2.输出重定向(覆盖,追加)
正确输出: 1> 1>> 等价于 > >> 输出重定向。相对于输入重定向来说,输出重定向更常用,输出重定向使用户能把一个命令的输出重定向到一个文件里,而不是显示在屏幕上,这种功能使用于多种情况,例如,如果某个命令的输出很多,在屏幕上不能完全显示,即可把他重定向到一个文件中,稍后在用文本编辑器来打开这个文件
1> 1>> 或 > >>表示将正确的输出信息重定向到一个文件中去
[root@admin ~]# date 1> date.txt
[root@admin ~]# cat date.txt
2020年 07月 09日 星期四 16:52:21 CST
[root@admin ~]#

[root@admin ~]# date >> date.txt
[root@admin ~]# cat date.txt
2020年 07月 09日 星期四 16:52:21 CST
2020年 07月 09日 星期四 16:54:52 CST

使用>或 1> 代表输以覆盖的方式出重定向到一个文件(文件之前的内容便不存在被覆盖掉)
使用>>或1>> 代表以追加的方式输出重定向到一个文件中(文件之前的内容还存在)
3.错误输出重定向: 2> 2>>
2> 2>>表示将错误信息重定向到一个文件中去
#特意给出一个错误的选项,目的是得到错误输出
[root@admin ~]# ls -T > right.txt #这里是将正确的信息重定向到文件right.txt中去
ls:选项需要一个参数 -- T
Try 'ls --help' for more information.
[root@admin ~]# cat right.txt #因为该命令未得到正确执行,自然而然该文件中没有任何内容
#那么我们想将错误信息重定向到一个文件中去该怎么做呢?
[root@admin ~]# ls -T 2> error.txt
[root@admin ~]# cat error.txt
ls:选项需要一个参数 -- T
Try 'ls --help' for more information.
#如果是 >> 表示追加到该文件中去而不是覆盖此文件。
#如果我们想将正确信息重定向到一个文件的同时将错误信息重定向到另一个文件中去,该怎么做?
[root@admin ~]# ls -T 1> right.txt 2 > error.txt #以什么方式重定向自己根据需要定
#或者这样ls -T
4.输入重定向 <
< 实现输入重定向。输入重定向不经常使用,因为大多数命令都以参数的形式在命令行上指定输入文件的文件名,尽管如此,当使用一个不接受文件名为输入参数的命令,而需要的输入又是在一个已存在的文件里,就可以使用输入重定向解决问题。
[root@admin ~]# cat < test.sh #其实就相当于 cat test.sh
name=xiaoming
echo $name
5.正确输出和错误输出都重定向到一个地方
①正确输出和错误混合输出:&> (覆盖)、&>>(追加)
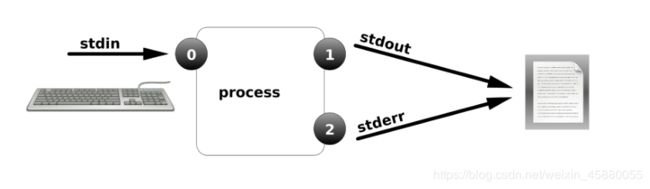
[root@admin test]# cat file1 file2 &> file3
[root@admin test]# cat file3
welcome to my CSDN!
cat: file2: 没有那个文件或目录
[root@admin test]#
②正确和错误都输入到相同位置:2>&1
例如:
date > file 2>&1 这是以覆盖的方式将正确和错误都重定向到 file文件中
date >> file 2>&1 这是以追加的方式将正确和错误都重定向到file文件中
当然,这样也可以:
date 2> file 1>&2 这是以覆盖的方式将正确和错误都重定向到 file文件中
date 2>> file 1>&2 这是以追加的方式将正确和错误都重定向到file文件中
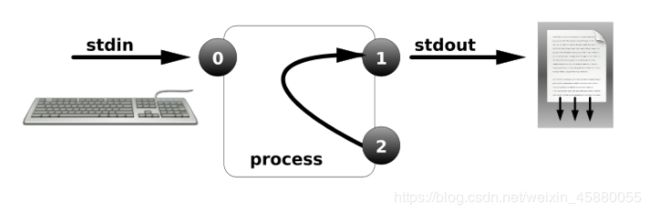
[root@admin test]# cat file1 file2 > file3 2>&1
[root@admin test]# cat file3
welcome to my CSDN!
cat: file2: 没有那个文件或目录
&>和2>&1的作用是一样的,都是将命令执行后的正确和错误信息重定向到同一个文件中
6.实践
/dev/null,它是空设备,也称为位桶(bit bucket),外号叫无底洞
你可以向它输出任何数据,它通吃,并且不会撑着!任何写入它的输出都会被抛弃。如果不想让消息以标准输出显示或写入文件,那么可以将消息重定向到位桶。
[root@admin ~]# ls ; date &> /dev/null #等价于:ls ; date > /dev/null 2>&1
anaconda-ks.cfg file test.sh
[root@admin ~]# ls &> /dev/null;date &> /dev/null #等价于:ls > /dev/null 2>&1 ;date > /dev/null 2>&1
[root@admin ~]#
[root@admin ~]# grep "root" < /etc/passwd
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
#其实就相当于:
[root@admin ~]# grep "root" /etc/passwd
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
#/dev/zero,是一个输入设备,你可你用它来初始化文件
该设备无穷尽地提供0,可以使用任何你需要的数目——设备提供的要多的多。它可以用于向设备或文件写入字符串0。
#dd命令功能是用指定大小的块拷贝一个文件,并在拷贝的同时进行指定的转换
[root@admin /]# dd if=/dev/zero of=/file1 bs=1M count=2 #从设备/dev/zero中读取数据 ,输出到/file1文件中去,块大小为1M,拷贝2块
记录了2+0 的读入
记录了2+0 的写出
2097152字节(2.1 MB)已复制,0.0182214 秒,115 MB/秒
[root@admin /]# du -h file1
2.0M file1
#我们来看一下这个文件内是什么:
[root@admin /]# vim file1
^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@
^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@
^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@
^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@
^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@
^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@
^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@
^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@
^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@
^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@
^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@
^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@
^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^
#这个时候file1已经是一个块设备不是普通的文件
#其实以上命令还可以这样写:
[root@admin /]# dd /file1 bs=1M count=2 #效果是一样的
不足之处望批评指正!