基于Hadoop生态圈的数据仓库实践 —— ETL(三)
三、使用Oozie定期自动执行ETL
1. Oozie简介
(1)Oozie是什么
Oozie是一个管理Hadoop作业、可伸缩、可扩展、可靠的工作流调度系统,其工作流作业是由一系列动作构成的有向无环图(DAGs),协调器作业是按时间频率周期性触发的Oozie工作流作业。Oozie支持的作业类型有Java map-reduce、Streaming map-reduce、Pig、 Hive、Sqoop和Distcp,及其Java程序和shell脚本等特定的系统作业。
第一版Oozie是一个基于工作流引擎的服务器,通过执行Hadoop Map/Reduce和Pig作业的动作运行工作流作业。第二版Oozie是一个基于协调器引擎的服务器,按时间和数据触发工作流执行。它可以基于时间(如每小时执行一次)或数据可用性(如等待输入数据完成后再执行)连续运行工作流。第三版Oozie是一个基于Bundle引擎的服务器。它提供更高级别的抽象,批量处理一系列协调器应用。用户可以在bundle级别启动、停止、挂起、继续、重做协调器作业,这样可以更好地简化操作控制。
(2)为什么需要Oozie
Oozie的体系结构如下图所示。
hPDL是一种很简洁的语言,只会使用少数流程控制和动作节点。控制节点会定义执行的流程,并包含工作流的起点和终点(start、end和fail节点)以及控制工作流执行路径的机制(decision、fork和join节点)。动作节点是一些机制,通过它们工作流会触发执行计算或者处理任务。Oozie为以下类型的动作提供支持: Hadoop map-reduce、Hadoop文件系统、Pig、Java和Oozie的子工作流(SSH动作已经从Oozie schema 0.2之后的版本中移除了)。
所有由动作节点触发的计算和处理任务都不在Oozie之中——它们是由Hadoop的Map/Reduce框架执行的。这种方法让Oozie可以支持现存的Hadoop用于负载平衡、灾难恢复的机制。这些任务主要是异步执行的(只有文件系统动作例外,它是同步处理的)。这意味着对于大多数工作流动作触发的计算或处理任务的类型来说,在工作流操作转换到工作流的下一个节点之前都需要等待,直到计算或处理任务结束了之后才能够继续。Oozie可以通过两种不同的方式来检测计算或处理任务是否完成,也就是回调和轮询。当Oozie启动了计算或处理任务的时候,它会为任务提供唯一的回调URL,然后任务会在完成的时候发送通知给特定的URL。在任务无法触发回调URL的情况下(可能是因为任何原因,比方说网络闪断),或者当任务的类型无法在完成时触发回调URL的时候,Oozie有一种机制,可以对计算或处理任务进行轮询,从而保证能够完成任务。
Oozie工作流可以参数化(在工作流定义中使用像${inputDir}之类的变量)。在提交工作流操作的时候,我们必须提供参数值。如果经过合适地参数化(比方说,使用不同的输出目录),那么多个同样的工作流操作可以并发。
一些工作流是根据需要触发的,但是大多数情况下,我们有必要基于一定的时间段和(或)数据可用性和(或)外部事件来运行它们。Oozie协调系统(Coordinator system)让用户可以基于这些参数来定义工作流执行计划。Oozie协调程序让我们可以以谓词的方式对工作流执行触发器进行建模,那可以指向数据、事件和(或)外部事件。工作流作业会在谓词得到满足的时候启动。
经常我们还需要连接定时运行、但时间间隔不同的工作流操作。多个随后运行的工作流的输出会成为下一个工作流的输入。把这些工作流连接在一起,会让系统把它作为数据应用的管道来引用。Oozie协调程序支持创建这样的数据应用管道。
https://www.cloudera.com/documentation/enterprise/latest/topics/cm_props_cdh570_oozie.html
2. 建立定期装载工作流
(1)修改资源配置
需要将以下两个参数的值调高:
org.apache.oozie.action.ActionExecutorException: JA009: org.apache.hadoop.yarn.exceptions.InvalidResourceRequestException: Invalid resource request, requested memory < 0, or requested memory > max configured, requestedMemory=1536, maxMemory=1500
具体做法是,从CDH Web控制台修改相关参数,保存更改并重启集群。
yarn.nodemanager.resource.memory-mb参数在YARN服务的NodeManager范围里,如下图所示。
 yarn.scheduler.maximum-allocation-mb参数在YARN服务的ResourceManager范围里,如下图所示。
yarn.scheduler.maximum-allocation-mb参数在YARN服务的ResourceManager范围里,如下图所示。
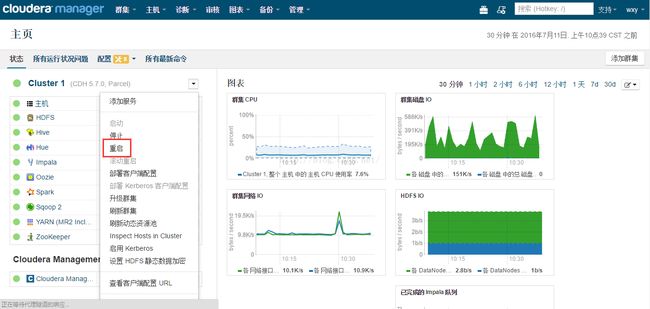
 从Web控制台重启集群的界面如下图所示。
从Web控制台重启集群的界面如下图所示。
 (2)启用Oozie Web Console
(2)启用Oozie Web Console
缺省配置时,Oozie Web Console是禁用的,为了后面方便监控Oozie作业的执行,需要将其改为启用。“启用 Oozie 服务器 Web 控制台”参数在Oozie服务的主要范围里,如下图所示。
(3)启动sqoop的share metastore service
定期装载工作流需要用Oozie调用Sqoop执行,这需要开启Sqoop元数据共享存储,命令如下:
(4)连接metastore重建sqoop job
前面建立的sqoop job,其元数据并没有存储在share metastore里,所以需要使用以下的命令重建。
(5)定义工作流
建立内容如下的workflow.xml文件:

该工作流包括9个节点,其中有5个控制节点,4个动作节点:工作流的起点(start)、终点(end)、失败处理节点(fail,DAG图中未显示),两个执行路径控制节点(fork-node和joining,fork与join节点必须成对出现),三个并行处理的Sqoop行动节点(sqoop-customer、sqoop-product、sqoop-sales_order)用作数据抽取,一个Hive行动节点(hive-node)用作数据转换与装载。
(6)部署工作流
建立内容如下的job.properties文件:
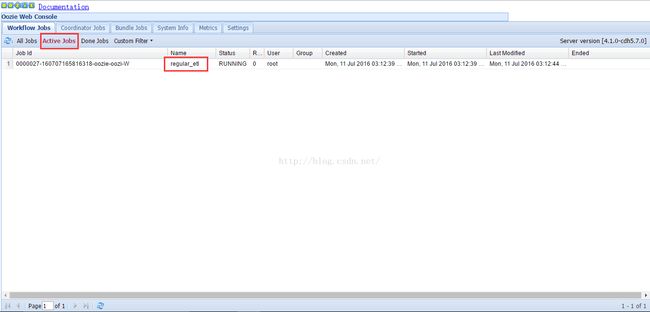 点击作业所在行,可以打开作业的详细信息窗口,如下图所示。
点击作业所在行,可以打开作业的详细信息窗口,如下图所示。
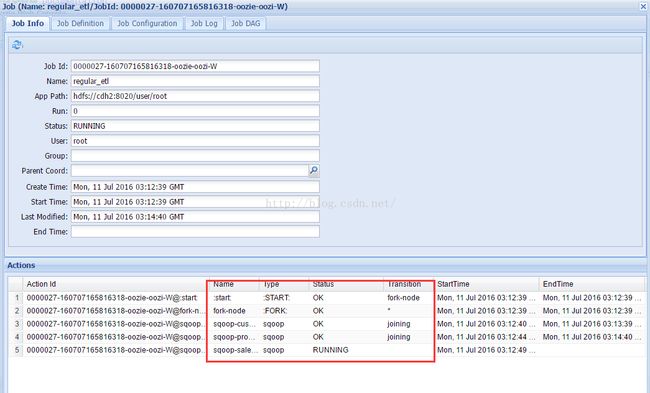 点击动作所在行,可以打开动作的详细信息窗口,如下图所示。
点击动作所在行,可以打开动作的详细信息窗口,如下图所示。
 可以点击Console URL右侧的图标,可以打开Map/Reduce作业的跟踪窗口,如下图所示。
可以点击Console URL右侧的图标,可以打开Map/Reduce作业的跟踪窗口,如下图所示。
 当Oozie作业执行完,可以在“All Jobs”标签页看到,Status列已经从RUNNING变为SUCCEEDED,如下图所示。
当Oozie作业执行完,可以在“All Jobs”标签页看到,Status列已经从RUNNING变为SUCCEEDED,如下图所示。
 此时查看cdc_time表的数据,可以看到日期已经改为当前日期,如下图所示。
此时查看cdc_time表的数据,可以看到日期已经改为当前日期,如下图所示。

3. 建立协调作业定期自动执行工作流
(1)建立协调作业属性文件
建立内容如下的job-coord.properties文件:
建立内容如下的coordinator.xml文件:
 此协调作业自2016年7月11日开始,每天14点执行一次。结束日期非常晚,这里设置的是2020年12月31日。需要注意一下时区的设置。Oozie默认的时区是UTC,而且即便在属性文件中设置了timezone=GMT+0800也不起作用,所以start属性设置的是06:00,实际就是北京时间14:00。
此协调作业自2016年7月11日开始,每天14点执行一次。结束日期非常晚,这里设置的是2020年12月31日。需要注意一下时区的设置。Oozie默认的时区是UTC,而且即便在属性文件中设置了timezone=GMT+0800也不起作用,所以start属性设置的是06:00,实际就是北京时间14:00。
当时间到达14:00时,协调作业开始运行,状态由PREP变为RUNNING,如下图所示。
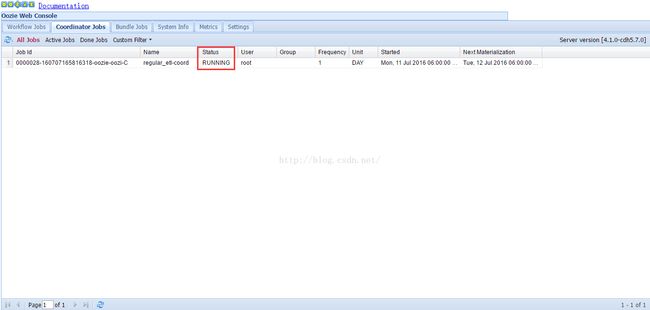 点击作业所在行,可以打开协调作业的详细信息窗口,如下图所示。
点击作业所在行,可以打开协调作业的详细信息窗口,如下图所示。
 点击协调作业所在行,可以打开工作流作业的详细信息窗口,如下图所示。
点击协调作业所在行,可以打开工作流作业的详细信息窗口,如下图所示。
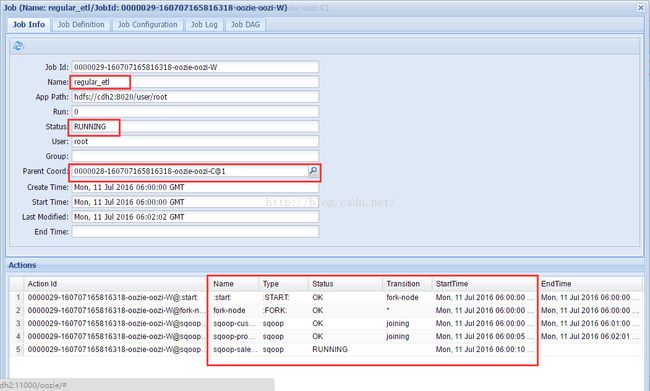 点击动作所在行,可以打开动作的详细信息窗口,如下图所示。
点击动作所在行,可以打开动作的详细信息窗口,如下图所示。
 可以点击Console URL右侧的图标,可以打开Map/Reduce作业的跟踪窗口,如下图所示。
可以点击Console URL右侧的图标,可以打开Map/Reduce作业的跟踪窗口,如下图所示。
 至此介绍了使用Oozie定期自动执行ETL的一般方法。Oozie 4.1.0的官方文档链接地址如下: http://oozie.apache.org/docs/4.1.0/index.html
至此介绍了使用Oozie定期自动执行ETL的一般方法。Oozie 4.1.0的官方文档链接地址如下: http://oozie.apache.org/docs/4.1.0/index.html
1. Oozie简介
(1)Oozie是什么
Oozie是一个管理Hadoop作业、可伸缩、可扩展、可靠的工作流调度系统,其工作流作业是由一系列动作构成的有向无环图(DAGs),协调器作业是按时间频率周期性触发的Oozie工作流作业。Oozie支持的作业类型有Java map-reduce、Streaming map-reduce、Pig、 Hive、Sqoop和Distcp,及其Java程序和shell脚本等特定的系统作业。
第一版Oozie是一个基于工作流引擎的服务器,通过执行Hadoop Map/Reduce和Pig作业的动作运行工作流作业。第二版Oozie是一个基于协调器引擎的服务器,按时间和数据触发工作流执行。它可以基于时间(如每小时执行一次)或数据可用性(如等待输入数据完成后再执行)连续运行工作流。第三版Oozie是一个基于Bundle引擎的服务器。它提供更高级别的抽象,批量处理一系列协调器应用。用户可以在bundle级别启动、停止、挂起、继续、重做协调器作业,这样可以更好地简化操作控制。
(2)为什么需要Oozie
- 在Hadoop中执行的任务有时候需要把多个Map/Reduce作业连接到一起执行,或者需要多个作业并行处理。Oozie可以把多个Map/Reduce作业组合到一个逻辑工作单元中,从而完成更大型的任务。
- 从调度的角度看,如果使用crontab的方式调用多个工作流作业,可能需要编写大量的脚本,还要通过脚本来控制好各个工作流作业的执行时序问题,不但脚本不好维护,而且监控也不方便。基于这样的背景,Oozie提出了Coordinator的概念,它能够将每个工作流作业作为一个动作来运行,相当于工作流定义中的一个执行节点,这样就能够将多个工作流作业组成一个称为Coordinator Job的作业,并指定触发时间和频率,还可以配置数据集、并发数等。
Oozie的体系结构如下图所示。

Oozie是一种Java Web应用程序,它运行在Java servlet容器——即Tomcat——中,并使用数据库来存储以下内容:
- 工作流定义
- 当前运行的工作流实例,包括实例的状态和变量
hPDL是一种很简洁的语言,只会使用少数流程控制和动作节点。控制节点会定义执行的流程,并包含工作流的起点和终点(start、end和fail节点)以及控制工作流执行路径的机制(decision、fork和join节点)。动作节点是一些机制,通过它们工作流会触发执行计算或者处理任务。Oozie为以下类型的动作提供支持: Hadoop map-reduce、Hadoop文件系统、Pig、Java和Oozie的子工作流(SSH动作已经从Oozie schema 0.2之后的版本中移除了)。
所有由动作节点触发的计算和处理任务都不在Oozie之中——它们是由Hadoop的Map/Reduce框架执行的。这种方法让Oozie可以支持现存的Hadoop用于负载平衡、灾难恢复的机制。这些任务主要是异步执行的(只有文件系统动作例外,它是同步处理的)。这意味着对于大多数工作流动作触发的计算或处理任务的类型来说,在工作流操作转换到工作流的下一个节点之前都需要等待,直到计算或处理任务结束了之后才能够继续。Oozie可以通过两种不同的方式来检测计算或处理任务是否完成,也就是回调和轮询。当Oozie启动了计算或处理任务的时候,它会为任务提供唯一的回调URL,然后任务会在完成的时候发送通知给特定的URL。在任务无法触发回调URL的情况下(可能是因为任何原因,比方说网络闪断),或者当任务的类型无法在完成时触发回调URL的时候,Oozie有一种机制,可以对计算或处理任务进行轮询,从而保证能够完成任务。
Oozie工作流可以参数化(在工作流定义中使用像${inputDir}之类的变量)。在提交工作流操作的时候,我们必须提供参数值。如果经过合适地参数化(比方说,使用不同的输出目录),那么多个同样的工作流操作可以并发。
一些工作流是根据需要触发的,但是大多数情况下,我们有必要基于一定的时间段和(或)数据可用性和(或)外部事件来运行它们。Oozie协调系统(Coordinator system)让用户可以基于这些参数来定义工作流执行计划。Oozie协调程序让我们可以以谓词的方式对工作流执行触发器进行建模,那可以指向数据、事件和(或)外部事件。工作流作业会在谓词得到满足的时候启动。
经常我们还需要连接定时运行、但时间间隔不同的工作流操作。多个随后运行的工作流的输出会成为下一个工作流的输入。把这些工作流连接在一起,会让系统把它作为数据应用的管道来引用。Oozie协调程序支持创建这样的数据应用管道。
(4)CDH 5.7.0中的Oozie
CDH 5.7.0中,Oozie的版本是4.1.0,元数据存储使用MySQL。关于CDH 5.7.0中Oozie的属性,参考以下链接:https://www.cloudera.com/documentation/enterprise/latest/topics/cm_props_cdh570_oozie.html
2. 建立定期装载工作流
(1)修改资源配置
需要将以下两个参数的值调高:
yarn.nodemanager.resource.memory-mb = 2000
yarn.scheduler.maximum-allocation-mb = 2000org.apache.oozie.action.ActionExecutorException: JA009: org.apache.hadoop.yarn.exceptions.InvalidResourceRequestException: Invalid resource request, requested memory < 0, or requested memory > max configured, requestedMemory=1536, maxMemory=1500
具体做法是,从CDH Web控制台修改相关参数,保存更改并重启集群。
yarn.nodemanager.resource.memory-mb参数在YARN服务的NodeManager范围里,如下图所示。
缺省配置时,Oozie Web Console是禁用的,为了后面方便监控Oozie作业的执行,需要将其改为启用。“启用 Oozie 服务器 Web 控制台”参数在Oozie服务的主要范围里,如下图所示。

具体的做法是:
- 下载安装ext-2.2。
- 从CDH Web控制台修改相关参数,保存更改并重启Oozie服务。
(3)启动sqoop的share metastore service
定期装载工作流需要用Oozie调用Sqoop执行,这需要开启Sqoop元数据共享存储,命令如下:
sqoop metastore > /tmp/sqoop_metastore.log 2>&1 &(4)连接metastore重建sqoop job
前面建立的sqoop job,其元数据并没有存储在share metastore里,所以需要使用以下的命令重建。
last_value=`sqoop job --show myjob_incremental_import | grep incremental.last.value | awk '{print $3}'`
sqoop job --delete myjob_incremental_import
sqoop job \
--meta-connect jdbc:hsqldb:hsql://cdh2:16000/sqoop \
--create myjob_incremental_import \
-- \
import \
--connect "jdbc:mysql://cdh1:3306/source?useSSL=false&user=root&password=mypassword" \
--table sales_order \
--columns "order_number, customer_number, product_code, order_date, entry_date, order_amount" \
--hive-import \
--hive-table rds.sales_order \
--incremental append \
--check-column order_number \
--last-value $last_value(5)定义工作流
建立内容如下的workflow.xml文件:
${jobTracker}
${nameNode}
import
--connect
jdbc:mysql://cdh1:3306/source?useSSL=false
--username
root
--password
mypassword
--table
customer
--hive-import
--hive-table
rds.customer
--hive-overwrite
/tmp/hive-site.xml#hive-site.xml
/tmp/mysql-connector-java-5.1.38-bin.jar#mysql-connector-java-5.1.38-bin.jar
${jobTracker}
${nameNode}
import
--connect
jdbc:mysql://cdh1:3306/source?useSSL=false
--username
root
--password
mypassword
--table
product
--hive-import
--hive-table
rds.product
--hive-overwrite
/tmp/hive-site.xml#hive-site.xml
/tmp/mysql-connector-java-5.1.38-bin.jar#mysql-connector-java-5.1.38-bin.jar
${jobTracker}
${nameNode}
job --exec myjob_incremental_import --meta-connect jdbc:hsqldb:hsql://cdh2:16000/sqoop
/tmp/hive-site.xml#hive-site.xml
/tmp/mysql-connector-java-5.1.38-bin.jar#mysql-connector-java-5.1.38-bin.jar
${jobTracker}
${nameNode}
/tmp/hive-site.xml
Sqoop failed, error message[${wf:errorMessage(wf:lastErrorNode())}]
该工作流包括9个节点,其中有5个控制节点,4个动作节点:工作流的起点(start)、终点(end)、失败处理节点(fail,DAG图中未显示),两个执行路径控制节点(fork-node和joining,fork与join节点必须成对出现),三个并行处理的Sqoop行动节点(sqoop-customer、sqoop-product、sqoop-sales_order)用作数据抽取,一个Hive行动节点(hive-node)用作数据转换与装载。
(6)部署工作流
hdfs dfs -put -f workflow.xml /user/root/
hdfs dfs -put /etc/hive/conf.cloudera.hive/hive-site.xml /tmp/
hdfs dfs -put /root/mysql-connector-java-5.1.38/mysql-connector-java-5.1.38-bin.jar /tmp/
hdfs dfs -put /root/regular_etl.sql /tmp/建立内容如下的job.properties文件:
nameNode=hdfs://cdh2:8020
jobTracker=cdh2:8032
queueName=default
oozie.use.system.libpath=true
oozie.wf.application.path=${nameNode}/user/${user.name}oozie job -oozie http://cdh2:11000/oozie -config /root/job.properties -run3. 建立协调作业定期自动执行工作流
(1)建立协调作业属性文件
建立内容如下的job-coord.properties文件:
nameNode=hdfs://cdh2:8020
jobTracker=cdh2:8032
queueName=default
oozie.use.system.libpath=true
oozie.coord.application.path=${nameNode}/user/${user.name}
timezone=UTC
start=2016-07-11T06:00Z
end=2020-12-31T07:15Z
workflowAppUri=${nameNode}/user/${user.name}建立内容如下的coordinator.xml文件:
${workflowAppUri}
jobTracker
${jobTracker}
nameNode
${nameNode}
queueName
${queueName}
hdfs dfs -put -f coordinator.xml /user/root/oozie job -oozie http://cdh2:11000/oozie -config /root/job-coord.properties -run当时间到达14:00时,协调作业开始运行,状态由PREP变为RUNNING,如下图所示。