Android HTTP编程基础
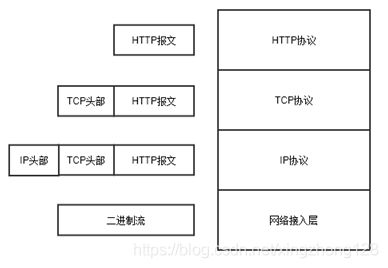
HTTP协议是一种请求响应式通信协议,通常是客户端向服务器端发送资源请求,服务器接收到客户端请求后返回对应资源响应,两端不断重复请求响应的过程就完成了客户端与服务器端的会话操作。HTTP是运行与TCP协议之上的应用层协议,它定义自己独特的报文格式,HTTP报文在网络发送时传输层使用了TCP协议,TCP协议重传和确认机制能够确保HTTP报文到达接收端,因而HTTP协议是一种可靠的数据传输协议。
HTTP报文
为了方便查看HTTP报文笔者搭建了简单的JSP/Servlet网络应用HttpServer并且部署在Tomcat服务器上,在应用的根路径下有一个简单的index.jsp文件。Charles网络抓包工具能够抓取本机发送和接收到的HTTP网络数据,这里就使用Charles抓包工具来查看浏览器请求index.jsp文件发送的HTTP报文。
GET /HttpServer/index.jsp HTTP/1.1
Host: 192.168.137.240:8080
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML,
like Gecko) Chrome/69.0.3497.100 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,
image/webp,image/apng,*/*;q=0.8
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
Cookie: JSESSIONID=FBD78F118328969D843751AAD84162CB;
_ga=GA1.1.2124913443.1537969664; jenkins-timestamper-offset=-28800000
在发送报文分成三个部分,第一行的请求行,中间的请求头部分和最后的请求体部分,index.jsp的请求报文并不包含请求体部分,后面章节讨论请求方式的时候会重点讲解请求体。
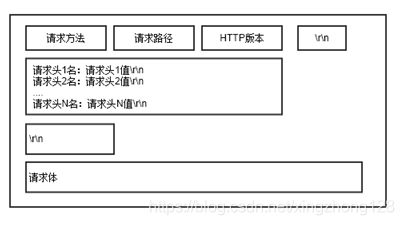
请求行的GET代表请求获取服务器上的资源,资源的路径在服务器的/HttpServer/index.jsp路径下,HTTP/1.1本次请求使用的HTTP版本是1.1版本。HTTP的资源请求方式除了GET获取,用的最多的就是POST代表向服务器发送数据,其他还有五种请求方式相对来说使用的较少。
| HTTP请求方式 | 备注 |
|---|---|
| GET | 请求服务器发送资源 |
| HEAD | 请求服务器资源,但不返回资源实体,只返回资源相关的头部 |
| POST | 向服务器发送数据的,HTTP中最常见的数据交互方式 |
| PUT | 请求服务器用请求的主体部分来创建资源,相当于上传主体数据 |
| TRACE | 用于获取请求经过的网络路径信息 |
| OPTIONS | 获取服务器支持的操作信息 |
| DELETE | 请求服务器删除请求URL所指定的资源 |
在请求头下面的多条键值对形式存在的头部用来描述本次请求的属性,Host代表服务器对象的IP地址和端口号,User-Agent代表使用的浏览器类型,Accept-*开头的头部表明本次请求支持返回的数据类型、编码和语言。最后一个Cookie代表本次HTTP请求客户端保存的Cookie信息,里面有三个键值对,重点看一下JSESSIONID键值对。HTTP协议属于无状态协议,所谓的无状态是指在HTTP协议本身并不会记录之前处理的信息,如果后续的请求需要在之前的信息上做处理,那么旧的数据必须重新传递给服务器端,重传之前数据会导致资源浪费和效率低下,现代的HTTP客户端会使用Cookie来保存之前的状态信息,而服务器端会在Session对象中保存信息。Tomcat服务器内部就是用JSESSIONID值来代表同一个会话Session对象,只要客户端请求里带了相同的JSESSIONID Cookie值这些请求就属于同一个会话,它们就可以共用键值为JSESSIONID的Session中的数据。
HTTP/1.1 200 OK
Server: Apache-Coyote/1.1
Content-Type: text/html;charset=UTF-8
Content-Length: 64
Date: Sat, 04 May 2019 10:17:30 GMT
Connection: Keep-alive
Insert title here
接着查看Tomcat服务器返回的index.jsp响应报文,响应报文也包含了三个部分,第一行的响应结果行,接着是多个键值对组成的响应头部,响应头部下方就是服务器返回的HTML内容。

响应结果行里的状态码和状态描述说明本次请求的响应结果,200代表请求响应成功,OK只是简单的文本描述,HTTP定义多个响应状态值,它们主要分成了五个区间。
| HTTP响应码 | 含义 |
|---|---|
| 100~199 | 消息型状态码 |
| 200~299 | 成功型状态码,通常表示本次请求成功或部分成功 |
| 300~399 | 重定向状态码,访问的资源位置发生变化 |
| 400~499 | 客户端错误状态码 |
| 500~599 | 服务器错误状态码 |
其中重定向状态码代表客户端请求的资源位置发生变化,通常会返回Location消息头中包含新的资源位置,比如访问百度网站直接发送HTTP百度服务器就会要求用户浏览器重定向到HTTPS连接地址。
HTTP/1.1 302 Moved Temporarily
Location: https://www.baidu.com/
在响应头部分以Content-开头的头部是描述响应体类型的,index.jsp的类型就是text/html长度为64个字节,Date代表本次响应发生的时间。Connection头部代表要保持本次连接,不要立即将本次请求响应的网络连接断掉。在老版本的HTTP协议中客户端和服务器完成一次请求响应就会断掉之前的连接,下一次再做请求响应就重新创建连接,网络连接的创建相对来说是非常耗时的,这种断开重连的方式对服务器和网络都会产生性能消耗,在新版本的HTTP中允许一次请求响应后保持连接方便后续的操作复用之前的连接。
请求和响应报文中的头部主要用来增加一些附加信息,头部主要分成四种:请求头部,也就是只会在请求报文中出现的头部;响应头部,只会在响应报文中出现的头部;通用头部,既能在请求报文也可以在响应报文中出现的头部;实体头部,主要使用来描述请求体或者响应体里面的实体对象信息的。
请求方式
HTTP协议中的请求方式多种多样,不过在实际开发中最常用的请求方式主要有GET、POST和HEADER三种方式,现在就通过Android中的HttpUrlConnnection网络接口和Tomcat服务器上部署的基于JSP/Servlet开发的HttpServer服务来学习上面三种请求方式的报文格式。
GET请求方式顾名思义就是从服务器获取内容,在HTTP报文节贴出的是GET方式正常的index.jsp资源的请求和响应报文,有时服务器端的资源位置发生了变化,客户端如果继续使用资源以前的位置发送请求服务器可以通过返回302状态码并且附上Location头告知客户端向新的地址发送请求。
// HTTP GET网络请求
HttpURLConnection httpURLConnection =
(HttpURLConnection) new URL(getUrl).openConnection();
httpURLConnection.setRequestMethod("GET"); // 设置请求方式为GET
httpURLConnection.setConnectTimeout(3000); // 设置连接超时时间为3秒
httpURLConnection.setReadTimeout(3000); // 设置读取数据超时时间为3秒
httpURLConnection.setDoInput(true); // 本次请求可以做输入操作
httpURLConnection.setDoOutput(false); // 本次请求不需要做输入操作
httpURLConnection.setInstanceFollowRedirects(true); // 支持请求Http重定向
httpURLConnection.getResponseCode(); // 等待返回响应码
printHeads(httpURLConnection.getHeaderFields()); // 打印响应报文头部
InputStream inputStream = httpURLConnection.getInputStream(); // 读取响应体数据
ByteArrayOutputStream bos = new ByteArrayOutputStream();
byte[] buf = new byte[1024];
int len = -1;
// 把响应体中的数据读取到bos输出流的内存中
while ((len = inputStream.read(buf)) != -1) {
bos.write(buf, 0, len);
}
String text = new String(bos.toByteArray(), "UTF-8");
Log.e(TAG, text); // 输出响应体内容
httpURLConnection.disconnect(); // 断开网络连接
需要注意高版本的Android中不允许在主线程执行网络请求,需要开发者把网络请求放到子线程中执行,在Android中调用上面的代码并且用Charles抓包会看到两个HTTP请求和两个HTTP响应,报文中一些不重要的头部没有贴出来。
// 第一次请求hello.html请求报文
GET /HttpServer/hello.html HTTP/1.1
Host: 10.2.129.168:8080
// 响应第一次请求302响应报文
HTTP/1.1 302 Found
Server: Apache-Coyote/1.1
Location: /HttpServer/newPath.jsp
// 重定向后再发起第二次请求报文
GET /HttpServer/newPath.jsp HTTP/1.1
Host: 10.2.129.168:8080
// 响应第二次请求的响应报文
HTTP/1.1 200 OK
Server: Apache-Coyote/1.1
Set-Cookie: JSESSIONID=B6B446A8A09978AE57B7FBBBEF3E96F0;
Path=/HttpServer; HttpOnly
Content-Type: text/html;charset=ISO-8859-1
Content-Length: 276
Date: Fri, 17 May 2019 07:21:04 GMT
Connection: Keep-alive
....
可以看到在第一次响应返回的状态码是302,Location头部资源新的路径 /HttpServer/newPath.jsp,随后HttpURLConnection内部解析出Location值并且发送新的请求,新的响应报文内部就包含了资源数据。在第二次返回的报文中包含了Set-Cookie响应头,它的值包含了三个Cookie键值对数据,Cookie之间使用分号分割,键值对之间使用等于号分割,想要保存JSESSIONID需要对键值对做分割操作,保存下来的sessionId可以在下次请求时带上,Tomcat服务器把具有相同sessionId的请求视作同一个会话,它们之间可以共享保存在服务器上的Session会话数据。
// 解析报文头JSESSIONID信息
private void printHeads(Map> headerFields) {
for (Map.Entry> entry : headerFields.entrySet()) {
if ("set-cookie".equalsIgnoreCase(entry.getKey())) {
List cookies = entry.getValue();
for (String cookie : cookies) {
if (cookie.contains("JSESSIONID")) {
sessionId = cookie.split("=")[1];
}
}
}
}
}
HttpURLConnection在初始化的时候设置了连接超时和读取超时两个属性,它们有什么区别呢?HTTP应用层协议实际上是运行在传输层的TCP协议之上的,TCP在建立连接的时候会有三次握手的过程,只有客户端和服务端都进行了三次握手才真正建立起TCP连接,三次握手过程耗费的时间对应的就是连接超时设置时间,Wireshark截图前三条TCP报文正是TCP建立连接发送的SYN和ACK报文。在连接建立之后两端才开始真正的发送数据,服务器的数据在网络上传输由于网络的质量的问题需要消耗一定的时间,读取超时对应的就是数据传输时间。
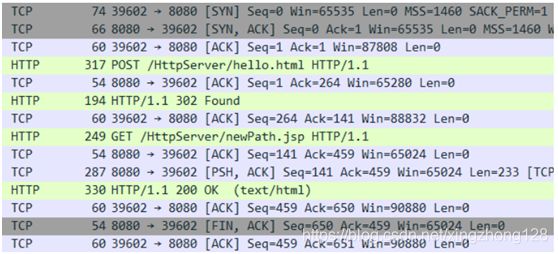
HTTP网络通信的底层是Socket对象,它能够支持全双工通信方式,也就是既能发送数据也可以接收数据,setDoInput()设置是否支持读取网络数,setDoOuput()则设置是否支持写入网络数据,只有设置支持输入时HttpURLConnection.getInputStream()返回的输入流才是有效的,同理设置支持输出时HttpURLConnection.getOutputStream()返回的输出流才是有效的。输入和输出流对象写入的数据都是放在请求报文体里面的,请求报文的头部信息写入需要使用HttpURLConnection.addRequestProperty(String header, String value)方法实现,而响应报文的头部读取需要用HttpURLConnection.getHeaderFields()方法。POST请求方式支持向服务器端发送数据,GET发送的数据一定要放在请求行的路径里,POST发送的数据既可以放在请求路径里也可以放到请求体中。
// 发起HTTP POST请求
httpURLConnection.setDoOutput(true); // 支持输出数据
// 其他配置同HTTP GET请求
if (!TextUtils.isEmpty(sessionId)) { // 添加cookie请求头部
httpURLConnection.addRequestProperty("cookie", "JSESSIONID=" + sessionId);
}
OutputStream outputStream = httpURLConnection.getOutputStream();
outputStream.write("name=xxx&password=abcd1234".getBytes("UTF-8"));
outputStream.flush(); // 在请求体里写入请求参数
上面的代码省略了HttpURLConnection初始化配置和最后的数据读取操作,它们和前面的GET请求方式大体相似,不过再请求发送之前添加了Cookie请求头并且在请求体里添加请求参数,执行上面的POST请求方法代码,查看Charles抓包的结果。
// POST请求报文
POST /HttpServer/unsafelogin HTTP/1.1
Content-Type: application/x-www-form-urlencoded
User-Agent: Dalvik/2.1.0 (Linux; U; Android 8.1.0; Nexus 6 Build/OPM7.181005.003)
Host: 10.2.129.168:8080
Connection: Keep-Alive
Accept-Encoding: gzip
Content-Length: 26
name=xxx&password=abcd1234
// POST响应报文
HTTP/1.1 200 OK
Server: Apache-Coyote/1.1
Set-Cookie: JSESSIONID=D235C4074E6035F04FEAF7C6489725FF;
Path=/HttpServer; HttpOnly
Date: Fri, 17 May 2019 08:07:41 GMT
Transfer-Encoding: chunked
Proxy-Connection: Keep-alive
{"code":0,"data":{"age":20,"name":"xxx","sex":"Female"},"msg":"login success"}
请求报文包含了Content-Type: application/x-www-form-urlencoded请求头,它代表请求体中的数据是普通的请求参数类型,在请求头部下面会有一行空白行,空白行后面的就是请求体内容,正式前面代码中写入的请求参数。响应报文包含了Set-Cookie响应头和响应体数据,通过数据可知本次登录成功。不过这种使用HTTP协议做登录其实是非常不安全的,后面会介绍使用HTTPS协议实现登录。在代码中会保存下此次登录成功返回的JSESSIONID,接着再执行一次登录请求。
POST /HttpServer/unsafelogin HTTP/1.1
cookie: JSESSIONID=54FC1377AA128CD8CB91D73AC5C866CA; Path
Content-Type: application/x-www-form-urlencoded
User-Agent: Dalvik/2.1.0 (Linux; U; Android 8.1.0; Nexus 6 Build/OPM7.181005.003)
Host: 10.2.129.168:8080
Connection: Keep-Alive
Accept-Encoding: gzip
Content-Length: 26
name=xxx&password=abcd1234
HTTP/1.1 200 OK
Server: Apache-Coyote/1.1
Date: Fri, 17 May 2019 08:20:29 GMT
Transfer-Encoding: chunked
Proxy-Connection: Keep-alive
{"code":-10,"data":{"age":20,"name":"xxx","sex":"Female"},"msg":"alreay login!!!"}
可以看到由于保存过上一次的返回的JSESSIONID,本次请求头中增加了cookie请求头,服务器端会认为两次请求属于同一个会话,根据会话中保存的登录信息返回用户已经登录的响应数据。POST除了能够传递简单的键值对参数数据,还可以实现文件上传功能,不过此时需要使用的请求头Content-Type需要是multipart/form-data类型,为了查看上传文件的报文结构,可以使用Android第三方OkHttp框架来实现上传操作,通过Charles抓包工具观察请求响应报文。
// OkHttp实现文件上传
OkHttpClient okHttpClient = new OkHttpClient();
RequestBody requestBody = RequestBody.create(MediaType.parse("image/png"),
new File("ic_launcher.png"));
MultipartBody body = new MultipartBody.Builder()
.setType(MultipartBody.FORM)
.addFormDataPart("filename", "ic_launcher.png", requestBody)
.addFormDataPart("name", "xxx")
.build();
Request request = new Request.Builder()
.url("http://10.2.129.168:8080/HttpServer/upload ")
.post(body)
.build();
try {
Response response = okHttpClient.newCall(request).execute();
if (response.isSuccessful()) {
System.out.println(response.body().string());
}
} catch (IOException e) {
e.printStackTrace();
}
执行上面的上传文件代码后观察上传请求和响应报文,请求报文的Content-Type头部还定义了一个boundary请求体数据分隔符,它的值是随机的,不是固定的值。请求体会以两个横杠加boundary开头,接着是Content-Disposition描述参数的名称和文件名,如果是文件类型还有Content-Type描述文件类型,Content-Length指明参数值的长度。每个参数之间都是用双横杠加boundary分割,在最后一个参数的结尾处还需要添加左右都有两个横杠的boundary代表数据结束。
// 上传请求报文
POST /HttpServer/upload HTTP/1.1
Content-Type: multipart/form-data; boundary=71f62f86-7932-4ba5-bdb9-0deda48ef376
Transfer-Encoding: chunked
Host: 10.2.129.168:8080
Connection: Keep-Alive
Accept-Encoding: gzip
User-Agent: okhttp/3.10.0
--71f62f86-7932-4ba5-bdb9-0deda48ef376 // 参数之间的边界只有开头有两条横线
Content-Disposition: form-data; name="filename"; filename="ic_launcher.png"
Content-Type: image/png
Content-Length: 52586
.....
--71f62f86-7932-4ba5-bdb9-0deda48ef376 // 参数之间的边界只有开头有两条横线
Content-Disposition: form-data; name="name"
Content-Length: 3
xxx
--71f62f86-7932-4ba5-bdb9-0deda48ef376-- // 结束的边界前后都有两个横线
了解了上传文件请求报文的格式就可以使用HttpURLConnection来实现上传文件功能,只要正确的设置了Content-Type请求头,请求体的内容正确拼接在一起就能够将文件上传到服务器。下面的代码通过生成和代OkHttp下载请求相同的报文向服务器端发送上传文件HTTP请求,测试能够正常执行。
// 文件上传实现
// 设置Content-Type请求头
String boundary = "71f62f86-7932-4ba5-bdb9-0deda48ef376";
httpURLConnection.addRequestProperty("Content-Type",
"multipart/form-data; boundary=" + boundary);
// 拼接上传文件请求体
OutputStream outputStream = httpURLConnection.getOutputStream();
// 添加文件参数
StringBuilder builder = new StringBuilder("--" + boundary);
builder.append("\r\n");
builder
.append("Content-Disposition: form-data; name=\"filename\";filename=\"hello.mp4\"")
.append("\r\n");
.append("Content-Type: video/mp4").append("\r\n");
byte[] buf = new byte[1024];
InputStream data = getAssets().open("swim.mp4");
builder.append("Content-Length: ").append(data.available()).append("\r\n");
builder.append("\r\n");
outputStream.write(builder.toString().getBytes("UTF-8"));
// 向方法体写入文件内容
int dataLen = -1;
while ((dataLen = data.read(buf)) != -1) {
outputStream.write(buf, 0, dataLen);
}
outputStream.write("\r\n".getBytes("UTF-8"));
// 写入结尾边界符
outputStream.write(("--" + boundary + "--").getBytes("UTF-8"));
outputStream.flush();
既然有了上传文件功能,自然也需要有下载文件的功能,下载文件完全可以使用GET请求方式,下载文件和普通的请求资源实现完全一致,不过鉴于文件内容可能比较大HTTP协议提供了Range请求头,也就是说只请求文件的一部分数据,在断点续传和多线程下载中通常都会使用到。
HEAD请求只会返回请求结果的响应头,它在多线程下载的时候通常非常有用,需要注意的是HEAD请求一定不要启用输出数据的选项,HTTP协议开发者认为如果需要输出数据建议使用POST请求类型,因此如果在HttpURLConnection做HEAD请求启用setDoOutput(true)就会抛出异常。
// HEAD请求实现
// 设置setDoOutput(true)抛出java.net.ProtocolException:
// HEAD does not support writing
httpURLConnection.setRequestMethod("HEAD"); // 设置HEAD请求方式
httpURLConnection.setDoInput(true);
httpURLConnection.setDoOutput(false);
httpURLConnection.getResponseCode();
// 其他与GET配置相同
// 查看Charles抓包结果看到下载文件时只返回了响应头部分,文件内容并没有随之返回,
// 在响应头里包含了要下载文件的描述信息和文件长度Content-Length。
// HEAD请求报文
HEAD /HttpServer/download?filename=sport.mp4 HTTP/1.1
User-Agent: Dalvik/2.1.0 (Linux; U; Android 8.1.0; Nexus 6 Build/OPM7.181005.003)
Host: 192.168.137.240:8080
Connection: Keep-Alive
Accept-Encoding: gzip
// HEAD响应报文,只有头部信息,没有响应体
HTTP/1.1 200 OK
Server: Apache-Coyote/1.1
Content-Disposition: attachment; filename=sport.mp4
Content-Type: video/mp4
Content-Length: 1898889
Date: Fri, 17 May 2019 13:55:09 GMT
Connection: Keep-alive
在了解Content-Length之前需要了解HTTP的连接持久化概念,HTTP连接工作在TCP协议之上,TCP在建立连接过程中需要三次握手, 如果连接不成功还需要执行慢启动,因而建立TCP连接是比较耗时的操作。在HTTP旧版本上一次请求响应操作就执行一次TCP连接建立和断开,这种连接方式被称作短连接,所谓的持久化连接其实就是长连接,HTTP一次请求响应后不会直接断开连接,下一次请求数据时直接复用已有的长连接,长连接的数据发送效率更高。
多个响应数据在长连接上发送会出现响应数据边界无法确定的问题,为了解决响应边界问题HTTP在响应头中增加了Content-Length头部,客户端在读取数据时只要读够了Content-Length长度的数据就代表本次响应数据读取完成。Content-Length的值必须是精确的,如果返回的数据不是服务器本地数据,还需要到其他的网络上获取数据,服务器端就必须把所有的数据都读取回来,最后设置正确的Content-Length值返回给客户端。很显然如果请求的数据比较大,服务器端等到数据请求完成才向客户端发送响应,客户端请求和响应的时间过长,用户体验非常的差。
为了解决长连接大数据传输响应慢的问题,HTTP提供了分块传输机制,响应头Transfer-Encoding: chunked就代表服务器端开启的分块传输机制,分块传输会将数据分成多个块,每个块包含一个块数据长度和块数据,最后一个块长度必须为0代表整个数据传输完成。分块传输内部会增加长度字段,实际上传递的数据长度不能确定,因此Content-Length和Transfer-Encoding: chunked是互斥出现的。
多线程下载
服务器端本地的文件通常都可以获取它们的长度值,不需要使用分块传输技术,只使用一个线程下载大文件会比较慢,客户端此时可以开启多个线程同时下载文件。多线程下载首先需要通过HEAD请求得到要下载文件的长度,之后为每个线程分配下载的数据区间,每个线程内部采用POST请求方式下载文件数据。

为每个线程分配好下载区间值后用POST请求方式下载数据,同时增加Range请求头指定要下载数据的区间,服务器端会读取区间数据并返回区间数据,客户端使用RandomAccessFile接收区间数据并且写入文件中,由于多个线程写入的文件区间不同实际上并不存在共享数据问题,也就不需要考虑线程安全问题。
// HTTP多线程下载
// 开启资源HEAD请求
httpURLConnection.setRequestMethod("HEAD");
httpURLConnection.setDoInput(true);
httpURLConnection.setDoOutput(false);
httpURLConnection.getResponseCode();
int contentLength = httpURLConnection.getContentLength();
httpURLConnection.disconnect();
int size = contentLength / 4; // 开启四个线程,计算平均每个线程下载的长度值,可能有余数
for (int i = 0; i < 4; i++) {
final int start = size * i;
int end = start + size - 1;
if (i == 3) { // 最后一个线程需要下载平均长度+余数长度
end = contentLength;
}
final int startPos = start;
final int endPos = end;
// 开启新线程下载startPos-endPos的数据
}
// 开启部分下载
httpURLConnection.setRequestMethod("GET");
httpURLConnection.setDoInput(true);
httpURLConnection.setDoOutput(false);
// 添加请求数据区间Range:bytes:startPos-endPos
httpURLConnection.addRequestProperty("Range", "bytes:" + startPos + "-" + endPos);
httpURLConnection.getResponseCode();
httpURLConnection.getResponseCode();
fileSize = httpURLConnection.getContentLength();
InputStream inputStream = httpURLConnection.getInputStream();
int len = -1;
byte[] buf = new byte[1024];
final RandomAccessFile file = new RandomAccessFile(
getCacheDir().getAbsolutePath() + File.separator + "panda.jpg", "rw");
file.seek(startPos); // 写入位置定位到startPos
while ((len = inputStream.read(buf)) != -1) {
file.write(buf, 0, len);
}
file.close();
上面的代码实现了简单的多线程下载,在开始下载前先通过HEAD方法请求要下载的文件,由于HEAD请求的响应体只会返回对应的头部信息,下载文件信息根本不会被返回,客户端就能够轻松获取要下载的文件大小。得到文件大小后需要为每个线程分配需要下载的文件数据区间,通常按照线程个数平均分配,不过文件大小很可能出现剩余一小段的问题,为此下载最后一段的线程通常就要负责将平均分配后剩余的那小段文件数据一同下载。客户端每个线程在请求服务器数据时需要带上Range: startPos-endPos请求头,服务器端读取到该请求头后只会返回该区间段内的文件数据回来。客户端在接收到部分数据后需要写入到本地文件中,RandomAccessFile支持在写入读取时先定位到某个位置,调用seek(startPos)就能将写入文件指针位置调整到下载区间开始位置,四个线程都是用同样的方式写入下载的个部分数据,当所有线程全部执行完毕后,本地文件中就包含了所有数据。
HTTP缓存机制
服务器端的有些数据不是经常变化的,客户端访问过一次后可以把服务端的数据缓存下来,之后再需要请求对应的数据只需要判断缓存是否过期或者向服务器求证缓存内容是否发生变化,未过期或未变化的数据都可以继续使用,缓存处理可以减少用户流量,提高数据加载速度。
在HTTP早期版本中有一个Expires响应头部,Expires的内容就是数据过期的时间,HTTP在请求数据时只要把过期时间和系统时间作对比,小于过期时间直接使用缓存数据即可,否则要重新向服务器端请求新数据。Expires的缺点很明显如果客户端系统时间不精确就会导致数据过期判断失误,因此在HTTP新版本中Expires响应头已经被废弃。
HTTP新版本中使用了Cache-Control响应头部来指定缓存策略,它包含常见的取值有private、public、no-cache、max-age,no-store,默认为private。
| Cache-Control头部字段 | 备注 |
|---|---|
| private | 只有客户端内部可以缓存 |
| public | 客户端和代理服务器都可缓存 |
| max-age=xxx | 缓存的内容将在 xxx 秒后失效 |
| no-cache | 不使用max-age来判定缓存有效,使用请求头If-Modified-Since或If-None-Match判定 |
| no-store | 禁止任何形式的缓存,也即不缓存网络数据 |
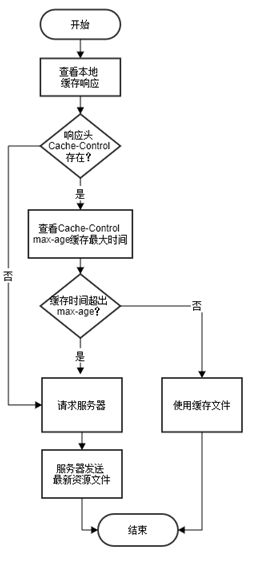
除了Cache-Control的max-age判定缓存是否有效,HTTP还提供了Etag/If-None-Match响应请求头判定文件内容是否改变,Etag的内容可以认为是资源文件的MD5运算结果,如果发生变化Etag值就发生变化。在客户端第一次请求资源时服务器端会将资源数据连同Etag一起返回给客户端,客户端后续再请求该资源会带上If-None-Match:etag请求头,服务器根据请求头判定缓存在客户端的数据是否过期,未过期就返回304状态码,否则返回新的资源数据。

Last-Modified/If-Modified-Since的缓存判定策略与Etag基本类似,不过If-Modified-Since请求头发送给服务器的是资源的上次修改时间。服务器的资源通常都是开发者提供的,如果开发者不小心在资源文件内部多加了空行就会导致修改时间发生变化,实际上资源的内容并没有发生改变,因此Etag和Last-Modified同时存在的时候Etag的优先级更高。
Cache-Control、Etag、Last-Modified三种缓存策略的优先级从高到低排序,如果它们同时存在高优先级的缓存策略生效,低优先级的自动被忽略。在Android网络开发中HTTP缓存其实使用的比较少,这里就只做原理性介绍。
HTTP网络编程测试Demo