redis常见应用场景
目录
string应用场景
微博数、粉丝数等
热点数据的缓存
Session 存储
限时业务的运用
计数器相关问题
分布式全局唯一id(string)
分布式锁
hash应用场景
存储对象信息
热点数据的缓存
list应用场景
关注列表,粉丝列表
消息队列
set应用场景
点赞、好友、粉丝等相互关系的存储
抽奖活动(set)
zset应用场景
排行榜
分页、模糊搜索
Redis 是一个强大的内存型存储,具有丰富的数据结构,使其可以应用于很多方面,包括作为数据库、缓存、消息队列等等。
string应用场景
此类型和memcache相似,作为常规的key-value缓存应用。
一个键最大能存储512MB
微博数、粉丝数等
比如key为用户名,value为具体的值
热点数据的缓存
由于redis访问速度块、支持的数据类型比较丰富,所以redis很适合用来存储热点数据,另外结合expire,我们可以设置过期时间然后再进行缓存更新操作,这个功能最为常见,我们几乎所有的项目都有所运用。
比如key为缓存的签名,如调用public int cal(String a,String b)方法,进行缓存,key就是com.cal_123_abc,value就是方法的返回结果,这里value为12,如果返回的是一个对象,可以变成一个json对象,或者一个二进制对象,通过特别的转换代码,将数据库里的value和对象来回转换。
Session 存储
这可能是应用最广的点了,相比较于类似 memcache 的 session 存储,Redis 具有缓存数据持久化的能力,当缓存因出现问题而重启后,之前的缓存数据还在那儿,这个就比较实用,避免了因为session突然消失带来的用户体验问题。
限时业务的运用
redis中可以使用expire命令设置一个键的生存时间,到时间后redis会删除它。利用这一特性可以运用在限时的优惠活动信息、手机验证码等业务场景。
比如手机验证码,key为手机号,value为手机验证码,设置expire的时机为60s。
计数器相关问题
redis由于incrby命令可以实现原子性的递增,所以可以运用于高并发的秒杀活动、分布式序列号的生成、具体业务还体现在比如限制一个手机号发多少条短信、一个接口一分钟限制多少请求、一个接口一天限制调用多少次等等。
例如key为手机号,value为已经发送的短信数
set key 0
incr key // incr readcount::{帖子id} 每阅读一次
get key // get readcount::{帖子id} 获取阅读量
分布式全局唯一id(string)
实现类似于RDBMS的Sequence功能,生成一系列唯一的序列号
设置序列起始值:
SET sequence "10000"
获取一个序列值:
INCR sequence
直接将返回值作为序列使用即可。
获取一批(如100个)序列值:
INCRBY sequence 100
假设返回值为N,那么[N - 99 ~ N]的数值都是可用的序列值。
当多个客户端同时向Redis申请自增序列时,Redis能够确保每个客户端得到的序列值或序列范围都是全局唯一的,绝对不会出现不同客户端得到了重复的序列值的情况
分布式锁
这个主要利用redis的setnx命令进行,setnx:"set if not exists"就是如果不存在则成功设置缓存同时返回1,否则返回0 ,这个特性在后台中有所运用,因为我们服务器是集群的,定时任务可能在两台机器上都会运行,所以在定时任务中首先 通过setnx设置一个lock,如果成功设置则执行,如果没有成功设置,则表明该定时任务已执行。 当然结合具体业务,我们可以给这个lock加一个过期时间,比如说30分钟执行一次的定时任务,那么这个过期时间设置为小于30分钟的一个时间 就可以,这个与定时任务的周期以及定时任务执行消耗时间相关。
setnx key value,当key不存在时,将 key 的值设为 value ,返回1。若给定的 key 已经存在,则setnx不做任何动作,返回0。
当setnx返回1时,表示获取锁,做完操作以后del key,表示释放锁,如果setnx返回0表示获取锁失败,整体思路大概就是这样
hash应用场景
redis hash是一个string类型的field和value的映射表,hash特别适合用于存储对象(应为对象可能会包含很多属性)
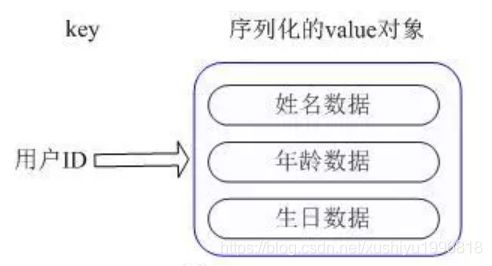
存储对象信息
key为用户id,value为hash,hash里的key为name,age等字段名称,value为abc,12等字段值。
注意:对象信息可以用hash,也可以用string存储,但是如果用string,必须要每次都整个get和set对象,不能get和set一个字段
热点数据的缓存
由于redis访问速度块、支持的数据类型比较丰富,所以redis很适合用来存储热点数据,另外结合expire,我们可以设置过期时间然后再进行缓存更新操作,这个功能最为常见,我们几乎所有的项目都有所运用。
key为这种缓存的代号,hash的key为缓存的签名,如调用public int cal(String a,String b)方法,进行缓存,hash的key就是com.cal_123_abc,hash的value就是方法的返回结果,这里hash的value为12,如果返回的是一个对象,可以变成一个json对象,或者一个二进制对象,通过特别的转换代码,将数据库里hash的value和对象来回转换。
list应用场景
list列表是简单的字符串列表,按照插入顺序排序(内部实现为LinkedList),可以选择将一个链表插入到头部或尾部
关注列表,粉丝列表
twitter的关注列表,粉丝列表等都可以用Redis的list结构来实现。
key为用户id,value为一个list,里面的值为用户的粉丝等。
消息队列
例如 email 的发送队列、等待被其他应用消费的数据队列,Redis 可以轻松而自然的创建出一个高效的队列。
电商秒杀就可以用
# 实现方式一
# 一直往list左边放
lpush key value
# key这个list有元素时,直接弹出,没有元素被阻塞,直到等待超时或发现可弹出元素为止,上面例子超时时间为10s
brpop key value 10
# 实现方式二
rpush key value
blpop key value 10
set应用场景
点赞、好友、粉丝等相互关系的存储
Redis set对外提供的功能与list类似是一个列表的功能,特殊之处在于set是可以自动排重的,当你需要存储一个列表数据,又不希望出现重复数据时,set是一个很好的选择,并且set提供了判断某个成员是否在一个set集合内的重要接口,这个也是list所不能提供的。 又或者在微博应用中,每个用户关注的人存在一个集合中,就很容易实现求两个人的共同好友功能。
而且Redis还为集合提供了求交集、并集、差集等操作,可以非常方便的实现如共同关注、共同喜好、二度好友等功能,对上面的所有集合操作,你还可以使用不同的命令选择将结果返回给客户端还是存集到一个新的集合中。
这个在奶茶活动中有运用,就是利用set存储用户之间的点赞关联的,另外在点赞前判断是否点赞过就利用了sismember方法,当时这个接口的响应时间控制在10毫秒内,十分高效。
key为用户id,value为一个set,里面的值为用户的粉丝等。
# 1001用户给8001帖子点赞
sadd like::8001 1001
# 取消点赞
srem like::8001 1001
# 检查用户是否点过赞
sismember like::8001 1001
# 获取点赞的用户列表
smembers like::8001
# 获取点赞用户数
scard like::8001
seven关注的人
sevenSub -> {qing, mic, james}
青山关注的人
qingSub->{seven,jack,mic,james}
Mic关注的人
MicSub->{seven,james,qing,jack,tom}
# 返回sevenSub和qingSub的交集,即seven和青山的共同关注
sinter sevenSub qingSub -> {mic,james}
# 我关注的人也关注他,下面例子中我是seven
# qing在micSub中返回1,否则返回0
sismember micSub qing
sismember jamesSub qing
# 我可能认识的人,下面例子中我是seven
# 求qingSub和sevenSub的差集,并存在sevenMayKnow集合中
sdiffstore sevenMayKnow qingSub sevenSub -> {seven,jack}
抽奖活动(set)
# 参加抽奖活动
sadd key {userId}
# 获取所有抽奖用户,大轮盘转起来
smembers key
# 抽取count名中奖者,并从抽奖活动中移除
spop key count
# 抽取count名中奖者,不从抽奖活动中移除
srandmember key count
zset应用场景
Redis sorted set的内部使用HashMap和跳跃表(SkipList)来保证数据的存储和有序,HashMap里放的是成员到score的映射,跳跃表按score从小到大保存所有集合元素。使用跳跃表的结构可以获得比较高的查找效率,并且在实现上比较简单。时间复杂度与红黑树相同,增加、删除的操作较为简单。
排行榜
关系型数据库在排行榜方面查询速度普遍偏慢,所以可以借助redis的SortedSet进行热点数据的排序。
例如图书的热度,每个书代表一个热度值,比如吞噬星空的值为100,盘龙的值为80,zset可以直接得到最大的n个元素及他们的score。
key为图书热度的标志key,value为zet,里面的元素是图书,元素对应的score是图书热度。
在奶茶活动中,我们需要展示各个部门的点赞排行榜, 所以我针对每个部门做了一个SortedSet,然后以用户的openid作为上面的username,以用户的点赞数作为上面的score, 然后针对每个用户做一个hash,通过zrangebyscore就可以按照点赞数获取排行榜,然后再根据username获取用户的hash信息,这个当时在实际运用中性能体验也蛮不错的。
分页、模糊搜索
redis的set集合中提供了一个zrangebylex方法,语法如下:
ZRANGEBYLEX key min max [LIMIT offset count]
通过ZRANGEBYLEX zset - + LIMIT 0 10 可以进行分页数据查询,其中- +表示获取全部数据
zrangebylex key min max 这个就可以返回字典区间的数据,利用这个特性可以进行模糊查询功能,这个也是目前我在redis中发现的唯一一个支持对存储内容进行模糊查询的特性。
前几天我通过这个特性,对学校数据进行了模拟测试,学校数据60万左右,响应时间在700ms左右,比mysql的like查询稍微快一点,但是由于它可以避免大量的数据库io操作,所以总体还是比直接mysql查询更利于系统的性能保障。