Data Mining in
Python: A Guide
转载原文:https://www.springboard.com/blog/data-mining-python-tutorial/(全英)
译文:
1、数据挖掘和算法
数据挖掘是从大型数据库的分析中发现预测信息的过程。对于数据科学家来说,数据挖掘可能是一项模糊而艰巨的任务 - 它需要多种技能和许多数据挖掘技术知识来获取原始数据并成功获取数据。您需要了解统计学的基础,以及可以帮助您大规模进行数据挖掘的不同编程语言。
本指南将提供一个示例填充的使用Python的数据挖掘简介,Python是最广泛使用的数据挖掘工具之一 - 从清理和数据组织到应用机器学习算法。首先,让我们更好地理解数据挖掘及其完成方式。
1.1、数据挖掘定义
数据挖掘的期望结果是从给定数据集创建模型,该模型可以将其洞察力推广到类似数据集。从银行和信贷机构的自动欺诈检测中可以看到成功的数据挖掘应用程序的真实示例。
如果您的银行检测到您的帐户存在任何可疑活动,您的银行可能会制定一项提醒您的政策 - 例如在您注册的住所以外的州内重复提取ATM或大量购物。这与数据挖掘有何关系?数据科学家通过应用算法来创建该系统,通过将交易与欺诈性和非欺诈性收费的历史模式进行比较,对交易是否具有欺诈性进行分类和预测。该模型“知道”如果你住在加利福尼亚州圣地亚哥,那么向俄罗斯人口稀少的省份收取的数千美元购买的可能性很大。
这只是数据挖掘的众多强大应用之一。数据挖掘的其他应用包括基因组测序,社交网络分析或犯罪成像 - 但最常见的用例是分析消费者生命周期的各个方面。公司使用数据挖掘来发现消费者的偏好,根据他们的购买活动对不同的消费者进行分类,并确定对付高薪客户的要求 - 这些信息可以对改善收入流和降低成本产生深远影响。
如果您正在努力获得良好的数据集以开始分析,我们为您的第一个数据科学项目编译了19个免费数据集。
什么是数据挖掘技术?
有多种方法可以从数据集构建预测模型,数据科学家应该了解这些技术背后的概念,以及如何使用代码生成类似的模型和可视化。这些技术包括:
回归 - 通过优化误差减少来估计变量之间的关系。

具有拟合线性回归模型的散点图的示例
分类 - 识别对象所属的类别。一个例子是将电子邮件分类为垃圾邮件或合法邮件,或者查看某人的信用评分并批准或拒绝贷款请求。
聚类分析 - 根据数据的已知特征查找数据对象的自然分组。在营销中可以看到一个例子,其中分析可以揭示具有独特行为的客户分组 - 这可以应用于业务战略决策中。
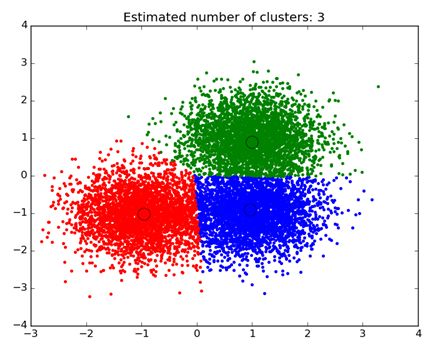
散点图的示例,其中数据按群集分段和着色
关联和相关分析 - 寻找不明显的变量之间是否存在唯一关系。一个例子就是着名的啤酒和尿布案例:在本周末购买纸尿裤的男性更有可能购买啤酒,因此商店将它们放在一起以增加销量。
异常值分析 - 检查异常值以检查所述异常值的潜在原因和原因。其中一个例子是在欺诈检测中使用离群值分析,并试图确定规范之外的行为模式是否是欺诈。
业务数据挖掘通常使用事务和实时数据库执行,该数据库允许轻松使用数据挖掘工具进行分析。其中一个例子是在线分析处理服务器或OLAP,它允许用户在数据服务器内进行多维分析。OLAP允许企业查询和分析数据,而无需下载静态数据文件,这在数据库日常增长的情况下很有用。但是,对于那些希望学习数据挖掘和自己练习的人来说,iPython笔记本 非常适合处理大多数数据挖掘任务。
让我们来看看如何使用Python来使用上述两种数据挖掘算法执行数据挖掘:回归和 聚类。
2、在Python中创建回归模型
我们想解决的问题是什么?
我们想要建立变量之间线性关系的估计,打印相关系数,并绘制最佳拟合线。对于这个分析,我将使用来自Kaggle的King's County数据集中的House Sales的数据。如果您对Kaggle不熟悉,那么它是查找适合数据科学实践的数据集的绝佳资源。King's County的数据包含有关房价和房屋特征的信息 - 让我们看看我们是否可以估算房价与房屋面积之间的关系。
第一步:为工作提供合适的数据挖掘工具 - 安装Jupyter,熟悉一些模块。
首先,如果您想要跟随,请在桌面上安装Jupyter。它是一个免费的平台,为iPython笔记本(.ipynb文件)提供了一个非常直观的处理器。请按照以下说明进行安装。我在这里所做的一切都将在Jupyter的“Python [Root]”文件中完成。
我们将使用Python 的Pandas mo dule来清理和重构我们的数据。Pandas是一个开源模块,用于处理数据结构和分析,这对于使用Python的数据科学家来说无处不在。它允许数据科学家以任何格式上传数据,并提供一个简单的平台来组织,排序和操作该数据。如果这是您第一次使用Pandas,请查看有关基本功能的精彩教程!
在[1]中:
导入 pandas as pd
In [1]:
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import scipy.stats as stats
import seaborn as sns
from matplotlib import rcParams
%matplotlib inline
%pylab inline
从numpy和matplotlib填充交互式命名空间
在上面的代码中,我导入了一些模块,这里是他们所做的细分:
Numpy - 科学计算的必要包。它包含一个非常通用的结构,用于处理数组,这是scikit-learn用于输入数据的主要数据格式。
Matplotlib - Python中数据可视化的基础包。该模块允许创建从简单的散点图到三维等高线图的所有内容。请注意,从matplotlib我们安装pyplot,这是模块层次结构中最高级的状态机环境(如果这对你没有任何意义,请不要担心它,只需确保将它导入到你的笔记本中)。使用'%matplotlib inline'对于确保所有图表都显示在笔记本中至关重要。
Scipy - python中统计工具的集合。Stats是导入回归分析函数的scipy模块。
让我们分解如何应用数据挖掘来逐步解决回归问题!在现实生活中,您很可能不会立即准备好应用机器学习技术的数据集,因此您需要首先清理和组织数据。
In [2]:
df = pd.read_csv('/Users/michaelrundell/Desktop/kc_house_data.csv')
df.head()
OUT [2]:
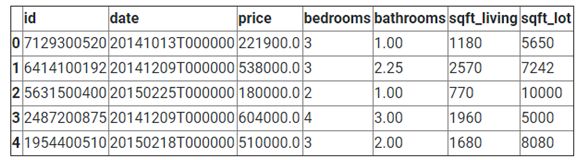
使用pandas(pd.read_csv)从Kaggle读取csv文件。
In [3]:
df.isnull().any()
Out[3]:
id False
date False
price False
bedrooms False
bathrooms False
sqft_living False
sqft_lot False
...
dtype: bool
Checking to see if any of our data has null values. If there were any, we’d drop or filter the null values out.
In [4]:
df.dtypes
Out[4]:
id int64
date object
price float64
bedrooms int64
bathrooms float64
sqft_living int64
sqft_lot int64
...
dtype: object
检查每个变量的数据类型。我们想要了解数据是否是数字(int64,float64)或不是(对象)。
我使用Pandas从csv文件导入了数据框,我做的第一件事是确保它正确读取。我还使用了“isnull()”函数来确保我的数据都不能用于回归。在现实生活中,单个列可能具有整数,字符串或NaN形式的数据,所有这些都在一个地方 - 这意味着您需要检查以确保类型匹配并且适合回归。这个数据集恰好已经非常严格地准备好了,你不会经常在自己的数据库中看到这些数据集。
下一篇:简单的探索性分析和回归结果。
让我们在进一步了解之前了解数据,重要的是要查看数据的形状 - 并仔细检查数据是否合理。损坏的数据并不罕见,因此最好始终运行两项检查:首先,使用df.describe()查看分析中的所有变量。其次,使用plt.pyplot.hist()绘制分析所针对的变量的直方图。
In [5]:
df.describe()
out[5]:
| 价钱 |
卧室 |
浴室 |
sqft_living |
|
| 计数 |
21613 |
21613 |
21613 |
21613 |
| 意思 |
540088.10 |
3.37 |
2.11 |
2079.90 |
| STD |
367127.20 |
0.93 |
0.77 |
918.44 |
| 分 |
75000.00 |
0.00 |
0.00 |
290.00 |
| 25% |
321950.00 |
3.00 |
1.75 |
1427.00 |
| 50% |
450000.00 |
3.00 |
2.25 |
1910.00 |
| 75% |
645000.00 |
4.00 |
2.50 |
2550.00 |
| 最大 |
7700000.00 |
33.00 |
8.00 |
13540.00 |
快速消息:我们正在处理包含21,613个观测资料的数据集,平均价格约为$ 540k,中位数价格约为$ 450k,而且平均房屋面积为2080 ft 2
In [19]:
fig = plt.figure(figsize=(12, 6))
sqft = fig.add_subplot(121)
cost = fig.add_subplot(122)
sqft.hist(df.sqft_living, bins=80)
sqft.set_xlabel('Ft^2')
sqft.set_title("Histogram of House Square Footage")
cost.hist(df.price, bins=80)
cost.set_xlabel('Price ($)')
cost.set_title("Histogram of Housing Prices")
plt.show()
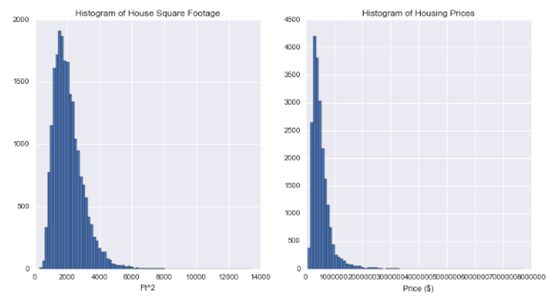
使用matplotlib(plt),我们打印了两个直方图,以观察房价和平方英尺的分布情况。我们发现两个变量的分布都是右倾的。
现在我们已经很好地了解了我们的数据集,并且知道了我们试图测量的变量的分布,让我们做一些回归分析。首先,我们导入statsmodels以获得最小二乘回归估计函数。在“普通最小二乘法”模块会做大量的工作,当涉及到捣弄数字在Python中回归。
In [15]:
import statsmodels.api as sm
from statsmodels.formula.api import ols
当您使用只有两个变量的OLS编码生成线性回归摘要时,这将是您使用的公式:
Reg = ols('因变量〜自变量,数据帧).fit()
打印(Reg.summary())
当我们查看King's县的房屋价格和房屋面积时,我们打印出以下摘要报告:
In [16]:
m = ols('price ~ sqft_living',df).fit()
print (m.summary())
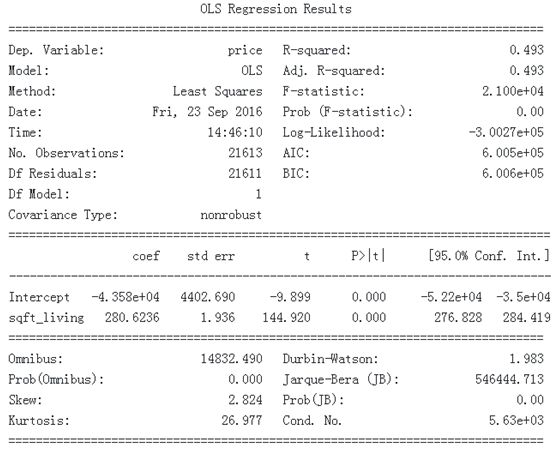
警告:
[1]标准错误假设正确指定了错误的协方差矩阵。
[2]条件数很大,5.63e + 03。这可能表明存在
强多重共线性或其他数值问题。
简单线性回归模型摘要输出的示例。
当您打印OLS回归的摘要时,可以轻松找到所有相关信息,包括R平方,t统计量,标准误差和相关系数。从产量来看,很明显平方英尺和房价之间存在极其显着的关系,因为存在极高的t值144.920,并且 P> | t | 0% - 这实际上意味着这种关系由于统计变异或机会而几乎为零。
这种关系也有一个不错的规模 - 每增加100平方英尺的房子,我们可以预测房子平均价格会高出28,000美元。可以很容易地调整此公式以包含多个自变量,只需遵循以下公式:
Reg = ols(‘Dependent variable ~ivar1 + ivar2 + ivar3… + ivarN, dataframe).fit()
print(Reg.summary())
In [26]:
m = ols('price ~ sqft_living + bedrooms + grade + condition',df).fit()
print (m.summary())
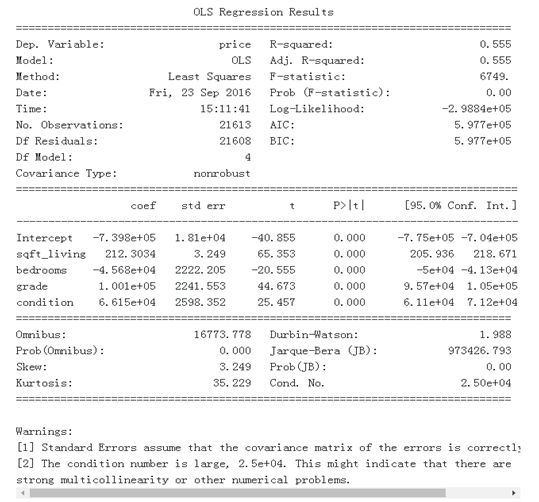
警告:
[1]标准错误假设正确指定了错误的协方差矩阵。
[2]条件数很大,2.5e + 04。这可能表明存在
强多重共线性或其他数值问题。
多元线性回归的一个例子。
在我们上面的多元回归输出中,我们了解到通过使用额外的自变量,例如卧室的数量,我们可以提供更好地拟合数据的模型,因为此回归的R平方已增加到0.555。这意味着我们能够通过添加更多的自变量来解释模型中49.3%的变异到55.5%。
可视化回归结果:
使用回归汇总输出对于检查回归模型的准确性以及用于估计和预测的数据非常重要 - 但是可视化回归是以更易消化的格式传达回归结果的重要步骤。
本节将完全依赖于Seaborn(sns),它具有非常简单和直观的功能,可以使用散点图绘制回归线。我选择为平方英尺和价格创建一个联合图,显示回归线以及每个变量的分布图。
In [24]:
sns.jointplot(x="sqft_living", y="price", data=df, kind = 'reg',fit_reg= True, size = 7)
plt.show()
/Users/michaelrundell/anaconda/lib/python3.5/site-packages/statsmodels/nonparametric/kdetools.py:20:VisibleDeprecationWarning:使用非整数而不是整数将导致将来出错
y = X [:m / 2 + 1] + np.r_ [0,X [m / 2 + 1:],0] * 1j
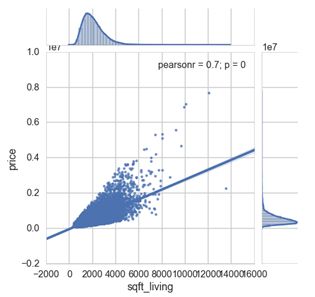
这包含了我的回归示例,但是在python中还有许多其他方法可以执行回归分析,尤其是在使用某些技术时。有关回归模型的更多信息,请参阅以下资源。接下来我们将介绍集群分析。
使用Seaborn可视化线性关系 - 本文档提供了具体示例,说明如何修改回归图,并显示您可能不知道如何自行编码的新功能。它还教你如何适应不同类型的模型,如二次或逻辑模型。
Python中的统计信息 - 本教程介绍了在python中执行回归的不同技术,还将教您如何进行假设测试和交互测试。
如果您想了解更多可帮助您可视化结果的数据挖掘软件,您应该查看 我们编译的这31个免费数据可视化工具。
3、在Python中创建聚类模型
我们希望为一组数据对象创建自然分组,这些数据对象可能未在数据本身中明确说明。我们的分析将使用黄石公园着名间歇泉Old Faithful喷发的数据。Barney Govan 从这个Github存储库中找到了这些数据。它只包含两个属性,即喷发(分钟)和喷发长度(分钟)之间的等待时间。只有两个属性可以很容易地创建一个简单的k-means集群模型。
什么是k-means集群模型?
K-Means Cluster模型以下列方式工作 - 所有这些博客都归功于此:
(1)、从一组随机选择的k个质心(k个簇的假定中心)开始
(2)、根据最接近的质心确定哪个观测点在哪个群集中(使用平方欧几里德距离:Σpj= 1(xij-xi'j)2其中p是维数。
(3)、通过最小化与群集中每个观察的平方欧几里德距离来重新计算每个群集的质心
(4)、重复2.和3.直到簇的成员(以及因此质心的位置)不再改变。
(5)、如果这仍然令人困惑,请查看Jigsaw Academy的这段有用的视频。现在,让我们继续将此技术应用于我们的Old Faithful数据集。
第一步:探索性数据分析
您需要安装一些模块,包括一个名为Sci-kit Learn的新模块- 用于Python中机器学习和数据挖掘的工具集(阅读我们使用Sci-kit进行神经网络模型的教程)。Cluster是sci-kit模块,它使用聚类算法导入函数,因此从sci-kit导入它。
首先,让我们将所有必要的模块导入我们的iPython Notebook并进行一些探索性数据分析。
In [18]:
import pandas as pd
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
import sklearn
from sklearn import cluster
%matplotlib inline
faithful = pd.read_csv('/Users/michaelrundell/Desktop/faithful.csv')
faithful.head()
out[18]:
| 爆发 |
等候 |
|
| 0 |
3.600 |
79 |
| 1 |
1.800 |
54 |
| 2 |
3.333 |
74 |
| 3 |
2.283 |
62 |
| 4 |
4.533 |
85 |
阅读旧的忠实csv并导入所有必要的值
我所做的就是从本地目录中读取csv,这恰好是我计算机的桌面,并显示了数据的前5个条目。幸运的是,我知道这个数据集没有缺少或NaN值的列,因此我们可以跳过此示例中的数据清理部分。我们来看一下数据的基本散点图。
In [19]:
faithful.columns = ['eruptions', 'waiting']
plt.scatter(faithful.eruptions, faithful.waiting)
plt.title('Old Faithful Data Scatterplot')
plt.xlabel('Length of eruption (minutes)')
plt.ylabel('Time between eruptions (minutes)')
Out[19]:
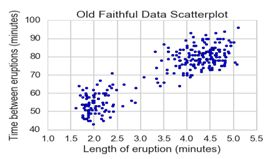
重命名列并使用matplotlib创建一个简单的散点图
关于我的过程的一些快速说明:我重新命名了列 - 它们与肉眼看起来没什么不同,但是“等待”列在单词之前有一个额外的空间,并且为了防止与进一步分析混淆我更改了它确保我不会忘记或在路上犯任何错误。
第二步:构建集群模型
我们看到的是散点图,其中有两个很容易明显的聚类,但数据集并未将任何观察标记为属于任何一个组。接下来的几个步骤将涵盖视觉上区分两组的过程。在下面的代码中,我建立了一些重要的变量并改变了数据的格式。
In [20]:
faith = np.array(faithful)
k = 2
kmeans = cluster.KMeans(n_clusters=k)
kmeans.fit(faith)
labels = kmeans.labels_
centroids = kmeans.cluster_centers_
格式化和功能创建:
1、我将忠实的数据帧读作一个numpy数组,以便sci-kit能够读取数据。
2、选择K = 2作为簇的数量,因为我们正在尝试创建2个明确的分组。
3、'kmeans'变量由sci-kit中的集群模块调用的输出定义。我们采用了K个簇,并将数据拟合到数组'faith'中。
现在我们已经设置了用于创建集群模型的变量,让我们创建一个可视化。下面的代码将绘制按簇颜色的散点图,并给出最终的质心位置。具体的代码行的说明可以在下面找到。
In [21]:
for i in range(k):
# select only data observations with cluster label == i
ds = faith[np.where(labels==i)]
# plot the data observations
plt.plot(ds[:,0],ds[:,1],'o', markersize=7)
# plot the centroids
lines = plt.plot(centroids[i,0],centroids[i,1],'kx')
# make the centroid x's bigger
plt.setp(lines,ms=15.0)
plt.setp(lines,mew=4.0)
plt.show()

创建群集模型的可视化
快速细分上面的代码:
1、将数据分组为2组的所有工作都在上一段代码中完成,我们使用命令kmeans.fit(faith)。代码的这一部分只是创建了显示它的图。
2、ds变量只是原始数据,但重新格式化为包含基于组数的新颜色标签 - k中的整数数。
3、plt.plot调用x数据,y数据,对象的形状和圆的大小。
4、其余代码显示k-means聚类过程的最终质心,并控制质心标记的大小和厚度。
在这里我们拥有它 - 一个简单的集群模型。此代码适用于包含不同数量的群集,但对于此问题,仅包含2个群集是有意义的。现在我们已经将这些聚类看起来很好地定义了,我们可以从这两个聚类中推断出意义。他们代表什么?绿色集群:主要由火山爆发组成,火山爆发之间的短暂等待时间可以定义为“弱火或快速射击”,而蓝色火星群可以称为“火力爆发”。
值得注意的是:这种技术不适用于所有数据集 - 数据科学家David Robinson 在他的文章中完美地解释了K-means聚类“不是免费的午餐”。如果您的数据具有不均匀的聚类概率,K-means的假设会失败(它们在每个簇中没有大致相同的观察量),或者具有非球形簇。如果您认为您的群集问题不适用于K-means群集,请查看有关替代群集建模技术的这些资源:
Sci-kit群集模块 - 此文档有一个漂亮的图像,可以直观地比较scikit-learn中的聚类算法,因为它们会查找不同的散点图。如果您有一个类似于其中一个示例的散点图,则使用此文档可以指向正确的算法。它还为您提供了有关如何以数学方式评估聚类模型的一些见解。
聚类算法 - 这个来自斯坦福大学CS345课程的Powerpoint演示文稿,数据挖掘,可以深入了解不同的技术 - 它们如何工作,有效和无效等等。它是理解聚类在理论层面如何工作的一个很好的学习资源。
结论
数据挖掘包含许多预测建模技术,您可以使用各种数据挖掘软件。要学习使用Python来应用这些技术是很困难的 - 将练习和勤奋应用到您自己的数据集上是很困难的。在早期,您将遇到无数的错误,错误消息和包版广告。 - 但在数据挖掘尝试中保持持久和勤奋。我希望通过查看上面的集群和线性回归模型的代码和创建过程,您已经了解到数据挖掘是可以实现的,并且可以使用有效数量的代码完成。