针对鸢尾花问题使用sk-learn库训练模型
鸢尾花的种类主要分为:变色鸢尾花、维吉尼亚鸢尾花、山鸢尾花
鸢尾花的种类的划分主要是根据:花萼长度,花萼宽度,花瓣长度,花瓣宽度
通过使用python来建立一个模型来自己学习各个种类鸢尾花的特点,根据学习到的经验去自动帮我划分不同种类的鸢尾花。
1、使用sk-learn库来导入鸢尾花数据,使用train_test_split函数和创建一个K近邻算法。
(得到一个题库,题库里面存储有题目和答案)
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn import datasets
iris = datasets.load_iris()
print(iris)
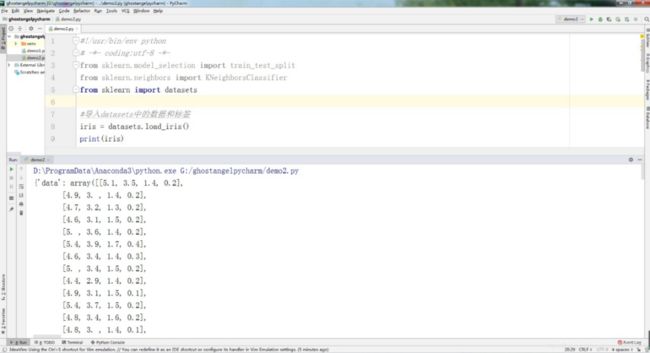
2、将数据集中的鸢尾花的数据放在iris_X中。
(将题目放在iris_X里面储存)
iris_X = iris.data
print(iris_X)

3、将数据集中的目标放入iris_y
(将答案放在iris_y里面存储)
iris_y = iris.target
# print(iris_y)
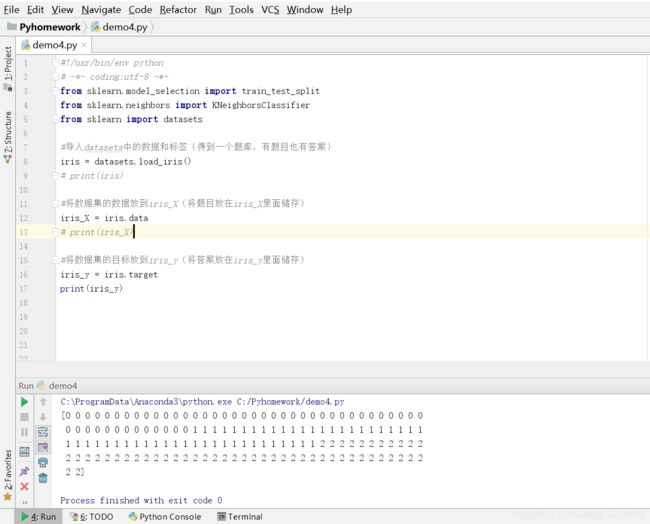
4、将源数据划分为测试集和训练集数据
(将问题和答案按比例划分为模拟题类和真题类)
X_train, X_test, y_train, y_test = train_test_split(iris_X, iris_y, test_size=0.3)
5、设置knn分类器
(将题型相近的进行分类)
knn = KNeighborsClassifier(n_neighbors=5)
6、#进行模型训练
(模型通过模拟题进行练习学到有关于鸢尾花种类的知识)
knn.fit(X_train, y_train)
7、定义目标预测值 = knn模型根据X_test预测出来的值
(得到模型预测真题的答案)
y_predict = knn.predict(X_test)
8、输出一下模型的预测值
print("模型的预测值为:",y_predict)

对于输出的数字,可以理解为:1是代表山鸢尾花,2是代表维吉尼亚鸢尾花,3是代表变色鸢尾花
9、输出目标测试值
(既然模型已经对答案进行了预测,接下来是时候揭晓真正的答案了。看看模型预测得准不准。)
print("目标测试值为:y_test")
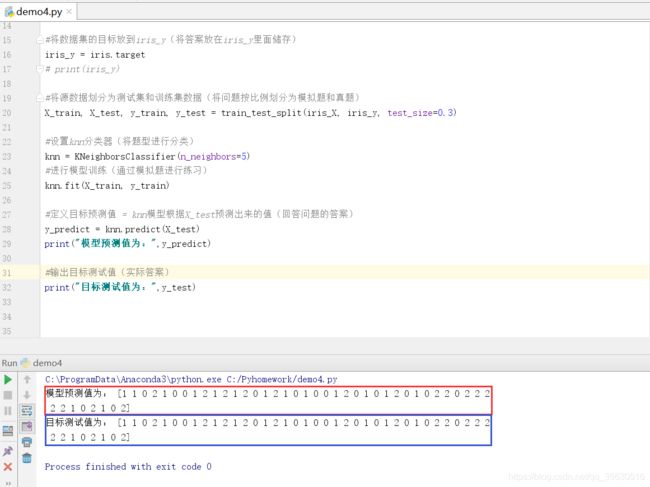
这次似乎测得挺准的呢,全测对了。(不过每一次测它的预测结果都不太一样)
10、用公式对预测值和测试值进行计算,算出其准确率
(通过计算答对了多少题,然后计算其答题的准确率)
print("准确率:%f"%knn.score(X_test, y_test))

这次预测错了2个,所以准确率是93.33%(其实模型也不可能每次都能预测准确的,淡定)