python爬虫之biilibili弹幕爬取+qq音乐热评爬取
目录
前言
Bilibili弹幕爬取
分析与弹幕相关的内容
BilibiliSpider源码
run.py
结果截图
QQ音乐热评爬取
QQ音乐热评爬取源码
run.py
settting.py
结果截图:
结语:
前言
爬虫的方法很多比如用requests,beautifulsoup,scrapy这些库可以很方便的抓取网页内容。如果他的web端提供api接口那就更方便了,如果提供返回json数据也可以
Bilibili弹幕爬取
要爬取弹幕首先我们要分析它是如何进行http请求的,我们这里使用360极速浏览器的内置开发者工具,查看网络请求过程
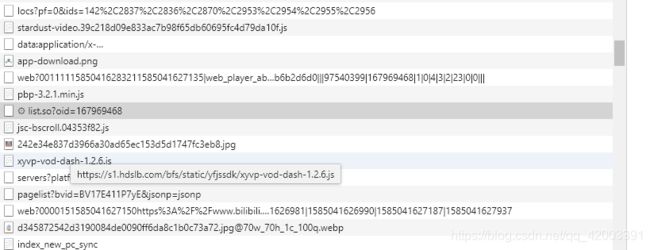
分析与弹幕相关的内容
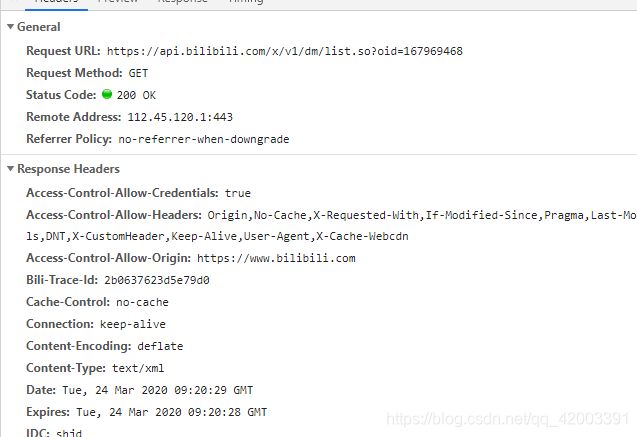
发现这是bilibili的一个api接口,那这就简单了,直接调用它的接口获取数据,这里有一个oid我们不知道是什么,我们直接搜索这个数值发现

这个请求出现了这个数值叫cid
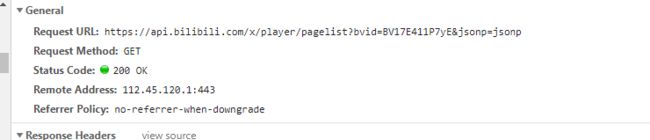
cid是通过url里面的内容得到的![]()
很明显是区分video的
于是我们可以得到如下代码(使用scrapy库)
BilibiliSpider源码
import scrapy
import re
import json
from matplotlib import pyplot as plt
# 视频排序方式
sort_model = {1:"totalrank",2:"click",3:"pubdate",4:"dm",5:"stow"}
# bilibili 弹幕分析
class BilibiliDanmuSpider(scrapy.Spider):
name="BilibiliDanmuSpider"
#,"https://api.bilibili.com/x/v1/dm/list.so?oid=43147218"
def __init__(self,key=None,*args,**kwargs):
super(eval(self.__class__.__name__),self).__init__(*args,**kwargs)
print(key)
self.start_urls=["https://search.bilibili.com/all?keyword=%s"%(key)]
self.danmu_header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.167 Safari/537.36','Accept': '*/*','Accept-Encoding': 'gzip, deflate, br','Accept-Language': 'zh-CN,zh;q=0.9'}
def isHttpUrl(self,url):
return len(re.findall("^(http)s?://*",url))==1
def parse(self,response):
try:
data=response.body.decode()
selector=scrapy.Selector(text=data)
print(response.url)
for url in selector.xpath("//ul[@type='video']/li/a/@href").extract():
url="https:%s"%(url)
if self.isHttpUrl(url):
yield scrapy.Request(url=url,callback=self.parseSubPage)
except Exception as err:
print(err)
def parseSubPage(self,response):
try:
#print("subPage=%s"%(response.url))
url=response.url
#av_id=self.getAVID(url)
#print(response.url,av_id)
b_vid=re.findall(r"(?<=video/)[a-zA-Z0-9]+\.?[a-zA-Z0-9]*",url)
if len(b_vid)==1:
b_vid=b_vid[0]
print("b_vid="+b_vid)
url = "https://api.bilibili.com/x/player/pagelist?bvid="+b_vid+"&jsonp=jsonp"
#url = "https://api.bilibili.com/x/player/pagelist?aid="+av_id+"&jsonp=jsonp"
yield scrapy.Request(url=url,callback=self.getBarrage)
except Exception as err:
print(err)
def getAVID(self,url):
av_id = re.findall(r"(?<=av)\d+\.?\d*",url)
if len(av_id)>0:
return av_id[0]
else:
return ""
def getBarrage(self,response):
try:
res=json.loads(response.text)
cid=res['data'][0]['cid']
print(cid)
url="https://api.bilibili.com/x/v1/dm/list.so?oid=%d"%(cid)
yield scrapy.Request(url=url,callback=self.getDanMu)
except Exception as err:
print(err)
def getDanMu(self,response):
import wordcloud
try:
texts={}
data=response.body.decode()
selector=scrapy.Selector(text=data)
for text in selector.xpath("//d/text()").extract():
if texts.get(text) == None:
texts[text]=1
else:
texts[text]+=1
texts=sorted(texts.items(), key=lambda kv: (kv[1]), reverse=True)
res=""
for text in texts:
res+=text[0]+","
print(res[:-1])
# 构建词云对象w,设置词云图片宽、高、字体、背景颜色等参数
w = wordcloud.WordCloud(width=1000,height=700,max_words=200,background_color='white', max_font_size=100,font_path="C:/Users/tangy/Desktop/py/lesson.cdu/res/simhei.ttf")
# 调用词云对象的generate方法,将文本传入
w.generate(res[:-1])
plt.figure("response=%s"%(response.url))
plt.imshow(w)
plt.axis('off')
plt.show()
except Exception as err:
print(err)
run.py
from scrapy import cmdline
key = input("输入关键字:")
cmdline.execute(("scrapy crawl BilibiliDanmuSpider -s LOG_ENABLED=False -a key=%s"%(key)).split())结果截图
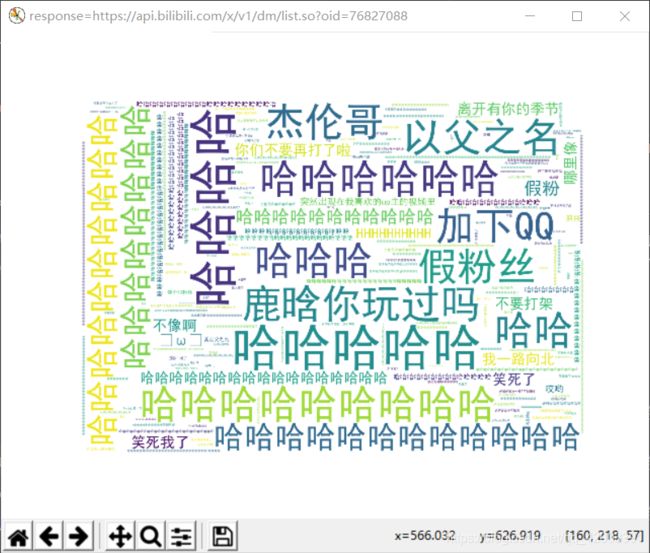
QQ音乐热评爬取
想要爬取杰伦哥的歌的热评,直接上它的网页,也可以用app但是要用其他的抓包软件。这里只介绍网页端
找到具体位置,清除网络请求并点击加载更多的热评
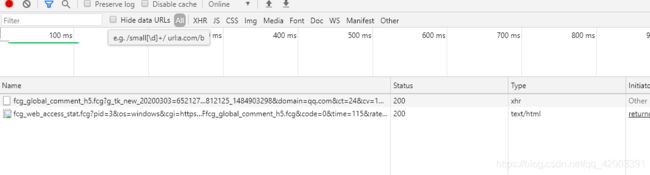
发现第一个请求便是我们需要的数据

但是呢,我们发现加载更多的数据仍然是相同的数据,怀疑是api的问题于是我们找到它具体的javascript代码
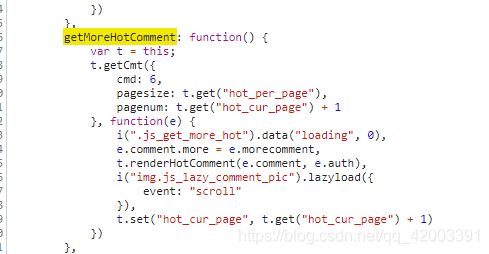
根据代码进行编写,多次实验发现是同一数据,于是尝试修改pagesize,终于200是比较合适的,可以正常返回数据
新加:
https://c.y.qq.com/base/fcgi-bin/fcg_global_comment_h5.fcg?format=json&cid=205360772&reqtype=2&biztype=1&topid=104883226&cmd=6&needmusiccrit=1&pagenum=4&pagesize=20这个连接是从桌面的应用抓的包得到的,根据这个就可以获取更多的热评
于是开始分析请求url

分析前面很多都是固定的,还有就是qq音乐的版本,所以我们这里不准备获取版本,直接使用当前版本,多首歌对比下来,值得我们注意的参数就只有topid和lasthotcommentid
于是乎开始分析这两个参数是如何得到的

在第一个请求我们找到了这个songid,但是后面在写搜索的时候发现在搜索列表也有数据,于是就用的搜索数据
在第3个url请求我们找到了


接下来对request url进行分析,值得我们注意的是多了一个serachId,这个seachid我觉得是随机生成的于是我就固定一个值,loginUin也可以可有可无,w是搜索的内容
start_urls初始化代码如下
self.start_urls=["https://c.y.qq.com/soso/fcgi-bin/client_search_cp?ct=24&qqmusic_ver=1298&new_json=1&remoteplace=txt.yqq.song&searchid=55594271468033902&t=0&aggr=1&cr=1&catZhida=1&lossless=0&flag_qc=0&p=1&n=10&w=%s&g_tk_new_20200303=652127051&g_tk=652127051&loginUin=&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0"%(key)]QQ音乐热评爬取源码
import scrapy
import re
import json
class ReviewsSpider(scrapy.Spider):
name="ReviewsSpider"
key=""
pagesize=200
topId=0
def __init__(self,key=None,*args,**kwargs):
self.key=key
super(eval(self.__class__.__name__),self).__init__(*args,**kwargs)
self.start_urls=["https://c.y.qq.com/soso/fcgi-bin/client_search_cp?ct=24&qqmusic_ver=1298&new_json=1&remoteplace=txt.yqq.song&searchid=55594271468033902&t=0&aggr=1&cr=1&catZhida=1&lossless=0&flag_qc=0&p=1&n=10&w=%s&g_tk_new_20200303=652127051&g_tk=652127051&loginUin=&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0"%(key)]
print(self.start_urls)
self.music_header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.167 Safari/537.36','Accept': '*/*','Accept-Encoding': 'gzip, deflate, br','Accept-Language': 'zh-CN,zh;q=0.9'}
def parse(self,response):
try:
data=response.body.decode()
data=json.loads(data)
songs=data['data']['song']['list']
if len(songs)==0:
print("not found by key=%s"%(self.key))
return
song=songs[0]
self.topId=song['id']
#mId=song['mid']
url="https://c.y.qq.com/base/fcgi-bin/fcg_global_comment_h5.fcg?g_tk_new_20200303=652127051&g_tk=652127051&loginUin=&hostUin=0&format=json&inCharset=utf8&outCharset=GB2312¬ice=0&platform=yqq.json&needNewCode=0&cid=205360772&reqtype=2&biztype=1&topid=%s&cmd=8&needmusiccrit=0&pagenum=0&pagesize=25&lasthotcommentid=&domain=qq.com&ct=24&cv=10101010"%(self.topId)
yield scrapy.Request(url=url,callback=self.getComments)
except Exception as err:
print(err)
def getComments(self,response):
try:
data=response.body.decode()
data=json.loads(data)
comments=data['hot_comment']['commentlist']
if len(comments)==0:
print("found comment error")
return
lastcommentid=comments[len(comments)-1]['rootcommentid']
url="https://c.y.qq.com/base/fcgi-bin/fcg_global_comment_h5.fcg?g_tk_new_20200303=652127051&g_tk=652127051&loginUin=676435008&hostUin=0&format=json&inCharset=utf8&outCharset=GB2312¬ice=0&platform=yqq.json&needNewCode=0&cid=205360772&reqtype=2&biztype=1&topid=%s&cmd=6&needmusiccrit=0&pagenum=1&pagesize=%d&lasthotcommentid=%s&domain=qq.com&ct=24&cv=10101010"%(self.topId,self.pagesize,lastcommentid)
yield scrapy.Request(url=url,callback=self.getHotComment)
except Exception as err:
print(err)
def getHotComment(self,response):
try:
data=response.body.decode()
data=json.loads(data)
comments=data['comment']['commentlist']
if len(comments)==0:
print("found comment error")
return
for comment in comments:
print(comment['rootcommentcontent'])
except Exception as err:
print(err)run.py
from scrapy import cmdline
key = input("输入关键字:")
cmdline.execute(("scrapy crawl ReviewsSpider -s LOG_ENABLED=False -a key=%s"%(key)).split())settting.py
DEFAULT_REQUEST_HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.167 Safari/537.36',
'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9'
}结果截图:

结语:
不难发现爬取一些简单的数据并不困难,在爬取资源文件的时候多注意资源id的获取