上一篇我们又介绍了26个Python内置函数。现回忆一下吧:
1.all
2.any
3.ascii
4.bin
5.bool
6.bytes
7.bytearray
8.callable
9.chr
10.compile
11.complex
12.dir
13.divmod
14.enumerate
15.eval
16.exec
17.format
18.frozenset
19.globals
20.locals
21.hash
22.hex
23.id
24.iter
25.oct
26.zip
有没有感觉很陌生的?
下面再来看看其他的函数:
1.filter
filter()函数接收一个函数 f 和一个list,这个函数 f 的作用是对每个元素进行判断,返回 True或 False,filter()根据判断结果自动过滤掉不符合条件的元素,返回由符合条件元素组成的新list。
例如,要从一个list [1, 4, 6, 7, 9, 12, 17]中删除偶数,保留奇数,首先,要编写一个判断奇数的函数:
def is_odd(x):
return x % 2 == 1
然后,利用filter()过滤掉偶数:
filter(is_odd, [1, 4, 6, 7, 9, 12, 17])
结果:[1, 7, 9, 17]
利用filter(),可以完成很多有用的功能,例如,删除 None 或者空字符串:
def is_not_empty(s):
return s and len(s.strip()) > 0
filter(is_not_empty, ['test', None, '', 'str', ' ', 'END'])
结果:['test', 'str', 'END']
注意: s.strip(rm) 删除 s 字符串中开头、结尾处的 rm 序列的字符。
当rm为空时,默认删除空白符(包括'\n', '\r', '\t', ' '),如下:
a = ' 123' a.strip()
结果: '123'
a='\t\t123\r\n' a.strip()
结果:'123'
2.map()函数
map()函数,它接收一个函数 f 和一个 list,并通过把函数 f 依次作用在 list 的每个元素上,得到一个新的 list 并返回。
例如,对于list [1, 2, 3, 4, 5, 6, 7, 8, 9]
如果希望把list的每个元素都作平方,就可以用map()函数:
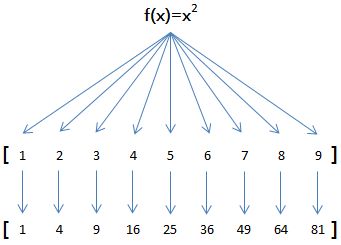
因此,我们只需要传入函数f(x)=x*x,就可以利用map()函数完成这个计算:
def f(x):
return x*x
print map(f, [1, 2, 3, 4, 5, 6, 7, 8, 9])
输出结果:
[1, 4, 9, 10, 25, 36, 49, 64, 81]
注意:map()函数不改变原有的 list,而是返回一个新的 list。
利用map()函数,可以把一个 list 转换为另一个 list,只需要传入转换函数。
由于list包含的元素可以是任何类型,因此,map() 不仅仅可以处理只包含数值的 list,事实上它可以处理包含任意类型的 list,只要传入的函数f可以处理这种数据类型。
可以在后面放多个列表
>>> def sqr(x):
... return x*x
...
>>> print map(sqr,a)
[1, 4, 9, 16, 25]
>>> def uin(y):
... return y+y
...
>>> print map(uin,(a,b))
[[1, 2, 3, 4, 5, 1, 2, 3, 4, 5], [5, 6, 7, 8, 5, 6, 7, 8]]
3、set
set是一个无序而且不重复的集合,有些类似于数学中的集合,也可以求交集,求并集等,下面从代码里来看一下set的用法,如果对这些用法不太熟悉的话,可以照着下面的代码敲一遍。
|
1
2
3
|
>>> s1
=
{
1
,
2
,
3
,
1
}
>>>
print
(s1)
{
1
,
2
,
3
}
|
由此可见set不包含重复数据。
|
1
2
3
4
5
6
|
>>> s2
=
set
([
2
,
5
,
6
])
>>>
print
(s2)
{
2
,
5
,
6
}
>>> s2
=
set
((
2
,
5
,
6
))
>>>
print
(s2)
{
2
,
5
,
6
}
|
由此可见set能够将可迭代的数据类型转为集合。
|
1
2
3
|
>>> s1.add(
5
)
>>>
print
(s1)
{
1
,
2
,
3
,
5
}
|
添加一个元素。
|
1
2
3
|
>>> s3
=
s1.difference(s2)
>>>
print
(s3)
{
1
,
3
}
|
返回s1中存在而不存在于s2的集合。
|
1
2
3
|
>>> s1.difference_update(s2)
>>>
print
(s1)
{
1
,
3
}
|
将s1中存在而s2不存在的数据,存放到s1中,s1数据被改变。
|
1
2
3
|
>>> s1.discard(
1
)
>>>
print
(s1)
{
3
}
|
删除集合s1中的元素 1,不存在的话不报错 。
|
1
2
3
4
5
6
7
|
>>> s1.remove(
3
)
>>>
print
(s1)
set
()
>>> s1.remove(
3
)
Traceback (most recent call last):
File
"
, line
1
,
in
KeyError:
3
|
删除集合s1中的元素 3,不存在的话报错。
|
1
2
3
4
5
6
|
>>> s1.update([
11
,
2
,
3
])
>>>
print
(s1)
{
2
,
3
,
11
}
>>> s1.update([
11
,
2
,
4
])
>>>
print
(s1)
{
2
,
3
,
4
,
11
}
|
更新s1中的元素,其实是添加 。
|
1
2
3
|
>>> k
=
s1.pop()
>>>
print
(s1)
{
3
,
4
,
11
}
print
(k)
2
|
删除一个元素,并将删除的元素返回给一个变量,无序的,所以并不知道删除谁。
|
1
2
3
4
5
|
>>> s1
=
{
1
,
2
,
3
,
4
}
>>> s2
=
{
3
,
4
,
5
,
6
}
>>> r1
=
s1.intersection(s2)
>>>
print
(r1)
{
3
,
4
}
|
取交集,并将结果返回给一个新的集合。
|
1
2
3
4
5
|
>>>
print
(s1)
{
1
,
2
,
3
,
4
}
>>> s1.intersection_update(s2)
>>>
print
(s1)
{
3
,
4
}
|
取交集,并将s1更新为取交集后的结果。
|
1
2
3
|
>>> k1
=
s1.issubset(s2)
>>>
print
(k1)
True
|
s1是否是s2的的子集是的话返回True,否则False 这里k1=True 。
|
1
2
3
|
>>> k2
=
s1.issuperset(s2)
>>>
print
(k2)
False
|
s1是否是s2的父集 k2=False 。
|
1
2
3
|
>>> k3
=
s2.isdisjoint(s1)
>>>
print
(k3)
False
|
s1,s2,是否有交集,有的话返回False,没有的话返回True 。
|
1
2
3
4
5
6
7
|
>>>
print
(s1)
{
1
,
2
,
3
,
4
}
>>>
print
(s2)
{
3
,
4
,
5
,
6
}
>>> r3
=
s1.union(s2)
>>>
print
(r3)
{
1
,
2
,
3
,
4
,
5
,
6
}
|
取并集将结果返回给r3 。
|
1
2
3
|
>>> r2
=
s1.symmetric_difference(s2)
>>>
print
(r2)
{
1
,
2
,
5
,
6
}
|
r2=s1并s2-s1交s2 ,即把两个集合共有的元素去掉。
|
1
2
3
|
>>> s1.symmetric_difference_update(s2)
>>>
print
(s1)
{
1
,
2
,
5
,
6
}
|
将s1更新为 s1并s2 - s1交s2 。
4、open
用于打开文件。
打开文件的模式有:
- r,只读模式(默认)。
- w,只写模式。【不可读;不存在则创建;存在则删除内容;】
- a,追加模式。【可读; 不存在则创建;存在则只追加内容;】
"+" 表示可以同时读写某个文件
- r+,可读写文件。【可读;可写;可追加】
- w+,无意义
- a+,同a
"b"表示处理二进制文件(如:FTP发送上传ISO镜像文件,linux可忽略,windows处理二进制文件时需标注)
- rb
- wb
- ab
eg.
f = open('ha.ini.bak', 'w') # 以只写模式打开文件
f.close() # 关闭文件
with open('ha.ini') as fy, open('ha.ini.bak', 'w') as fb: # with 模式打开文件,可以打开多个,也不用关心关闭的问题。
for i in fy:
pass
5.isinstance # 判断对象是否属于类
6.issubclass # 判断类B是否属于A的子类
class A:
def __iter__(self):
return iter([11,22,33])
class B(A):
def test(self):
print('我是B类的test函数。')
obj1 = A()
obj2 = B()
if isinstance(obj1,A): # isinstance 判断对象obj1是否属于A类
print('对象obj属于类A。')
print(isinstance(obj2.test,A)) # 报错,第一个参数必须是对象
print(issubclass(B,A)) # issubclass判断类B是否属于A的子类
7、8、9、10
hasattr、getattr、setattr、delattr 这四个函数放在一起,因为他们共同实现了一个功能:
反射
该四个函数分别用于对对象内部执行:检查是否含有某成员、获取成员、设置成员、删除成员。
class Foo(object):
def __init__(self):
self.name = 'wupeiqi'
def func(self):
return 'func'
obj = Foo()
# #### 检查是否含有成员 ####
hasattr(obj, 'name')
hasattr(obj, 'func')
# #### 获取成员 ####
getattr(obj, 'name')
getattr(obj, 'func')
# #### 设置成员 ####
setattr(obj, 'age', 18)
setattr(obj, 'show', lambda num: num + 1)
# #### 删除成员 ####
delattr(obj, 'name')
delattr(obj, 'func')
11.silce
该函数返回已序列切片(slice)对象,该对象表示由range(start,stop,step)指定的索引集。如果给出一个参数,此参数就作为 stop参数值;如果给出两个参数,它们就作为start和stop的参数值;任何未给出参数值的参数默认取值为None。序列切片对象有3个属性 (start,stop,和step),这3个属性仅仅返回要提供给slice()函数的参数
myslice = slice(5)
print(myslice)
l = list(range(10))
print(l[0:5:1])
print(l[myslice])
print(l[:5])
slice(None, 5, None)
[0, 1, 2, 3, 4]
[0, 1, 2, 3, 4]
[0, 1, 2, 3, 4]
12、13、14
calssmethod、staticmethod、property 这三个函数都是在类中使用的,后面会详细讲到
calssmethod:类方法:由类调用; 至少一个cls参数;执行类方法时,自动将调用该方法的类复制给cls;
staticmethod:静态方法:由类调用,无默认参数;
property:在普通方法的基础上添加 @property 装饰器来定义属性;
15、__import__
使用__import__函数获得特定函数:
def getfunctionbyname(module_name, function_name):
module = __import__(module_name)
return getattr(module, function_name)
还可以使用这个函数实现延迟化的模块导入:
class LazyImport:
def __init__(self, module_name):
self.module_name = module_name
self.module = None
def __getattr__(self, name):
if self.module is None:
self.module = __import__(self.module_name)
return getattr(self.module, name)
string = LazyImport("test")
print(string.function1)
16、memoryview
本函数是返回对象obj的内存查看对象。所谓内存查看对象,就是对象符合缓冲区协议的对象,为了给别的代码使用缓冲区里的数据,而不必拷贝,就可以直接使用。
v = memoryview(b'abc123')
print(v[1])
print(v[0])
17、super
主动执行父类的方法 ,类中会详细介绍