python爬取前程无忧scrapy存mogondb案例
一、分析网页
新:python爬取前程无忧scrapy存mogondb案例+可视化
原网页直达
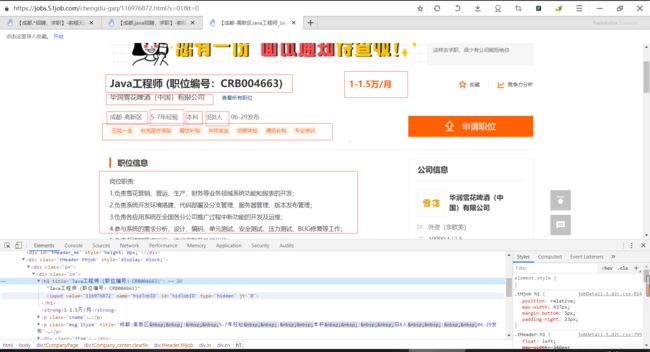
1、比如java字段,可以先拿到全部的el获取java字段的href,然后在逐个访问进入详情页

2、编写xpath://*[@id=“resultList”]/div/p/span/a/@href

逐个去编写相应字段的xpath
废话不多,先上源码,我懂的
-- coding: utf-8 --
spiders.py源码
import scrapy
class QianchenSpider(scrapy.Spider):
name = 'qianchen'
allowed_domains = ['51job.com']
#实现翻页
def start_requests(self):
for x in range(1, 50):
url = "https://search.51job.com/list/090200,000000,0000,00,9,99,java,2,{}.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=".format(x)
yield scrapy.Request(
url,
callback= self.parse
)
def parse(self, response):
#print(response.text)打印网址源码
#选择出网址列表
selectors = response.xpath('//div[@class="el"]')
print(len(selectors))
for selector in selectors:
#详情页网址
url = selector.xpath('./p/span/a/@href').get()
if url:
print(url)
#进入详情页 发出请求将结果交给parseDatail函数
yield scrapy.Request(url,callback=self.parseDatail)
def parseDatail(self,response):
'''
这个函数 用来处理详情页的数据
:param response:详情页的结果
:return:详情页提取的数据
'''
job_name=response.xpath('/html/body/div[3]/div[2]/div[2]/div/div[1]/h1/text()').get(default='')
job_jingyan=response.xpath('/html/body/div[3]/div[2]/div[2]/div/div[1]/p[2]/text()[2]').get(default='')
job_gongsi_name=response.xpath('/html/body/div[3]/div[2]/div[2]/div/div[1]/p[1]/a[1]/text()').get(default='')
job_dizhi=response.xpath('/html/body/div[3]/div[2]/div[3]/div[2]/div/p/text()').get(default='')
job_xingzi=response.xpath('/html/body/div[3]/div[2]/div[2]/div/div[1]/strong/text()').get(default='')
job_link=response.xpath('/html/body/div[3]/div[2]/div[2]/div/div[1]/p[1]/a[1]/@href').get(default='')
job_zhizhe=response.xpath('/html/body/div[3]/div[2]/div[3]/div[1]/div/p/text()').get(default='')
items = {
'职位:':job_name,
'待遇:':job_jingyan,
'就职公司:':job_gongsi_name,
'就职地址:':job_dizhi,
'薪资:':job_xingzi,
'公司链接:':job_link,
'员工职责:':job_zhizhe
}
yield items
item.py源码
class QianchengItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
job_name = scrapy.Field() # 职位名称
job_link = scrapy.Field() # 职位链接
job_info = scrapy.Field() # 职位要求
job_tags = scrapy.Field() # 职位待遇
company = scrapy.Field() # 公司名称
address = scrapy.Field() # 公司地址
salary = scrapy.Field() # 薪资
settings.py源码
# -*- coding: utf-8 -*-
# Scrapy settings for qiancheng project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'qiancheng'
SPIDER_MODULES = ['qiancheng.spiders']
NEWSPIDER_MODULE = 'qiancheng.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'qiancheng (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
# 'Cookie': 'guid=46fc4fe107b6dc2f8ce495306768785f; nsearch=jobarea%3D%26%7C%26ord_field%3D%26%7C%26recentSearch0%3D%26%7C%26recentSearch1%3D%26%7C%26recentSearch2%3D%26%7C%26recentSearch3%3D%26%7C%26recentSearch4%3D%26%7C%26collapse_expansion%3D; adv=adsnew%3D1%26%7C%26adsnum%3D2168935%26%7C%26adsresume%3D1%26%7C%26adsfrom%3Dhttps%253A%252F%252Fwww.baidu.com%252Fbaidu.php%253Fsc.060000KKXYb9K48fSdSWZI9PPrBzjoMfr5PHUXuS-R6uDVPY-YQnOPLw43jmiLj1ChM205AbAnGId5-F_OHE1JQvpCF7Pp9reLGfJnwkAybc7gt_cFu0iM0zQnRWsLblrjQmqkl8nbQYonIoEEBz95-W4srJep_dzZv6YiV9U9iaZq3gZczBolWpO8eKaCPZEqlzzH5S1hfeS9oeJ9e4allc6xwR.DR_NR2Ar5Od66CHnsGtVdXNdlc2D1n2xx81IZ76Y_u2SMuE3e8orgAs1SOOo_9OxOBI5lqAS61kO56OQS9qxuxbSSjO_uPqjqxZOg7SEWSyWxSrSrOFIqZO03OqWCOgGJ_EOU3c54DgSdq7Ol7UOSkSLweUEvOovqXdWujyhk5W_zggun-YPOub8LS2yThieGHYqhOkRojPakgug_v20.U1Yk0ZDqkea11neXYtT0TA-W5H00IjLZ_Q5n1VeHV0KGUHYznWR0u1dEugK1n0KdpHdBmy-bIfKspyfqnW60mv-b5Hc1P0KVIjYknjD4g1DsnHIxn1Dzn7tknjfYg1nvnjD0pvbqn0KzIjYYnH60uy-b5Hnznjb3g1DYPHwxn1DvP1KxnWDsrH9xn1DvPWKxn1DLPWNxn1csPjuxn103nWwxn1D3Pj60mhbqnHR3g1csP7tznHT0UynqnH0snNtkrjRsP10vnHc1g1Dsn-tknjFxn0KkTA-b5H00TyPGujYs0ZFMIA7M5H00mycqn7ts0ANzu1Yz0ZKs5H00UMus5H08nj0snj0snj00Ugws5H00uAwETjYs0ZFJ5H00uANv5gKW0AuY5H00TA6qn0KET1Ys0AFL5HDs0A4Y5H00TLCq0A71gv-bm1dsTzdMXh93XfKGuAnqiD4a0Zw9ThI-IjYvndtsg1DdnsKYIgnqnHnYnH6LrjTYnjRsn1RdrjDLrjn0ThNkIjYkPHbzP1cznjbdnWc30ZPGujdhnHfYmH6kn10snjubnW9h0AP1UHdanHRkwbNDnYF7PRN7fWRk0A7W5HD0TA3qn0KkUgfqn0KkUgnqn0KlIjYs0AdWgvuzUvYqn7tsg1KxnH0YP-ts0Aw9UMNBuNqsUA78pyw15HKxn7tYnWnYn1mkg1fzn1f1PW7xn0Ksmgwxuhk9u1Ys0AwWpyfqn0K-IA-b5iYk0A71TAPW5H00IgKGUhPW5H00Tydh5H00uhPdIjYs0A-1mvsqn0KlTAkdT1Ys0A7buhk9u1Yk0Akhm1Ys0AwWmvfq0AFbpyfqfWn1PYnkrDm4rRn3wWwKwDwDrRmzrjIDPDwAPWm3wWR0mMfqn0KEmgwL5H00ULfqn0KETMKY5H0WnanWnansc10Wna3snj0snj0WnanWnanVc108nj0snj0sc1D8nj0snj0s0Z7xIWYsQWb1g108njKxna3sn7tsQW0Yg108njPxna31P0KBTdqsThqbpyfqn0KWThnqPj0kPHc%2526word%253D%2525E5%252589%25258D%2525E7%2525A8%25258B%2525E6%252597%2525A0%2525E5%2525BF%2525A7%2526ck%253D4718.2.136.197.556.289.549.143%2526shh%253Dwww.baidu.com%2526us%253D1.0.1.0.0.0.0%2526bc%253D110101%26%7C%26; partner=www_baidu_com; 51job=cenglish%3D0%26%7C%26; search=jobarea%7E%60090200%7C%21ord_field%7E%600%7C%21recentSearch0%7E%60090200%A1%FB%A1%FA000000%A1%FB%A1%FA0000%A1%FB%A1%FA00%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA9%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA0%A1%FB%A1%FApython%A1%FB%A1%FA2%A1%FB%A1%FA1%7C%21recentSearch1%7E%60090500%A1%FB%A1%FA000000%A1%FB%A1%FA0000%A1%FB%A1%FA00%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA9%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA0%A1%FB%A1%FAPython%A1%FB%A1%FA2%A1%FB%A1%FA1%7C%21recentSearch2%7E%60090500%A1%FB%A1%FA000000%A1%FB%A1%FA0000%A1%FB%A1%FA00%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA9%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA0%A1%FB%A1%FAjava%A1%FB%A1%FA2%A1%FB%A1%FA1%7C%21recentSearch3%7E%60090500%A1%FB%A1%FA000000%A1%FB%A1%FA0000%A1%FB%A1%FA00%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA9%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA0%A1%FB%A1%FA%A1%FB%A1%FA2%A1%FB%A1%FA1%7C%21',
'Host': 'jobs.51job.com',
'Referer': 'https://search.51job.com/list/090200,000000,0000,00,9,99,python,2,1.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare=',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'same-site',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36',
}
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'qiancheng.middlewares.QianchengSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'qiancheng.middlewares.QianchengDownloaderMiddleware': 543,
#}
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'qiancheng.pipelines.QianchengPipeline': 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
接下来就是编辑管道文件pipelines.py
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
from pymongo import MongoClient
import matplotlib.pylab as pyl
import pandas as pda
class QianchengPipeline:
def open_spider(self,ii):
self.db = MongoClient('localhost', 27017).zh_db
self.collection = self.db.zh_all
def process_item(self, item, spider):
self.collection.insert_one(dict(item))
return item
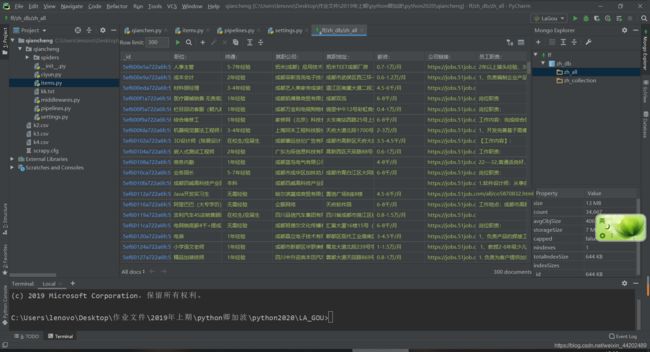
注意:使用mogondb数据库,应先安装哦
1,pymogon库
pip install pymogon
2、下载mogon 插件

插件下载重启pycharm后出现如图

+号,连接到你本地的mogondb数据库
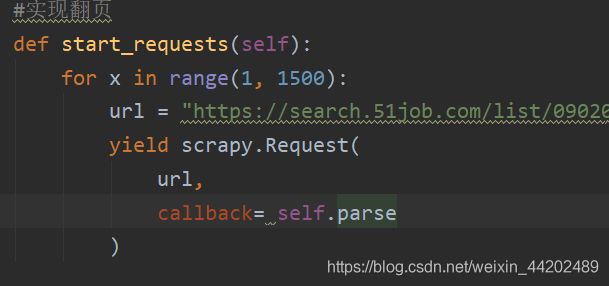
最后如果想爬取整栈的话只需要修改
原href=https://search.51job.com/list/090200,000000,0000,00,9,99,java,2,{}.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=
新href=https://search.51job.com/list/090200,000000,0000,00,9,99,*,2,{}.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=
修改你要爬取的页数

谢谢观看!,喜欢可以点个赞呢,嘿嘿!!!