Flask-SQLAlchemy与蓝图(Blueprint)配置
Flask_数据库(SQLAlchemy)
ORM:对象-关系映射 【object-Relation Mapping】
作用:实现模型对象到关系数据库数据的映射
图解:

优点:
1.面向对象编程而不是面向数据库,对数据的操作都 转换成对类属性和方法的操作,不需要写sql语句
2.实现了数据模型和数据的解耦,解决了不同数据操作上的差异
缺点:
1.相对于SQL语句操作,性能损失。因为是将对象转SQL,将结果转对象造成的
Flask_SQLAlchemy
定义:关系型数据库框架,对数据库的抽象,提高开发效率
安装:
pip istall flask-sqlalchemy
pip install flask-mysqldb 【连接的数据库的驱动】
连接配置:
app.config['SQLALCHEMY_DATABASE_URI']="mysql://root:[email protected]:3306/test"
【连接数据库,名称、账号、密码、地址、端口、数据库名】
其他配置:
样式:app.config['xx'] 【】
参数:
动态追踪修改配置:SQLALCHEMY_TRACK_MODIFICATIONS = True
查询时显示原始SQL语句:SQLALCHEMY_ECHO = True
映射binds连接url的字典:SQLALCHEMY_BINDS
显示禁用查询记录(测试调试时使用): SQLALCHEMY_RECORD_QUERIES
显示禁用原生unicode支持:SQLALCHEMY_NATIVE_UNICODE
数据库连接池大小(默认5):SQLALCHEMY_POOL_SIZE
数据库连接池的连接超时时间(默认10):SQLALCHEMY_POOL_TIMEOUT
自动收回连接时间(默认8小时,MYSQL自动为2小时):SQLALCHEMY_POO_RECYCLE
连接数据库(示例)
Posthgres:postgresql://scott:tiger@localhost/mydatabase
MySQL:mysql://scott:[email protected]:1521/sidname
Oracle:oracle://scott:[email protected]:1521/sidname
SQLite:sqlite:////absolute/path/to/foo.db
字段类型(类型)
Integer = int(32)
Smalllnteger = int(16)
BigInteger = int(不限制精度)
Float = float(浮点数)
Numeric = decimal.Decimal(整数32)
String = str(字符串)
Text = str(字符串)
Unicode = unicode(长字符串)
Unicode Text = unicode(长字符串)
Boolean = bool(布尔值)
Date = datetime.date(时间)
Time = datetime.datetime(日期和时间)
LargeBinary = str(二进制文件)
列选项(权限)
primary_key True为主键
unique True为唯一
index True为索引
nullable True允许为空,False不允许
default 定义默认值
ForeignKey 外键
关系选项(连接)
backref 关系另一模型添加反向引用
primary join 两个模型之间使用的联结条件
uselist False标识不使用列表,使用标量值?
order_by 排序方式
secondary 多对多关系表的名字
secondary join 多对多的二级联结条件
基本操作
会话:db.session
提交:commit()
查询:query 可通过过滤器精确
查询过滤器
filter() 用于添加查询条件进行数据过滤
filter_by() 等值过滤器添加原查询,返回新查询
limit 返回指定值限定的结果
offset() 偏移查询结果,返回新查询【指定开始位置偏移查询】
order_by() 对查询结果排序,返回新查询
group_by() 对查询结果分组,返回新查询
查询执行器
all() 列表形式放回所有结果
first() 返回查询的第一个结果,没查到返回None
first_or_404() 返回查询的第一个结果,没查到返回404
get() 返回指定主键对应的行,不存在返回None【根据主键查询】
get_or_404() 返回指定主键对应的行,不存在返回404
count() 返回查询结果的数量
paginate() 返回paginate对象,包含指定范围内的结果
表操作
db.create_all() 创建
db.deop_all() 删除
插入单条数据:
模板类对象.属性 ="值" 设置值
db.session.add(模板对象) 添加
db.session.commit() 提交
插入多条数据:
db.session.add([对象1,对象2...]) 【无序】
创建步骤:
1.新建FLask对象
2.配置数据库配置,并加载至Flask对象
3.根据Flask对象新建db
4.建立模型类
db.Column(设置类型和约束)
db.relationship('xx',backref='yy')[关联设置]
5.进行操作
db.session.add_all([x1,x2..])
db.session.commit()[提交数据库]
db.session.rollback()[事务回滚]
连接数据库配置信息
py2: 使用的是 mysqldb
py3:使用的是 pymsql
项目中在init文件中: import pymsql / pymsql.install_as_MYSQLdb()
精准查询
Students.query.filter_by(student_name = 'f').all()
获取student=f的全部数据
模糊查询
Students.query.filter(Students.student_name.like('%d%')).all()
获取 student_name以d开头或者结尾的全部数据
注:不一定是like,可以是endswith字符串方法,且判断提交必须是类加字段名
倒序查询
Students.query.order_by(Students.id.desc()).all()
以id作为拍讯输出所有数据
外键关联
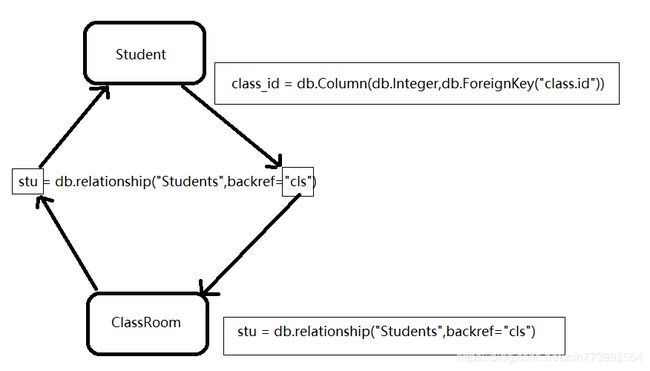
sudent中有class表id作为外键,class则创建relationship,
class可以通过stu获取student中的信息,student可以通过cls获取class信息
stu = db.relationship("Students",backref="cls")
修改结果
temp = Students.query.get(4) 查询
temp.student_name = "xxx" 修改
db.session.commit() 提交
删除数据
temp = Students.query.get(4) 查询
db.session.delete(temp) 删除
db.session.commit() 提交
数据库迁移
作用:直接修改数据库中的结构而不影响数据
安装:pip install flask-migrate
导入:
from flask_sqlalchemy import SQLAIchemy
from flask_migrate import Migrate,MigrateCommand
from flask_script import Shell,Manager 【附加在manager对象上】
样式:
app = Flask(__name__)
manager = Manager(app)
.........
db = SQLAlchemy(app) # 创建SQLAlchemy对象
migrate = Migrate(app, db) # 初始化migrate对象,绑定应用和db
manager.add_command('db',migrateCommand) # 将migrateCommand命令添加至manager中,'db'为自定义名称,作为命令行运行时的名称
命令行操作:
1.python aa.py db init 【创建迁移文件夹】
2.python aa.py db migrate -m '注释信息' 【创建版本表,文件名包含注释信息】
3.python aa.py db upgrad 【更新数据库】
4.python aa.py db history 【查看历史版本】
5.python aa.py db downgrade '系统定义的版本号' 【回退数据库】
注意:
1.迁移后数据库中会有因为迁移生成的表,不要做任何修改
2.迁移时,修改了数据库结构,新增字段必须设置为允许为空,才能正常迁移
3.迁移库会将数据库中的全部表删除,只留下建立了模型类的表
4.迁移时注意部分配置信息的前后,比如在新建用户表,如果采用内部的表结构,需要先在配置修改,才能迁移
5.如果需要修改数据库迁移,重复2,3步即可
关系模型:
一对多:用户与发布的帖子
多对多:讲师与班级 【需要建立1张关联表,将其他两张表的主键以外键创建在表内】
自关联一对多:评论与子评论
自关联多对多:用户与关注的其他用户
Flask_Buleprint(蓝图)
概述:存储操作方法的容器,将Flask程序进行模块化
属性:
1.在程序中可以有多个Blueprint
2.可以将其注册到任何一个未使用的URL下
3.一个应用中,一个模块可以注册多次
4.Blueprint单独具有自己的模板、静态文件或其他通用方法,不是必须要要实现视图与函数
5.在一个应用初始化时,就应该注册使用的Blueprint
注:不是一个完整应用,必须注册在某个应用中
使用步骤:
1.创建蓝图对象
admin=Blueprint('xx', __name__) 【'xx'中的名称自定义,用于区分其他同名的蓝图】
2.进行操作
@admin.route('/')
def admin_txt():
return "success"
3.应用对象注册蓝图对象
from 文件夹 import 蓝图对象
app.register_blueprint(admin.url\_prefix='/admin')
4.应用启动后,可以通过/admin/访问蓝图中定义的视图
运行机制:
1.蓝图保存一组将来可以在应用对象执行的操作
2.当在应用对象上调用route装饰器注册路由时,将修改对象的url_map路由表
3.蓝图对象没有路由表,在蓝图对象上调用route装饰器注册路由时,只是在内部的一个延迟操作记录列表defered_functions中添加了一项
4.执行应用对象 register_blueprint() 方法时,应用对象将从蓝图的 defered_functions 列表中取出每一项,并以自身作为参数执行该匿名函数,也就是调用应用对象的 add_url_rule() 方法,此时才真正的修改应用对象的路由表