【Python网络爬虫实战篇】使用selenium+requests爬取下载高清源视频:关于爬取m3u8文件链接解析为ts视频合并成mp4视频的分析实战
这两天博主在摸鱼时,偶然间接触到了流媒体的概念,一时间来了兴致。再加上之前博主有着七、八年的视频制作经验,深知视频素材获取的不易。因此,打算利用自己所学的python网络爬虫的知识,通过编写代码实现获取视频解析m3u8链接完成视频的下载功能。
目录
- 流媒体
- 流媒体的介绍
- 流媒体的分类
- 分析实战
- 编码过程
- 整体代码
- 总结
流媒体
流媒体的介绍
流媒体:从远程服务器传输过来的文件流(分段传输,例如:.ts视频)。
流媒体的分类
1.伪流媒体:边下边存,会保存下来,渐进式下载。
- 特征:能够暂停、看到时间(时长)、快进、后退。
- 协议:http/https。
2.实时流媒体:边下边播,不会保存,看不到时间。
- 协议:HLS(苹果端,流媒体的传输协议)/RTMP协议(Adobe,实时消息传输协议)
- 框架:ffmpeg(底层由纯C语言编写,用来进行解码的音视频播放器框架)
- 实时流媒体图示:

其中:
① ts:高清单独编辑码的视频文件。
② m3u8:记录文件的文件,ts的顺序记录在m3u8文件中。
- 视频合成指令(需要按照顺序命名,多个ts合并成一个ts):
cat *.ts>hecheng.mp4 # mac
copy /b *.ts hecheng.mp4 # windows
分析实战
编码过程
1.通过selenium的无头模式获取视频名称和m3u8长链接。
from selenium import webdriver
url = 'http://jx.618g.com/?url=https://v.qq.com/x/cover/0pj8vuntnocu797/o0034hawh6r.html'
# 开启无头模式提取视频m3u8路径地址
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
browser = webdriver.Chrome(options=chrome_options)
videoAnalysis = browser.get(url)
videoName = browser.title # 获取当前页面title值
print(videoName)
videoSrcAll = browser.find_element_by_id('player').get_attribute('src')
print(videoSrcAll)
browser.close()
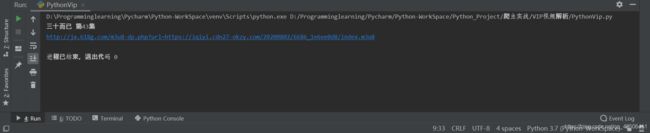
2.观察输出结果,发现我们所需要的m3u8链接的url应该是获取到的长链接去除http://jx.618g.com/m3u8-dp.php?url=的url,因此,我们只需要保留等于号后面的内容即可。
# 链接分割取出真正的m3u8
videoSrc = str(videoSrcAll).split('=')[1] # 取出“=”分割的右半部分
print(videoSrc) # 输出我们所需的url
res = requests.get(videoSrc).text
print(res) # 输出我们所需的url的内容

加上上述代码观察输出结果,发现我们已经成功解析出了我们所需要的m3u8链接的url。其中输出的url内容如下所示:
#EXTM3U
#EXT-X-STREAM-INF:PROGRAM-ID=1,BANDWIDTH=800000,RESOLUTION=1080x608
1000k/hls/index.m3u8
url的内容表示m3u8链接作了跳转,这个只是将文件设置为二次访问获取真实地址。因此我们只需将m3u8链接改为 https://iqiyi.cdn27-okzy.com/20200802/6686_1e6ee0d8/1000k/hls/index.m3u8 再次请求访问内容才能得到真正的m3u8文件内容。
3.将链接复制粘贴到浏览器,浏览器会自动下载m3u8文件,那么我们可以以此为模板,将刚刚第2步获取到的m3u8链接与其内容的第三行进行整合。
getShortSrc = res.split('\n')[2] # 获取文件第三行内容
print(getShortSrc)
noindexurl = url.replace('index.m3u8', '') # 删除url的index.m3u8
trueUrl = noindexurl + getShortSrc # 得到m3u8二次链接(真正的m3u8链接)
print(trueUrl)
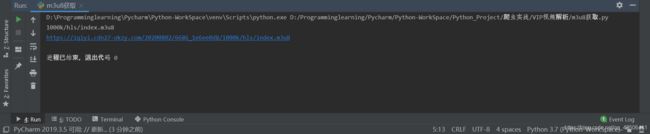
4.整合成功后,我们对真正的m3u8链接进行请求。
res1 = requests.get(trueUrl).text
print(res1)
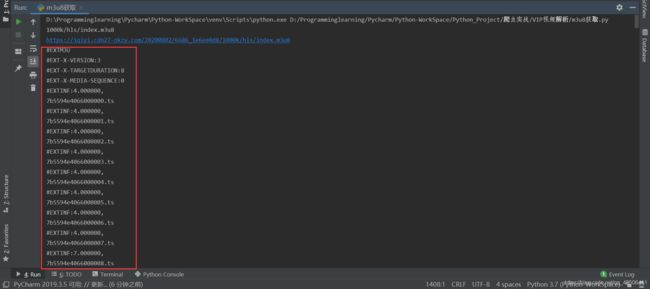
观察m3u8文件内容,其中第一行 “#EXTM3U” 表明这是一个 m3u8 格式的视频文件,“#EXTINF”后面的一行链接便是每一个视频流的文件地址。如果将链接输入到浏览器中访问,你将得到一个以 .ts 结尾的几秒钟视频文件。这个m3u8文件中所有的链接全部请求合并得到的就是一个完整的视频。
有时候得到的 m3u8 文件不一样,会有一行 “#EXT-X-KEY” ,说明这个视频是经过加密的,需要我们去解密才能得到视频,否则得到的视频文件打开就会报错。本次实战的视频解析网站解析出来的m3u8链接经过测试并未进行加密,因此不进行加密情况的讨论。
5.接下来,我们需要提取出每一个ts视频链接并保存到列表中。根据第4步观察的ts视频名称,我们需要按照第3步的整合方法ts视频名称前加上前缀“https://iqiyi.cdn27-okzy.com/20200802/6686_1e6ee0d8/1000k/hls/”,这样整合而成的ts链接才是真正下载下来能观看的高清单独编辑码的视频文件。(注意:ts链接前缀和m3u8链接前缀相同,不同的只是将index.m3u8改成ts名称)之后,将ts链接全部保存在一个列表中。
tslist = re.findall('EXTINF:(.*),\n(.*)\n#', res1) # 得到每一个ts视频名称
newlist = []
for i in tslist:
newlist.append(i[1]) # 将ts视频名称添加到列表中
# print(newlist) # 输出列表
noindextrueurl = trueUrl.replace('index.m3u8', '') # 删除trueurl的index.m3u8
tslisturl = [] # 构造链接空列表
for i in newlist:
tsurl = noindextrueurl + i
tslisturl.append(tsurl)
print(tslisturl) # 输出列表

6.获取所有的ts链接并合并成mp4视频。这一步在本次实战中由于我是用普通文件二进制追加(ab+)的形式合并的,因此速度较慢。建议有能力的同学尝试改用多线程,因为我还没学习多线程这一块暂时就这样了,未来会进行多线程的改写。
def downloadvideo(urllist, videoName):
header = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'
}
path = './' + videoName.strip() + ".mp4"
videolen = len(urllist)
for i in urllist:
print("视频下载中...剩余" + str(videolen) + "个ts视频未下载!")
videolen = videolen - 1
r = requests.get(i, header).content
# tsname = i[-9:-3] + '.ts'
with open(path, 'ab+') as f:
f.write(r)
# f.close()
print("视频下载完毕!")
整体代码
from selenium import webdriver
import requests
import re
def getvideourl(url):
# 开启无头模式提取视频m3u8路径地址
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
browser = webdriver.Chrome(options=chrome_options)
browser.get(url)
videoName = browser.title # 获取当前页面title值
print(videoName) # 输出视频名称
videoSrcAll = browser.find_element_by_id('player').get_attribute('src')
# print(videoSrcAll) # 输出视频m3u8长链接(带前缀)
browser.close()
# 链接分割取出第一个m3u8链接
videoSrc = str(videoSrcAll).split('=')[1] # 取出“=”分割的右半部分
# print(videoSrc) # 输出视频m3u8第一个链接
res = requests.get(videoSrc).text
# print(res) # 输出所请求的m3u8第一个链接中的内容
getShortSrc = res.split('\n')[2]
# print(getShortSrc) # 获取m3u8第一个链接中的内容的第三行
noindexurl = videoSrc.replace('index.m3u8', '') # 删除第一个m3u8链接的index.m3u8
# 得到m3u8二次链接(真正的m3u8链接)
trueUrl = noindexurl + getShortSrc
# print(trueUrl) # 输出真正的m3u8链接(第二个m3u8链接)
res1 = requests.get(trueUrl).text
# print(res1) # 输出真正的m3u8链接的内容(第二个m3u8链接)
tslist = re.findall('EXTINF:(.*),\n(.*)\n#', res1) # 得到每一个ts视频链接
newlist = []
for i in tslist:
newlist.append(i[1])
# print(newlist) # 输出列表
noindextrueurl = trueUrl.replace('index.m3u8', '') # 删除trueurl的index.m3u8
tslisturl = []
for i in newlist:
tsurl = noindextrueurl + i
tslisturl.append(tsurl)
print(tslisturl) # 输出列表
return tslisturl, videoName
def downloadvideo(urllist, videoName):
header = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'
}
path = './' + videoName.strip() + ".mp4"
videolen = len(urllist)
for i in urllist:
print("视频下载中...剩余" + str(videolen) + "个ts视频未下载!")
videolen = videolen - 1
r = requests.get(i, header).content
# tsname = i[-9:-3] + '.ts'
with open(path, 'ab+') as f:
f.write(r)
# f.close()
print("视频下载完毕!")
if __name__ == '__main__':
getVideoUrl = input("请输入视频链接:") # https://v.qq.com/x/cover/0pj8vuntnocu797/o0034hawh6r.html
url = 'http://jx.618g.com/?url=' + getVideoUrl
tslisturl,videoName = getvideourl(url) # 获取ts视频列表
downloadvideo(tslisturl, videoName) # 下载视频
总结
本次实战由于采用普通文件二进制追加(ab+)的形式将ts视频合并成mp4视频,因而耗费时间较长,所以不再展示最终效果图。但是经过亲身测试,已经证明了代码的可行性,只是实用性不强(下载太慢),未来会更新为多线程下载方式。本次对视频的爬取下载,只是为了学习了解m3u8文件的构造。总体来说较为成功。