标准BP算法详细解析
下面的过程参考西瓜书
注意是标准BP噢,意思是一个单拿出一个样本来看的bp,单位是一个样本噢~
一、图解以及符号定义
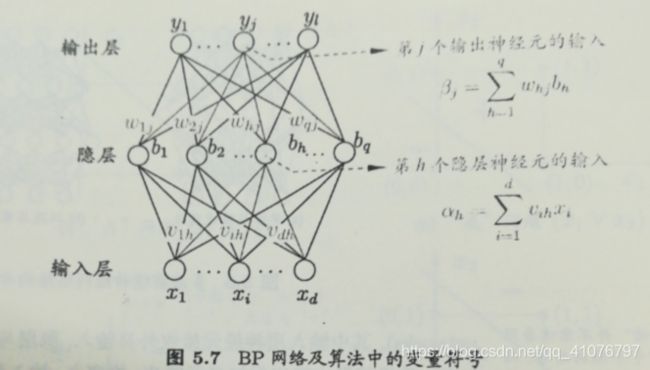
我要再啰嗦一遍,写成我习惯的方式:
二、过程解释
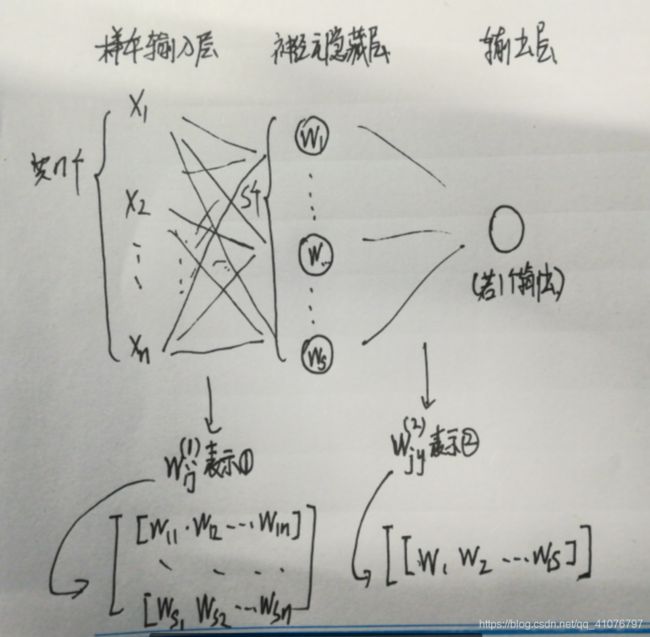
①表示的是第一层第i个权值向量和第j个输入相乘的权值
②表示的是第二层第j个权值向量和第y个输入相乘的权值,很明显,只有一个输出所以j=1,y取值1~S
由此我们可以继续得到下面这些参数:
a:隐藏层的输入

隐藏层的输出:

解释一下b和f:
b是偏置值:

f是sigmoid激活函数
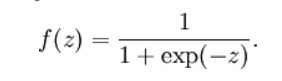
再看从隐藏层到输出层的过程:
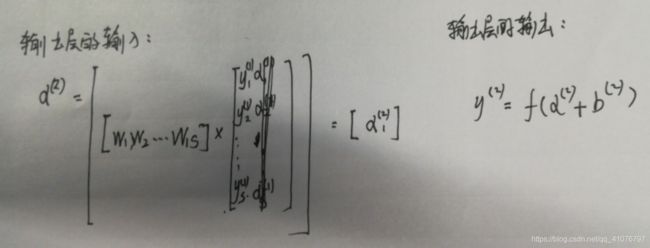
上面其实就是正向传播的过程,重点来了,下面是反向传播的过程。
我们需要根据输出来修改每一层的权值向量了,这里分为两类讨论,一类是修改输出层的权值向量,另一类是修改中间层(隐藏层)的权值向量,以上面为例,这两类分别就是修改W(2)和修改W(1)。
三、反向传播

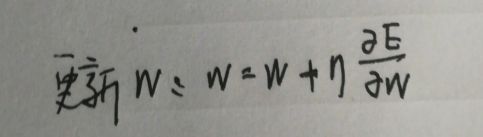
我们知道误差与输出y(2)有关,而输出与输入a(2)有关,输入又与w(2)有关,所以根据链式求导法则:
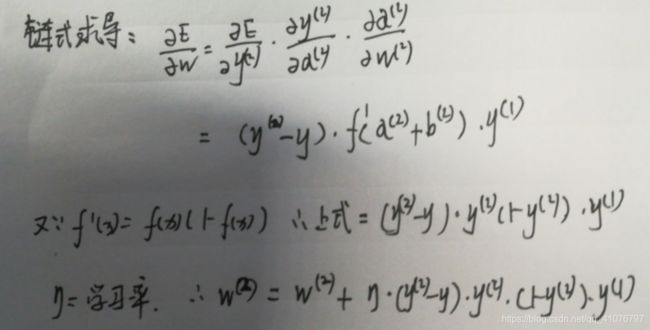
同理更新b,

到此为止,第一类更新就写完了,下面要写修改中间层的权值更新了。

四、python代码实现
import numpy as np
x=np.array([
[1,2,3],
[4,5,6]
],dtype=np.float64)
w1=np.random.rand(3,4)#第一层四个神经元,三个特征
b1=np.random.rand(1,4)
w2=np.random.rand(4,2)#输出层有两个神经元,上一层每个神经元生成一个特征,共四个特征
b2=np.random.rand(1,2)
lr=0.1#学习率
#真正的y
y=np.array([
[8,2]
],dtype=np.float64)
def sigmoid(x):
return 1/(1+np.exp(-x))
for index,i in enumerate(x):
#对x中的每一个样本进行正`向传播
#中间层的输入
a1=np.dot(i,w1)#[1,4]
#隐藏层的输出
y1=sigmoid(a1+b1)#[1,4]
#输出层的输入
a2=np.dot(y1,w2)#[1,2]
#输出层的输出
y2=sigmoid(a2+b2)#[1,2]
#反向传播
g=np.multiply((y-y2),np.multiply(y2,(1-y2)))
#更新输出层的权值w和偏置值b
w2=w2+lr*np.dot(y1.T,g)
b2=b2+lr*g
print("第"+str(index+1)+"个样本")
print("更新后的输出层权重w2",w2)
print("更新后的输出层b2",b2)
print("下面开始更新中间层权重w1和偏置值b1")
w1=w1+lr*i.reshape(3,1)*np.multiply(np.multiply(y1,(1-y1)),np.dot(w2,g.T).T)
b1=b1+lr*np.multiply(np.multiply(y1,(1-y1)),np.dot(w2,g.T).T)
print("更新后的输出层权重w1", w1)
print("更新后的输出层b1", b1)公式都懂,但是这个向量化的过程着实是让我费了一番功夫。
用书上公式来讲吧:
实在是难以描述,我们看到西瓜书的102页上的图
以及103页的公式,很明显bh影响的只是权值的行,对于每一列的乘积是一样的,哎,不讲了,不好说。总之代码是对的。
------------------------------------------------第二天更新--------------------------------------------------
不描述出来还是咽不下这口气,下面的图示可能只有我能看懂吧,哈哈
正向传播:
反向传播更新输出层权重:
反向传播更新中间层权重:

上面公式推导倒不是很难,主要是代码向量化的过程,不想看算法推导的直接用上面python代码就好。