String详解(intern、StringBuffer、StringBuilder)
- “+”操作符,它执行的加入对原始类型(如int和double),重载对String对象进行操作。’+'两个字符串操作数进行串联。 java不考虑让开发者支持运算符重载。在支持运算符重载像C++语言,可以把一个“+”操作符来执行减法,引起不良代码。 “+”操作符是重载的内部支持字符串连接在java中的唯一操作符。注意到,“+”不在两个任意对象上工作。
字符串的方法
| SN | 方法 | 描述 |
|---|---|---|
| 1 | char charAt(int index) | 返回指定索引处的字符 |
| 2 | int compareTo(Object o) | 该字符串的另一个对象比较 |
| 3 | int compareTo(String anotherString) | 字典顺序比较两个字符串 |
| 4 | int compareToIgnoreCase(String str) | 按字典顺序比较两个字符串,忽略大小写差异 |
| 5 | String concat(String str) | 将指定字符串添加到该字符串的结尾处 |
| 6 | boolean contentEquals(StringBuffer sb) | 当且仅当此String表示字符与指定StringBuffer的顺序相同时返回true |
| 7 | static String copyValueOf(char[] data) | 返回表示所指定的数组中的字符序列的字符串 |
| 8 | static String copyValueOf(char[] data, int offset, int count) | 返回表示所指定的数组中的字符序列的字符串 |
| 9 | boolean endsWith(String suffix) | 测试此字符串是否以指定的后缀结束 |
| 10 | boolean equals(Object anObject) | 比较此字符串指定的对象 |
| 11 | boolean equalsIgnoreCase(String anotherString) | 这个字符串与另一个字符串比较,不考虑大小写 |
| 12 | byte getBytes() | 将此String使用平台默认的字符集的字节序列解码,并将结果存储到一个新的字节数组 |
| 13 | byte[] getBytes(String charsetName) | 将此String使用指定字符集的字节序列解码,并将结果存储到一个新的字节数组。ISO8859-1或GBK或UTF-8 |
| String(…) | 利用构造函数编码 | |
| 14 | void getChars(int srcBegin, int srcEnd, char[] dst, int dstBegin) | 将这个字符串的字符复制到目标字符数组 |
| 15 | int hashCode() | 返回此字符串的哈希码 |
| 16 | int indexOf(int ch) | 返回此字符串指定字符第一次出现处的索引 |
| 17 | int indexOf(int ch, int fromIndex) | 返回此字符串指定字符,从指定索引的搜索中第一次出现处的索引 |
| 18 | int indexOf(String str) | 返回此字符串的指定子第一次出现处的索引 |
| 19 | int indexOf(String str, int fromIndex) | 返回此字符串的指定从指定索引处的子字符串第一次出现的索引 |
| 20 | String intern() | 返回字符串对象规范表示形式 |
| 21 | int lastIndexOf(int ch) | 返回此字符串指定字符最后一次出现处的索引 |
| 22 | int lastIndexOf(int ch, int fromIndex) | 返回此字符串指定字符最后一次出现处的索引,从指定索引处开始向后搜索 |
| 23 | int lastIndexOf(String str) | 返回此字符串指定子最右边出现处的索引 |
| 24 | int lastIndexOf(String str, int fromIndex) | 返回此字符串的指定子最后一次出现处的索引,指定索引处向后开始搜索 |
| 25 | int length() | 返回此字符串的长度 |
| 26 | boolean matches(String regex) | 判断此字符串是否与给定的正则表达式匹配。 |
| 27 | boolean regionMatches(boolean ignoreCase, int toffset, String other, int ooffset, int len) | 检测两个字符串区域是否是相等的 |
| 28 | boolean regionMatches(int toffset, String other, int ooffset, int len) | 检测两个字符串区域是否是相等的 |
| 29 | String replace(char oldChar, char newChar) | 返回从此字符串中使用newChar替换oldChar所有出现的字符串 |
| 30 | String replaceAll(String regex, String replacement) | 这个替换字符串使用给定的正则表达式匹配并替换每个子字符串 |
| 31 | String replaceFirst(String regex, String replacement) | 这个替换字符串使用给定的正则表达式匹配替换第一个字符串 |
| 32 | String[] split(String regex) | 围绕给定的正则表达式的匹配来拆分此字符串 |
| 33 | String[] split(String regex, int limit) | 围绕给定的正则表达式的匹配来拆分此字符串 |
| 34 | boolean startsWith(String prefix) | 测试此字符串是否以指定的前缀开始 |
| 35 | boolean startsWith(String prefix, int toffset) | 检测此字符串是否从指定索引开始以指定前缀开始 |
| 36 | CharSequence subSequence(int beginIndex, int endIndex) | 返回一个新的字符序列,它是此序列的子序列 |
| 37 | String substring(int beginIndex) | 返回一个新字符串,它是此字符串的子串 |
| 38 | String substring(int beginIndex, int endIndex) | 返回一个新字符串,它是此字符串的子串 |
| 39 | char[] toCharArray() | 这个字符串转换为一个新的字符数组 |
| 40 | String toLowerCase() | 将所有在这个字符串中的字符的使用默认语言环境的规则转为小写 |
| 41 | String toLowerCase(Locale locale) | 将所有在这个字符串中的字符使用给定Locale的规则转为小写 |
| 42 | String toString() | 这个对象(这已经是一个字符串!)本身返回。 |
| 43 | String toUpperCase() | 所有的字符在这个字符串使用默认语言环境的规则转换为大写。 |
| 44 | String toUpperCase(Locale locale) | 所有的字符在这个字符串使用给定的Locale规则转换为大写 |
| 45 | String trim() | 返回字符串的副本,开头和结尾的空白省略 |
| 46 | static String valueOf(primitive data type x) | 返回传递的数据类型参数的字符串表示 |
String
-
String是一个final类,代表不可变的字符序列 。String对象的字符内容是存储在一个字符数组value[]中的。
-
实现了Serializable接口:表示字符串是支持序列化的。
-
实现了Comparable接口:表示String可以比较大小
-
String内部定义了final char[] value用于存储字符串数据
String:代表不可变的字符序列。简称:不可变性。
体现:
- 当对字符串重新赋值时,需要重写指定内存区域赋值,不能使用原有的value进行赋值。
- 当对现有的字符串进行连接操作时,也需要重新指定内存区域赋值,不能使用原有的value进行赋值。
- 当调用String的replace()方法修改指定字符或字符串时,也需要重新指定内存区域赋值,不能使用原有的value进行赋值。
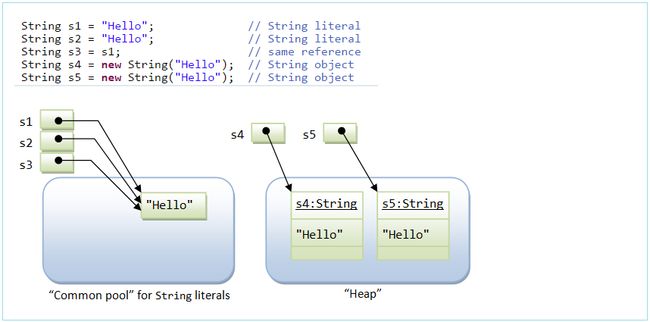
- 通过字面量的方式(区别于new)给一个字符串赋值,此时的字符串值声明在字符串常量池中。
- 字符串常量池中是不会存储相同内容的字符串的。
String s1 = "abc";//字面量的定义方式
String s2 = "abc";
System.out.println(s1 == s2);//比较s1和s2的地址值//true
\2. String位于java.lang包中,java程序默认导入java.lang包下的所有类。
\3. java字符串就是Unicode字符序列,例如字符串“java”就是4个Unicode字符’J’、’a’、’v’、’a’组成的。
\4. java没有内置的字符串类型,而是在标准java类库中提供了一个预定义的类String,每个用双引号括起来的字符串都是String类的一个实例。
构造器
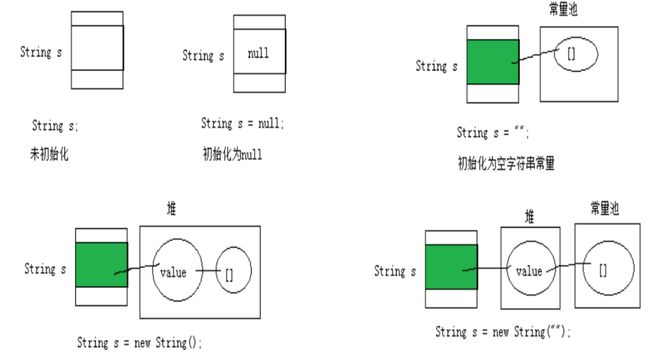
String str = "hello";//放在方法区(常量池)
//本质上this.value = new char[0];
String s1 = new String();//放在堆区
//this.value = original.value;
String s2 = new String(String original);
//this.value = Arrays.copyOf(value, value.length);
String s3 = new String(char[] a);
String s4 = new String(char[] a,int startIndex,int count);
判断String为空☆★
public static boolean isNotEmptyString(String str){
if (str != null && !"".equals(str.trim()) && !"null".equals(str)){
return true;
}
return false;
}
1. null表示这个字符串不指向任何的东西,如果这时候你调用它的方法,那么就会出现空指针异常。
2. ""表示它指向一个长度为0的字符串,这时候调用它的方法是安全的。
3. null不是对象,""是对象,所以null没有分配空间,""分配了空间,例如:
String str1 = null; str引用为空
String str2 = ""; str应用一个空串
str1还不是一个实例化的对象,儿str2已经实例化。
对象用equals比较,null用等号比较。
如果str1=null;下面的写法错误:
if(str1.equals("")||str1==null){ }
正确的写法是 if(str1==null||str1.equals("")){ //先判断是不是对象,如果是,再判断是不是空字符串 }
4. 所以,判断一个字符串是否为空,首先就要确保他不是null,然后再判断他的长度。
String str = xxx;
if(str != null && str.length() != 0) { }
https://www.cnblogs.com/Nico-luo/p/8024781.html
内存:堆和常量池
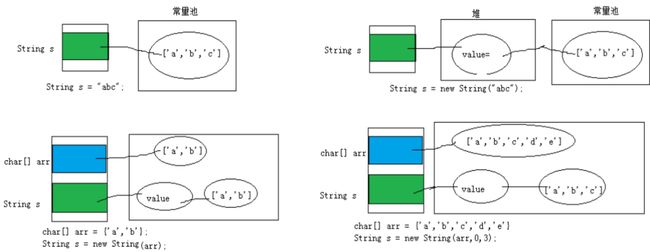
- s=“abc”;//放在了字符串常量池
- s =new String();//放在了堆区,value指向也是堆区[]
- s=new String("");//放在了堆区,但是value数组指向常量池
- s=new String(“abc”);//放在了堆区,但是value指向常量池中同一个abc
例子
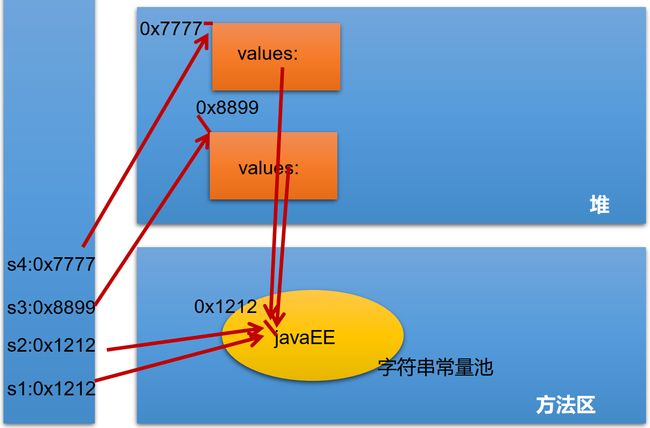
//如下4个语句,只在常量池中有一个javaEE
String s1 = "javaEE";
String s2 = "javaEE";
String s3 = new String("javaEE");//value指向常量池
String s4 = new String("javaEE");
System.out.println(s1 == s2);//true
System.out.println(s1 == s3);//false
System.out.println(s1 == s4);//false
System.out.println(s3 == s4);//false
//Person类中有成员String name和int age。构造器Person(String name, int age)
Person p1 = new Person();
p1.name = "atguigu";
Person p2 = new Person();
p2.name = "atguigu";
System.out.println(p1.name .equals( p2.name)); //
System.out.println(p1.name == p2.name); //
System.out.println(p1.name == "atguigu"); //
String s1 = new String("bcde");
String s2 = new String("bcde");
System.out.println(s1==s2); //
Person p1 = new Person("Tom",12);
Person p2 = new Person("Tom",12);
System.out.println(p1.name == p2.name);//true//value指向常量池同一个字符串

String s1 = "a";
//说明:在字符串常量池中创建了一个字面量为"a"的字符串。
s1 = s1 + "b";
//说明:实际上原来的“a”字符串对象已经丢弃了, 现在在堆空间中产生了一个字符串s1+"b"(也就是"ab")。如果多次执行这些改变串内容的操作,会导致大量副本字符串对象存留在内存中,降低效率。如果这样的操作放到循环中,会极大影响程序的性能。`
String s2 = "ab";
//说明:直接在字符串常量池中创建一个字面量为"ab"的字符串。
String s3 = "a" + "b";
//说明: s3指向字符串常量池中已经创建的"ab"的字符串。
String s4 = s1.intern();
//说明:堆空间的s1对象在调用intern()之后,会将常量池中已经存在的"ab"字符串赋值给s4。


常量与常量的拼接结果在常量池。 且常量池中不会存在相同内容的常量。
只要其中有一个是变量, 结果就在堆中
如果拼接的结果调用intern()方法, 返回值就在常量池中
==与equals
“==”:
①基本类型比较的是值;
②引用类型比较的是地址;
③不同类型不能用它比较,无法通过编译。
.equals(Object obj):
①用于应用类型的比较;
②String重写Object的equals方法,先用“==”判断地址,地址相同则直接返回true;不同的话再比较类型,类型不同则直接返回false;最后才比较内容。代码如下:
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String aString = (String)anObject;
if (coder() == aString.coder()) {
return isLatin1() ? StringLatin1.equals(value, aString.value)
: StringUTF16.equals(value, aString.value);
}
}
return false;
}
由于equals是Object的方法,意味着任意引用类型对象都可以调用,而且,入参是Object类型,所以,不同类型是可以用equals()方法的,不会像“==”一样编译异常,这也正是我经常遇到的一个小坑,例如:char chr = 'a',String str = "a",我经常会写成str.equals(chr),而且还傻傻的等着返回true,上面说到过,两个不同类型的变量比较,equals()会直接返回false。str.equals(chr+"")倒是可以解决。
equalsIgnoreCase(String str):
虽然也是用来比较的,但是不同于equals,它是String自己的方法而不是重写Object的方法,只有String对象能调用,而且入参只能是String。
\1. equals方法用来检测两个字符串内容是否相等。如果字符串s和t内容相等,则s.equals(t)返回true,否则返回false。
\2. 要测试两个字符串除了大小写区别外是否是相等的,需要使用equalsIgnoreCase方法。
\3. 判断字符串是否相等不要使用"=="。
忽略大小写的字符串比较
"Hello".equalsIgnoreCase("hellO");//true
字符串的比较"=="与equals()方法
public class TestStringEquals {
public static void main(String[] args) {
String g1 = "北京尚学堂";
String g2 = "北京尚学堂";
String g3 = new String("北京尚学堂");
System.out.println(g1 == g2); // true 指向同样的字符串常量对象
System.out.println(g1 == g3); // false g3是新创建的对象
System.out.println(g1.equals(g3)); // true g1和g3里面的字符串内容是一样的
}
}

字符串拼接
- 常量和常量的拼接结果在常量池,原理是编译器优化
- 常量池不会存在相同内容的常量
- 之后要其中有一个变量,结果就在堆中。变量拼接的原理是StringBuiler
- 如果拼接的结果调用intern(),则主动将常量池中还没有的字符串对象放入池中,并返回对象地址。(版本间有区别)
s3=s1+s2;//a+b
//a=new StringBuilder
//a.append(s1)
//a.append(s2);
//String s3 = s.toString();//约等于new String("ab");
//JDK5之前用给定是StringBuffer
//但如果是final的话跟字符串没区别
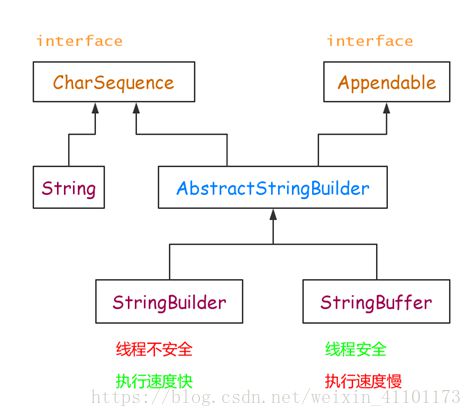
StringBuffer和StringBuilder
StringBuffer和StringBuilder非常类似,均代表可变的字符序列。 这两个类都是抽象类AbstractStringBuilder的子类,方法几乎一模一样。我们打开AbstractStringBuilder的源码,如示例8-11所示:
AbstractStringBuilder 部分源码:
abstract class AbstractStringBuilder implements Appendable, CharSequence {
/**
* The value is used for character storage.
*/
char value[];
//以下代码省略
}
显然,内部也是一个字符数组,但这个字符数组没有用final修饰,随时可以修改。因此,StringBuilder和StringBuffer称之为“可变字符序列”。那两者有什么区别呢?
- StringBuffer JDK1.0版本提供的类,线程安全,做线程同步检查, 效率较低。(记法:两个ff有先后顺序,代表同步)
- StringBuilder JDK1.5版本提供的类,线程不安全,不做线程同步检查,因此效率较高。 建议采用该类。
StringBuilder常用方法列表:
\1. 重载的public StringBuilder append(…)方法
可以为该StringBuilder 对象添加字符序列,仍然返回自身对象。
\2. 方法 public StringBuilder delete(int start,int end)
可以删除从start开始到end-1为止的一段字符序列,仍然返回自身对象。
\3. 方法public StringBuilder deleteCharAt(int index)
移除此序列指定位置上的 char,仍然返回自身对象。
\4. 重载的public StringBuilder insert(…)方法
可以为该StringBuilder 对象在指定位置插入字符序列,仍然返回自身对象。
\5. 方法 public StringBuilder reverse()
用于将字符序列逆序,仍然返回自身对象。
\6. 方法 public String toString() 返回此序列中数据的字符串表示形式。
\7. 和 String 类含义类似的方法:
public int indexOf(String str)
public int indexOf(String str,int fromIndex)
public String substring(int start)java
public String substring(int start,int end)
public int length()
char charAt(int index)
StringBuffer/StringBuilder基本用法
public class TestStringBufferAndBuilder 1{
public static void main(String[] args) {
/**StringBuilder*/
StringBuilder sb = new StringBuilder();
for (int i = 0; i < 7; i++) {
sb.append((char) ('a' + i));//追加单个字符
}
System.out.println(sb.toString());//转换成String输出
sb.append(", I can sing my abc!");//追加字符串
System.out.println(sb.toString());
/**StringBuffer*/
StringBuffer sb2 = new StringBuffer("中华人民共和国");
sb2.insert(0, "爱").insert(0, "我");//插入字符串
System.out.println(sb2);
sb2.delete(0, 2);//删除子字符串
System.out.println(sb2);
sb2.deleteCharAt(0).deleteCharAt(0);//删除某个字符
System.out.println(sb2.charAt(0));//获取某个字符
System.out.println(sb2.reverse());//字符串逆序
}
}
类型转换
字符串 → 基本数据类型、包装类:
Integer包装类的public static int Integer.parseInt(String s)可以将由数字组成的字符串转换为整型。(记法:解析成整型)
类似地,使用java.lang包中的Byte、 Short、 Long、 Float、 Double类调相应的类方法可以将由“数字”字符组成的字符串,转化为相应的基本数据类型。
基本数据类型、包装类 → 字符串
调用String类的public static String valueOf(int n)可将int型转换为字符串。(记法:值的字符串)
相应的valueOf(byte b)、 valueOf(long l)、 valueOf(float f)、 valueOf(double d)、 valueOf(boolean b)可由参数的相应类型到字符串的转换
字符数组 → 字符串
String 类的构造器: String(char[]) 和 String(char[], int offset, int length) 分别用字符数组中的全部字符和部分字符创建字符串对象。
字符串 → 字符数组
public char[] toCharArray(): 将字符串中的全部字符存放在一个字符数组中的方法。
public void getChars(int srcBegin, int srcEnd, char[] dst,
int dstBegin): 提供了将指定索引范围内的字符串存放到数组中的方法
字节数组 → 字符串
String(byte[]): 通过使用平台的默认字符集解码指定的 byte 数组,构造一个新的 String。
String(byte[], int offset, int length) : 用指定的字节数组的一部分,即从数组起始位置offset开始取length个字节构造一个字符串对象。
String str = "中";
System.out.println(str.getBytes("ISO8859-1").length);// -128~127
System.out.println(str.getBytes("GBK").length);
System.out.println(str.getBytes("UTF-8").length);
System.out.println(new String(str.getBytes("ISO8859-1"), "ISO8859-1"));// 乱码,表示不了中文
System.out.println(new String(str.getBytes("GBK"), "GBK"));
System.out.println(new String(str.getBytes("UTF-8"), "UTF-8"));
字符串 → 字节数组
public byte[] getBytes() : 使用平台的默认字符集将此 String 编码为byte 序列,并将结果存储到一个新的 byte 数组中。
public byte[] getBytes(String charsetName) : 使用指定的字符集将此 String 编码到 byte 序列,并将结果存储到新的 byte 数组
编码问题
单个汉字在GBK、UTF-8、ISO8859-1和unicode编码下的byte数组表示,此时b_gbk的长度为2,b_utf8的长度为3,b_iso88591的长度为1,unicode为4。
通过打印s_gbk、s_utf8、s_iso88591和unicode,会发现,s_gbk、s_utf8和unicode都是“深”,而只有s_iso88591是一个不认识的字符,为什么使用ISO8859-1编码再组合之后,无法还原“深”字呢,其实原因很简单,因为ISO8859-1编码的编码表中,根本就没有包含汉字字符,当然也就无法通过"深".getBytes(“ISO8859-1”);来得到正确的“深”字在ISO8859-1中的编码值了,所以再通过new String()来还原就无从谈起了。
不可变和可变字符序列

String 类中使用 final 关键字修饰字符数组来保存字符串,private final char value[],所以 String 对象是不可变的。
补充(来自issue 675):在 java 9 之后,String 类的实现改用 byte 数组存储字符串
private final byte[] value;
而 StringBuilder 与 StringBuffer 都继承自 AbstractStringBuilder 类,在 AbstractStringBuilder 中也是使用字符数组保存字符串char[]value 但是没有用 final 关键字修饰,所以这两种对象都是可变的。
StringBuilder 与 StringBuffer 的构造方法都是调用父类构造方法也就是 AbstractStringBuilder 实现的
StringBuffer 对方法加了同步锁或者对调用的方法加了同步锁,所以是线程安全的。StringBuilder 并没有对方法进行加同步锁,所以是非线程安全的。
StringBuffer类
java.lang.StringBuffer代表可变的字符序列, JDK1.0中声明,可以对字符串内容进行增删,此时不会产生新的对象。
很多方法与String相同。
作为参数传递时,方法内部可以改变值。
StringBuffer类不同于String,其对象必须使用构造器生成。有三个构造器:
StringBuffer():初始容量为16的字符串缓冲区
StringBuffer(int size):构造指定容量的字符串缓冲区
StringBuffer(String str):将内容初始化为指定字符串内容
String s = new String("我喜欢学习");
StringBuffer buffer = new StringBuffer("我喜欢学习");
buffer.append("数学");
StringBuffer append(xxx):提供了很多的append()方法, 用于进行字符串拼接
StringBuffer delete(int start,int end):删除指定位置的内容
StringBuffer replace(int start, int end, String str):把[start,end)位置替换为str
StringBuffer insert(int offset, xxx):在指定位置插入xxx
StringBuffer reverse() :把当前字符序列逆转
public int indexOf(String str)
public String substring(int start,int end)
public int length()
public char charAt(int n )
public void setCharAt(int n ,char ch)
当append和insert时,如果原来value数组长度不够,可扩容。
如上这些方法支持方法链操作。
方法链的原理
StringBuilder
- StringBuffer的容量长度为16,如果构造器传入字符串"abc",那么StringBuffer初始容量为16+3。但.lenth()返回的还是3
- 用.append()可以往StringBuffer里追加内容,不改变容量,容量不够时,扩容为原来容量的2倍 + 2
- 效率:StringBuilder > StringBuffer > String
package com.atguigu.java;
import org.junit.Test;
public class StringBufferBuilderTest {
//对比效率:StringBuilder > StringBuffer > String
@Test
public void test3(){
//初始设置
long startTime = 0L;
long endTime = 0L;
String text = "";
StringBuffer buffer = new StringBuffer("");
StringBuilder builder = new StringBuilder("");
//开始对比
startTime = System.currentTimeMillis();
for (int i = 0; i < 20000; i++) {
buffer.append(String.valueOf(i));
}
endTime = System.currentTimeMillis();
System.out.println("StringBuffer的执行时间:" + (endTime - startTime));
startTime = System.currentTimeMillis();
for (int i = 0; i < 20000; i++) {
builder.append(String.valueOf(i));
}
endTime = System.currentTimeMillis();
System.out.println("StringBuilder的执行时间:" + (endTime - startTime));
startTime = System.currentTimeMillis();
for (int i = 0; i < 20000; i++) {
text = text + i;
}
endTime = System.currentTimeMillis();
System.out.println("String的执行时间:" + (endTime - startTime));
}
/*
StringBuffer的常用方法:
StringBuffer append(xxx):提供了很多的append()方法,用于进行字符串拼接
StringBuffer delete(int start,int end):删除指定位置的内容
StringBuffer replace(int start, int end, String str):把[start,end)位置替换为str
StringBuffer insert(int offset, xxx):在指定位置插入xxx
StringBuffer reverse() :把当前字符序列逆转
public int indexOf(String str)
public String substring(int start,int end):返回一个从start开始到end索引结束的左闭右开区间的子字符串
public int length()
public char charAt(int n )
public void setCharAt(int n ,char ch)
总结:
增:append(xxx)
删:delete(int start,int end)
改:setCharAt(int n ,char ch) / replace(int start, int end, String str)
查:charAt(int n )
插:insert(int offset, xxx)
长度:length();
*遍历:for() + charAt() / toString()
*/
@Test
public void test2(){
StringBuffer s1 = new StringBuffer("abc");
s1.append(1);
s1.append('1');
System.out.println(s1);
// s1.delete(2,4);
// s1.replace(2,4,"hello");
// s1.insert(2,false);
// s1.reverse();
String s2 = s1.substring(1, 3);
System.out.println(s1);
System.out.println(s1.length());
System.out.println(s2);
}
/*
String、StringBuffer、StringBuilder三者的异同?
String:不可变的字符序列;底层使用char[]存储
StringBuffer:可变的字符序列;线程安全的,效率低;底层使用char[]存储
StringBuilder:可变的字符序列;jdk5.0新增的,线程不安全的,效率高;底层使用char[]存储
源码分析:
String str = new String();//char[] value = new char[0];
String str1 = new String("abc");//char[] value = new char[]{'a','b','c'};
StringBuffer sb1 = new StringBuffer();//char[] value = new char[16];底层创建了一个长度是16的数组。
System.out.println(sb1.length());//
sb1.append('a');//value[0] = 'a';
sb1.append('b');//value[1] = 'b';
StringBuffer sb2 = new StringBuffer("abc");//char[] value = new char["abc".length() + 16];
//问题1. System.out.println(sb2.length());//3
//问题2. 扩容问题:如果要添加的数据底层数组盛不下了,那就需要扩容底层的数组。
默认情况下,扩容为原来容量的2倍 + 2,同时将原有数组中的元素复制到新的数组中。
指导意义:开发中建议大家使用:StringBuffer(int capacity) 或 StringBuilder(int capacity)
*/
@Test
public void test1(){
StringBuffer sb1 = new StringBuffer("abc");
sb1.setCharAt(0,'m');
System.out.println(sb1);
StringBuffer sb2 = new StringBuffer();
System.out.println(sb2.length());//0
}
}
要点:
\1. String:不可变字符序列。
\2. StringBuffer:可变字符序列,并且线程安全,但是效率低。
\3. StringBuilder:可变字符序列,线程不安全,但是效率高(一般用它)。
StringBuilder和StringBuffer
StringBuffer 和 StringBuilder 类的对象能够被多次的修改,并且不产生新的未使用对象。
StringBuilder 类在 java 5 中被提出,它和 StringBuffer 之间的最大不同在于 StringBuilder 的方法不是线程安全的(不能同步访问)。
由于 StringBuilder 相较于 StringBuffer 有速度优势,所以多数情况下建议使用 StringBuilder 类。然而在应用程序要求线程安全的情况下,则必须使用 StringBuffer 类。
| 类 | 说明 | 例子 |
|---|---|---|
| String | 不可变字符序列 | 操作少量的数据 |
| StringBuilder | 可变字符序列、速度快 | |
| StringBuffer | 可变字符序列、效率低、线程安全 | 不能赋值null。StringBuffer s = new StringBuffer();代表空对象 |
小结:
(1)如果要用 String;
(2)多线程操作字符串缓冲区下操作大量数据 StringBuffer;
(3)单线程操作字符串缓冲区下操作大量数据 StringBuilder。
String详解
String声明为final的,不可被继承
String实现了Serializable接口,表示字符串是支持序列化的。
实现了Comparable接口,表示String可以比较大小。
String8在jdk8及以前内部定义了final char[] value用于存储字符串数据,jdk9时改为byte[] value。
为什么改变:对于拉丁文每个字符只占一个字节,有很多东西没用到。所以改为byte再加上一个说明是编码情况的标识。
字符串常量池中不会存储相同内容的字符串。
- String的String pool是一个固定大小的HashTable,默认值大小长度是1009,。如果放进String Pool的String非常多,就会造成Hash冲突严重,从而导致链表会很长,而链表长了后直接造成的影响就是当调用String.intern时性能会大幅下降。
-XX:StringTableSize可设置StringTable的长度- 在jdk6中StringTable是固定的,也就是1009的长度,所以如果常量池中的字符串过多就会导致效率下降很快。StringTableSize设置没有要求
- 在jdk7中, StringTable的长度默认值是60013。1009是可设置的最小值。
java的内存分配
在java语言中有8种基本数据类型和String,这些类型为了使他们在运行过程中速度更快,更节省内存,都提供了一种常量池的概念。
常量池就类似一个java系统级别提供的缓存。8中基础类型的常量池都是系统协调的,String类型的常量池比较特殊。它的主要使用方法有两种
- 直接双引号的String对象会直接存储在常量池中
- new出来的String可以使用intern()
JDK6以前,字符串常量池存放在永久代。
JDK7中Oracle的工程师对字符串的逻辑做了很大的改编,将字符串常量池的位置调整到java堆内。
- 所有的字符串都保存在堆中,这样就可以调优堆大小
JDK8元空间、字符串常量在堆
字符串常量池
一、new String都是在堆上创建字符串对象。当调用 intern() 方法时,编译器会将字符串添加到常量池中(stringTable维护),并返回指向该常量的引用。

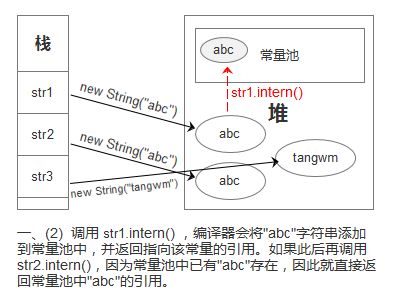
String s = new String("abc");//字符串常量池中有abc,堆中也有
String s1 = "abc";
String s2 = new String("abc");
System.out.println(s == s1.intern());//false
System.out.println(s == s2.intern());//false
System.out.println(s1 == s.intern());//true
System.out.println(s1 == s2.intern());//true
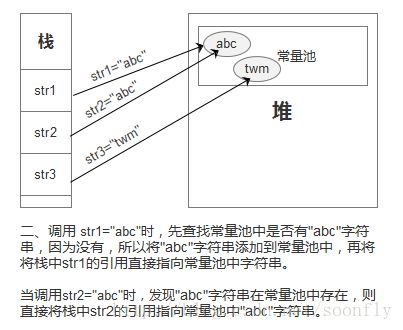
二、通过字面量赋值创建字符串(如:String str=”twm”)时,会先在常量池中查找是否存在相同的字符串,若存在,则将栈中的引用直接指向该字符串;若不存在,则在常量池中生成一个字符串,再将栈中的引用指向该字符串。
三、常量字符串的“+”操作,编译阶段直接会合成为一个字符串。如string str=”JA”+”VA”,在编译阶段会直接合并成语句String str=”JAVA”,于是会去常量池中查找是否存在”JAVA”,从而进行创建或引用。
四、对于final字段,编译期直接进行了常量替换(而对于非final字段则是在运行期进行赋值处理的)。
final String str1=”ja”;
final String str2=”va”;
String str3=str1+str2;
在编译时,直接替换成了String str3=”ja”+”va”,根据第三条规则,再次替换成String str3=”JAVA”
String s1 = “abc”;
final String s2 = “a”;
final String s3 = “bc”;
String s4 = s2 + s3;
System.out.println(s1 == s4);
A:true,因为final变量在编译后会直接替换成对应的值,所以实际上等于s4=”a”+”bc”,而这种情况下,编译器会直接合并为s4=”abc”,所以最终s1==s4。
五、常量字符串和变量拼接时(如:String str3=baseStr + “01”;)会调用stringBuilder.append()在堆上创建新的对象。
六、JDK 1.7后,intern方法还是会先去查询常量池中是否有已经存在,如果存在,则返回常量池中的引用,这一点与之前没有区别,
区别在于,如果在常量池找不到对应的字符串,则不会再将字符串拷贝到常量池,而只是在常量池中生成一个对原字符串的引用。简单的说,就是往常量池放的东西变了:原来在常量池中找不到时,复制一个副本放到常量池,1.7后则是将在堆上的地址引用复制到常量池。
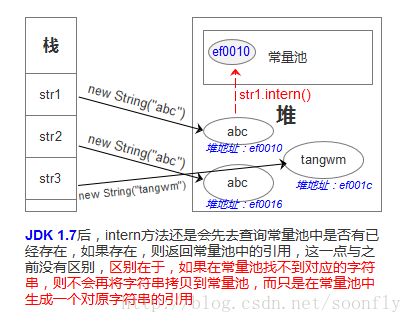
调用intern()
- 如果常量池中已经有了该字符串str1,那直接返回常量池中str1的引用
- 如果常量池中没有该字符串str1,
- JDK6会把字符串复制到常量池中,相当于常量池中是一个副本str2,并且返回的是该副本的引用str2,而该字符串str1还是指向堆中;
- JDK7会把堆中字符串str1的引用写到常量池中str1,而不是复制,当新的变量被赋值该字符串str1时,直接指向的是该引用str1。
举例说明:
String str2 = new String("str")+new String("01");
str2.intern();//JDK6:复制一份,返回该副本引用,但str2还是指向堆中的。JDK7:在常量池中生成一个引用指向堆中。
String str1 = "str01";//JDK6:常量池中的副本。JDK7:这个引用从字符串常量池中指向堆中
System.out.println(str2==str1);//JDK6:false。JDK7:true
在JDK 1.7下,当执行str2.intern();时,因为常量池中没有“str01”这个字符串,所以会在常量池中生成一个对堆中的“str01”的引用(注意这里是引用 ,就是这个区别于JDK 1.6的地方。在JDK1.6下是生成原字符串的拷贝),而在进行String str1 = “str01”;字面量赋值的时候,常量池中已经存在一个引用,所以直接返回了该引用,因此str1和str2都指向堆中的同一个字符串,返回true。
String str2 = new String("str")+new String("01");//JDK6:堆//JDK7:堆
String str1 = "str01";//JDK6: 常量池//JDK7:常量池
str2.intern();//JDK6:尝试复制,常量池已经有了,没有复制,返回了常量池中的引用,但str2还是指向堆中的//JDK7:尝试提供堆中的引用给常量池,常量池已经有自己的了,无需引用堆中你的了
System.out.println(str2==str1);//JDK6:false//JDK7:false//都是堆中一份,常量池中一份
将中间两行调换位置以后,因为在进行字面量赋值(String str1 = “str01″)的时候,常量池中不存在,所以str1指向的常量池中的位置,而str2指向的是堆中的对象,再进行intern方法时,对str1和str2已经没有影响了,所以返回false。
String s = new String("1");//堆中,同时常量池中也有1了
s.intern();// JDK6,复制,复制失败 //JDK7:常量池中已经有了,无需复制
String s2 = "1";
System.out.println(s == s2);// JDK6和7都是false
String s3 = new String("1") + new String("1");//堆中有11,常量池中没有11
s3.intern();//JDK6复制成功//JDK7引用成功
String s4 = "11";
System.out.println(s3 == s4);//JDK6:false JDK7:true
再分别调整上面代码2.3行、7.8行的顺序:
String s = new String("1");//堆中,同时常量池中也有1了
String s2 = "1";//指向上一句在常量池中创建好的常量,但不是堆中的常量
s.intern();
System.out.println(s == s2);//JDK6:false JDK7:false
String s3 = new String("1") + new String("1");//堆中有11,常量池中没有11
String s4 = "11";//常量池中也自己的有11了
s3.intern();//JDK6复制失败//JDK7引用失败
System.out.println(s3 == s4);//JDK6:false JDK7:false
JDK6
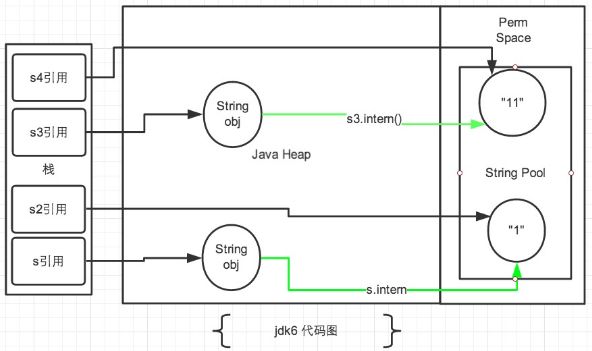
在JDK1.6中所有的输出结果都是 false,因为JDK1.6以及以前版本中,常量池是放在 Perm 区(属于方法区)中的,熟悉JVM的话应该知道这是和堆区完全分开的。
使用引号声明的字符串都是会直接在字符串常量池中生成的,而 new 出来的 String 对象是放在堆空间中的。所以两者的内存地址肯定是不相同的,即使调用了intern()方法也是不影响的。
intern()方法在JDK1.6中的作用是:比如String s = new String(“SEU_Calvin”),再调用s.intern(),此时返回值还是字符串"SEU_Calvin",表面上看起来好像这个方法没什么用处。但实际上,在JDK1.6中它做了个小动作:检查字符串池里是否存在"SEU_Calvin"这么一个字符串,如果存在,就返回池里的字符串;如果不存在,该方法会把"SEU_Calvin"添加到字符串池中,然后再返回它的引用。然而在JDK1.7中却不是这样的,后面会讨论。
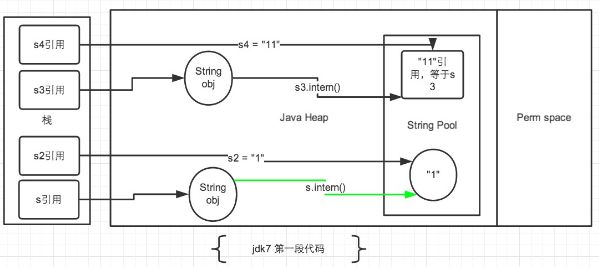
JDK7
针对JDK1.7以及以上的版本,我们将上面两段代码分开讨论。先看第一段代码的情况:
 **
**
String s = new String("1");//生成了常量池中的“1” 和堆空间中的字符串对象
s.intern();// s对象去常量池中寻找后发现"1"已经存在于常量池中了。
String s2 = "1";//生成一个s2的引用指向常量池中的“1”对象。
System.out.println(s == s2);// JDK6和7都是false
String s3 = new String("1") + new String("1");//在字符串常量池中生成“1” ,并在堆空间中生成s3引用指向的对象(内容为"11")。注意此时常量池中是没有 “11”对象的。
s3.intern();//将 s3中的“11”字符串放入 String 常量池中,此时常量池中不存在“11”字符串,JDK1.6的做法是直接在常量池中生成一个 "11" 的对象。
//但是在JDK1.7中,常量池中不需要再存储一份对象了,可以直接存储堆中的引用。这份引用直接指向 s3 引用的对象,也就是说s3.intern() ==s3会返回true。
String s4 = "11";//直接去常量池中创建,但是发现已经有这个对象了,此时也就是指向 s3 引用对象的一个引用。因此s3 == s4返回了true。
System.out.println(s3 == s4);//JDK6:false JDK7:true
下面继续分析第二段代码:
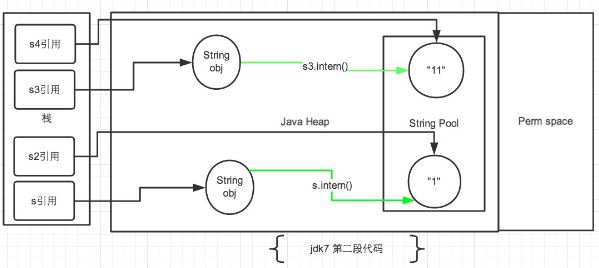
再把第二段代码贴一下便于查看:
String s = new String("1");//生成了常量池中的“1” 和堆空间中的字符串对象。
String s2 = "1";//这行代码是生成一个s2的引用指向常量池中的“1”对象,但是发现已经存在了,那么就直接指向了它。
s.intern();//这一行在这里就没什么实际作用了。因为"1"已经存在了。
System.out.println(s == s2);// 引用地址不同//JDK6:false JDK7:false
String s3 = new String("1") + new String("1");//在字符串常量池中生成“1” ,并在堆空间中生成s3引用指向的对象(内容为"11")。注意此时常量池中是没有 “11”对象的。
String s4 = "11";//直接去生成常量池中的"11"。
s3.intern();//这一行在这里就没什么实际作用了。因为"11"已经存在了。
System.out.println(s3 == s4);//引用地址不同//JDK6:false JDK7:false
String str1 = new String("SEU") + new String("Calvin");
System.out.println(str1.intern() == str1);//JDK6:false//JDK7:true
System.out.println(str1 == "SEUCalvin");//JDK6:false//JDK7:true
String str2 = "SEUCalvin";//新加的一行代码,其余不变
String str1 = new String("SEU")+ new String("Calvin");
System.out.println(str1.intern() == str1);//JDK6:false//JDK7:false
System.out.println(str1 == "SEUCalvin");//JDK6:false//JDK7:false
也很简单啦,str2先在常量池中创建了“SEUCalvin”,那么str1.intern()当然就直接指向了str2,你可以去验证它们两个是返回的true。后面的"SEUCalvin"也一样指向str2。所以谁都不搭理在堆空间中的str1了,所以都返回了false。
new String()究竟创建几个对象?
1. 由来
遇到一个Java面试题,是关于String的,自己对String还有点研究?下面是题目的描述:
在Java中,
new String("hello")这样的创建方式,到底创建了几个String对象?
题目下答案,各说纷纭,有说1个的,有说2个的。我觉得都对,但也都不对,因为要加上一定的条件,下面来分析下!
2. 解答
2.1. 分析
题目中的String创建方式,是调用String的有参构造函数,而这个有参构造函数的源码则是这样的public String(String original),这就是说,我们可以把代码转换为下面这种:
String temp = "hello"; // 在常量池中
String str = new String(temp); // 在堆上
这段代码就创建了2个String对象,temp指向在常量池中的,str指向堆上的,而str内部的char value[]则指向常量池中的char value[],所以这里的答案是2个对象。(这里不再详述内部过程,之前的文章有写,参考深入浅出Java String)
那之前我为什么说答案是1个的也对呢,假如就只有这一句String str = new String("hello")代码,并且此时的常量池的没有"hello"这个String,那么答案是两个;如果此时常量池中,已经存在了"hello",那么此时就只创建堆上str,而不会创建常量池中temp,(注意这里都是引用),所以此时答案就是1个。
https://blog.csdn.net/w605283073/article/details/72753494
《深入理解java虚拟机》第二版 57页
对String.intern()返回引用的测试代码如下:
String str1 = new StringBuilder("计算机").append("软件").toString();
// String str3= new StringBuilder("计算机软件").toString();
System.out.println(str1.intern() == str1);//JDK6:false//JDK7:true
String str2 = new StringBuilder("Java(TM) SE ").append("Runtime Environment").toString();
;//堆中有,问题是常量池中在intern之前是否有拼接完的字符串
System.out.println(str2.intern() == str2);//JDK6:false//JDK7:false
//jdk6因为是复制,所以不可能相等,问题是jdk7可能是引用,按理说应该是true,为什么是false
//这个因为jdk源码中已经有了这个拼接完的字符串,在标注版本的时候定义过了
可能很多人觉得这个结果很奇怪,在这里我们进行深入地探究。
因为JDK1.6中,intern()方法会把首次遇到的字符串实例复制到永久代中,返回的也是永久代中这个字符串的实例的引用,而StringBulder创建的字符串实例在Java堆上,所以必然不是同一个引用,将返回false。
在JDK1.7中,intern()的实现不会在复制实例,只是在常量池中记录首次出现的实例引用,因此返回的是引用和由StringBuilder.toString()创建的那个字符串实例是同一个。
str2的比较返回false因为"java"这个字符串在执行StringBuilder.toString()之前已经出现过,字符串常量池中已经有它的引用了,不符合“首次出现”的原则,而“计算机软件”这个字符串是首次出现,因此返回true。
那么就有疑问了,这个“java”字符串在哪里出现过呢?显然并不是直接出现在这个类里面。
我们分别打开String 、StringBuilder和System类的源码看看有啥发现,
其中在System类里发现
有java版本的字符串
因此sun.misc.Version 类会在JDK类库的初始化过程中被加载并初始化,而在初始化时它需要对静态常量字段根据指定的常量值(ConstantValue)做默认初始化,此时被 sun.misc.Version.launcher 静态常量字段所引用的"java"字符串字面量就被intern到HotSpot VM的字符串常量池——StringTable里了。
因此我们修改一下代码:
String str2 = new StringBuilder("Java(TM) SE ").append("Runtime Environment").toString();System.out.println(str2.intern() == str2)
发现结果还是false
从而更加证实了我们的猜测。
再遇到类似问题的时候,希望大家可以多从源码角度去追本溯源,能够多分享出来。
String s = new String("1");//创建了2个对象
s.intern();//没有什么用
String s2="1";//之前字符串常量池中有了
S==S2;//false
String s3= new String("1") + new String("1");//常量池中没创建11
s3.intern();//JDK6复制//JDK7放引用
String s4="11";
s3==s4;//在JDK6中false,jdk7中true
String str=new String("a")+new String("b");
//对象1 new StringBuilder
//对象2 new String("a")
//对象3 常量池a
//对象4 new String("b")
//对象5 常量池b
//对象6 toString(){new String;}
//没有ab
https://www.cnblogs.com/clamp7724/p/11751278.html
字符串常量池:String table又称为String pool,
- 字符串常量池在Java内存区域的哪个位置
- 在JDK6.0及之前版本,字符串常量池是放在【Perm Gen区(也就是方法区)】中;
- 在JDK7.0版本,字符串常量池被移到了【堆】中了。至于为什么移到堆内,大概是由于方法区的内存空间太小了。但是字符串常量池与堆对象还是不一样
- 字符串常量池放的是什么:
- 在JDK6.0及之前版本中,String Pool里放的都是字符串常量
- 在JDK7.0中,由于String#intern()发生了改变,因此String Pool中也可以存放放于堆内的字符串对象的引用
- StringTable还存在一个hash表的特性∶里面不存在相同的两个字符串。
- main String,java等属于关键词,在一开始就在StringTable中存在了,所以str.intern没能插入进去。
String s1 = "ha";
String s2 = "ha";
String s3 = s1 +s2;//s3本质调用了 new StringBuilder.append("a").append("b").toString(); 声明了新的引用变量,开辟了新的空间,所以指向的是堆中的对象地址而不是StringTable中的字符串了。
String s4 = "ha" + "ha";//因为是两个常量拼接,在编译时就会直接变成"haha"进行处理,进入StringTable
String s5 = "haha";//因为也是常量,会先在StringTable中查找,找到后s5指向了StringTable中的"haha"
String s6 = new String("haha");
System.out.println(s3 == s4);//false
System.out.println(s4 == s5);//true
System.out.println(s5 == s6);//false
串常量池的位置
JVM1.6的时候StringTable在常量池。
JVM1.8后,StringTable在堆区
验证:串常量池的位置
//运行如下代码探究常量池的位置
public static void main(String[] args) throws Throwable {
List list = new ArrayList();
int i=0;
while(true){
list.add(String.valueOf(i++).intern());
}
}
/*
用jdk1.6运行后会报错,永久代这个区域内存溢出会报:
Exception in thread “main” java.lang.OutOfMemoryError:PermGen space的内存溢出异常,表示永久代内存溢出。
jdk1.7 和1.8Exception in thread “main” java.lang.OutOfMemoryError: Java heap space说明1.6在永久带,1.7以后移动到了heap中
98%的垃圾回收,但只有2%的堆被重置
*/
串常量垃圾回收
package JVMtest;
/*
* 演示stringTable垃圾回收
* -Xmx10m -XX:+PrintStringTableStatistics -XX:+PrintGCDetails -verbose:gc
* 打印字符串表的统计信息
* 打印垃圾回收的详细信息
* */
public class StringTable {
public static void main(String[] args) {
int i=0;
try {
for(int j=0;j<100;j++){//ctrl+alt+t快捷键try catch
String.valueOf(j).intern();//这句话注释与打开
i++;
}
} catch (Exception e) {
e.printStackTrace();
} finally {
System.out.println(i);
}
}
}
//输出信息如下:
100
Heap//堆
PSYoungGen total 2560K, used 1644K [0x00000000ffd00000, 0x0000000100000000, 0x0000000100000000)
eden space 2048K, 80% used [0x00000000ffd00000,0x00000000ffe9b3f0,0x00000000fff00000)
from space 512K, 0% used [0x00000000fff80000,0x00000000fff80000,0x0000000100000000)
to space 512K, 0% used [0x00000000fff00000,0x00000000fff00000,0x00000000fff80000)
ParOldGen total 7168K, used 0K [0x00000000ff600000, 0x00000000ffd00000, 0x00000000ffd00000)
object space 7168K, 0% used [0x00000000ff600000,0x00000000ff600000,0x00000000ffd00000)
Metaspace used 3144K, capacity 4496K, committed 4864K, reserved 1056768K
class space used 343K, capacity 388K, committed 512K, reserved 1048576K
SymbolTable statistics://符号表
Number of buckets : 20011 = 160088 bytes, avg 8.000
Number of entries : 13114 = 314736 bytes, avg 24.000
Number of literals : 13114 = 562744 bytes, avg 42.912
Total footprint : = 1037568 bytes
Average bucket size : 0.655
Variance of bucket size : 0.655
Std. dev. of bucket size: 0.810
Maximum bucket size : 6
StringTable statistics://串常量分析
Number of buckets : 60013 = 480104 bytes, avg 8.000//桶个数60013
Number of entries : 1839 = 44136 bytes, avg 24.000//键值对个数1839
Number of literals : 1839 = 161288 bytes, avg 87.704//字符串常量个数//什么都没做就有1000+了//注释了for之后显示1739
Total footprint : = 685528 bytes
Average bucket size : 0.031
Variance of bucket size : 0.031
Std. dev. of bucket size: 0.175
Maximum bucket size : 3
Process finished with exit code 0
//for改为10000后,//字符串常量并没有变为10000多个,而是满了之后就垃圾回收了。证明了StringTable也会发生垃圾回收
[GC (Allocation Failure) [PSYoungGen: 2048K->488K(2560K)] 2048K->636K(9728K), 0.0012292 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
10000
StringTable statistics:
Number of buckets : 60013 = 480104 bytes, avg 8.000
Number of entries : 3174 = 76176 bytes, avg 24.000
Number of literals : 3174 = 225688 bytes, avg 71.105
Total footprint : = 781968 bytes
串常量池性能调优
- 调整:
XX:+StringTableSize=桶个数。将StringTable中的桶个数设为2000。 hash表桶的数量越多(数组部分长度越长),数据越分散,hashcode撞车的概率越小,速度越快。 默认值是6万多 - 考虑将字符串对象是否入池
-Xms500m 设置堆内存为500mb
-Xmx500m -XX:+PrintStringTableStatistics -XX:+StringTableSize=20000
限制了桶大小为2W。
变慢了
往StringTable里放一个字符串,就要去哈希表里查找有没有。有就不能放进去。
public static void main(String[] args) {
try {
BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream(new File("f:\\test.txt"))));
String line = null;
long start = System.nanoTime();
while (true) {
line = reader.readLine();
if (line == null) {
break;
}
line.intern();
}
System.out.println("cost:" + (System.nanoTime() - start) / 1000000);
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
//通过读取文件将文件中的每一行逐行加入到StringTable中,修改桶的大小来测试所需要的时间(文件为8145行)
StringTableSize |
Time |
|---|---|
| 128 | 172 ms |
| 1024 | 116 ms |
| 4096 | 87 ms |