Redis-数据类型
Redis-数据类型
文章目录
- Redis-数据类型
- String
- SDS与C字符串的区别
- Hash
- rehash
- List
- Set
- ZSet
- Geo
- **HyperLogLog**
- Bitmaps
- **Pub/Sub**
String
redis中的字符串String结构是底层采取SDS来实现:
// 3.0
struct sdshdr {
// 记录buf数组中已使用字节的数量,即SDS所保存字符串的长度
unsigned int len;
// 记录buf数据中未使用的字节数量
unsigned int free;
// 字节数组,用于保存字符串
char buf[];
};
3.2版本之后会根据字符串的长度来选择不同的结构:
// 3.2
/* Note: sdshdr5 is never used, we just access the flags byte directly.
* However is here to document the layout of type 5 SDS strings. */
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
SDS与C字符串的区别

Hash
Redis的键值对存储就是用字典实现的,散列(Hash)的底层实现之一也是字典,一个哈希表里边有多个哈希节点,一个哈希节点保存一个键值对
哈希表结构定义:
typedef struct dictht {
// 哈希表数组
dictEntry **table;
// 哈希表大小
unsigned long size;
// 哈希表大小掩码,用于计算索引值,等于size-1
unsigned long sizemask;
// 哈希表已有节点的数量
unsigned long used;
} dictht;
哈希表是由数组table组成,table中每个元素都是指向dict.h/dictEntry结构的指针,哈希表节点的定义如下:
typedef struct dictEntry {
// 键
void *key;
// 值
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
// 指向下一个哈希表节点,形成链表
struct dictEntry *next;
} dictEntry;
哈希冲突采取拉链法解决
字典整体定义:
typedef struct dict {
// 和类型相关的处理函数
dictType *type;
// 私有数据
void *privdata;
// 哈希表,一个用于保存数据,一个用于数据迁移时使用
dictht ht[2];
// rehash 索引,当rehash不再进行时,值为-1
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
// 迭代器数量
unsigned long iterators; /* number of iterators currently running */
} dict;

rehash
当哈希表的键值对数量超过一定值的时候,会将键值对从一个哈希表迁移到另一个哈希表上
rehashidx也是跟rehash相关的,rehash的操作不是瞬间完成的,rehashidx记录着rehash的进度,如果目前没有在进行rehash,它的值为-1
List
链表在Redis中应用的非常广,列表(List)的底层实现就是链表。此外,Redis的发布与订阅、慢查询、监视器等功能也用到了链表,双向链表
链表节点的定义:
typedef struct listNode {
// 前置节点
struct listNode *prev;
// 后置节点
struct listNode *next;
// 节点值
void *value;
} listNode;
链表定义:
typedef struct list {
// 链表头节点
listNode *head;
// 链表尾节点
listNode *tail;
// 节点值复制函数
void *(*dup)(void *ptr);
// 节点值释放函数
void (*free)(void *ptr);
// 节点值对比函数
int (*match)(void *ptr, void *key);
// 链表所包含的节点数量
unsigned long len;
} list;
Set
整数集合是集合(Set)的底层实现之一,如果一个集合只包含整数值元素,且元素数量不多时,会使用整数集合作为底层实现,整数集合(intset)是Redis用于保存整数值的集合抽象数据结构,可以保存类型为int16_t、int32_t、int64_t的整数值,并且保证集合中不会出现重复元素
整数集合的定义:
typedef struct intset {
// 编码方式
uint32_t encoding;
// 集合包含的元素数量
uint32_t length;
// 保存元素的数组,整数集合的每个元素在数组中按值的大小从小到大排序,且不包含重复项
int8_t contents[];
} intset;
ZSet
zset的底层实现是跳表,使用跳表实现是用来解决查找效率问题的
跳表可以理解成多层链表:
- 多层的结构组成,每层是一个有序的链表
- 最底层(level 1)的链表包含所有的元素
- 跳跃表的查找次数近似于层数,时间复杂度为O(logn),插入、删除也为 O(logn)
- 跳跃表是一种随机化的数据结构(通过抛硬币来决定层数)

查找元素的方法是这样,从上层开始查找,大数向右找到头,小数向左找到头,例如我要查找17,查询的顺序是:13 -> 46 -> 22 -> 17;如果是查找35,则是 13 -> 46 -> 22 -> 46 -> 35;如果是54,则是 13 -> 46 -> 54
跳表实现节点定义:
typedef struct zskiplistNode {
// 成员对象 (robj *obj;)
sds ele;
// 分值
double score;
// 后退指针
struct zskiplistNode *backward;
// 层
struct zskiplistLevel {
// 前进指针
struct zskiplistNode *forward;
// 跨度
// 跨度实际上是用来计算元素排名(rank)的,在查找某个节点的过程中,将沿途访过的所有层的跨度累积起来,得到的结果就是目标节点在跳跃表中的排位
unsigned long span;
} level[];
} zskiplistNode;
链表定义:
typedef struct zskiplist {
// 表头节点和表尾节点
struct zskiplistNode *header, *tail;
// 表中节点的数量
unsigned long length;
// 表中层数最大的节点的层数
int level;
} zskiplist
Geo
redis在3.2版本推出了这个数据结构,可以用来推算地理位置信息,两地之间的距离,方圆几里的人
只有6个命令:
-
geoadd
增加位置信息:geoadd key 纬度 经度 地名 -
geodist
获取两地之间的距离:geodist key 地名1 地名2 单位 -
geohash
-
georadius:可用于实现附近的人
获取指定位置范围的地理信息位置集合:GEORADIUS key longitude latitude radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [ASC|DESC] [COUNT count] georadius key 经度 纬度 半径 单位 获取的数量 -
geopos
获取位置信息:geopos key -
georadiusbymember
获取指定元素范围的地理信息位置集合 georadiusbymember key member 半径 单位
geo底层实现是通过redis的跳表
如:geoadd再添加地理位置信息时:
geoadd key 纬度 经度 地名
实际上,redis将经度和纬度做了一个编码,编码作为zset的score,地名作为value存储到指定的key跳表中
这个编码实际上是通过geohash实现,核心在于:
- 通过什么hash算法唯一标识地球上任意位置
- 如何将地球上不同位置将地球切分为不同的区块,并支持不同粒度的表示
这边文章对于geohash解释的不错:geohash
HyperLogLog
HyperLogLog 是一种概率数据结构,用来估算数据的基数。数据集可以是网站访客的 IP 地址,E-mail 邮箱或者用户 ID。
什么是基数?
基数是不重复的元素,例如:A = {1,3,5,7,8,7,},B={1,3,5,7,8},则AB基数为5
在redis中可以利用hyperloglog实现基数统计
例如,我们需要统计网站访问的用户数,
- 我们可以使用set集合去保存访问网站的用户Id,最后根据set的size作为访问的用户数,但是在这个场景下,我只需要拿到一个访问数,不需要你保存的userId。且一个set保存太多userId时,占用的内存也大,这也是为什么需要HtperLogLog的原因,hyperloglog占用的内存时固定的,为12kb

因为hyperloglog存在一定的错误率,如果允许容错可以使用这个,不允许容错只能使用set
Bitmaps
原理
8bit = 1b = 0.001kb
bitmap就是通过最小的单位bit来进行0或者1的设置,表示某个元素对应的值或者状态。
一个bit的值,或者是0,或者是1;也就是说一个bit能存储的最多信息是2
优势
1.基于最小的单位bit进行存储,所以非常省空间。
2.设置时候时间复杂度O(1)、读取时候时间复杂度O(n),操作是非常快的。
3.二进制数据的存储,进行相关计算的时候非常快。
4.方便扩容
简单使用:

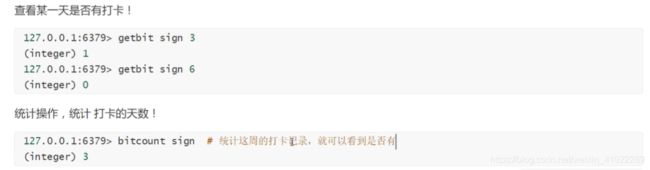
Pub/Sub
redis中的发布订阅也是一种消息通信模式,发送者发送消息,订阅者接收消息,redis客户端可以订阅任意数量的频道
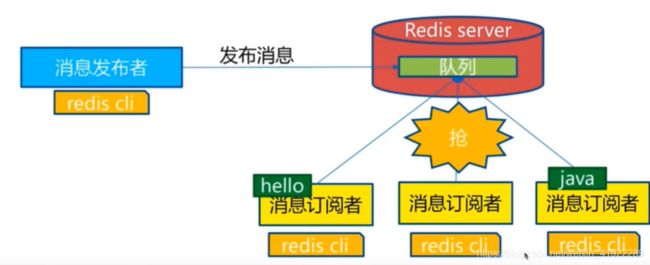
原理:
- 订阅:
- redis内部使用字典维护所有的频道,一个频道下通过链表维护所有的频道订阅者,即subscribe就是将订阅的客户端添加到指定频道的链表下
- 发布:
- 当一个频道接收到新的消息后,就会遍历链表的订阅者将消息push到指定的redis客户端
命令:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1HqfFD1b-1596381801913)(C:%5CUsers%5C12642%5CAppData%5CRoaming%5CTypora%5Ctypora-user-images%5Cimage-20200802185957207.png)]