小白学Java22:MySQL
MySQL
- MySQL的安装
- 常见SQL语句
- 创建数据库:
- 展示数据库:
- 修改数据库
- 删除数据库
- 查看当前使用的数据库
- 使用数据库
- 关于表格
- 创建表格
- 展示当前数据库下的所有表格
- 打开表格详细信息
- 删除表
- 修改数据表的结构
- 数据库中的约束
- 常见的数据库约束
- 数据查询(重要)
- 基本查询
- 1. 查询列
- 2.查询所有列
- 3.对列中的数据进行运算
- 4.查询结果去重
- 5.列的别名
- 排序查询
- 按照单列排序
- 按照多列排序
- 条件查询
- 1. 等值判断(=)
- 2. 逻辑判断(and, or , not)
- 3. 不等于值判断
- 4.区间判断
- 5.NULL值判断
- 6.枚举查询
- 7.模糊查询
- 8. 分支结构查询
- 时间查询
- 字符串查询
- 聚合函数
- 分组查询
- 分组过滤查询
- 限定查询
- LIMIT 的典型应用: 分页查询
- 查询总结
- 书写顺序
- 执行顺序
- 子查询
- 作为条件判断
- 作为枚举查询的条件
- 作为一张表
- 合并查询
- 表连接查询
- 内连接查询 (INNER JOIN ON)
- 三表连接接查询
- 左外连接(LEFT JOIN ON)
- 右外连接(RIGHT JOIN ON)
- DML操作(重点)
- 新增(INSERT)
- 修改(update)
- 删除(DELETE)
- 清空整张表(TRUNCATE)
- 数据表的操作
- 数据类型
- 数值类型
- 日期类型
- 字符串类型
- 数据表的创建
- 数据表的修改(ALTER)
- 向现有表中添加一个列
- 修改表中的列
- 删除表中的列
- 修改列名
- 修改表名
- 数据表的删除(DROP)
- 约束
- 实体完整性约束
- 主键约束(PRIMARY KEY)
- 唯一约束(UNIQUE)
- 自动增长列(AUTO_INCREMENT)
- 域完整性约束
- 非空约束(NOT NULL)
- 默认值约束(DEFAULT)
- 引用完整性约束(外键约束)
- 约束小结
- 事物
- 事物的边界
- 事物的原理
- 事物的特性(ACID):重点
- 事务应用
- 权限管理
- 创建用户
- 授权
- 撤销权限
- 删除用户
- 视图
- 概念
- 视图的优缺点
- 视图的创建
- 使用视图
- 视图的修改
- 视图的删除
- 注意:
MySQL的安装
下载链接:https://dev.mysql.com/downloads/windows/installer/
截止2020/06/08,最新版本:8.0.20
![]()
具体安装步骤可参考:https://www.bilibili.com/video/BV1gC4y1p7z2?p=463
常见SQL语句
-
创建数据库:
//1,创建一个名字为name的数据库,默认跟随本机的字符集
create database name;//(name:新建数据库的名字)
//2,创建一个名字为name的数据库,采用gbk编码
create database name character set gbk;
//3;如果名字叫name的库不存在,则创建一个叫name的库
create database if not exists name;
-
展示数据库:
//1,展示所有的数据库
show databases;
//2,展示数据库的创建信息
show create database mydb2;
-
修改数据库
//1,修改编码格式为UTF-8(UTF-8是没有- 的)
alter database mydb2 character set utf8;
-
删除数据库
//删除名为mydb1的数据库
drop database mydb1;
-
查看当前使用的数据库
select database();
-
使用数据库
//使用mydb2数据库
use mydb2;
-
关于表格
-
创建表格
//在当前数据库下创建一个新的表格,并定义字段和默认数据类型
CREATE TABLE USER(
id INT(10),
NAME VARCHAR(100),
age INT(10)
);
-
展示当前数据库下的所有表格
//3,展示数据库下的表格
show tables;
-
打开表格详细信息
//打开表格详细信息
DESC USER;
-
删除表
//删除表:user;
drop table user;
-
修改数据表的结构
//1,改 表user 添加 gender 默认类型为varchar;
alter table user add gender varchar(10);
//2,改 表user 修改name 的默认类型为varchar(255)
alter table user modify name varchar(255);
//3,改 表user 删除name
alter table user drop name;
//4改 表 user 修改名称为 zhanghaha;
alter table user rename zhanghaha;
数据库中的约束
约束就是数据库中的校验规则
常见的数据库约束
-
- 非空约束(not null)
//创建表时添加非空 约束
create table person(
-> id int(10) not null,
-> name varchar(100));
//通过alter 关键字添加非空约束
alter table person modify name varchar(100) not null;
//删除非空约束
alter table person modify name varchar(100);
-
- 唯一约束(unique key)
//创建表的时候添加唯一约束
create table user_table(
-> id int(10) unique key,
-> name varchar(100));
//创建表的时候添加唯一约束
create table person(
-> id int(10).
-> name varchar(100),
-> constraint no1 unique (id name));
//
通过alter关键字添加唯一约束
alter table user_table modify name varchar(100) unique key;
//删除唯一约束:删除被约束字段的下标
alter table user_table drop index name;
//删除自定义约束名的唯一约束:删除约束名
alter table person drop index no1;
-
- 主键约束(primary key)
主键只能有一个,并且主键等于唯一约束+非空约束
//创建表的时候添加主键约束
CREATE TABLE NAME(
id INT(10) PRIMARY KEY,
NAME VARCHAR(100)
);
//通过alter关键字添加主键约束
ALTER TABLE USER MODIFY ID INT(10) PRIMARY KEY;
//通过alter关键字删除主键约束
ALTER TABLE USER DROP PRIMARY KEY;
-
- 外键约束(foreign key)
外键关联就是两张表进行关联,并且其中某一个列的值,只能是另一张表的某一列的值
数据查询(重要)
基本查询
SELECT:指定要查询的列
FROM: 指定要查询的表
1. 查询列
//查询id属性在user表
SELECT id FROM USER;
2.查询所有列
//查询所有列
SELECT * FORM USER;
SLERCT (全列名) FROM USER;//在生产环境中少用* 的方式
3.对列中的数据进行运算
| 算数运算符 | 描述 |
|---|---|
| + | 加 |
| - | 减 |
| * | 乘 |
| / | 除 |
注:没有取余
4.查询结果去重
关键字:DISTINCT
//显示去重后的查询结果
SELECT DISTINCT id FROM USER;
5.列的别名
关键字 AS ‘自定义名字’
//查询id属性在user表 但是把id显示成编号
SELECT id AS '编号' FROM USER;
排序查询
SELECT 列名 FROM 表名 ORDER BY 排序列 排序规则
注:排序规则可以省略
| 排序规则 | 关键字 |
|---|---|
| 升序 | ASC |
| 降序 |
按照单列排序
//查找ID 来自user表,并按照ID的升序排列
SELECT id FROM USER ORDER BY id ASC;
按照多列排序
两个排序条件用逗号隔开,当第一个被排序的列同名后调用第二个列的排序规则为其排序
SELECT id, NAME FROM ORDER BY id DESC ,NAME ASC;
条件查询
SELECT 列名 FROM 表名 WHERE 条件
关键字: where 条件,条件为布尔表达式
1. 等值判断(=)
==注: 与java不同, mysql中的等值判断使用的是= ==
SELECT ID , NAME FROM person WHERE age =10 ;
2. 逻辑判断(and, or , not)
| 关键字 | 含义 |
|---|---|
| and | 与 |
| or | 或 |
| not | 非 |
//查询年龄=10,且id=10的数据,并显示他的ID和name
SELECT ID ,name from person where age =10 and id = 10;
//查询年龄=10,或者id=10的数据,并显示他的ID和name
SELECT ID ,name from person where age =10 OR id = 10;
//查询年龄不等于10的数据,并显示他的ID和name
SELECT ID ,name from person where NOT age =10;
3. 不等于值判断
| 逻辑符号 | 含义 |
|---|---|
| > | 大于 |
| < | 小于 |
| >= | 大于等于 |
| >= | 小于等于 |
| != | 不等于 |
| <> | 不等于 |
4.区间判断
关键字: BETWEEN AND
用法: WHERE 属性 BETWEEN 小值 AND 大值;
注:一定要小值在前,大值在后;
//查询id在10和20之间的数据
SELECT id,NAME
FROM person
WHERE id BETWEEN 10and20;
5.NULL值判断
关键字:IS NULL: 为空
关键字:IS NOT NULL:不为空
//查询id不为空的数据
SELECT id ,NAME
FROM person
WHERE id IS NOT NULL;
6.枚举查询
关键字 :IN
用法:WHERE 属性 IN(范围1,范围2,范围3);
//查询id为01,02,03的数据
WHERE id IN(01,02,03);
7.模糊查询
关键字: like
用法: WHERE 属性 LIKE ’ 条件’;
//查询以L开头的三个字的员工信息
//条件1:指定长度:_ 占位符,有几个就代标后面跟几个字符
SELECT EMPLOYEE_ID,FIRST_NAME,SALARY
FROM t_employees
WHERE FIRST_NAME LIKE 'L__';
//查询所有以L开头的员工信息
//条件2:% 通配符,表示后跟任意个字符
SELECT EMPLOYEE_ID,FIRST_NAME,SALARY
FROM t_employees
WHERE FIRST_NAME LIKE 'L%';
8. 分支结构查询
CASE
WHEN 条件1 THEN 结果1
WHEN 条件2 THEN 结果2
WHEN 条件3 THEN 结果3
ELSE 结果4;
END
//查询数据,并自定义一个薪资级别的列
SELECT EMPLOYEE_ID,FIRST_NAME,SALARY,
CASE
WHEN SALARY>10000 THEN 'A'
WHEN SALARY>=8000 AND SALARY <10000 THEN 'B'
WHEN SALARY>=6000 AND SALARY <8000 THEN 'C'
ELSE 'D';
END AS '薪资计别'
FROM t_employees;
//查询工号,名字,和工资,并根据工资划分薪资级别,并根据薪资降序排列
SELECT EMPLOYEE_ID,FIRST_NAME,SALARY,
CASE
WHEN SALARY>=10000 THEN 'A'
WHEN SALARY>=8000 AND SALARY <10000 THEN 'B'
WHEN SALARY>=6000 AND SALARY <8000 THEN 'C'
ELSE 'D'
END AS '薪资计别'
FROM t_employees
ORDER BY SALARY ASC;
时间查询
SELECT 时间函数 ([参数列表])
# 查询当前系统日期加时间
SELECT SYSDATE();
# 查询当前系统日期
SELECT CURDATE();
# 查询当前系统时间
SELECT CURTIME();
# 获取指定日期为一年中的第几周
SELECT WEEK(SYSDATE());
# 获取指定日期中的年份
SELECT YEAR('2020-6-10');
# 获取小时值
SELECT HOUR(CURTIME());
# 获取分钟值
SELECT MINUTE(CURTIME());
# 指定日期之间的相隔天数
SELECT DATEDIFF('2020-4-1','2020-6-10');
# 计算date日期加上N天后的日期
SELECT ADDDATE('2020-6-10',30);
字符串查询
SELECT 字符串函数([参数列表])
# 将多个字符串做拼接
SELECT CONCAT('my','s','lq');
#字符串的替换,将原字符串的从3开始的两个字符替换成新的字符串;
SELECT INSERT('字符串A',位置(从1开始),个数,'替换的字符串');
SELECT INSERT('这是一个数据库',3,2,'MYSQL');
# 字符串转小写
SELECT LOWER('MySQL');
# 字符串转大写
SELECT UPPER('MySQL');
# 截取字符串
Select substring('javamysqloracle',5,5);
聚合函数
SELECT 聚合函数(列名) FROM 表名
# 求单列所有数据的和
SELECT SUM(salary) FROM t_employees;
# 求单列所有数据的平均值
SELECT AVG(salary) FROM t_employees;
# 求单列最大值
SELECT MAX(salary) FROM t_employees;
# 求单列最小值
SELECT MIN(salary) FROM t_employees;
# 求总行数
SELECT COUNT(employee_ID)FROM t_employees;
# 统计有提成的员工人数(会自动忽略null值)
SELECT commission_pct FROM t_employees;
SELECT COUNT(commission_pct) FROM t_employees;
分组查询
SELECT 列名 FROM表名 WHERE条件 GROUP BY 分组依据(列)
注:分组查询中,select 显示的列只能是分组依据列,或者聚合函数列,不能出现其他的列
# 查询各部门的总人数
SELECT department_id ,COUNT(EMPLOTEE_ID)
FROM t_employees
GROUP BY DEPARTMENT_ID;
# 查询各部门的平均工资
SELECT department_id ,AVG(salary)
FROM t_employees
GROUP BY department_id;
# 查询各部门,各个岗位的总人数
SELECT DEpartment_id,job_id,COUNT(employee_id)
FROM t_employees
GROUP BY department_id ,job_id;
分组过滤查询
SELECT 列名 FROM 表名 WHERE 条件 GROUP BY 分组列== HAVING 过滤规则==
# 分组过滤查询
# 查询60/70/80组中工资最高的数据
SELECT department_id,MAX(salary)
FROM t_employees
GROUP BY Department_id
HAVING Department_id IN(60,70,80);
限定查询
SELECT 列名 FROM 表名 LIMIT 起始行,查询行数
用法: LIMIT 起始行,总行数
注: 起始行是从0开始, 代表了第一行,第二个参数代表的是从起始行开始查询几行
//查询前五行数据
SELECT * FROM t_employees LIMIT 0,5;
//从第四条开始查询,查询10行
SELECT * FROM t_employees LIMIT 3,10;
LIMIT 的典型应用: 分页查询
//一页显示10条,一共查询三页
SELECT * FROM t_employees LIMIT 0,10;
SELECT * FROM t_employees LIMIT 10,10;
SELECT * FROM t_employees LIMIT 20,10;
查询总结
书写顺序
SELECT 列名 FROM 表名
WHERE 条件
GROUP BY 分组
HAVING 过滤条件
ORDER BY 排序列 (asc/desc) (升序/降序)
LIMIT 起始行,总条数
执行顺序
- FROM :指定数据来源表
- WHERE:对查询做第一次过滤
- GROUP BY : 分组
- HAVING : 对分组后的数据做第二次过滤
- SELECT : 查询各字段的值
- ORDER BY : 排序
- LIMIT :限定查询结果
子查询
作为条件判断
SELECT 列名 FROM 表名 WHERE 查询条件
将子查询单行单列的结果作为外部查询的条件,然后做二次查询
//查询工资比Bruce高的人的工资
SELECT salary FROM t_employees WHERE salary>(
SELECT salary FROM t_employees WHERE first_name = 'Bruce');
作为枚举查询的条件
将子查询多行单列的结果作为外部查询的条件,然后做二次查询
SELECT employee_id ,first_name ,salary
FROM t_employees
WHERE department_id IN(
SELECT department_id FROM t_employees WHERE last_name = 'King');
- 查询工资高于60部门所有人的信息
关键字:ALL 全部
关键字: ANY 部分
作为一张表
将子查询多行多列的结果作为外部查询的一张表,做二次查询
注: 子查询作为临时表, 必须要为其赋予一个临时表名
SELECT Employee_id,first_name, salary FROM(
SELECT Employee_id,first_name, salary FROM T_employees ORDER BY salary DESC) AS temp
LIMIT 0,5;
合并查询
关键字: UNION(去除重复记录的合并查询)
关键字: UNION ALL (保留重复记录的合并查询)
SELECT * FROM T1 UNION SELECT * FROM T2;
SELECT * FROM T1 UNION ALL SELECT * FROM T2;
表连接查询
SELECT 列名 FROM 表1 连接方式 表2 ON 连接条件
内连接查询 (INNER JOIN ON)
# SQL标准内连接语法
SELECT * FROM T_EMPLOYEES
INNER JOIN T_JOBS
ON T_EMPLOYEES.JOB_ID = T_JOBS.job_id;
# MySQL 标准
SELECT * FROM t_employees, t_jobs
WHERE t_employees.job_id = t_jobs.job_id;
三表连接接查询
SELECT * FROM T_EMPLOYEES
INNER JOIN t_departments
ON t_employees.department_id = t_departments.department_id
INNER JOIN t_locations
ON t_locations.location_id = t_departments.location_id;
左外连接(LEFT JOIN ON)
注意: 左外连接,是以左表为主表,依次向右匹配,匹配到返回结果,匹配不到,以null值填充
SELECT * FROM T1
left JOIN T2
ON T1.id = T2.id
右外连接(RIGHT JOIN ON)
注意: 右外连接,是以右表为主表,依次向左匹配,匹配到返回结果,匹配不到,以null值填充
SELECT * FROM T1
RIGHT JOIN T2
ON T1.id = T2.id
DML操作(重点)
新增(INSERT)
对表新增一条数据
注: 表名后的列名和values里的值要一一对应,(个数,顺序,类型)
# 插入一条数据
INSERT INTO test(
id,NAME ,age)
VALUES (02,'李四',18);
修改(update)
UPDATE 表名 SET 列1 = 新值1, 列2 = 新值2 , WHERE 条件;
注意: set后跟多个列名 = 值,绝大多数型情况下,都要加where 条件,指定修改的条件,否则为整表更新
# 修改年龄为18的员工,工资为10086元
UPDATE test SET salary=10086 WHERE age = 18;
# 修改多个列
UPDATE test SET SALARY =10000,age =10 WHERE id =1;
删除(DELETE)
# 删除id为1 的数据信息
DELETE FROM test WHERE id = 1 ;
# 删除 name = 王五,age = 18的数据
DELETE FROM test WHERE NAME = '王五'AND age = 18;
清空整张表(TRUNCATE)
TRUNCATE TABLE 表名;
#清空test表 :对表做删除操作
#先把表销毁,然后按照原表的格式,创建一张新表
truncate table test;
# 清空test表的数据,:是对数据做删除操作
DELETE FROM test;
数据表的操作
数据类型
数值类型

日期类型
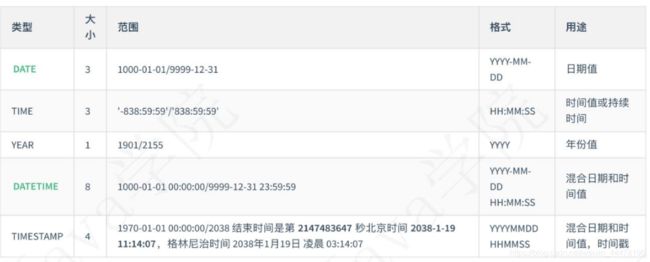
字符串类型
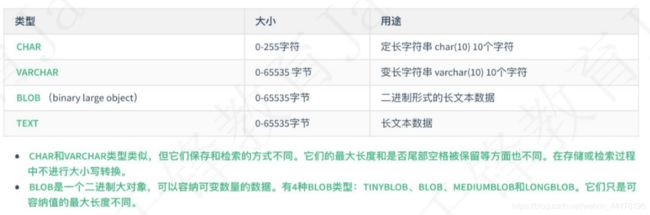
数据表的创建
CREATE TABLE demo(
id INT ,
NAME VARCHAR(20),
hours INT
)CHARSET = utf8;
数据表的修改(ALTER)
ALTER TABLE 表名 操作;
向现有表中添加一个列
//添加一个列,名为grade 类型为int
ALTER TABLE demo ADD grade INT;
修改表中的列
//修改gradE
ALTER TABLE demo MODIFY grade VARCHAR(2);
删除表中的列
删除每次只能删除一个列
# 删除表中名为grade的列
ALTER TABLE demo DROP grade;
修改列名
在表里有数据的时候,不能修改数据类型
ALTER TABLE demo CHANGE hours TIME INT;
修改表名
ALTER TABLE DEMO RENAME AAA;
数据表的删除(DROP)
DROP TABLE aaa;
约束
实体完整性约束
主键约束(PRIMARY KEY)
PRIMARY KEY:唯一,表示表中的一列数据,此列的值不可重复,且不能为null
# 在新建表的时候对ID列增加主键约束
CREATE TABLE demo(
id INT PRIMARY KEY,
NAME VARCHAR(20),
hours INT
)CHARSET = utf8;
唯一约束(UNIQUE)
UNIQUE:唯一,表示表中的一列数据,此列的值不可重复,可以为null
自动增长列(AUTO_INCREMENT)
必须要搭配主键约束一起使用
会实现本列自动+1的效果
域完整性约束
域完整性约束是限制单元格数据的正确性
非空约束(NOT NULL)
表示此列必须有值,不能为空
默认值约束(DEFAULT)
为此列设置一个默认值,如果插入数据的时候没有设置数值,则使用默认值
引用完整性约束(外键约束)
CONSTRAINT 引用名 FOREIGN KEY (列名) REFFERENCES 被引用表名( 列名)
删除的时候,一定要先删除从表,在删除主表,否则会报错
# 先新建主表(被引用的表)
# t1有两个列,一列编号,一列名字
CREATE TABLE t1(
id INT PRIMARY KEY AUTO_INCREMENT,
neme VARCHAR (10) UNIQUE NOT NULL);
CHARSET = utf8;
# 再新建从表(引用表)
# 从表有三个属性,一个编号,一个学生姓名,一个课程编号
CREATE TABLE t2(
id INT(100) PRIMARY KEY AUTO_INCREMENT,
Students_name VARCHAR(10) UNIQUE NOT NULL,
k_name VARCHAR(10) UNIQUE NOT NULL,
# 引用的列为k_name 引用来t1的name列
CONSTRAINT fk_t2_kname FOREIGN KEY (k_name) REFERENCES t1(NAME)
)CHARSET = utf8;
约束小结
# 1,创建班级表,内含 :
# 班级编号:int类型 主键,自增
# 班级名称:varchar类型 唯一,非空
CREATE TABLE class(
id INT PRIMARY KEY AUTO_INCREMENT,
classname VARCHAR(10) UNIQUE NOT NULL
) CHARSET = utf8;
# 2 创建学生表,内含:
# 学号,int 主键,自增
# 姓名,varchar 非空
# 性别,char 默认男
# 出生日期,date ,默认 2000-01-01
# 手机号码 varchar
# 班级名称 引用班级表的班级名称
CREATE TABLE students(
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(5)NOT NULL,
gender CHAR(1) DEFAULT '男',
birthday DATE DEFAULT '2020-01-01',
phone_num VARCHAR(11),
classname VARCHAR(10) UNIQUE NOT NULL,
CONSTRAINT a FOREIGN KEY (classname) REFERENCES class(classname)
)CHARSET = utf8;
事物
事物是一个原子操作,是一个最小的执行单元,可以由一个或多个sql语句组成,在同一个事物当中,所有的sql语句都执行成功,则整个事物成功,有一个sql语句失败,整个事物失败
事物的边界
开始
- 连接到数据库,执行一条DML语句
- 上一个事务结束后,又执行了一条DML语句,
结束
- 提交
1.显示提交: commit
2.隐式提交: 一条创建/删除/修改的语句,正常退出(客户端推出链接) - 回滚
1.显示回滚 : rollback
2. 隐式回滚: 非正常退出(断电,宕机),执行了创建.删除的语句,但是失败了,会为这个语句执行回滚
事物的原理
数据库会为每一个客户端都维护一个空间独立的缓存区(回滚段),一个事务中所有的增删改语句的执行结果都会缓存在回滚段中,只有当事务中所有的SQL语句都正常结束(commit)了,才会将回滚段中的数据同步到数据库中,否则无论因为哪种原因失败,整个事务都将回滚(rollback)
事物的特性(ACID):重点
- 原子性(Atomicity)
表示一个事务内的所有操作是一个整体,要么全部成功,要么全部失败 - 一致性(Consistency)
表示一个事务内有一个操作失败是,所有更改过的数据都必须回滚到修改前的状态 - 隔离性(Isolation)
事务查看数据操作时数据所处的状态,要么是另一并发事务修改它之前的状态,要么是另一并发事务修改它之后的状态,事务不会查看中间状态的数据 - 持久性(Durability)
持久性事务完成之后,它对于系统的影响是永久性的
事务应用
# 1 开启事务
START TRANSACTION;
## 模拟转账
UPDATE account SET money = money -1000 WHERE id = 1 ;
UPDATE account SET money = money +1000 WHERE id = 2;
SELECT * FROM account;
# 如果成功
COMMIT;
# 如果失败
ROLLBACK;
权限管理
创建用户
CREATE USER 用户名 IDENTIFIED BY 密码;
==注:密码一定要用 ’ ’ 括起来;
CREATE USER user_name IDENTIFIED BY '1234';
授权
GRANT ALL ON 数据库.表 TO 用户名;
GRANT ALL ON companydb.* TO user_name;
撤销权限
REVOKE ALL ON 数据库.表名 FROM 用户名;
注: 被撤销权限的账户需要重新登录一下才能生效
REVOKE ALL ON companydb.* FROM user_name;
删除用户
同上,不会立即生效,需要重新登录
DROP USER user_name;
视图
概念
视图,虚拟白哦,从一个表或者多个表中查询出来的表,作用和真是表一样,包含一系列带有行和列的数据,视图中,用户可以使用SELECT 语句查询数据,也可以增删改,视图可以使用户操作更方便,并保障数据库系统安全
视图的优缺点
-
优点:
简单: 所见即所得
安全: 用户只能查询或修改他们所能见到的数据
逻辑独立性: 可以屏蔽真是表结构变化带来的影响 -
缺点
性能相对较差
修改不方便,特别是复杂的聚合视图基本无法修改
视图的创建
CREATE VIEW 视图名 AS 查询数据源表语句
# 创建一个视图
CREATE VIEW t_view
AS
SELECT id, NAME FROM `demo`;
使用视图
# 直接查询视图
SELECT * FROM t_view;
视图的修改
方式一:CREATE OR REPLACC VIEW 视图名 AS 查询语句 (用于不确定视图是否存在,如果存在就更新,如果不存在就新建
方式二: ALTER VIEW 视图名 AS 查询语句 (确定存在 则使用此方式)
视图的删除
DROP VIEW view_name;
注意:
