Java数据结构和算法-链表(1-单链表)
在前面所讲的数组当中,我们发现虽然数组能解决基本的插入、删除和查找的问题,但是数组却存在着一些缺点,无序数组的查找有序数组的插入,以及两者的删除效率都很低,而且数组创建之后其大小是固定不变的。
而在本章中所讲的链表就可以解决这些问题,它也是一种数据存储结构,在大多数情况下我们可以通过链表来代替数组的操作,比如说栈和队列的实现,除非需要频繁的通过下标随机访问数据。
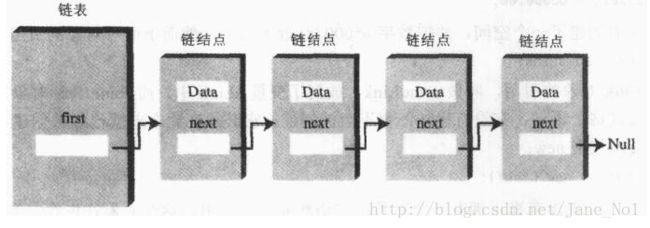
链接点(Link)
在每个链表中,每一个数据项都包含在一个Link类对象当中(因为链表中有许多相同的链接点,所以就用一个类对象来表示它),在每个链接点的Link类对象中都包含一个对下一个链接点进行引用的next对象字段,并且链表也有一个指向第一个链接点的引用first字段。如下图:
下面代码是对Link类的定义的一部分:
class Link {
private int iData;
private double dData;
private Link next;
}在本文中我们定义的Link类只包含了两个数据项:iData和dData,实际上一个链接点可以包含多个数据项,并且有时当数据项太多时,我们可以用一个类来封装它,如下:
class Link {
private itemData data; //包含了链接点所需的数据项
private Link next;
}引用和基本类型
上述的链接点类的定义中引用了同一个类的对象,这被称为是自引用。在C++中,如果在某个类中定义一个字段如下:
private Link next;那么这个类就是确确实实的包含了这个Link的对象,所以在C++中你不能写一个如上代码的自引用,因为编译器在不知道一个Link类占有多大内存空间的情况下,该如何定义包含了相同对象的Link对象应该占用多大的空间。因此在C++中只能通过定义一个指向同种类型的对象的指针来进行所谓的自引用。
但是Java不同,在上述代码中,Link对象next并没有包含Link整个对象,而只是在next中存放了另一个Link对象的地址,尽管看起来好像包含了。
注意,在Java中,基础类型的存储和对象的存储是完全不同的,基础类型的存储,不是对某个类型的引用,而是确确实实的包含了这个类型的数据,比如:
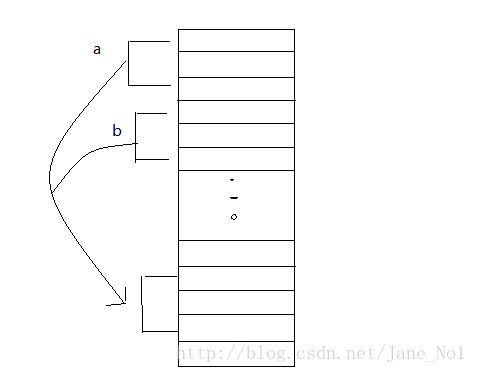
int a = 123;在a中,确实通过创建的空间来存放了123这个数据。但是对对象的引用:
Link a = b;则是把对Link对象的引用b放在了a中,而b对象本身是在其他地方,这是a和b都同时指向了同一个Link对象,如下图(画的似乎有点丑):
关系,而不是位置
对于数值,每一个数据项对应的位置都是给定的可以通过下标来访问这个数据项,就像是给定了地址,你就可以找到某人的家。但是链表不同,链表访问某个元素,只能沿着链一直向下寻找,而链接点之间是通过关系next链接的,就好像人们之间的关系,想查找f这个人,去问了a,a说b可能知道,于是去问了b,b说f和c出去了,去问d,都说f和e在一起,去问e,e说f在办公室,于是顺着这条关系链我们最终找到了f。链表就是这样,不能够直接访问某个数据项,而需要通过关系来找到它。
单链表
当链表只能在链表头进行数据的插入和删除以及通过遍历来显示某个数据项的内容时,这个链表就被称为单链表。
单链表的Java代码
以下代码通过Link类来封装数据项的内容已经下一个链接点的引用,然后通过LinkList来封装第一个链接点的引用及对链接点插入和删除等操作:
class Link {
private int iData;
private double dData;
private Link next;
public Link(int i, double d) {
iData = i;
dData = d;
}
public void displayLink() {
Systsem.out.println("{" + iData + ", " + dData + "}");
}
}//end Link
class LinkList {
private Link first; //指向第一个链接点
public void insertFirst(int i, double d) {
Link l = new Link(i, d);
l.next = first;
first = l;
}
public Link deleteFirst() {
Link temp = first;
first = first.next;
return temp;
}
public boolean isEmpty() {
return (first == null)
}
public void displayList() {
Link current = first;
while(current != null) {
current.displayLink();
current = current.next; //指向下一个节点
}
}
}在上面的两个类的构造函数,都没有对next和first初始化,赋予null值,因为在定义对象时,如果没有赋值,程序会自动对其赋予null值。
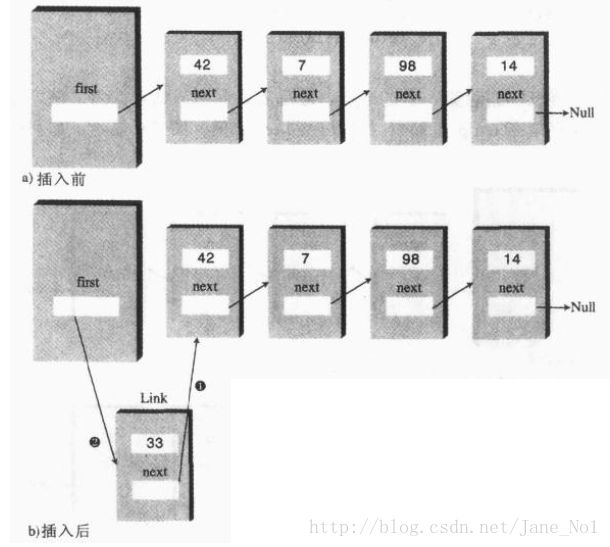
插入insertFirst操作,单链表只能在链表头插入新的链接点,所以首先将新插入节点的next赋予第一个节点的引用,然后再将表头first指向新节点,从而完成插入操作,如下图:
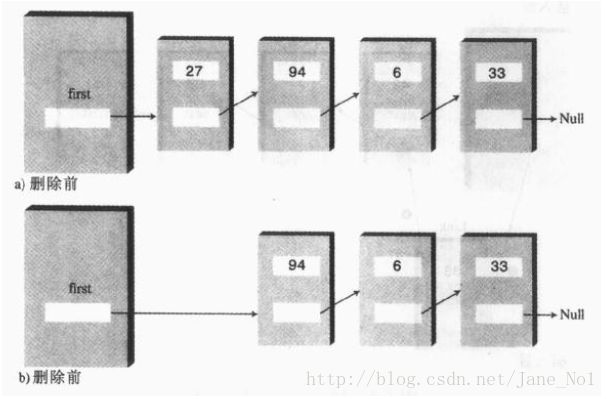
删除deleteFirst操作,删除操作和插入操作恰好相反,删除操作将表头的first重新指向了第二个链接点,从而断开了与第一个链接点的连接,如下图:
在C++或者其它类似的语言中,从链表中取下一个节点后,需要考虑如何删除节点。但是此时该节点仍然存放在内存中,且没有任何东西指向它,这是个很棘手的问题。但是在Java中,我们不需要担心这些,因为垃圾收集进程将在未来的某个时刻销毁它。
还有一点要注意的是,在删除操作之前需要判断链表是否为空,这个操作通过调用isEmpty()方法来完成。
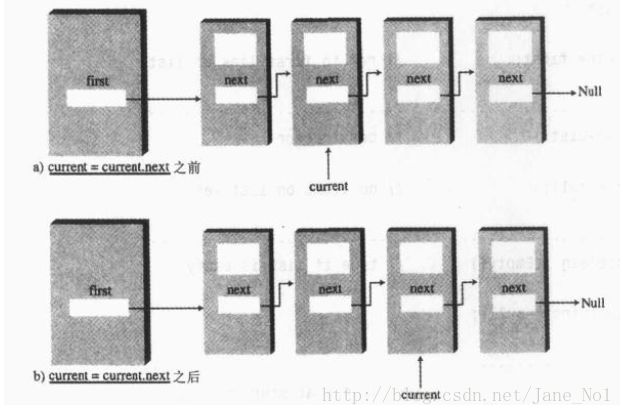
displayList()方法实现了对链表的节点展示操作,用current变量引用当前要展示的节点。具体过程如下图:
查找和删除指定链接点
在下面的程序为上述的LinkList新增了两个新的方法,查找和删除特定的链接点:
public Link findLink(int key) {//查找iData值为key的链接点
Link current = first;
while(current != null) {
if(current.iData == key)
break;
current = current.next;
}
if(current != null)
return current;
}
public Link deleteLink(int key) {//删除iData值为key的链接点
Link current = first;
Link previous = first;
while(current != null;) {
if(current.iData == key)
break;
previous = current;
current = current.next;
}
if(current != null)
previous.next = current.next;
return current;
}findLink方法定义了一个Link变量current,指向当前查找到的链接点,初始时给它赋予first,指向第一个链接点,然后不断沿着链表移动,直到找到找到想要的链接点为止。
deleteLink方法定义了两个Link变量previous和current,previous指向当前查找到的链接点的前一个链接点,为的是在找到想要删除的Link时,将该链接点的前一个链接点的next变量指向要删除的链接点的后一个链接点,从而完成对链接点的删除,如下图:

在这两个方法中,我们要查找的关键字是iData,这个是以具体情况改变的。
其他方法
当然除了上面的几个方法的实现,也可以有其他方法,比如在某个特定的链接点前后插入新链接点等。在后面的迭代器中会对这个方法加以实现。