3.实战java高并发程序设计--JDK并发包---3.4 使用JMH进行性能测试
3.4.1 什么是JMH
JMH(Java Microbenchmark Harness)是一个在OpenJDK项目中发布的,专门用于性能测试的框架,其精度可以到达毫秒级。通过JMH可以对多个方法的性能进行定量分析。比如,当要知道执行一个函数需要多少时间,或者当对一个算法有多种不同实现时,需要选取性能最好的那个。
3.4.2 Hello JMH
要想使用JMH,首先需要得到JMH的jar包,一种简单可行的方式是使用Maven进行导入,代码如下:

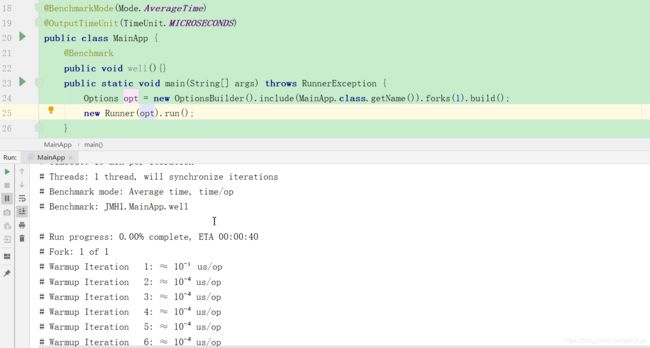


其中被度量的代码为函数MainApp()。类似于JUnit,被度量代码用注解@Benchmark标注,这里仅仅为一个空函数。在main()函数中,首先对测试用例进行配置,使用Builder模式配置测试,将配置参数存入Options对象,并使用Options对象构造Runner启动测试。
这是一个测试结果的报告,前面部分表示测试的基本信息。比如,使用的Java路径,预热代码的迭代次数,测量代码的迭代次数,使用的线程数量,测试的统计单位等。从fork 1 往下开始显示了每一次热身中的性能指标,预热测试不会作为最终的统计结果。预热的目的是让Java虚拟机对被测代码进行足够多的优化,比如,在预热后,被测代码应该得到了充分的JIT编译和优化。从第17行开始显示测量迭代的情况,每一次迭代都显示了当前的执行速率,即一个操作所花费的时间。在进行20次迭代后,进行统计,在本例中,第29行显示了wellHelloThere()函数的平均执行花费时间为0.001μs,误差为0.001μs。
3.4.3 JMH的基本概念和配置
为了能够更好地使用JMH的各项功能,首先需要对JMH的基本概念有所了解。
1.模式(Mode)Mode表示JMH的测量方式和角度,共有4种。
● Throughput:整体吞吐量,表示1秒内可以执行多少次调用。
● AverageTime:调用的平均时间,指每一次调用所需要的时间。
● SampleTime:随机取样,最后输出取样结果的分布,例如“99%的调用在xxx毫秒以内,99.99%的调用在xxx毫秒以内”。
● SingleShotTime:以上模式都是默认一次Iteration是1秒,唯有SingleShotTime只运行一次。往往同时把 warmup 次数设为0,用于测试冷启动时的性能。
2.迭代(Iteration)
迭代是JMH的一次测量单位。在大部分测量模式下,一次迭代表示1秒。在这一秒内会不间断调用被测方法,并采样计算吞吐量、平均时间等。
3.预热(Warmup)
由于Java虚拟机的JIT的存在,同一个方法在JIT编译前后的时间将会不同。通常只考虑方法在JIT编译后的性能。
4.状态(State)
通过State可以指定一个对象的作用范围,范围主要有两种。一种为线程范围,也就是一个对象只会被一个线程访问。在多线程池测试时,会为每一个线程生成一个对象。另一种是基准测试范围(Benchmark),即多个线程共享一个实例。
5.配置类(Options/OptionsBuilder)
在测试开始前,首先要对测试进行配置。通常需要指定一些参数,比如指定测试类(include)、使用的进程个数(fork)、预热迭代次数(warmupIterations)。在配置启动测试时,需要使用配置类,比如:

3.4.4 理解JMH中的Mode
在JMH中,吞吐量和方法执行的平均时间是最为常用的统计方式。下面是吞吐量的测量方法:


另外一种有趣的统计方式是采样,即不再计算每个执行方法的平均执行时间,而是通过采样得到部分方法的执行时间\

3.4.5 理解JMH中的State
JMH中的State可以理解为变量或者数据模型的作用域,通常包括整个Benchmark级别和Thread线程级别。声明了两个数据模型,一个是Benchmark级别,另一个是Thread级别。

3.4.6 有关性能的一些思考
性能是一个重要且很复杂的话题。简单来说,性能调优就是要加快系统的执行,因此就是要尽可能使用执行速度快的组件。有时候,我们会不自觉地询问,哪个组件更快,哪个方法更快?但是,这个看起来很简单的问题却是没有答案的。在大部分场景中,并没有绝对的快或者慢。性能需要从不同角度、不同场景进行评估和取舍。一个典型的例子就是时间复杂度和空间复杂度的关系。如果一个算法时间上很快,但是消耗的内存空间极其庞大,还能说它是一个好的算法吗?反之,如果一个算法内存消耗很少,但是执行时间却很长,可能同样也是不可取的。对性能的优化和研究就是需要在各种不同的场景下,对组件进行全方位的性能分析,并结合实际应用情况进行取舍和权衡。
下面以HashMap和ConcurrentHashMap为例进行性能分析和比较。首先,从严格意义上说,这两个模块无法进行比较,因为它们的功能是不等价的。只有在等价的功能下,去比较性能才是有意义的。HashMap并不是一个线程安全的组件,而ConcurrentHashMap却是线程安全的组件。因此,这里再引入一个线程安全的组件,它由HashMap包装而成:Collections.synchronizedMap(new HashMap())。
其次,虽然同属于Map接口的实现,但依然很难说HashMap和ConcurrentHashMap谁快谁慢。在Map接口中,有多达20种方法。如果HashMap的get()方法比ConcurrentHashMap的快,也不能说明它的put()方法或者size()方法同样也会更快。因此,快慢的比较不能离开具体的使用场景。
最后,除了执行时间的比较,还有空间使用的比较,显而易见,ConcurrentHashMap内存结构更加复杂,也使用了更多的内存空间。但在绝大部分场合,这里产生的内存消耗都是可以接受的。
下面这段代码显示了对HashMap、Collections.synchronizedMap(new HashMap())和ConcurrentHashMap的JMH性能测试。

可以看到,在单线程下,ConcurrentHashMap的get()方法比HashMap的略快,但是size()方法却比HashMap的慢很多。当HashMap进行同步后,由于同步锁的开销,size()方法的性能急剧下降,与ConcurrentHashMap的size()方法在一个数量级上,但依然比ConcurrentHashMap快。
由于使用了两个线程,一般来说,吞吐量可以增加一倍。尤其是HashMap这个完全不关心线程安全的实现,增加线程数量可以几乎等比增加其吞吐量。值得注意的是,ConcurrentHashMap的size()方法的吞吐量也等比例增加一倍。但是HashMap的同步包装由于引入了线程竞争性能反而出现下降。对于get()方法,由于ConcurrentHashMap的合理优化,避免了线程竞争,因此其性能和HashMap几乎等同,甚至略胜。而同步的HashMap在两个线程的场景中出现了严重的性能损失。
。在JDK 8后,对ConcurrentHashMap的size()方法有了极大的更新。以下是使用JDK 8进行的两个线程的性能测试
可以看到,在JDK 8中,ConcurrentHashMap的size()方法的性能有了极大的提升(实际上是以牺牲精确性为代价的)。
3.4.7 CopyOnWriteArrayList类与ConcurrentLinkedQueue类
CopyOnWriteArrayList类和ConcurrentLinkedQueue类是两个重要的高并发队列。CopyOn-WriteArrayList类通过写复制来提升并发能力。ConcurrentLinkedQueue类则通过CAS操作和锁分离来提高系统性能。那么在实际应用中,对于这两个功能上极其相似的组件,应该如何选择呢?根据实际的应用场景,两者的性能表现可能会有所差异。
可以看到,在并发条件下,写的性能远远低于读的性能。而对于CopyOnWriteArrayList类来说,当内部存有1000个元素的时候,由于复制的成本,写性能要远远低于只包含少数元素的List,但依然优于ConcurrentLinkedQueue类。就读的性能而言,进行只读不写的Get操作,两者性能都不错。但是由于实现上的差异,ConcurrentLinkedQueue类的size操作明显要慢于CopyOnWriteArrayList类的。因此,可以得出结论,即便有少许的写入,在并发场景下,复制的消耗依然相对较小,当元素总量不大时,在绝大部分场景中,CopyOnWriteArrayList类要优于ConcurrentLinkedQueue类。