sql数据库查询聚合函数_如何使用SQL Server数据质量服务确保正确的数据聚合
sql数据库查询聚合函数
介绍 (Introduction)
An interesting opportunity arose at a client site during early October which provided a phenomenal opportunity to do a Data Quality Services implementation. My client (a grocer) had been requested to produce summary reports detailing the amount of funds spent during 2016 (YTD) with the myriad of manufacturers from whom the chain purchases their inventory. All “accounts payable” entries are done manually and as such are prone to errors.
10月初,一个客户站点上出现了一个有趣的机会,这为执行数据质量服务实现提供了绝佳的机会。 我的客户(杂货商)被要求提供摘要报告,详细说明2016年(年初至今)期间与连锁店从其购买库存的众多制造商所花费的资金量。 所有“应付帐款”条目都是手动完成的,因此容易出错。

In fact, the screenshot above shows the issues encountered with a subset of “Kellogg’s”
实际上,上面的屏幕截图显示了“凯洛格”子集遇到的问题
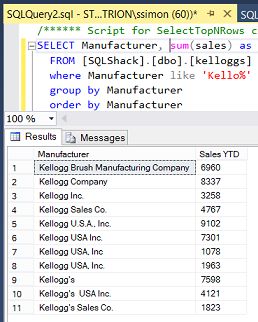
Thus when the client would execute the above query, the total purchases for “Kellogg’s” are not truly represented. Why? Mainly because there should be one and only one summary figure for the cereal manufacturer.
因此,当客户执行上述查询时,“凯洛格”的总购买额并未真正体现出来。 为什么? 主要是因为谷物制造商应该只有一个且只有一个汇总图。
This is our point of departure for today’s “fire side chat”.
这是我们今天的“火边聊天”的出发点。
入门 (Getting started)
For those of us whom have never worked with SQL Server Data Quality Services, please do have a look at a SQL Shack article entitled: How clean is YOUR data!!
对于那些从未使用过SQL Server数据质量服务的人,请阅读SQL Shack文章,标题为: 您的数据有多干净!
In the above mentioned article we are shown step by step how to set up a Data Quality Services application. This includes the creation of the model PLUS step by step instructions showing us how to create and implement a Data Quality Project.
在上述文章中,我们逐步展示了如何设置数据质量服务应用程序。 这包括创建模型PLUS的逐步说明,向我们展示了如何创建和实施数据质量项目。
继续 (Moving on)
From this point onward we shall assume that we have a basic understanding of how Data Quality Services functions and the benefits that it provides. The client worked through his master list of their creditors and a portion of the list may be seen below.
从现在开始,我们将假定我们对数据质量服务的功能及其提供的好处有基本的了解。 客户查看了其债权人的总清单,清单的一部分如下所示。
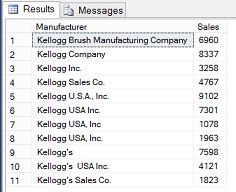
The astute reader is reminded that based upon the image above, that the purchases are not correctly aggregated as most of the variations of “Kellogg’s” could be aggregated together. However we are getting ahead of ourselves.
提醒精明的读者,根据上图,购买的商品未正确汇总,因为“凯洛格”的大多数变体都可以汇总在一起。 但是,我们正在超越自己。
建立我们的知识库 (Creating our Knowledge Base)
We begin by creating a new Data Quality Services Knowledge Base. Clicking upon the “Start” button, we bring up the “SQL Server 2016 Data Quality Client” (see below).
我们首先创建一个新的数据质量服务知识库。 单击“开始”按钮,我们调出“ SQL Server 2016数据质量客户端”(见下文)。
When the client appears, we select “New Knowledge Base” (see below).
当客户端出现时,我们选择“新知识库”(见下文)。
The “New Knowledge Base” designer opens.
将打开“新知识库”设计器。

We give our new knowledge base a name and note that we do not inherit an existing knowledge base. This is why we leave the “Create Knowledge Base from:” option as “None”.
我们给我们的新知识库起一个名字,并注意我们不会继承现有的知识库。 这就是为什么我们将“从以下位置创建知识库”选项保留为“无”的原因。
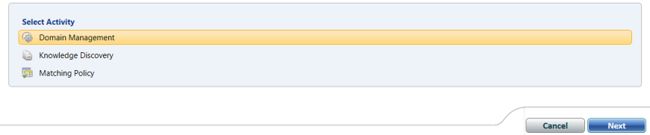
We leave the “Select Activity” set to “Domain Management” and click “Next” (see above).
我们将“选择活动”设置为“域管理”,然后单击“下一步”(请参见上文)。
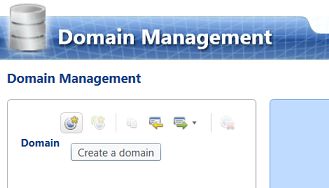
We find ourselves on the Domain Management tab. We wish to “Create a domain” (see above).
我们在“域管理”选项卡上找到自己。 我们希望“创建域”(请参见上文)。
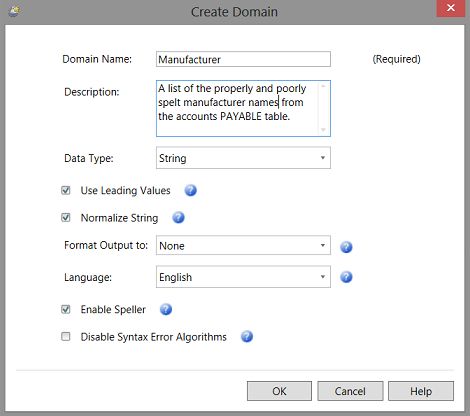
The “Create Domain” dialogue box opens. The reader is reminded that a “Domain” is comparable to a database table or an “entity” within the Data Quality Services realm. This domain will contain a list of manufacturers (a lone field / attribute). We click “OK” to continue (see above).
“创建域”对话框打开。 提醒读者的是,“域”相当于一个数据库表或数据质量服务领域内的“实体”。 该域将包含制造商列表(一个单独的字段/属性)。 我们单击“确定”继续(见上文)。

The reader will note that we find ourselves on the “Manufacturer definition screen”. There are 5 activities that may be performed upon the new domain. We shall be utilizing the “Domain Value” for this exercise. An in depth discussion with step by step instructions describing the purpose and functionality of the remaining tabs may be found in the SQL Shack article cited above.
读者会注意到,我们在“制造商定义屏幕”上发现了自己。 在新域上可以执行5种活动。 我们将在此练习中使用“域值”。 可以在上面引用SQL Shack文章中找到有关讨论其余选项卡的目的和功能的逐步说明的深入讨论。

Clicking upon the “Domain Values” tab we opt to import the creditor list from an Excel spreadsheet (the only way at present).
单击“域值”选项卡,我们选择从Excel电子表格中导入债权人列表(目前唯一的方法)。
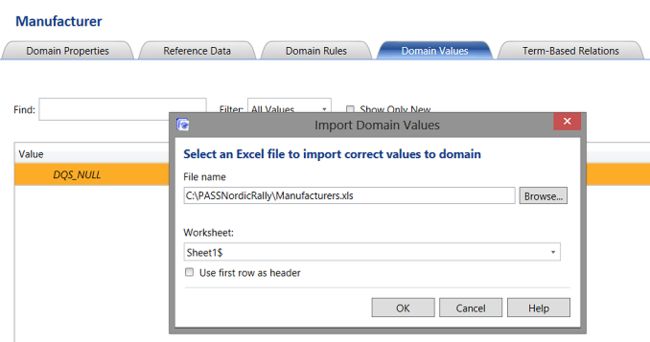
The “Import Domain Values” dialogue box opens and we browse our way to the location of the spreadsheet containing the list of manufacturers that we extracted from the clients “Account Payable” tables (see above). We click “OK” to continue.
“导入域值”对话框打开,我们浏览到电子表格的位置,该电子表格包含从客户“应付账款”表中提取的制造商列表(请参见上文)。 我们单击“确定”继续。

We are informed that our import was successful (see above) and click “OK” to continue.
我们被告知导入成功(请参见上文),然后单击“确定”继续。

We note that all the manufacturer names now appear within the “Manufacturer” entity on the screen (see above).
我们注意到,所有制造商名称现在都显示在屏幕上的“制造商”实体中(请参见上文)。
修改错误 (Modifying the errors)
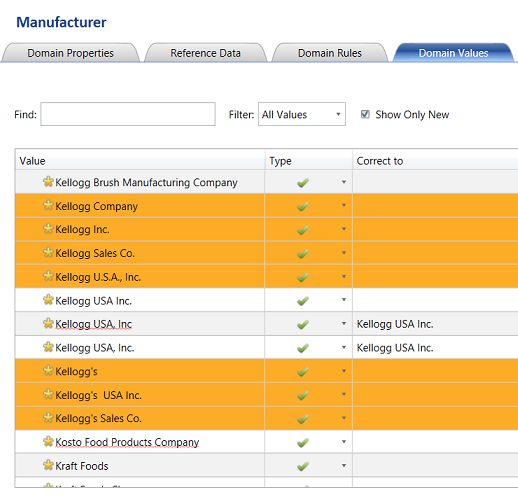
We highlight the wrongly spelt entries by clicking upon the row and holding down the left control key. The LAST CLICK will be on the name that we want to utilize as the correct name, which in this case is “Kellogg USA Inc.” as this was my client’s ‘name’ of choice (see above).
通过单击该行并按住左控制键,可以突出显示拼写错误的条目。 LAST CLICK将使用我们要用作正确名称的名称,在本例中为“ Kellogg USA Inc.”。 因为这是我客户选择的“名称”(请参见上文)。

Having selected the names that we wish to alter, we “right click” on the screen and select “Set as Synonyms” from the context menu (see above).
选择了我们想要更改的名称后,我们在屏幕上“右键单击”,然后从上下文菜单中选择“设置为同义词”(参见上文)。
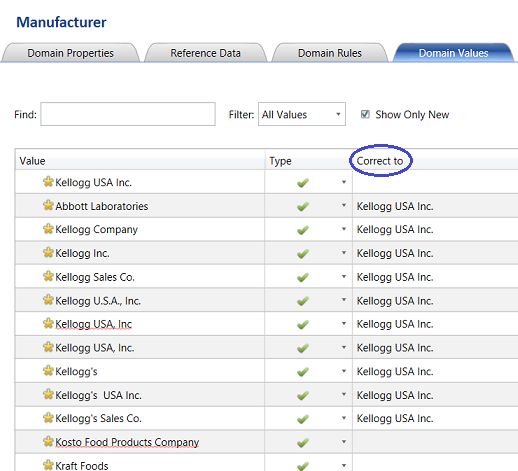
We note that all the incorrect values now have a “Correct to” value assigned to them. This said and going forward, each time the system finds one of these “bad boys”, it will correct the name to the spelling that is shown (see above). Should you ever wish to alter this spelling, then there is no issue. Simply log into the Data Quality Services client and alter the values in a similar manner.
我们注意到,现在所有不正确的值都分配有一个“正确于”值。 这样说来,以后,每次系统找到这些“坏男孩”之一时,它将把名称更正为显示的拼写(参见上文)。 如果您希望更改此拼写,则没有问题。 只需登录Data Quality Services客户端并以类似方式更改值。
For the sake of brevity, we shall assume that this was the only error encountered. In real life, there will be numerous rows to be altered and adjusted.
为了简洁起见,我们将假定这是唯一遇到的错误。 在现实生活中,将有许多行要更改和调整。

We click “Finish”. The system then asks us if we wish to “Publish” our changes. We select “Publish” and we exit the designer (see above).
我们点击“完成”。 然后,系统询问我们是否要“发布”我们的更改。 我们选择“发布”,然后退出设计器(见上文)。
Once again and for the sake of brevity our “Knowledge Base” is complete. Under normal circumstance one would run the “Knowledge Discovery” and “Matching Policy” steps as are described in detail in the SQL Shack article entitled: How clean is YOUR data!!
再次为了简洁起见,我们的“知识基础”已经完成。 在正常情况下,可以运行“知识发现”和“匹配策略”步骤,如SQL Shack文章标题中详细描述的那样: 您的数据有多干净!
The “Knowledge Discovery” module informs you of how your selected domain values compare with an un-sampled set of manufacturers (see below).
“知识发现”模块会通知您所选域值与未抽样的制造商集比较的方式(请参阅下文)。
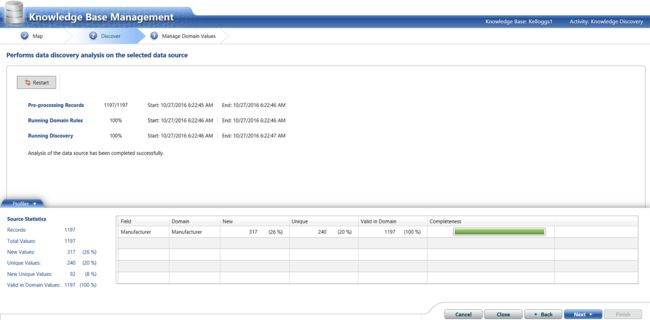
In the situation above, the astute reader will note that there are 317 new records. This should NOT be IF the client had a complete list of creditors to begin with. Thus it is “back to the drawing board” until there are no new manufacturers (see above).
在上述情况下,精明的读者会注意到有317条新记录。 这不应该被IF 客户首先要有完整的债权人清单。 因此,直到没有新的制造商(见上文),它才“回到图纸板上”。
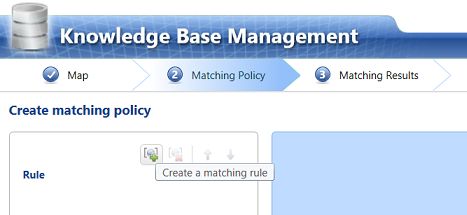
The third step is to create a “Matching Policy”. In other words just how similar must a potential wrongly spelt name be, in order to warrant changing that misspelling to “Kellogg USA Inc.” After all “Stationary” and “Stationery” are similar in spelling HOWEVER they have two entirely different meanings and therefore would never be interchanged. This unfortunately is where the “human element” comes into play, at least until the system has learnt what may be changed and what may not be changed.
第三步是创建“匹配策略”。 换句话说,一个潜在的错误拼写名称必须多么相似,才能保证将拼写错误更改为“ Kellogg USA Inc.”。 毕竟“文具”和“文具”在拼写上是相似的,但是它们具有两种完全不同的含义,因此永远不会互换。 不幸的是,这是“人为因素”发挥作用的地方,至少直到系统了解到可能会更改的内容和可能不会更改的内容为止。
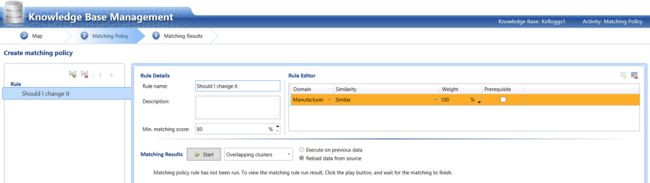
In the screen shot above we indicate to the system that we want the manufacturers to be 100% similar before effecting a change. Now this may seem like an oxymoron HOWEVER do not forget that during the first phase of this exercise we supposedly extracted ALL THE VARIATIONS in spelling plus we told the system how we wanted it to handle each specific variation of spelling. This said and assuming that there are no new variations in spelling with each successive data load, then one may assume that this rule will be efficient and effective. Obviously maintaining the “Master Knowledge Base dictionary” is of major importance.
在上面的屏幕截图中,我们向系统指示我们希望制造商在进行更改之前100%相似。 现在,这似乎有点矛盾,但是请不要忘记,在本练习的第一阶段中,我们应该提取出拼写中的所有变化,此外,我们还告诉系统我们希望它如何处理拼写的每个特定变化。 这就是说,并假设每个连续的数据加载在拼写上没有新的变化,那么人们可以假设该规则将是有效的。 显然,维护“ Master Knowledge Base词典”至关重要。
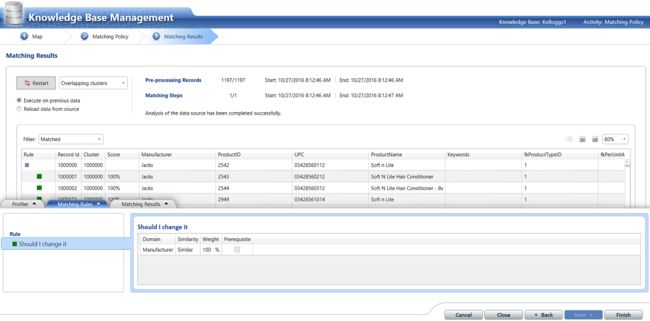
Having created our rule, we click “Next” and process the incoming data. This incoming new data (albeit new production data or a new subset of existing data) is done JUST TO ensure that the master list is complete. We must remember that if we encounter new manufacturers with each dataset then we do have an issue and we are therefore obliged to update the master list (as discussed above). In short and at all times, we must be certain that there are no new variations introduced.
创建规则后,我们单击“下一步”并处理传入的数据。 只是为了确保主清单完整,就完成了这些传入的新数据(尽管是新的生产数据或现有数据的新子集)。 我们必须记住,如果每个数据集都遇到新的制造商,那么我们确实会遇到问题,因此我们有义务更新主列表(如上所述)。 总之,在任何时候,我们都必须确保没有引入新的变化。
创建我们的数据质量项目 (Creating our Data Quality Project)
Having created and processed our Data Quality Services Knowledge Base, we are in a position to create a Data Quality Services Project based upon the Kellogg1’s Knowledge Base (see below).
创建并处理了数据质量服务知识库后,我们可以根据Kellogg1的知识库创建一个数据质量服务项目(请参见下文)。

Opening the new “Data Quality Project”, we give our project a name. Our “Kelloggs1” project will inherit the logic from the “Kelloggs1” Knowledge Base (see above).
打开新的“数据质量项目 ”,我们为项目命名。 我们的“ Kelloggs1”项目将继承 “ Kelloggs1”知识库的逻辑(请参见上文)。

We accept “Cleansing” as the selected activity and click “Next” (see above).
我们接受“清洁”作为所选活动,然后单击“下一步”(请参见上文)。

We are now asked to enter our raw data source. For this example we shall utilize a database and table that I have on my local drive. We set the “Source Column” to the manufacturer name (see above). The actual data may be seen below.
现在要求我们输入原始数据源。 对于此示例,我们将利用本地驱动器上的数据库和表。 我们将“源列”设置为制造商名称(请参见上文)。 实际数据如下所示。

The “Domain” on the other hand, originates from the “Kelloggs1” Knowledge Base (see below).
另一方面,“域”源自“ Kelloggs1”知识库(请参见下文)。
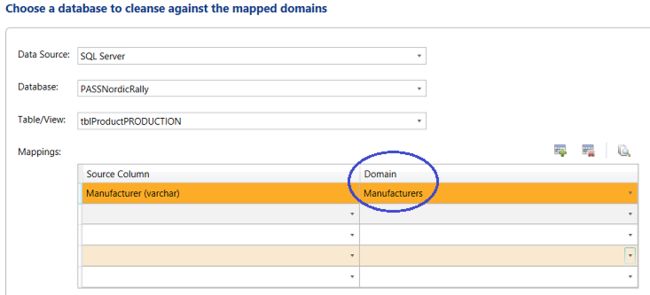
We click “Next” to continue.
我们单击“下一步”继续。

At this point it is worthwhile remembering that whilst we have the Knowledge Base, each day brings new data to the enterprise. This implies more data entry and unfortunately more potential for the “gremlins” to set in. We click “Start” to process the data. Once again to check for “New” records.
在这一点上,值得记住的是,尽管我们拥有知识库,但每天都会为企业带来新的数据。 这意味着需要输入更多的数据,而不幸的是,可能需要设置更多“ gremlins”。单击“开始”以处理数据。 再次检查“新”记录。

We note the completeness gage shows some questionable data. This is one sure indication that you are missing records within the master list. These missing “manufacturers” must be added.
我们注意到完整性测验显示了一些可疑的数据。 这肯定表明您缺少主列表中的记录。 必须添加这些缺少的“制造商”。
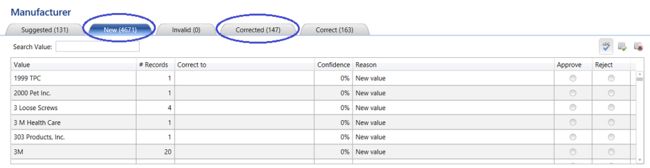
Clicking the “Next” button we confirm this. Indications are that the new lot of incoming data contained 4671 records that were totally new and that these records had to be added to the master list. HOWEVER what is important to note is that the system found 147 records that were spelt incorrectly and “corrected” these records.
单击“下一步”按钮,我们确认。 有迹象表明,新输入的数据中包含4671条全新的记录,这些记录必须添加到主列表中。 但是,值得注意的是,系统发现了147条拼写错误的记录,并“更正”了这些记录。
Having added these 4671 records to the master list and having re-published the Knowledge Base we are in a position to finish the “Kellogs1” project.
将这4671条记录添加到主列表中并重新发布知识库后,我们可以完成“ Kellogs1”项目。
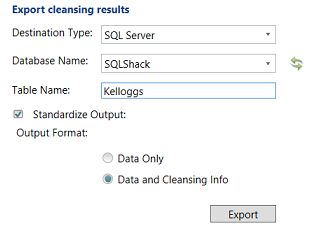
We extract the data processed via the project and export it to the “Kelloggs” table within the SQL Shack database. The importance of having this data within the database will be seen in a few minutes.
我们提取通过项目处理的数据,并将其导出到SQL Shack数据库中的“ Kelloggs”表。 几分钟后就会看到在数据库中包含此数据的重要性。

We note that the system found a plethora of records containing variations of
我们注意到,系统发现了大量记录,其中包含
“Kelloggs” and in each case “corrected” the spelling (see the “Manufacturer_Output” field above).
“家乐氏”,并在每种情况下均“纠正”拼写(请参见上面的“ Manufacturer_Output”字段)。
Now that we have completed the necessary work within Data Quality Services we are in a position to actually produce the require data to satisfy the end client’s needs.
现在,我们已经在数据质量服务中完成了必要的工作,我们可以实际生成需求数据来满足最终客户的需求。
塑造我们的数据以满足我们的需求 (Moulding our data to suit our needs)
As a reminder to the reader, the original list of sales values looked similar to the one shown below:
为了提醒读者,原始的销售价值清单看起来与以下所示类似:

Opening SQL Server Management Studio we create a query based upon the accounts payable data and the cleansed data which originated from the Data Quality Service Knowledge Base.
打开SQL Server Management Studio,我们根据应付帐款数据和源自数据质量服务知识库的清理数据创建查询。
SELECT Kell.Manufacturer_Output as Manufacturer, sum(sales) as Sales
FROM [SQLShack].[dbo].[DQSCompanyMasterSales2016] orig inner join [dbo].[kelloggs] kell
on kell.Manufacturer_Source = orig.Manufacturer
Group by Kell.Manufacturer_Output
order by Kell.Manufacturer_Output

Running the query, we note that the data is correctly aggregated based upon the corrected manufacturer name.
运行查询,我们注意到根据正确的制造商名称正确汇总了数据。
Naturally this query may be converted to a stored procedure and utilized by reporting services as we have often done is past.
自然,此查询可能会转换为存储过程,并像过去那样经常由报告服务使用。
结论 (Conclusions)
Thus once again we arrive at the end of our “get together”. We have seen how powerful Data Quality Services may be when it comes to ensuring correct aggregation of data. Nowhere is this more important than when we plan to work with SQL Server OLAP cubes.
因此,我们再次到达了“聚在一起”的结尾。 我们已经看到,在确保正确聚合数据方面,数据质量服务有多么强大。 当我们计划使用SQL Server OLAP多维数据集时,这没有什么比这更重要。
Utilizing Data Quality Services is an iterative process until you capture a correct master list PLUS the master list is continually changing. The one point that many people miss is that the Knowledge Base does in fact learn and it often compares its “corrected” values to new incoming data that really does look similar and hence passes the corrected value as a “Suggestion”. It is up to the Data Steward to continually monitor these “Suggested” values and indicate to the system, the action to take going forward.
在捕获正确的主列表之前,使用数据质量服务是一个反复的过程,而且主列表会不断变化。 许多人想念的一件事是,知识库实际上确实在学习,并且经常将其“校正后的”值与实际上看起来很相似的新输入数据进行比较,因此将校正后的值作为“建议”传递。 数据管理者有责任不断监视这些“建议”值并向系统指示要采取的措施。
Finally, whilst the whole process is highly iterative, one does arrive at a point where the system will monitor itself and will require less and less human intervention.
最后,尽管整个过程是高度迭代的,但确实可以达到这样一个程度,系统将对其进行自我监控,并且将需要越来越少的人为干预。
Until the next time. Happy programming!
直到下一次。 编程愉快!
参考资料 (References)
- Introduction to Data Quality Services数据质量服务简介
- DQS Knowledge Bases and DomainsDQS知识库和领域
- Data Quality Projects (DQS)数据质量项目(DQS)
翻译自: https://www.sqlshack.com/use-sql-server-data-quality-services-ensure-correct-aggregation-of-data/
sql数据库查询聚合函数