VTK学习笔记:可视化模型
可视化模型
图形模型的主要作用是用图形描述几何体构成的场景,可视化流水线的主要作用是把几何数据(如立方体的顶点坐标)转换成图形数据和负责构建几何体,VTK 使用数据流的方式把几何体数据转换成图形数据,主要有两个基本类和数据转换相关,它们是vtkDataObject类和vtkProcessObject类。
数据对象表达各种类型的数据,vtkDataObject 可以被看作是一个二进制大块(blob)数据,结构化的数据可以被认为是一个数据集(dataset) (vtkDataSet 类)。
过程对象一般也称为过滤器,按照某种运算法则对数据对象进行处理,对数据对象的数据进行优化,过程对象表现系统中的几何形状,数据对象和过程对象连接在一起形成可视化
流水线(例如,数据流网络),图1-4是一种可视化流程的描述。
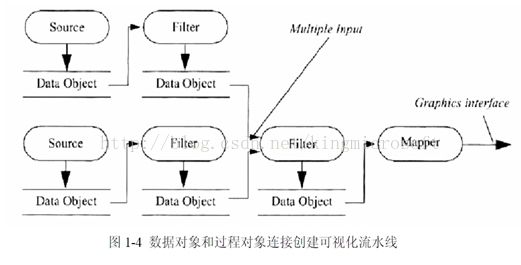
用VTK进行可视化应用是非常方便的,它包括两个基本部分。首先,建立适当的目标图形来演示数据;其次, 建立一个数据流水线(data pipeline)来处理数据, 建立流水线(pipeline)就是将Source、Filters 和Mappers连接起来。VTK的可视化模型主要包括两类对象:
(1)数据对象
(a)多边形数据(vtkPloyData):表示由顶点、直线、多边形即三角面片组成的几何体, 支持多种的原子类型, 如vtkVertex,vtk-PloyVertex, vtkLine 等。
(b)结构点数据(vtkStructurePoint):是一包括表面形状及几何形状的几何体。
(c)非结构点数据(vtkUnStructurePoint):指定了几何体的外观;结构网格( vtkStructureGrid):指定了几何体的结构。
(d)非结构网格(vtkUnStructureGrid):可以为任意的cell 类型的组合。
(e)数据对象继承关系。
(2)过程对象
VTK 中定义的过程对象根据其pipeline主要包括了数据源(Source),过滤器(Filters),映射(Mappers),数据流水线(data pipeline)。
数据源(Source):vtkSource是所有数据源的基类, 其子类定义了许多数据源类型;
过滤器(Filters):vtkFilter是各种Filter的基类, 从vtkSource中派生出来, 接收Source 中的数据, 进行种不同的Filter处理工作。Filters为VTK的主要部件, 由其基类派生出了许多子类, 实现了图形学算法。将其封装起来, 用户只需要编写简单程序接口调用就可, 并可以通过改变 参数来达到想要的效果;
映射(Mappers) :vtkMapper 是所有Mappers 的基类, 从Filtes接受数据,并把其映射为图形库中的基本图元。根据映射方式的不同, 有多个继承子类。
到这里,理解VTK怎么显示图像的,大致的原理介绍的差不多了。
由于本人研究的是图像的三维重建,所以,还是关注点放在数据的处理和分析。像控制相机,控制光源,控制场景中的物体都是控制显示的效果,不涉及到重建的数据处理,所以直接pass了。