从ctr预估问题看看f(x)设计—DNN篇
从ctr预估问题看看f(x)设计—DNN篇

lambdaJi
how to model anything
已关注
吴海波
等 223 人赞了该文章
上接机器学习模型设计五要素,这一篇接着讲模型结构设计
从ctr预估问题看看f(x)设计—LR篇提到ctr预估的f(x)可以分 大规模离散LR,Trees Model,DNN&Embedding,以及Reinforcement-Learing 四个分支,本文着重介绍DNN&Embedding这条分支的演进路线,把DNN引入ctr预估无非看重两点:
#1 改进模型结构,提高“信息利用率”,发现高阶非线性特征,挖掘以前挖不到潜在模式,比如DIN引入attention机制;
一般来说Embedding+MLP是标配。
#2 扩充“信息量”,把图片/文本这类不好处理的数据利用起来,比如DeepCTR;
进一步细分为三条演进路线:
#1串行路线 - embedding如何与deep part融合?
- concatenate: wide&deep/DEF/DCM/DeepFM/etc
- inner/outer product: PNN
- weighted sum: DIN/AFM
- Bi-interaction: NFM/AFM
#2并行路线 - shallow part + deep part,结合Memorization 和Generalization的优势,另外通过shallow part把反馈信号传回embedding层,收敛得更快。
- wide&deep:lr + mlp
- DeepFM:fm + mlp
- deep&cross:polynomial cross network + mlp
#3多模学习 - 数字/文本/图片/语音/视频等多形态数据利用起来
-DeepCTR:数字+图片
#0 RoadMap-搭积木

#1 LR
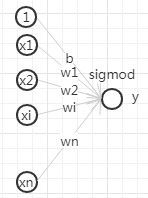
#{x,y}:
#f(x):单层单节点的“DNN”, 宽而不深,深宽大战鄙视链的底端
|--参数量n+1
#loss:logloss/... + L1/L2/...
#optimizer:sgd/...
#evalution:logloss/auc/...
#2 MF
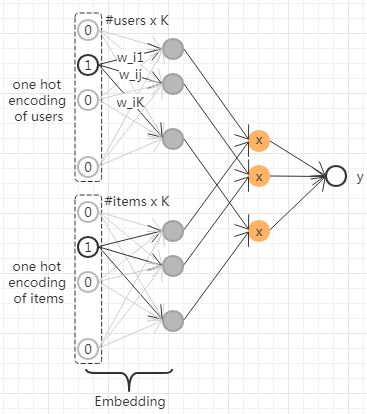
#{x,y}:
#f(x):前半部分实际上就是DL embedding层
|--参数量(#users+#items)xK
#loss:rmse/... + L1/L2/...
#optimizer:sgd/...
#evalution:rmse/...
#3 MLR = Embedding + MF + LR

#{x,y}:
#f(x):Embedding + MF + LR
|--参数量2mn
#loss:logloss + L21 + L1
#optimizer:
#evalution:auc
#4 FM = LR + MF
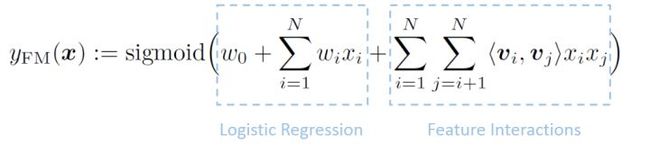
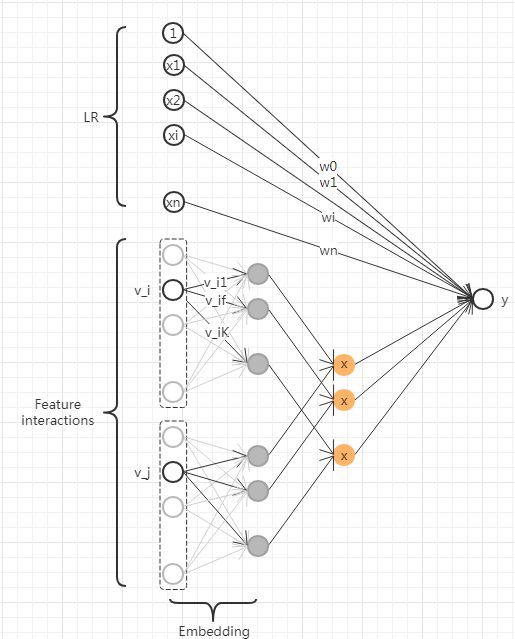
#{x,y}:
#f(x):FM = LR + MFs
|--参数量1+n(lr part) + nk(embedding part)
#loss:logloss/... + L1/L2/...
#optimizer:sgd/...
#evalution:logloss/auc/...
#5 FNN = FM + MLP = LR + MF + MLP

#{x,y}:
#f(x):FNN = FM + MLP, FM的基础上堆叠mlp, FM part pre-training;
|--参数量:1+n + nk(fm part) + (1+f+fk)xH1+H1xH2+H2x1(mlp part)
#loss:logloss + L2
#optimizer:sgd/...
#evalution:logloss/auc/...
#6 PNN = FNN + Product layer
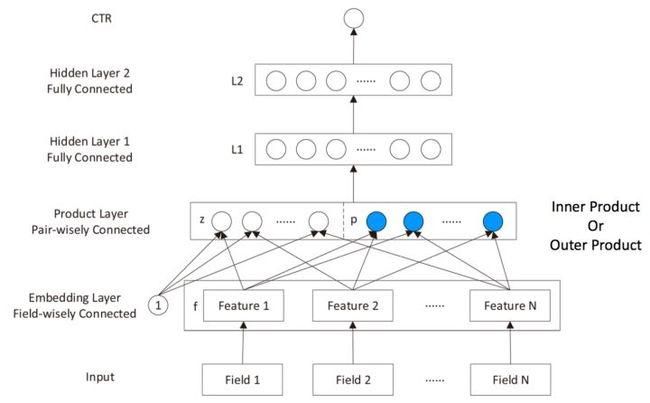
#{x,y}:
#f(x):produc layer learn interactive patterns再送入mlp, addition acts like "OR" gate while multiplication acting like "AND" gate, and the product layer seems to learn rules other than features.
|--inner参数量: 1+n + nk(embedding part) + (fxk+fx(f-1)/2)xH1(product part) + H1xH2+H2x1(mlp part)
|--outer参数量: 1+n + nk(embedding part) + (fxk+fx(f-1)/2xkxk)xH1(product part) + H1xH2+H2x1(mlp part)
#loss:logloss + dropout
#optimizer:gd
#evalution:logloss/auc/rig/rmse
#7 WDL = LR + Embedding + MLP

#{x,y}:
#f(x):LR + Embedding + MLP, embedding part跟MF前半部分一样, mlp part网络参数降到 f x K x #hiddens,
但是加上embedding layer(也需要训练更新), 总参数并没有减少, 相当于把第一个隐含层单独拿出来特殊处理
|--好处:前向支持更多算子(concatenate/inner/outer/...);后向每次迭代模型参数更新量降低了,相当于只更新非0的x
|--embedding layer参数如何更新:把输入层看做one hot encoding激活的那个节点,没画出来的都是0,更新按照链式法则展开即可(w = w- eta*delta*x when x=1)
|--参数量1+n(wide-part) + nxk(embedding part) + fxkxH1+H1xH2+H2x1(mlp part)
#loss:logloss/... + L1/L2/...
#optimizer:wide part用FTRL+L1正则, deep part用的AdaGrad
#evalution:auc
#8 DeepFM = FM + Embedding + MLP
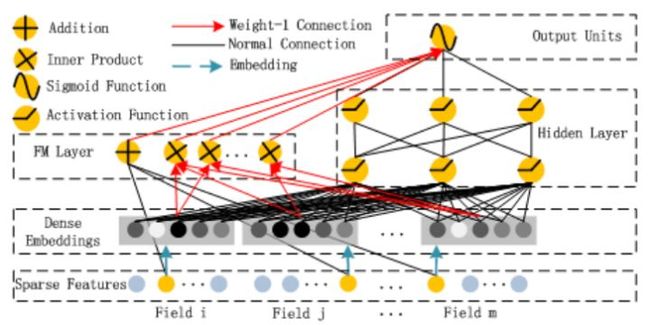
#{x,y}:
#f(x):wide part用FM取代LR, wide & deep part 共享embedding vector
|--参数量:1+n(fm part) + nxk(embedding part) + fxkxH1+H1xH2+H2x1(mlp part)
#loss:logloss/... + L1/L2/...
#optimizer:adam
#evalution:logloss/auc/...
#9 NFM = LR + Embedding + Bi-Interaction Pooling + MLP

#{x,y}:
#f(x):在embedding vector融合上做文章, 用Bi-Interaction pooling replace concatenation or sum/average,把layer参数量由fk -> k
|--参数量:1+n(lr part) + nxk(embedding part) + kxH1+H1xH2+...+Hlx1(mlp part)
#loss:squared loss/logloss/... + L1/L2/...
#optimizer:mini-batch Adagrad + dropout + Batch Normalization
#evalution:rmse
#10 AFM = LR + Embedding + Attention + MLP
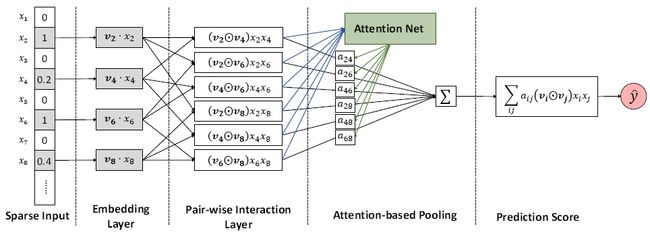
#{x,y}:
#f(x):引入attention net, 给FM中每个interaction一个权重aij
|--参数量:1+n(lr part) + nxk(embedding part) + kxH1+2H1(attention part) + kx1(mlp part)
#loss:squared loss/logloss/... + L1/L2/...
#optimizer:mini-batch Adagrad + dropout + L2
#evalution:rmse
#11 DIN = Embedding + Attention + MLP
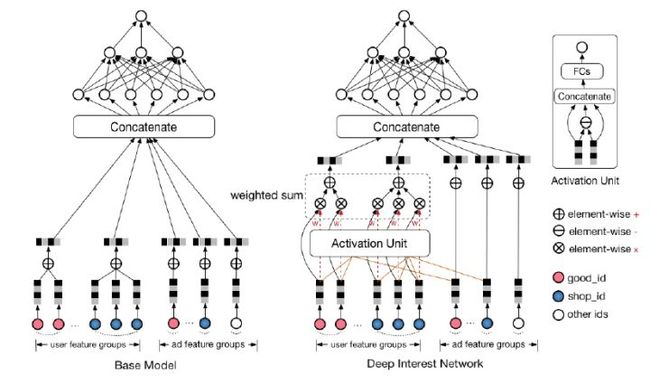
#{x,y}:
#f(x):引入Local Activation假设(用户的兴趣很广泛,用户看到一个商品时只有部分兴趣激活),用attention机制对用户历史行为进行筛选
|--参数量:nxk(embedding part) + 3xh1xh2x..x1(attention part) + fxkxH1+H1xH2+H2x1(mlp part)
#loss:logloss + L2/dropout/adaptive regularization
#optimizer:sgd/...
#evalution:GAUC
#12 DeepCTR = CNN + Embedding + MLP
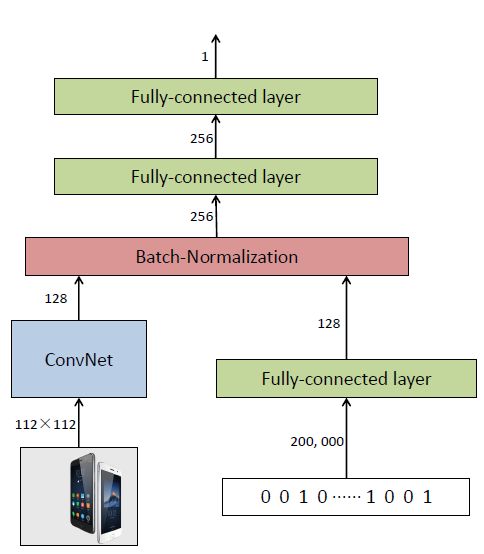
#{x,y}:,ad feature包含图片,扩大数据中的信息量
#f(x):CNN + Embedding + MLP,CNN提取图片信息,embedding提取离散特征信息(K=128,把SFC隐含层看做embedding layer)
|--参数量:?(cnn part) + nxSFC(embedding part) + 256x256+256x1(mlp part)
#loss:logloss + L2
#optimizer:sgd+momentum+weight decay
#evalution:relative auc
#13 Deep Crossing Model = Embedding + ResNet + LR
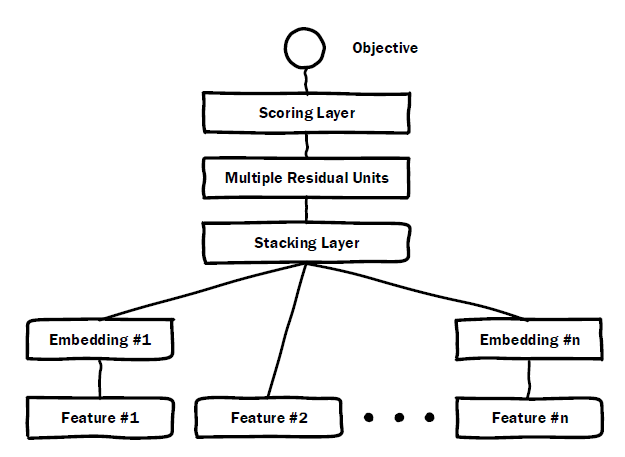
#{x,y}:,ad feature包含key words, title
#f(x):Embedding + ResNet + LR, 用ResNet 代替 mlp
|--参数量:embedding part + resnet part + lr part
#loss:logloss
#optimizer:BMUF in CNTK
#evalution:auc
#14 Deep Embedding Forest = Embedding + Forest

#{x,y}:,ad feature包含key words, title
#f(x):Embedding + Forest, 用forest代替Deep Crossing Model中的resnet+lr part, 可以明显降低在线预测服务时耗
|--参数量:embedding part + forest part
#loss:logloss
#optimizer:BMUF in CNTK + XgBoost/LightGBM
#evalution:logloss + predicting time
参考资料:
[1] Factorization Machines_Rendle2010
[2] LS-PLM:Large Scale Piecewise Linear Model
[3] Deep Learning over Multi-Field Categorical Data: A Case Study on User Response Prediction
[4] Product-based Neural Networks for User Response Prediction
[5] Wide & Deep Learning for Recommender Systems
[6] DeepFM: A Factorization-Machine based Neural Network for CTR Prediction
[7] Deep Interest Network for Click-Through Rate Prediction
[8] 独家 | 阿里盖坤演讲:从人工特征到深度学习,我们为了更准确地预估点击率都做了多少努力 ( 附PPT )
[9] Deep CTR Prediction in Display Advertising
[10] Deep Crossing: Web-Scale Modeling without Manually Crafted Combinatorial Features
[11] Deep Embedding Forest: Forest-based Serving with Deep Embedding Features
[12] Neural Factorization Machines for Sparse Predictive Analytics
[13] Attentional Factorization Machines:Learning theWeight of Feature Interactions via Attention Networks
编辑于 2018-07-25