伯努利分布、二项分布、多项分布、Beta分布、Dirichlet分布
https://blog.csdn.net/michael_r_chang/article/details/39188321
https://www.cnblogs.com/wybang/p/3206719.html
https://blog.csdn.net/jteng/article/details/60334628
1. 伯努利分布
伯努利分布(Bernoulli distribution)又名两点分布或0-1分布,介绍伯努利分布前首先需要引入伯努利试验(Bernoulli trial)。
- 伯努利试验是只有两种可能结果的单次随机试验,即对于一个随机变量X而言:
伯努利试验都可以表达为“是或否”的问题。例如,抛一次硬币是正面向上吗?刚出生的小孩是个女孩吗?等等
- 如果试验E是一个伯努利试验,将E独立重复地进行n次,则称这一串重复的独立试验为n重伯努利试验。
- 进行一次伯努利试验,成功(X=1)概率为p(0<=p<=1),失败(X=0)概率为1-p,则称随机变量X服从伯努利分布。伯努利分布是离散型概率分布,其概率质量函数为:
2. 二项分布
二项分布(Binomial distribution)是n重伯努利试验成功次数的离散概率分布。
- 如果试验E是一个n重伯努利试验,每次伯努利试验的成功概率为p,X代表成功的次数,则X的概率分布是二项分布,记为X~B(n,p),其概率质量函数为
显然,
- 从定义可以看出,伯努利分布是二项分布在n=1时的特例
- 二项分布名称的由来,是由于其概率质量函数中使用了二项系数,该系数是二项式定理中的系数,二项式定理由牛顿提出:
- 二项分布的典型例子是扔硬币,硬币正面朝上概率为p, 重复扔n次硬币,k次为正面的概率即为一个二项分布概率。
3. 多项分布
多项式分布(Multinomial Distribution)是二项式分布的推广。二项式做n次伯努利实验,规定了每次试验的结果只有两个,如果现在还是做n次试验,只不过每次试验的结果可以有多m个,且m个结果发生的概率互斥且和为1,则发生其中一个结果X次的概率就是多项式分布。
- 扔骰子是典型的多项式分布。扔骰子,不同于扔硬币,骰子有6个面对应6个不同的点数,这样单次每个点数朝上的概率都是1/6(对应p1~p6,它们的值不一定都是1/6,只要和为1且互斥即可,比如一个形状不规则的骰子),重复扔n次,如果问有k次都是点数6朝上的概率就是
多项式分布一般的概率质量函数为:
4. 贝塔分布
在介绍贝塔分布(Beta distribution)之前,需要先明确一下先验概率、后验概率、似然函数以及共轭分布的概念。
- 通俗的讲,先验概率就是事情尚未发生前,我们对该事发生概率的估计。利用过去历史资料计算得到的先验概率,称为客观先验概率; 当历史资料无从取得或资料不完全时,凭人们的主观经验来判断而得到的先验概率,称为主观先验概率。例如抛一枚硬币头向上的概率为0.5,这就是主观先验概率。
- 后验概率是指通过调查或其它方式获取新的附加信息,利用贝叶斯公式对先验概率进行修正,而后得到的概率。
- 先验概率和后验概率的区别:先验概率不是根据有关自然状态的全部资料测定的,而只是利用现有的材料(主要是历史资料)计算的;后验概率使用了有关自然状态更加全面的资料,既有先验概率资料,也有补充资料。另外一种表述:先验概率是在缺乏某个事实的情况下描述一个变量;而后验概率(Probability of outcomes of an experiment after it has been performed and a certain event has occured.)是在考虑了一个事实之后的条件概率。
- 似然函数
- 共轭分布(conjugacy):后验概率分布函数与先验概率分布函数具有相同形式
好了,有了以上先验知识后,终于可以引入贝塔分布啦!!首先,考虑一点,在试验数据比较少的情况下,直接用最大似然法估计二项分布的参数可能会出现过拟合的现象(比如,扔硬币三次都是正面,那么最大似然法预测以后的所有抛硬币结果都是正面)。为了避免这种情况的发生,可以考虑引入先验概率分布来控制参数,防止出现过拟合现象。那么,问题现在转为如何选择!
先验概率和后验概率的关系为:
二项分布的似然函数为(就是二项分布除归一化参数之外的后面那部分,似然函数之所以不是pdf,是因为它不需要归一化):
如果选择的先验概率也与和次方德乘积的关系,那么后验概率分布的函数形式就会跟它的先验函数形式一样了。具体来说,选择prior的形式是,那么posterior就会变成这个样子了(为pdf的归一化参数),所以posterior和prior具有相同的函数形式(都是也与和次方的乘积),这样先验概率与后验概率就是共轭分布了。
所以,我们选择了贝塔分布作为先验概率,其概率分布函数为:
,其中
5. 狄利克雷分布
狄利克雷分布(Dirichlet distribution)是多项分布的共轭分布,也就是它与多项分布具有相同形式的分布函数。
- 概率分布函数为:
6. 后记
本篇博文只是将伯努利分布、二项分布、多项分布、贝塔分布和狄利克雷分布做了简单的介绍,其中涉及到大量的概率基础和高等数学的知识,文中的介绍只是粗浅的把这些分布的概念作了大概介绍,没有对这些分布的产生历史做介绍。我想,更好的介绍方式,应是从数学史的角度,将这几项分布的发现按照历史规律来展现,这样会更直观、形象。后续再补吧!
在机器学习领域中,概率模型是一个常用的利器。用它来对问题进行建模,有几点好处:1)当给定参数分布的假设空间后,可以通过很严格的数学推导,得到模型的似然分布,这样模型可以有很好的概率解释;2)可以利用现有的EM算法或者Variational method来学习。通常为了方便推导参数的后验分布,会假设参数的先验分布是似然的某个共轭分布,这样后验分布和先验分布具有相同的形式,这对于建模过程中的数学推导可以大大的简化,保证最后的形式是tractable。
在概率模型中,Dirichlet这个词出现的频率非常的高。初始机器学习的同学或者说得再广一些,在学习概率模型的时候,很多同学都不清楚为啥一个表现形式如此奇怪的分布Dirichlet分布会出现在我们的教科书中,它是靠啥关系攀上了多项分布(Multinomial distribution)这个亲戚的,以至于它可以“堂而皇之”地扼杀我大天朝这么多数学家和科学家梦想的?为了引出背后这层关系,我们需要先介绍一个概念——共轭先验(Conjugate Prior)。
- Conjugate Prior: In Bayesian probability theory, if the posterior distributions p(θ|x) are in the same family as the prior probability distribution p(θ), the prior and posterior are then called conjugate distributions, and the prior is called a conjugate prior for the likelihood. ----from wiki
- 用中文来讲,在贝叶斯统计理论中,如果某个随机变量Θ的后验概率 p(θ|x)和气先验概率p(θ)属于同一个分布簇的,那么称p(θ|x)和p(θ)为共轭分布,同时,也称p(θ)为似然函数p(x|θ)的共轭先验。
介绍了这个重要的概念之后,我们回到文章的正题。首先需要弄清楚什么是二项分布(Binomial distribution)。这个概念是从伯努利分布推进的。伯努利分布是一个离散型的随机分布,其中的随机变量只有两类取值,非正即负{+,-}。二项分布即重复n次的伯努利试验,记为 X~b(n,p)。概率密度函数(概率质量函数)为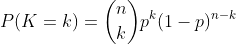 。再来看看Beta分布,给定参数
。再来看看Beta分布,给定参数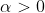 和
和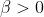 ,取值范围为[0,1]的随机变量x的概率密度函数
,取值范围为[0,1]的随机变量x的概率密度函数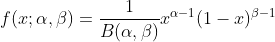 ,其中
,其中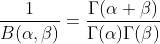 ,
,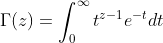 。这里假定,先验分布和似然概率如下所示:
。这里假定,先验分布和似然概率如下所示:
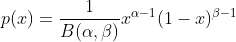
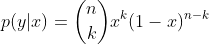
那么很容易知道后验概率为
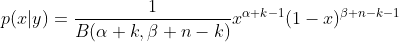
弄清楚了Beta分布和二项分布之间的关系后,对于接下来的Dirichlet 分布和多项分布(Multinomial distribution)的关系理解将会有非常大的帮助。多项分布,从字面上所表现出的含义,我们也大抵知道它的意思。它本身确实也是这样的,其单次试验中的随机变量的取值不再是0-1的,而是有多种离散值可能(1,2,3...,k),其中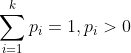 。多项分布的概率密度函数为
。多项分布的概率密度函数为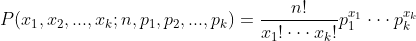 。而Dirichlet分布的的密度函数形式也如出一辙:
。而Dirichlet分布的的密度函数形式也如出一辙: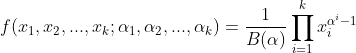 ,其中
,其中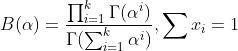 。到这里,我们可以看到Beta分布和Dirichlet 分布有多相似啊,二项分布和多项分布有多相似啊!
。到这里,我们可以看到Beta分布和Dirichlet 分布有多相似啊,二项分布和多项分布有多相似啊!
再一次来看看共轭。假设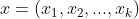 有先验分布
有先验分布
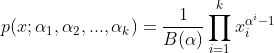
,
另有似然函数
则后验概率
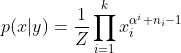
,和Dirichlet 分布形式一致。
其实,细心的读者已经发现,这里这四类分布,如果但从数学形式上看,它们的组织形式都是一致的,都是通过乘积的形式构成,加上先验分布、似然函数和后言分布之间的乘积推导关系,可以很容易发现,它们所表现出的共轭性质很容易理解。
Beta分布与Dirichlet分布的定义域均为[0,1],在实际使用中,通常将两者作为概率的分布,Beta分布描述的是单变量分布,Dirichlet分布描述的是多变量分布,因此,Beta分布可作为二项分布的先验概率,Dirichlet分布可作为多项分布的先验概率。这两个分布都用到了Gamma函数,所以,首先了解一下Gamma函数。
1. Gamma函数
首先看其表达式
Γ(x)=∫∞0tx−1e−tdtΓ(x)=∫0∞tx−1e−tdt
这样的表达看懂都很难,更不知道那些数学家怎么想出来的。据LDA数学八卦中记录,在Gamma函数的发现中做出主要贡献的数学家有哥德巴赫、丹尼尔·伯努利(不是伯努利分布的那个伯努利),最终由欧拉解决这个问题(这些大数学家互相都认识的啊)。
Gamma函数是对阶乘在实数领域的扩展,也就是说,Γ(x+1)=xΓ(x)Γ(x+1)=xΓ(x),下面用分部积分的方法进行推导,如不关心,可以略过。
据PRML第71页(2.14)式,Gamma函数在Beta分布和Dirichlet分布中起到了归一化的作用。
2. Beta分布
Beta分布描述的是定义在区间[0,1]上随机变量的概率分布,由两个参数α>0α>0和β>0β>0决定,通常记为μ∼Beta(μ|α,β)μ∼Beta(μ|α,β),其概率密度函数如下
P(μ|α,β)=Γ(α+β)Γ(α)Γ(β)μα−1(1−μ)β−1=1B(α,β)μα−1(1−μ)β−1P(μ|α,β)=Γ(α+β)Γ(α)Γ(β)μα−1(1−μ)β−1=1B(α,β)μα−1(1−μ)β−1
其中,Γ(⋅)Γ(⋅)就是Gamma函数,B(α,β)B(α,β)为Beta函数,并且
B(α,β)=Γ(α)Γ(β)Γ(α+β)B(α,β)=Γ(α)Γ(β)Γ(α+β)
Beta分布的概率密度函数曲线如下图:(摘自wikipedia Beta distribution)
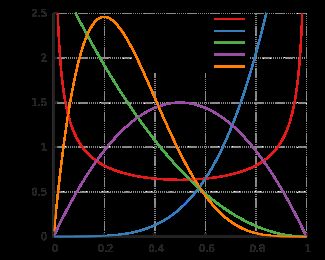
由于Beta分布定义在区间[0,1]上,所以适合作为概率的分布。第一段提到Beta分布可作为二项分布的先验概率,那就需要从二项分布的定义来理解Beta分布的形式。已知二项分布的形式为:
p(x=k|n,μ)=Cknμk(1−μ)n−kp(x=k|n,μ)=Cnkμk(1−μ)n−k
对 μμ 进行后验概率估计时,其似然项是 μμ 和 (1−μ)(1−μ) 的指数形式,如果先验概率也选择为 μμ 和 (1−μ)(1−μ) 的指数形式,那么后验概率就仍然保持这种指数形式,这种性质叫做共轭分布,我们会在后面的文章中对共轭分布进行介绍。
因此,Beta分布就是 μμ 和 (1−μ)(1−μ) 的指数形式,其中Beta函数为归一化系数。Beta分布的均值和方差分别为
E[μ]=αα+βE[μ]=αα+β
var(μ)=αβ(α+β)2(α+β+1)var(μ)=αβ(α+β)2(α+β+1)
3. Dirichlet分布
Dirichlet分布是关于定义在区间[0,1]上的多个随机变量的联合概率分布,假设有dd个变量μiμi,并且∑di=1μi=1∑i=1dμi=1,记μ=(μ1,μ2,...,μd)μ=(μ1,μ2,...,μd),每个μiμi对应一个参数αi>0αi>0,记α=(α1,α2,...,αd)α=(α1,α2,...,αd),α^=∑di=1αiα^=∑i=1dαi,那么它的概率密度函数为
p(μ|α)=Dir(μ|α)=Γ(α^)Γ(α1)⋯Γ(αd)∏di=1μαi−1ip(μ|α)=Dir(μ|α)=Γ(α^)Γ(α1)⋯Γ(αd)∏i=1dμiαi−1
Dirichlet分布的每一个随机变量具有统计量如下:
E[μi]=αiα^E[μi]=αiα^
var(μi)=αi(α^−αi)α^2(α^+1)var(μi)=αi(α^−αi)α^2(α^+1)
cov(μi,μj)=αiαjα^2(α^+1)cov(μi,μj)=αiαjα^2(α^+1)
由于Dirichlet分布描述的是多个定义于区间[0,1]的随机变量的概率分布,所以通常将其用作多项分布参数μiμi的概率分布。