【扯皮系列】一篇与众不同的 String、StringBuilder 和 StringBuffer 详解
碎碎念
这是一道老生常谈的问题了,字符串是不仅是 Java 中非常重要的一个对象,它在其他语言中也存在。比如 C++、Visual Basic、C# 等。字符串使用 String 来表示,字符串一旦被创建出来就不会被修改,当你想修改 StringBuffer 或者是 StringBuilder,出于效率的考量,虽然 String 可以通过 + 来创建多个对象达到字符串拼接的效果,但是这种拼接的效率相比 StringBuffer 和 StringBuilder,那就是心有余而力不足了。本篇文章我们一起来深入了解一下这三个对象。
简单认识这三个对象
String
String 表示的就是 Java 中的字符串,我们日常开发用到的使用 "" 双引号包围的数都是字符串的实例。String 类其实是通过 char 数组来保存字符串的。下面是一个典型的字符串的声明
String s = "abc";
上面你创建了一个名为 abc 的字符串。
字符串是恒定的,一旦创建出来就不会被修改,怎么理解这句话?我们可以看下 String 源码的声明

告诉我你看到了什么?String 对象是由final 修饰的,一旦使用 final 修饰的类不能被继承、方法不能被重写、属性不能被修改。而且 String 不只只有类是 final 的,它其中的方法也是由 final 修饰的,换句话说,Sring 类就是一个典型的 Immutable 类。也由于 String 的不可变性,类似字符串拼接、字符串截取等操作都会产生新的 Strign 对象。
所以请你告诉我下面
String s1 = "aaa";
String s2 = "bbb" + "ccc";
String s3 = s1 + "bbb";
String s4 = new String("aaa");
分别创建了几个对象?

- 首先第一个问题,s1 创建了几个对象。字符串在创建对象时,会在常量池中看有没有 aaa 这个字符串;如果没有此时还会在常量池中创建一个;如果有则不创建。我们默认是没有的情况,所以会创建一个对象。下同。
- 那么 s2 创建了几个对象呢?是两个对象还是一个对象?我们可以使用
javap -c看一下反汇编代码
public class com.sendmessage.api.StringDemo {
public com.sendmessage.api.StringDemo();
Code:
0: aload_0
1: invokespecial #1 // 执行对象的初始化方法
4: return
public static void main(java.lang.String[]);
Code:
0: ldc #2 // 将 String aaa 执行入栈操作
2: astore_1 # pop出栈引用值,将其(引用)赋值给局部变量表中的变量 s1
3: ldc #3 // String bbbccc
5: astore_2
6: return
}
编译器做了优化 String s2 = "bbb" + "ccc" 会直接被优化为 bbbccc。也就是直接创建了一个 bbbccc 对象。
javap 是 jdk 自带的
反汇编工具。它的作用就是根据 class 字节码文件,反汇编出当前类对应的 code 区(汇编指令)、本地变量表、异常表和代码行偏移量映射表、常量池等等信息。javap -c 就是对代码进行反汇编操作。
- 下面来看 s3,s3 创建了几个对象呢?是一个还是两个?还是有其他选项?我们使用 javap -c 来看一下

我们可以看到,s3 执行 + 操作会创建一个 StringBuilder 对象然后执行初始化。执行 + 号相当于是执行 new StringBuilder.append() 操作。所以
String s3 = s1 + "bbb";
==
String s3 = new StringBuilder().append(s1).append("bbb").toString();
// Stringbuilder.toString() 方法也会创建一个 String
public String toString() {
// Create a copy, don't share the array
return new String(value, 0, count);
}
所以 s3 执行完成后,相当于创建了 3 个对象。
- 下面来看 s4 创建了几个对象,在创建这个对象时因为使用了 new 关键字,所以肯定会在堆中创建一个对象。然后会在常量池中看有没有 aaa 这个字符串;如果没有此时还会在常量池中创建一个;如果有则不创建。所以可能是创建一个或者两个对象,但是一定存在两个对象。

说完了 String 对象,我们再来说一下 StringBuilder 和 StringBuffer 对象。
上面的 String 对象竟然和 StringBuilder 产生了千丝万缕的联系。不得不说 StringBuilder 是一个牛逼的对象。String 对象底层是使用了 StringBuilder 对象的 append 方法进行字符串拼接的,不由得对 StringBuilder 心生敬意。

不由得我们想要真正认识一下这个 StringBuilder 大佬,但是在认识大佬前,还有一个大 boss 就是 StringBuffer 对象,这也是你不得不跨越的鸿沟。

StringBuffer
StringBuffer 对象 代表一个可变的字符串序列,当一个 StringBuffer 被创建以后,通过 StringBuffer 的一系列方法可以实现字符串的拼接、截取等操作。一旦通过 StringBuffer 生成了最终想要的字符串后,就可以调用其 toString 方法来生成一个新的字符串。例如
StringBuffer b = new StringBuffer("111");
b.append("222");
System.out.println(b);
我们上面提到 + 操作符连接两个字符串,会自动执行 toString() 方法。那你猜 StringBuffer.append 方法会自动调用吗?直接看一下反汇编代码不就完了么?
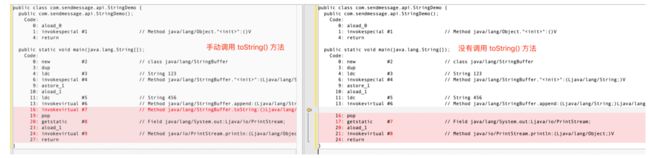
上图左边是手动调用 toString 方法的代码,右图是没有调用 toString 方法的代码,可以看到,toString() 方法不像 + 一样自动被调用。
StringBuffer 是线程安全的,我们可以通过它的源码可以看出
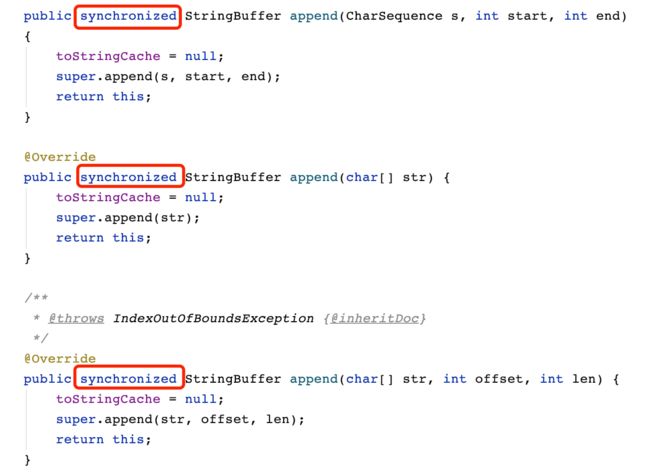
StringBuffer 在字符串拼接上面直接使用 synchronized 关键字加锁,从而保证了线程安全性。
StringBuilder
最后来认识大佬了,StringBuilder 其实是和 StringBuffer 几乎一样,只不过 StringBuilder 是非线程安全的。并且,为什么 + 号操作符使用 StringBuilder 作为拼接条件而不是使用 StringBuffer 呢?我猜测原因是加锁是一个比较耗时的操作,而加锁会影响性能,所以 String 底层使用 StringBuilder 作为字符串拼接。

深入理解 String、StringBuilder、StringBuffer
我们上面说到,使用 + 连接符时,JVM 会隐式创建 StringBuilder 对象,这种方式在大部分情况下并不会造成效率的损失,不过在进行大量循环拼接字符串时则需要注意。如下这段代码
String s = "aaaa";
for (int i = 0; i < 100000; i++) {
s += "bbb";
}
这是一段很普通的代码,只不过对字符串 s 进行了 + 操作,我们通过反编译代码来看一下。
// 经过反编译后
String s = "aaa";
for(int i = 0; i < 10000; i++) {
s = (new StringBuilder()).append(s).append("bbb").toString();
}
你能看出来需要注意的地方了吗?在每次进行循环时,都会创建一个 StringBuilder 对象,每次都会把一个新的字符串元素 bbb 拼接到 aaa 的后面,所以,执行几次后的结果如下

每次都会创建一个 StringBuilder ,并把引用赋给 StringBuilder 对象,因此每个 StringBuilder 对象都是强引用, 这样在创建完毕后,内存中就会多了很多 StringBuilder 的无用对象。了解更多关于引用的知识,请看
https://mp.weixin.qq.com/s/ZflBpn2TBzTNv_-G-zZxNg
这样由于大量 StringBuilder 创建在堆内存中,肯定会造成效率的损失,所以在这种情况下建议在循环体外创建一个 StringBuilder 对象调用 append()方法手动拼接。
例如
StringBuilder builder = new StringBuilder("aaa");
for (int i = 0; i < 10000; i++) {
builder.append("bbb");
}
builder.toString();
这段代码中,只会创建一个 builder 对象,每次循环都会使用这个 builder 对象进行拼接,因此提高了拼接效率。
从设计角度理解
我们前面说过,String 类是典型的 Immutable 不可变类实现,保证了线程安全性,所有对 String 字符串的修改都会构造出一个新的 String 对象,由于 String 的不可变性,不可变对象在拷贝时不需要额外的复制数据。
String 在 JDK1.6 之后提供了 intern() 方法,intern 方法是一个 native 方法,它底层由 C/C++ 实现,intern 方法的目的就是为了把字符串缓存起来,在 JDK1.6 中却不推荐使用 intern 方法,因为 JDK1.6 把方法区放到了永久代(Java 堆的一部分),永久代的空间是有限的,除了 Fullgc 外,其他收集并不会释放永久代的存储空间。JDK1.7 将字符串常量池移到了堆内存 中,
下面我们来看一段代码,来认识一下 intern 方法
public static void main(String[] args) {
String a = new String("ab");
String b = new String("ab");
String c = "ab";
String d = "a";
String e = new String("b");
String f = d + e;
System.out.println(a.intern() == b);
System.out.println(a.intern() == b.intern());
System.out.println(a.intern() == c);
System.out.println(a.intern() == f);
}
上述的执行结果是什么呢?我们先把答案贴出来,以防心急的同学想急于看到结果,他们的答案是
false
true
true
false
和你预想的一样吗?为什么会这样呢?我们先来看一下 intern 方法的官方解释

这里你需要知道 JVM 的内存模型
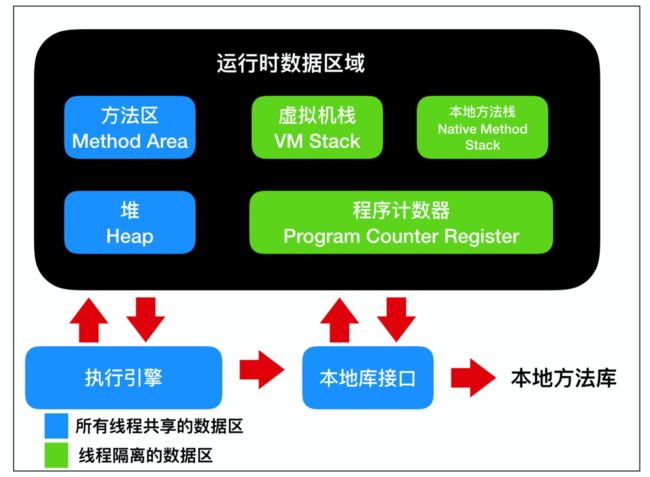
虚拟机栈: Java 虚拟机栈是线程私有的数据区,Java 虚拟机栈的生命周期与线程相同,虚拟机栈也是局部变量的存储位置。方法在执行过程中,会在虚拟机栈种创建一个栈帧(stack frame)。本地方法栈: 本地方法栈也是线程私有的数据区,本地方法栈存储的区域主要是 Java 中使用native关键字修饰的方法所存储的区域程序计数器:程序计数器也是线程私有的数据区,这部分区域用于存储线程的指令地址,用于判断线程的分支、循环、跳转、异常、线程切换和恢复等功能,这些都通过程序计数器来完成。方法区:方法区是各个线程共享的内存区域,它用于存储虚拟机加载的 类信息、常量、静态变量、即时编译器编译后的代码等数据。堆: 堆是线程共享的数据区,堆是 JVM 中最大的一块存储区域,所有的对象实例都会分配在堆上运行时常量池:运行时常量池又被称为Runtime Constant Pool,这块区域是方法区的一部分,它的名字非常有意思,它并不要求常量一定只有在编译期才能产生,也就是并非编译期间将常量放在常量池中,运行期间也可以将新的常量放入常量池中,String 的 intern 方法就是一个典型的例子。
在 JDK 1.6 及之前的版本中,常量池是分配在方法区中永久代(Parmanent Generation)内的,而永久代和 Java 堆是两个完全分开的区域。如果字符串常量池中已经包含一个等于此 String 对象的字符串,则返回常量池中这个字符串的 String 对象;否则,将此 String 对象包含的字符串添加到常量池中,并且返回此 String 对象的引用。
一些人把方法区称为永久代,这种说法不准确,仅仅是 Hotspot 虚拟机设计团队选择使用永久代来实现方法区而已。
从JDK 1.7开始去永久代,字符串常量池已经被转移至 Java 堆中,开发人员也对 intern 方法做了一些修改。因为字符串常量池和 new 的对象都存于 Java 堆中,为了优化性能和减少内存开销,当调用 intern 方法时,如果常量池中已经存在该字符串,则返回池中字符串;否则直接存储堆中的引用,也就是字符串常量池中存储的是指向堆里的对象。
所以我们对上面的结论进行分析
String a = new String("ab");
String b = new String("ab");
System.out.println(a.intern() == b);
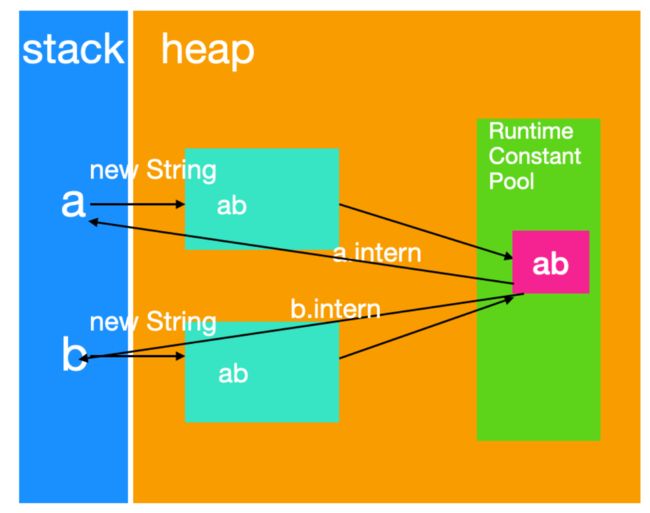
输出什么? false,为什么呢?画一张图你就明白了(图画的有些问题,栈应该是后入先出,所以 b 应该在 a 上面,不过不影响效果)
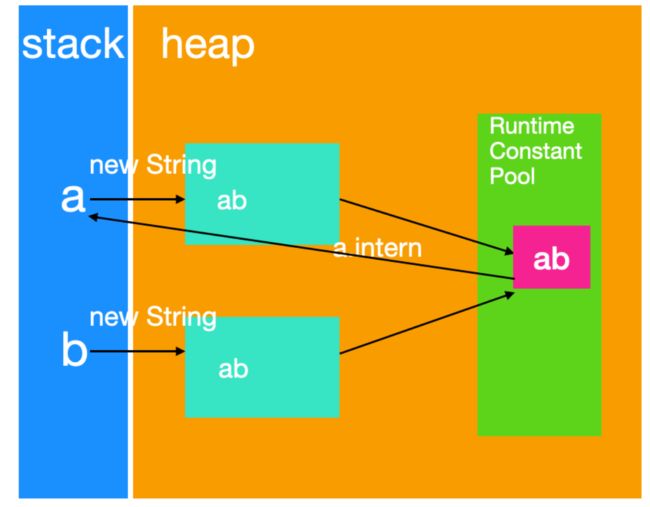
a.intern 返回的是常量池中的 ab,而 b 是直接返回的是堆中的 ab。地址不一样,肯定输出 false
所以第二个
System.out.println(a.intern() == b.intern());
也就没问题了吧,它们都返回的是字符串常量池中的 ab,地址相同,所以输出 true
然后来看第三个
System.out.println(a.intern() == c);
图示如下
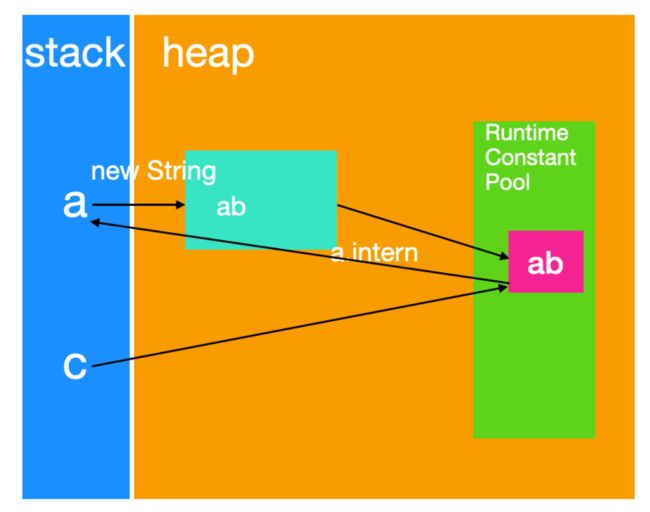
a 不会变,因为常量池中已经有了 ab ,所以 c 不会再创建一个 ab 字符串,这是编译器做的优化,为了提高效率。
下面来看最后一个
System.out.println(a.intern() == f);
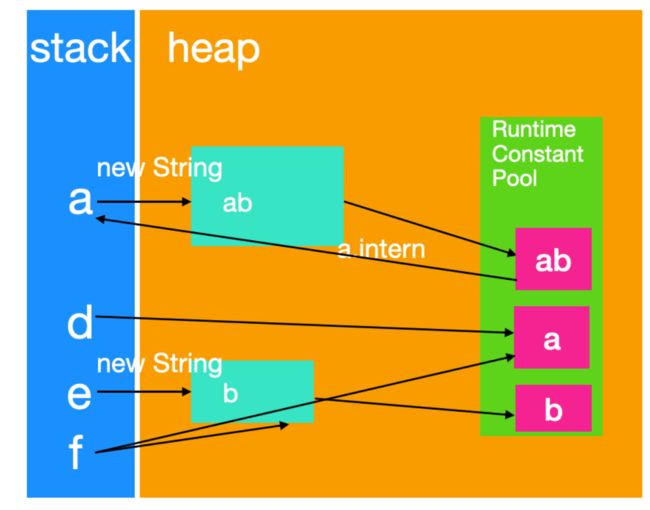
String
首先来看一下 String 类在继承树的什么位置、实现了什么接口、父类是谁,这是源码分析的几大重要因素。
String 没有继承任何接口,不过实现了三个接口,分别是 **Serializable、Comparable、CharSequence **接口
- Serializable :这个序列化接口没有任何方法和域,仅用于标识序列化的语意。
- Comparable:实现了 Comparable 的接口可用于内部比较两个对象的大小
- CharSequence:字符串序列接口,CharSequence 是一个可读的 char 值序列,提供了 length(), charAt(int index), subSequence(int start, int end) 等接口,StringBuilder 和 StringBuffer 也继承了这个接口
重要属性
字符串是什么,字!符!串! 你品,你细品。你会发现它就是一连串字符组成的串。
也就是说
String str = "abc";
// ===
char data[] = {'a', 'b', 'c'};
String str = new String(data);
原来这么回事啊!

所以,String 中有一个用于存储字符的 char 数组 value[],这个数组存储了每个字符。另外一个就是 hash 属性,它用于缓存字符串的哈希码。因为 String 经常被用于比较,比如在 HashMap 中。如果每次进行比较都重新计算其 hashcode 的值的话,那无疑是比较麻烦的,而保存一个 hashcode 的缓存无疑能优化这样的操作。

String 可以通过许多途径创建,也可以根据 Stringbuffer 和 StringBuilder 进行创建。

毕竟我们本篇文章探讨的不是源码分析的文章,所以涉及到的源码不会很多。
除此之外,String 还提供了一些其他方法
-
charAt:返回指定位置上字符的值 -
getChars: 复制 String 中的字符到指定的数组 -
equals: 用于判断 String 对象的值是否相等 -
indexOf: 用于检索字符串 -
substring: 对字符串进行截取 -
concat: 用于字符串拼接,效率高于 + -
replace:用于字符串替换 -
match:正则表达式的字符串匹配 -
contains: 是否包含指定字符序列 -
split: 字符串分割 -
join: 字符串拼接 -
trim: 去掉多余空格 -
toCharArray: 把 String 对象转换为字符数组 -
valueOf: 把对象转换为字符串
StringBuilder
StringBuilder 类表示一个可变的字符序列,我们知道,StringBuilder 是非线程安全的容器,一般适用于单线程场景中的字符串拼接操作,下面我们就来从源码角度看一下 StringBuilder
首先我们来看一下 StringBuilder 的定义
public final class StringBuilder
extends AbstractStringBuilder
implements java.io.Serializable, CharSequence {...}
StringBuilder 被 final 修饰,表示 StringBuilder 是不可被继承的,StringBuilder 类继承于 AbstractStringBuilder类。实际上,AbstractStringBuilder 类具体实现了可变字符序列的一系列操作,比如:append()、insert()、delete()、replace()、charAt() 方法等。
StringBuilder 实现了 2 个接口
- Serializable 序列化接口,表示对象可以被序列化。
- CharSequence 字符序列接口,提供了几个对字符序列进行只读访问的方法,例如 ength()、charAt()、subSequence()、toString() 方法等。
StringBuilder 使用 AbstractStringBuilder 类中的两个变量作为元素
char[] value; // 存储字符数组
int count; // 字符串使用的计数
StringBuffer
StringBuffer 也是继承于 AbstractStringBuilder ,使用 value 和 count 分别表示存储的字符数组和字符串使用的计数,StringBuffer 与 StringBuilder 最大的区别就是 StringBuffer 可以在多线程场景下使用,StringBuffer 内部有大部分方法都加了 synchronized 锁。在单线程场景下效率比较低,因为有锁的开销。
StringBuilder 和 StringBuffer 的扩容问题
我相信这个问题很多同学都没有注意到吧,其实 StringBuilder 和 StringBuffer 存在扩容问题,先从 StringBuilder 开始看起
首先先注意一下 StringBuilder 的初始容量
public StringBuilder() {
super(16);
}
StringBuilder 的初始容量是 16,当然也可以指定 StringBuilder 的初始容量。
在调用 append 拼接字符串,会调用 AbstractStringBuilder 中的 append 方法
public AbstractStringBuilder append(String str) {
if (str == null)
return appendNull();
int len = str.length();
ensureCapacityInternal(count + len);
str.getChars(0, len, value, count);
count += len;
return this;
}
上面代码中有一个 ensureCapacityInternal 方法,这个就是扩容方法,我们跟进去看一下
private void ensureCapacityInternal(int minimumCapacity) {
// overflow-conscious code
if (minimumCapacity - value.length > 0) {
value = Arrays.copyOf(value,
newCapacity(minimumCapacity));
}
}
这个方法会进行判断,minimumCapacity 就是字符长度 + 要拼接的字符串长度,如果拼接后的字符串要比当前字符长度大的话,会进行数据的复制,真正扩容的方法是在 newCapacity 中
private int newCapacity(int minCapacity) {
// overflow-conscious code
int newCapacity = (value.length << 1) + 2;
if (newCapacity - minCapacity < 0) {
newCapacity = minCapacity;
}
return (newCapacity <= 0 || MAX_ARRAY_SIZE - newCapacity < 0)
? hugeCapacity(minCapacity)
: newCapacity;
}
扩容后的字符串长度会是原字符串长度增加一倍 + 2,如果扩容后的长度还比拼接后的字符串长度小的话,那就直接扩容到它需要的长度 newCapacity = minCapacity,然后再进行数组的拷贝。
总结
本篇文章主要描述了 String 、StringBuilder 和 StringBuffer 的主要特性,String、StringBuilder 和 StringBuffer 的底层构造是怎样的,以及 String 常量池的优化、StringBuilder 和 StringBuffer 的扩容特性等。
如果有错误的地方,还请大佬们提出宝贵意见。