算法训练:嘘,别人我不告诉他
算法训练:嘘,别人我不告诉他
- 算法 or 游戏
- 基础的设计能力:不知道如何下手怎么办?
- 基础的建模能力:数组、链表,以及改进的结构
- 解题技巧:也说不清楚,就是对这道题有 feel 呀!
- 攻略:新手、老手和大神之间的差异。
- 模型:一题多解怎么来?
- 应用:如何把问题与某个抽象的模型相连?
- 总结
- 第一级【编好程序】
- 第二级【储备模型】
- 第三级【解决问题】
- 第四级【建模能力】
- 第五级【优化模型】
算法 or 游戏
编程、数学是十分适合自学的,因为一道题对不对,您可以立马得到答案。
哪怕您很喜欢编程,也会如我一样在这条路上遇到无数问题:
- 对一个题目,苦思冥想好几天;
- 看到大佬的博客、代码,不仅思路清晰,功能实现出来了,代码还很简洁、高效,突然有点沮丧、失意;
- …
这些问题,我们都会遇到,但我们也会一直学习,也许我们都不是很有毅力。
-
一个题目一直想,吃饭想、走路想、有时做梦也会梦到,最后解决了您可以想一想那感觉多爽;
-
其实您看懂了一篇博客或一段代码,不就向大佬迈进了一步么,有好的教程在这里,您应该特别兴奋才对呀。失意了就想一想自己成功时的体验,您能找到那种感觉的;
-
如果下定决心想超越大佬,不完全是比大佬更努力,因为这只是低层面的竞争,而是首先在见识和格局上要比大佬高,气度要更大。学习不是努力读更多的书,盲目追求阅读的速度和数量,这会让人产生低层次的勤奋和成长的感觉,这只是在使蛮力。要思辨,要践行,要总结和归纳,否则,只是在机械地重复某件事,而不会有质的成长的。
我们再不断的演化,我相信人也是可以不断成长的,所以专注于不断训练和发展自己。
而编程是工科,在于实现的细节。真正的功夫都在自己的练习之中,信心和水平只能在每一次成功解题和程序成功运行中提高。
那这种训练模式,是快乐,还是痛苦呢?
真是先苦后甜,一场激情不断的游戏。
TA是一款解谜、策略类游戏,您需要先熟悉TA的各种设定、各种道具、各种技能,最后去解决一个问题。
-
各种道具:所有结构的地基(数组、链表、改进的结构),一对一结构(栈、队列、哈希、串、广义表),一对多结构(树、堆)、多对多结构(图)、集合、排序与查找…
-
各种设定:算法设计、算法分析、算法思想(递归、递推、枚举、二分、倍增、模拟、贪心、分治、回溯、剪枝、缓存、搜索、构造、近似、仿生、随机化、双指针、时空互换、动态规划、启发)…
-
各种技能:数论、图论、找规律、计算几何、搜索、概率分析、并查集、线性规划、矩阵、AI算法…
这些工具一定要内化,因为光是知道是没用的,要感受到、触摸到。
每个工具都能带给您不一样的体验,如果您可以掌握,比较适合走算法路线,多参加算法竞赛,不过软件方面就会菜一些。
数组、链表、哈希表、二叉树、排序算法等一些基础知识,对大多数人来说是没什么问题的。但是一旦进入到路径规划、背包问题、字符串匹配、动态规划、递归遍历等一些比较复杂的问题上,就会让很多人跟不上了,不但跟不上,而且还会非常痛苦 — 那比较适合走软件方面,多参加软件竞赛,不过算法和数学方面会菜一些。
基础的设计能力:不知道如何下手怎么办?
我们实现程序里的算法时,其实就是写一个或者若干个函数。
有时候,我也不知道该如何下手。
没关系,我们可以先分析一下问题的参数:
- 应该传什么参数给函数(作为输入参数)
- 函数处理完后,应该把什么数据作为结果返回(作为输出参数)
函数参数搞定后,再推导返回类型、函数名,于是函数原型就出来了:
返回类型 函数名(函数参数)
对一道问题完全没想法时,多半是没有分析好,这时候不要急,一步步分析。
分析好函数原型以后,再确认条件:
- 不变式
- 终止条件
- 边界条件:避免不合理的输入参数来攻击程序。
如果程序功能和某一数据结构的数据关系相同,就可以用数据结构来实现。
P.S. 数据结构:数据结构:把数据放入结构里,通过结构里最基本的计算方法(增、删、改、查)操作数据。
基础的建模能力:数组、链表,以及改进的结构
好的结构设计可以简化算法复杂度,算法通常是和数据结构一起学习的。
所有数据结构在存储上,都只有俩种形式:
- 数组:顺序存储
- 链表:链式存储
所有的数据结构建模,基本都是建立在这俩种存储之上的,掌握好数组、链表,数据结构的建模基本没啥编程上的问题了。
大概,有一个性能上的问题:
- 数组便于直接访问,方便数据的 查找 Θ ( 1 ) \Theta(1) Θ(1),而 插入、删除 麻烦 Θ ( n ) \Theta(n) Θ(n)。
- 链表强调前后关系,方便数据的 插入、删除 Θ ( 1 ) \Theta(1) Θ(1),而 查找 麻烦 Θ ( n ) \Theta(n) Θ(n)。
所以,就有了许多新的数据结构来改进:
-
跳表( s k i p l i s t skip~list skip list):通过随机化,形成了一种可以二分查找的有序链表。
查找、插入、删除都是: Θ ( l o g n ) \Theta(log~n) Θ(log n)。
大概长这样:
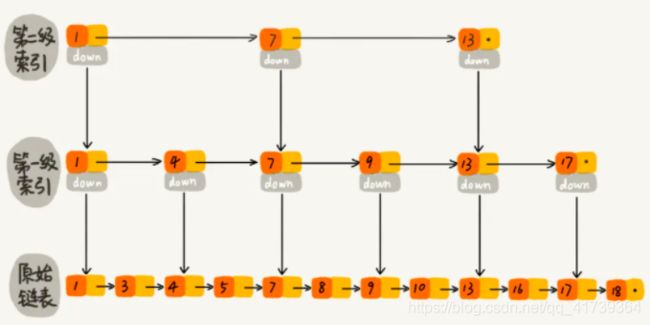
-
哈希表:通过随机化,把一个比较大的、稀疏的空间,映射到一个比较小的、紧密的空间中。
查找、插入、删除都是: Θ ( 1 ) \Theta(1) Θ(1),但占用空间大,利用率低。
数组、哈希表对比:数组在处理多个维度时变得很复杂,而哈希表可以将多个维度的数据映射到一个维度。
大概长这样:
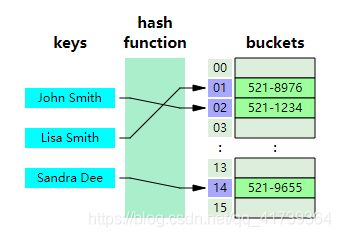
-
数组链表:本质是一个链表,这是语言学上的偏正关系,如牛奶和奶牛、蜜蜂和蜂蜜,主要是看最后一个词是什么。
因为数组链表,主要是便于在没有指针、引用类型的高级程序设计语言中使用链表结构,只是单纯的模拟链表,所以复杂度和链表一样。
插入、删除: Θ ( 1 ) \Theta(1) Θ(1),插入、删除只需要修改游标,不需要移动元素。
查找: Θ ( n ) \Theta(n) Θ(n),使用动态数组可解决表长难以确定的问题。
大概长这样:

-
链表数组:本质是一个数组,类似图的邻接表、树的孩子链,是一种顺序分配和链式分配相结合的存储结构。
查找: Θ ( l o g n ) \Theta(log~n) Θ(log n)。
插入、删除: Θ ( 1 ) \Theta(1) Θ(1)。
大概长这样:
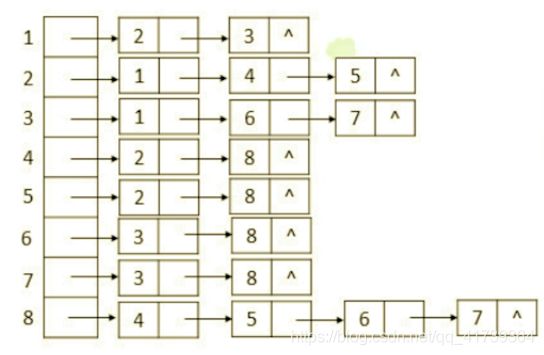
很多源码都有链表数组,如 :
HashMap 里的 tableLinux 内核 Buffer 里的 hash_tableLinux 内核进程调度里的 timer_listLinux 内核网络模块里的 sock_arrayLinux 内核网络模块里的 ip_protolsLinkedHashMap 里的 table
对比一下:
| 数据结构 | 查找 | 插入 | 删除 |
|---|---|---|---|
| 数组 | Θ ( 1 ) \Theta(1) Θ(1) | Θ ( n ) \Theta(n) Θ(n) | Θ ( n ) \Theta(n) Θ(n) |
| 链表 | Θ ( n ) \Theta(n) Θ(n) | Θ ( 1 ) \Theta(1) Θ(1) | Θ ( 1 ) \Theta(1) Θ(1) |
| 跳表 | Θ ( l o g n ) \Theta(log~n) Θ(log n) | Θ ( l o g n ) \Theta(log~n) Θ(log n) | Θ ( l o g n ) \Theta(log~n) Θ(log n) |
| 哈希表 | Θ ( 1 ) \Theta(1) Θ(1) | Θ ( 1 ) \Theta(1) Θ(1) | Θ ( 1 ) \Theta(1) Θ(1) |
| 数组链表 | Θ ( n ) \Theta(n) Θ(n) | Θ ( 1 ) \Theta(1) Θ(1) | Θ ( 1 ) \Theta(1) Θ(1) |
| 链表数组 | Θ ( l o g n ) \Theta(log~n) Θ(log n) | Θ ( 1 ) \Theta(1) Θ(1) | Θ ( 1 ) \Theta(1) Θ(1) |
后面的高级数据结构,就是基础的底层结构通过搭积木式的组合得到。
解题技巧:也说不清楚,就是对这道题有 feel 呀!
认知心理学说,人类最有效地解决问题方式,是"目标-手段分析法"。
- 先确认目标
- 再一层一层地分解,大问题变一组小问题
- 每一个小问题都有实现的手段,而后去做就完成啦
流程大致是:
- 确认目标
- 分析过程
- 分而治之
- 行行实现代码
- 代码封装
最重要的是确认目标,最难的是分析过程,因为这是脑力活;后面的代码一行行实现在封装,只是体力活。
分析多了,就会有一些感觉、套路。
比如,一般是从暴力开始思考,而后再进一步思考怎么去优化复杂度:
-
常见的枚举可以看一看枚举的范围是否有序,可以考虑用二分;
-
双重循环看一看是否可以用双指针(快慢指针、对撞指针);
-
一些要查找的 Θ ( n ) \Theta(n) Θ(n) 复杂度的部分是否可以用 m a p ( 键 值 对 ) 、 s e t ( 集 合 ) map(键值对)、set(集合) map(键值对)、set(集合);
-
括号、回文之类可以思考一下能否用栈;
-
一些暴力搜索的部分看一看是否存在根本不可能到达的状态可以考虑剪枝;
-
暴力搜索时看看是否有可重复利用的状态用 m a p map map 或数组把状态存起来(记忆化搜索),然后再看看是否可以用动态规划;
-
一些枚举的范围很大一看就知道不可能 a c ac ac,那思考一下是否可以直接推出结论或数学公式(贪心的思考方向);
-
一些感觉是动态规划的题目,貌似每一个状态都是有规律的可以尝试用打表这种比较赖皮的方法;
-
一些需要反复计算的部分如果是固定的,可以考虑先计算好然后把它存起来,下次直接拿来用(前缀和思想);
-
一些题目的条件和经典题型很像的可以考虑直接套用经典题型(例如 01 01 01背包模型,完全背包模型);
-
一些常见的操作可以看看有没有现成的类或方法可以直接拿来用(例如 j a v a java java大数、排序、字符串反转、拼接等常见操作);
-
一些数字的操作可以看看是否涉及到二进制,可以尝试下异或、&这些操作(位运算的骚操作);
-
动态规划的题目看一看这一次的状态和上一步的状态是否离得很近,如果离得很近可以考虑状态压缩,降低空间复杂度(例如斐波那契,每一次的状态只和前面两步状态有关);
-
如果题目给出了样例范围可以先通过样例范围反推出算法的时间复杂度,从而考虑题目大概可以用什么算法。
一般能有这种感觉,就是把知识【内化】为感觉了。
那具体怎么【内化】呢?
这个就得在《攻略》里说了。
攻略:新手、老手和大神之间的差异。
前置:数据结构是什么,以及作用?
如果不知道数据结构,请猛击:《数据结构 | 从哪里开始?》
既然数据结构这么重要,该怎么训练呢?
-
先系统性学习所有数据结构(数据如何建模+实现增删改查),做相关的题,做满三道就学下一个。
-
做相关的题:按类别 -> 画图分析增删改查的动态过程 -> 手写代码 -> 手敲 -> 对比题解 -> 背着敲。
-
广泛涉猎,一本一本书地学,一个一个知识点的认真总结,从长远来看,才是真正“高效率”的学习方法。
如果想未来是一个深不可测的计算机专家,在 21 21 21秒 或 24 小 时 24小时 24小时 内改变自己的人生,或者提高自己实际的编程水平,这是不可能的。
您得试试连续 24 个 月 24个月 24个月 不间断的努力提高自己。
曾经有人拿奥数题问数学家 丘成桐,而丘成桐表示自己不会做,也不值得做。
因为奥数注重于巧妙的技巧,而数学家却不是这技巧的集合。
就像真实世界里,警察是最擅长破案的,警察不是靠像福尔摩斯式的超高水平的推理,而是挨家挨户的排查,靠平时联络的线人、以及平时对这片区域的情况,还有网络摄像头。
真实的环境中,“孙子兵法”、“博弈论” 都没啥大用,智慧主要体现于 明智的选择、开阔的眼界、春去秋来的勤奋。
对于一位数学家也是如此,相对于解题技巧,数学家更需要的其实是 勤奋、眼光和思想。
系统训练之后,要以实践为主(遇到不会的再学):
《OJ训练:题目如何安排》
各种题型,都在上面,而且都是大佬自己做过的,里面大概包含了一种刻意的学习顺序,所以安利给您。
过去的读书人对“大而全的体系”都有偏执般的追求。
1923 1923 1923 年,清华大学的几个学生即将去美国留学,又怕被中国的学问圈落下,请胡适先生给开个国学必读书单。
胡适开了一个有 190 190 190 种书的《一个最低限度的国学书目》。
梁启超先生看了这个书单说“挂漏太多”、“博而寡要”。
胡适又精简成一个《实在的最低限度的书目》,有 38 38 38 种,但是其中包括《全唐诗》《王临川集》之类的大全集。然而梁启超也没有做的更好,他列出的《国学入门书要目及其读法》有 160 160 160 种书,之后的《最低限度之必读书目》中全都是各种“集”,比如《资治通鉴》和《李太白全集》……梁启超和胡适心想,这几本书你都没读过,你还跟我谈什么学问?
我的读书体会是,我们读书不是为了记住每一本书都讲些什么,而是为了建立一套自己对世界的“认知感”。
比如有人把一首诗摆在您面前。您没读过这首诗,但是您能从它的词句、意境、格局之中获得一些感觉。
- 如果这首诗水平很烂、一看就是现代人写的“老干部体”,您根本就不用理会。
- 而如果它出自高人之手,你也许就可以猜测出它是哪个朝代的哪个流派的,作者大概是谁。
您也不必读过所有的诗,甚至都不必通读《全唐诗》,就能获得对唐诗的认知感。
这个认知感往往无法言传。
就好像老专家鉴定文物一样,其实说不清到底哪里不对,但是因为看过的“老东西”多,你有一种“感”。
读书就是要养这个“感”。您没有必要通读《王临川集》,但是如果您对中国历史感兴趣,王安石这个人物,您得有个认知感。王安石是凉的还是热的?软的还是硬的?毛茸茸的还是扎手的?您没见过王安石本人,但是如果一个外行说王安石如何如何,您能听出来他说的不对。
大而全会让您感觉很成功,小而精却能让您成长。
所以,读书不能以书为本(如中学生必读、大学生必读),而是以自己为本(以培养认知感为本)。
- 您要选那些既能跟您现有的认知感产生共鸣,又让您感到些许意外的书。
- 读的书越多,你的敏感度就越高。您会体察到特别细微的差别。这个知识新不新,这个研究方向有没有前途,这个结果有多大价值?您会有所感。
- 贵精不贵多
学习的目的不能是为了“解除焦虑”,而是为了解决您真正遇到的问题。
很多人莫名其妙地焦虑,然后学了一些热门的新知,一瞬间获得那种 “哇,我懂了,我了解了新技术”的廉价快感,但是,这种快感来得快也去得快,焦虑并没有消除,甚至因为知道的东西多了更焦虑了。
学习的目的应该集中在解决问题,并且为了解决问题进行深度思考,直到问题解决,大学里学好基础学科就很好了,加油~
尽管我们不需要学奥数,但奥数训练的思路,与算法训练的思路是有共同点的,也就是【内化】这个事。
那,具体怎么【内化】呢?
关键要练习更高层次的推理,不要停留在浅层。
这就意味着做题一定要慢慢加难度,不要搞低水平重复。
学了这一层,把这一层当做默认信息,上高一层。
在高一层运用熟练了,再把那一层当做默认信息,再高一层,水平得这么练。
大多数人初学数据结构的时候(新手),会特意只做相关的练习,首先是让自己知道这个东西。
类似于知道 “三角形内角之和等于 180 180 180度” 这条知识,我们会去找这样一道题。
已知一个三角形,其中俩个角分别是 30度、60度,第三个角是多少度?
这种相关题,能迅速用上刚刚学的数据结构,但这是比较低的一层。
初学数据结构的人理解是,哪个结构对应哪种数据关系。
大多数人学过数据结构后(老手),会特意的问题尽量往数据结构偏移,主动制造一个局面 — 会通过一系列的布局引导,把局势引入自己擅长的局面。
类似于知道 “三角形内角之和等于180度” 这条知识,不过它不仅是一条知识,也是一个限制条件。
初学者知道的是:如果一个三角形的两个角知道了,那就等于三个角也知道了。
而老手的人根本不需要【有意识地】去调用这条知识,TA们会主动创造这么一个限制的环境,这个限制条件TA们会用,用的也特别好。
比如说,为了全面确定一个三角形,他会探寻其中两个角和一条边的情况。
他想的不是这个公式是什么 —— 那根本不用想 —— 他想的是我现在缺少什么关键条件,如何得到这个条件。
我和别人下军棋的时候,一开始根本不注意规则,俩个人玩起来也没什么规则…
后来,我发现利用好规则简直是利器,于是我说了一条规则:最小的棋子才能夺旗。
他对我定的规则没什么反应,我就怕他知道我心里的小九九,仔细观察后,发现他对自己的棋艺充满自信,对我的这条规则完全不在意(是一个会下棋的老头子)。
规则结合我的战术,就是把所有小棋(团长以下的)全部摆最前,主要是送死,全部给他。
因为我们只有俩个人下,没有中间的裁判,所以我也知道他那些吃了我小兵的棋子是什么。
我获取了大量的信息,消除了大量的不确定性,他的棋子在我眼里我差不多都是明棋;而我的棋子他一点都看不明白,中场的时候我把炸弹放到他那边,他应该以为是一个小兵吧…不过保险起见,还是用司令来吃我的“小兵”(炸弹),不得不说他很谨慎,难怪对我的这条规则完全不在意。
最后在双方都知道对方的军旗时,他的棋子愣是不敢过来 — 我最小的刚好和他最大的一样大,不过我只有几个棋子,而他的有十几个。
就因为多了一个限制条件,解决问题的视角就多了一种。
- 新手阶段,主要是在刻意的局面下,刻意用那些知识;
- 老手阶段,因为那些知识已经融入到了潜意识(变成了默认信息),主要是在刻意的制造一个有限制的局面;
学了这一层,把这一层当做默认信息,上高一层。
在高一层运用熟练了,再把那一层当做默认信息,再高一层,功夫得这么练。
无论是武术,还是编程,功夫越高,要求越严!
而顶级的 ACMer,对信息的掌握还要高一级。
题目在他们眼里,都是信息、信息的填充。
问题就是这么一个问题:
- 我已经知道什么信息
- 我能填充题目上的什么信息
- 哪里是确定的哪里是可变的,一目了然。
TA们根本都不用有意识地去想什么“因为……所以……”这种推理步骤,TA们眼中只有信息。
TA们都知道哪一步是必走的,哪一步是可选的,自己面临哪些选择,其中每一个选择会导致什么样的局面,每一个局面对自己是好是坏。
棋盘上最终出现的局面,只不过是他脑子里对这盘棋假想过的无数个局面中的一个而已 —— 那仅仅是信息。
因为竞赛题里有精妙的技巧、深刻的思想,不仅能让 p l a y e r player player 体会到 0 、 1 0、1 0、1 世界的正宗趣味,而且可以让 p l a y e r player player 看见别人看不见的隐性信息。所以,高水平的解题训练可以让 p l a y e r player player 学会十层的推理,而有的 p l a y e r player player 只能推一层。
高水平的 p l a y e r player player 总是稀缺的,不仅是在算法训练上,在各个领域都是如此,高水平的 p l a y e r player player 可能是军师、国师、丞相、元帅,其实都是一层一层练习出来的呀。
方法:做编程练习题,如同遇到一扇被锁着的门,您应该去哪里找钥匙呢?
显然不应该只盯着锁头看吧,您得把注意力从问题本身转移开啊,之所以打不开这扇门是因为钥匙并不在锁孔里,而是在别的地方。
- S t e p 1 − 我 已 经 知 道 什 么 信 息 Step1-我已经知道什么信息 Step1−我已经知道什么信息:彻底理解问题,但别找太难的,或已经会的。
用自己的语言重新表达问题,要求解的是什么?已知什么?要满足哪些条件?
- S t e p 2 − 我 能 填 充 题 目 上 的 什 么 信 息 Step2-我能填充题目上的什么信息 Step2−我能填充题目上的什么信息:形成解题思路,主要靠经验和工具。
以前有木有见过相似或相关的问题?以前用过的方法这次是否适用?
不相似的地方是否可以引入辅助限制?条件有木有用足?
能不能构造应该比现在更简单一点的问题,先解决简单的?
如果微调已知的条件,甚至改变求解目标,能否找到解题线索?
这些问题,您需要反复的问题,形成肌肉记忆,要背的这东西。
S t e p 3 − 哪 里 是 确 定 的 哪 里 是 可 变 的 , 一 目 了 然 Step3-哪里是确定的哪里是可变的,一目了然 Step3−哪里是确定的哪里是可变的,一目了然,核心在于总结。
绝不能解决完问题就了事,那就浪费了巩固知识和提升技巧的机会。你再检查一遍论证过程,尝试用另外的方法解题,寻找更明快简捷的方法,还要问,这次的解法能否用来解决其他问题?
这种解题方法在计算机科学里叫【启发式方法】,主要源于每个人的经验、之前的算法思想(视角),启发法本质上就是向经验学习,拆解经验中的规律和套路为当下所用。
而总结,是最好的启发时刻。
在《喾哲》的学者存在性定理中,我们通过玩一个小游戏,明白对任何一个问题,都存在一个能让答案一目了然、脱颖而出的视角。
一道难题摆在面前,可能当前谁都不知道怎么解决,但是您要相信,总有一个视角,会让答案看上去那么简单,能够脱颖而出。
视角,决定了问题的难度;也许普通人和大神差的只是一个视角及寻找视角的方法。
世界的规律在形式上并不复杂,但没有一个恰当的视角只会看得很复杂,因此寻找这视角反而是一个复杂的事情了。
启发式还有四种通用的套路:
- 类比启发式:通过联想寻找事物之间的联系和共同点,获取启发;
- 贪心启发式:通过寻找当前局面最优解,获取启发;
- 退火启发式:在贪心启发的基础上加上随机的探索,寻找到某个时刻时,停止探索,转为贪心启发式;
- 进化启发式:随机模拟生物(适者生存法则),留在最后的就是最优的;
新手、老手和大神之间的差异:
- 新手阶段,主要是在刻意的局面下,刻意用那些知识;
- 老手阶段,因为那些只是已经融入到了潜意识(变成了默认信息),主要是在刻意的制造一个有限制的局面;
- 大神阶段,都是信息(不仅看见能看见的,还能看见看不见的),各种信息之间尝试排列组合,就会形成很多方案。
除了刷题这个动作之外,
- 自己尝试:一个问题琢磨 1 − 2 1-2 1−2 天都是正常,提升能力的上策:贵精不贵多,下策:贵多不贵精
- 有思路,编出来:面对 b u g bug bug 不轻言放弃。逻辑都有了,为什么不能编出正确的代码,肯定可以的!
- 背着写:看别人的解决方案,自己试着实现,一个题目刷俩、三遍是很正常的
- 得总结:思考、吸收别人解决方案中的优点,反思自己的代码的问题。为什么别人的代码可以更有效率或者更加简洁?哪些是自己忽视的?
大神就是这么一级一级训练出来的,学了这一层,把这一层当做默认信息,上高一层。
在高一层运用熟练了,再把那一层当做默认信息,再高一层;功夫就得这么练,而且功夫越高,要求越严。
那怎么才能突破瓶颈,达到【大神】阶段呢?
这个就得在《模型》里说了。
攻略,最后倒是变成了一个能力管理问题了,所以您需要一个教练。
训练的甜蜜点是 85 : 15 85:15 85:15,每一个新知识都是建立在旧知识的基础之上。最好这一讲中 85 85 85% 的操作是您本来就会的(有亲切感), 15 15 15% 是新技巧。
当然,这是最理想的情况。
有时候我们接受的会是 80 80 80%新信息,这时候怎么办呢?
通用的方法是分多次死磕,一开始会感到很艰难,但坚持下来就好像吃了糖一样。
因为人有时候比较自恋,喜欢全能感,学习一个东西、做一个事情我一定要一次性过,这样会显得自己的厉害乃至伟大…如果分成俩次或者多次,那就会想:这么一件小事,伟大如我,居然要分成俩次才能完成这件小事,这怎么可以!!
生活中这样的例子比比皆是:
- 搬俩次比较合理的时候,却只搬一次…更大可能是弄巧成拙;
- 还有 “我不会再说第二次”…与别人交谈吧,如果不能让别人理解您的意思,那在是浪费双方的时间;
- 完美主义…
所以,自恋的人做起事情是不愿意一次又一次的尝试的,因为失败后,会有破坏 TA 的自恋。
自恋的人 TA 一定要一次性完成,要是没做好,反而更会猛烈的批评自己。
那怎么破呢?
最好是我们对自己既没有积极期待,也没有消极期待;既没有表扬,也没有批评,头脑只是用来分析认识事物,而不去评判好坏对错。
头脑的认识,只是为了帮助身体和潜意识的自我,更能放松和专注。当你能够做到这一点,您的能力发挥,是最惊人的。
训练的甜蜜点是 85 : 15 85:15 85:15,每一个新知识都是建立在旧知识的基础之上。
最好这一讲中 85 85 85% 的操作是您本来就会的, 15 15 15% 是新技巧。
如果是自学,因为没有基佬帮忙规划,通常面临的是 80 80 80%新信息,这个时候我们和别人相比,最不缺的就是【意志力】这东西,最缺的是【效率】。
如果我们可以不在意【自恋的情绪】时,我们就能不断的付出意志力,它是您最容易得到的东西,您可以以此来换取效率。
这 80 80 80% 的新信息,我第一次尝试能减少到 60 60 60%,去休息等状态好了,我立刻从头再来,失败是成功之路上所必要的,除非你失败,否则你不知道自己的脆弱之处。
其他事情尽可以自恋,但在学习这件事情上,自恋可就学不到东西了,失败就是失败了,不要严重的攻击自己,而是去安抚自己,并且在客观事实中总结原因,而后再次尝试,这样就可以了。
如果您想参加竞赛甚至一年内拿到亚洲赛区的冠军,那每天学习四小时,我想您的安排最好是这个配比,每天学习效率的上限也就是 15.87 15.87 15.87%。
训练,贵精不贵多。事实上,这种刻意练习,很难保持在 2 2 2 小时以上。
每天精力最充沛的时段拿出来训练自己,这段时间是您每天最重要的总结,是最值得分析的。
精力不那么集中的时候,去看比较轻松的知识,比如:
- 读理财、文化、历史、英语、文科、商科方面;
- 运动,洗澡,社交,处理好日常事务;
最好是跟着教练走,因为教练不仅能规划训练的层级,也能在竞赛前夕把选手的身体、心理调整到最佳状态。
扩展阅读 —> 请猛击:《系统性学习》。
模型:一题多解怎么来?
在OJ平台上,我们貌似比较追求一题多解。
其实新手、老手做题最好是多题一解,不要学大神的一题多解。
虽然一题多解是很厉害,但多题一解、多解归一对我们来说会更现实。
找到最优的算法太考智商了,我应该是不够的,如果能把完全不同类型的题目,看作一种题目去解,对我已然帮助很大;如若能把不同问题的解法,变成一种解法,那应该是抽象到最底层的方法论了。
建立自己的工具树,不断的挂果子,收获的也是知识。
相比之下,做那些只涉及到具体的问题,就算做很多,遇到新问题还是没法解决。
如果学会把具体问题抽象成模型,就能解决更多更难的新问题。
无论是【数据结构】,还是【算法思想】、【设计模式】,这些通用的方法,是人们在设计程序时,都总结出的经验。
这些经验是具体的慢慢演变为抽象的,从具象到抽象化并传承这些抽象的知识、经验,是人与其他动物最大的区别。
大神不也都是在抽象这方面掌握的特别的好嘛?
这种抽象的模型多了,自然能做到一题多解。
我们已经知道了大神为什么这么牛,但从老手到大神之间还有很多坎的。
应用:如何把问题与某个抽象的模型相连?
比如,如何把问题与某个抽象的模型相连?
也就是,抽象还原为具象。
具体怎么做呢,我们来看一个历史性的问题,这是一个让医生们束手无策的问题。
以前有一种射线,只要以一定的强度照射在肿瘤上,就能把肿瘤给杀死,等于是可以用来治疗癌症。
现在问题在于,射线到达肿瘤之前肯定会先接触到患者身体的其他组织,那就会把好的组织也给杀死。
可是如果把射线强度调低一点,好的组织能不被伤害,可是对肿瘤就也没用了。
那有没有一个什么办法,不用做手术开刀,既能让射线杀死肿瘤,又不会伤害其他组织呢?
尽管他们已经有了这么好的工具,但却不知道该怎么用~
就设计而言,这个答案本身并不重要,我们关心的是寻找答案过程中使用的思维方式。
有抽象才有 “类比”,用类比还原抽象问题,是把一个领域的思想,运用到另一个领域中去,不过您得先发现俩个领域的共同点。
从前有一个将军,要攻打一座城。攻城需要很多士兵同时发动进攻才好。可是这座城周围的道路都很窄小,并不适合大军通过。
这怎么办呢?
将军知道通往这座城的道路有很多条,于是他把士兵分散开,以小队的形式从不同的道路出发,按照约定时间一起到达 — 结果就把城给攻下来了。
类比解决问题,是把一个领域的思想,运用到另一个领域中去。
医生们的问题,也可以用若干束低强度的射线从不同的方向照射肿瘤。
因为射线强度不高,所以不会杀死途中路过的身体组织;而因为在肿瘤上汇聚的多个射线加起来的强度够高,所以能杀死肿瘤。
其实这就是现在有不少医院使用的“伽马刀”。
一般人看东西是关注不同点,而高手、抽象思维则善于发现两个很不一样的事物之间的相同点。
比如,下面这六件事情,您能不能把它们给分个类 ——
- 经济泡沫
- 北极冰川融化
- 美联储调节利率
- 人的身体出汗
- 不同的商品相继涨价
- 大脑指挥身体做动作
对美国西北大学的学生测试表明,如果是按照学科分,所有学生都能分的很好。
1、3、5 是经济学问题,4、6 是生理问题,2 是自然环境问题。
但要是按照这些事情的内部机制分类,就只有少数有跨界学习经历的学生能分好。
- 事实上 1 1 1 和 2 2 2 都是增强回路(因增强果,果增强因)
买东西的人越多经济越好,经济越好买东西的人越多;冰川越融化吸收阳光越多,吸收阳光越多冰川越融化。
- 3 3 3 和 4 4 4 都是平衡回路(因增强果,果减弱因)
美联储加息防止经济过热;皮肤出汗防止身体过热。
- 5 5 5 和 6 6 6 都是连锁信号传递(因果链)
石油涨价导致日用品涨价;大脑神经信号传递到四肢
能看出这种深层思维结构,才谈得上举一反三。
如果没看出来,其实也没关系,因为增强回路、平衡回路、因果链是【系统动力学】里面的模块,其地位等同数据结构的线性表、树、图。
数据结构是对数据关系的抽象,和系统动力学一样,都适用于解决有一定规律的重复性问题。
不过数据结构解决的是,数据储存和数据调用方面的问题,属于单纯的问题(有明确的方向、有标准的答案),大部分技术问题都是单纯问题,您掌握的工具、模型、视角,以及您是否聪明决定了您解决问题的上限。
而【系统动力学】虽然也是解决问题的,但这种问题不是单纯的问题(有明确的方向、有标准的答案),而是俩难问题(不好取舍)、棘手问题(对于无解的问题,也有应对的方法),比如 商业难题、看透和管理人心、预测未来等等。
【系统动力学】和【数据结构】也是有交集的,图论是数据结构的精神,也是系统动力学的灵魂。
但是一般大学生并没有这种深层的思维结构,他们只知道自己亲身经历的事情一样,只理解自己专业的一点知识。
有研究说,一般科研工作者的业余爱好水平跟普通老百姓没啥区别。
但是学术水平越高的科学家,就越有可能在学术工作之外发展个什么业余爱好 —— 而诺贝尔奖得主有诸如演员、舞蹈家或者魔术师之类业余爱好的可能性,比一般科研工作者要高…… 22 22 22 倍。
类比可以让我们举一反三,类比可以启发我们创造新事物,类比可以让我们审视自己和别人的原则,类比可以帮助我们发现各方的分歧所在,类比可以帮助交流思想……
从具象到抽象,需要抽象思维;从抽象到具象,需要类比与联想。
抽象思维能让您认识到事物的本质,发现各种看似不一样的事物背后的共同点;类比的背后,是高级的抽象思维。
总结
我说起来容易,但编程是一门硬技能,需要系统性的勤学苦练才能学会。
所以,推荐您联机学习,不要单机打怪。
虽然伙伴也只是在“在黑暗中并肩行走”,所能做到的仅是各自努力追求心中的光明,并相互感受到这种努力,相互鼓励。
但这种相互鼓励的圈子里,让我知道你一直与我同在,你让我平静,让我对自己感觉更好。
刷题也是一件很有意思的事情,如果没什么功利性的话(能打破所有对结果的预设期待,打破期待,关注练习本身)。
编程练习和别的事不同,要是解对了,自己能够知道,也会很开心。感觉自己的智慧就取得了一点实在的成就,虽然这种成就可能微不足道,但对个人来说,这些成就绝不是毫无意义的。
相对的,要是解的不对,自己也知道没解出来,就会有点小郁闷。
编程练习未必能培养我们什么能力,实际的好处可能就是修身养性,纯粹玩玩也是挺好的,把刷题当成强身健体陶治情操的活动吧。
正如乔恩·卡巴金说的:
你的态度就像是一片土壤,练习,就是你在这片土壤上培育一份能力,让心念平静、身体放松、集中注意力、看的更加清晰。
如果态度是这片贫瘠的土壤,也就是说,如果你对练习的承诺和投入很低微,那么,你就难以持之以恒的发展出那份平静和放松。
同样的,如果土壤被污染了,也就是说,如果你带着强烈的预期去练习,比如强迫自己去感到放松,强求达到某种目的,那么这片土壤将是不毛之地,你也将很快得出刷题是没有用的结论。
很大程度上,我们带到练习里的态度,将决定它对我们长期的价值。
这份态度,不仅仅可以用在练习这件事上,生活也可以哒~
… …
第一级【编好程序】
这是计算机从业者所必须掌握的,属于“雕虫小技”。
(P.S. 这是清华全球创新学院的创院院长史元春教授说的,这话要我说出来,估计会被各位大佬吊打)
【过关条件】:学完编程语言,每学一章都有做三道编程方面的练习。
文章 + 视频 + 题目
第二级【储备模型】
在《数据结构》、《算法思想》、《设计模式》里有大量的模型。
数据结构的出现和计算机本身工作的方式有关。
今天演化出来的很多数据结构,甚至和图灵机的原理,以及计算机底层的冯·诺依曼结构也有关。如链表这种数据结构,就和图灵机的设计直接相关。
世界上很多抽象化的结果,都和我们人容易掌握的工具有关。
如我们将大部分零件做成圆形的,或者有圆形的切割和开口,主要是因为圆形好加工。我过去做过金属工艺的加工,非常能体会使用机械(比如车床)切出一个圆的东西是很容易的事情,但是要切出一个方的是极为费劲的。
因此,谁要是在机械设计时搞了一堆方的设计,会被认为缺乏基本的机械设计素养。如果您到制造业的工厂去看看,基本上就只有两种运动,直线运动和圆周运动,其它所有的运动都是它们的组合(而且用得并不多)。
这并不是说世界上只有这两种运动,但是将运动抽象成这两种,就容易在机械中实现了。
顺序存储的数组、链式存储的链表也是如此。
与《算法训练》配套的数据结构索引:《数据结构从哪开始》
【过关条件】:
所以要对常见的算法有一定的基础:
-
常见排序(冒泡、快排、插入、堆排、归并…)
-
双指针(快慢指针、左右指针)
-
贪心、二分(二分查找)
-
搜索(dfs、bfs、各种剪枝、回溯思想)
-
动态规划(各种子序列、各种子串、常见的那几个背包问题)
-
前缀和
-
树的常见操作(各种遍历、各种树的性质、最小生成树)
-
图(最短路、常见性质)
常见的模型较为了解之后再去【第三级】:
- 常见数据结构和集合类(链表、队列、栈、map、list、set、并查集都得会用)
这些基础知识不求精通,不会写代码都行,但总得知道这些知识咋回事。
第三级【解决问题】
《OJ训练:题目如何安排》,如果想在这个阶段比较舒服、高效,就得找甜蜜点安排每天的题目,因材施教。
做相关的题:按类别 -> 画图分析增删改查的动态过程 -> 手写代码 o r or or 手敲 -> 对比题解 -> 背着敲。
广泛涉猎,一本一本书地学,一个一个知识点的认真总结,从长远来看,才是真正“高效率”的学习方法。
有耐心,如果想未来是一个深不可测的计算机专家,在 21 21 21 秒钟或 24 24 24 小时内改变自己的人生,或者提高自己实际的编程水平,这是不可能的。
您得试试连续 24 24 24 个月不间断的努力提高自己,这离不开春去秋来的勤奋。
【过关条件】:
-
一年里,每天做题刻意练习 2 h 2h 2h
-
饮食作息规律,要早睡才能早起,而早睡的条件是比较累,所以您可以每天负重深蹲 100 100 100 个,而要想运动表现处于好状态,您得多喝温水…
-
积极,推荐阅读《积极达成:处理好情绪再处理问题》,智商特别高的人,情绪不太能影响 TA
一个人要垮,首先精神先垮,只要精神不垮,就没有任何力量能摧毁我的意志和身体。
--- 某位大佬说的
第四级【建模能力】
抽象还原为具象的能力,打比方其实就是知识迁移的能力,一个人理解俩件事情的本质(还找了共同点),才能比方得让人拍案叫绝。
从具象到抽象:抽象思维
从抽象到具象:类比联想
抽象思维、类比联想相辅相成。
【过关条件】:
阅读,读完后认真做笔记。
-
抽象思维:波利亚三卷《怎样解题》、《数学的发现》、《数学的猜想》
-
培养类比能力的书籍:《The Art of Logic in an Illogical World》、《创新的本能:类比思维的力量》、《百科全书》
尽管阅读真是一件很有意思的事情,但我自己也有一个体系:日阅读量 143 页。
如果仅就阅读而言,应该以“阅读时长”为标准是最好的。
- 有这样一个规律:对同一个人来说,收获新知识的多少正比于阅读/学习的时长。
因为一个人的理解力和智力是稳定的,所以不论囫囵吞枣的快看,还是细嚼慢咽的慢看,单位时间里收获的知识总是大致一样多的。
无论是啃技术书籍,还是用在许许多多方面,每种都浅尝辄止,只要您持续花时间,最后的效果都很好。
第五级【优化模型】
如果有一天,自己可以优化模型,甚至挑战这些模型,您的编程水平就很高了,也就是培养建模能力,首推《系统动力学》。
- 培养洞察力能力的书籍:《Thinking in Systems: A Primer》、《如何系统思考》、《系统思考》、《第五项修炼》
系统动力学主要解决问题的,但这种问题不是单纯的问题(有明确的方向、有标准的答案),而是俩难问题(不好取舍)、棘手问题(对于无解的问题,也有应对的方法),比如 商业难题、看透和管理人心、预测未来等等。
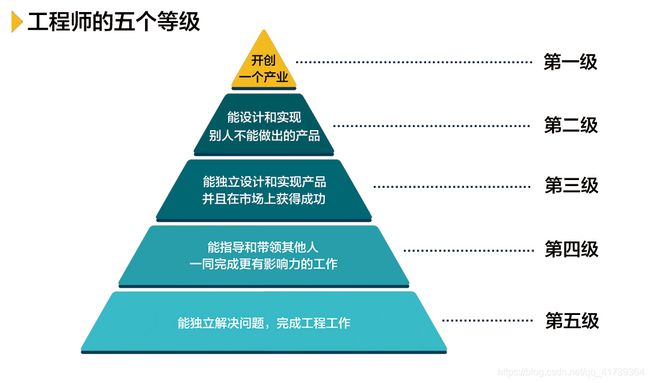
如果我们抛弃次要因素,专注主要的趋势,那工程师可以分为五级,第五级最多,第一级最少(中国还没有一级工程师)。
如果只盯着眼前的事情,一段时间后自然觉得自己啥都懂了,但其实还有一个更大的世界,更高的层次需要我们去认识。但这不仅是一个增强技术能力的过程,更是转变思考方式,扩大眼界的过程。
工程师列传:
-
一级工程师:高德纳Google云计算发明人 (爱迪生、贝尔、福特)
-
二级工程师:杰夫·迪恩发明Google大脑、邓峰打造出了真正意义上的网络防火墙
-
三级工程师:自己的产品做到世界第一,如人脸识别第一、语音识别第一等等
-
四级工程师:有头脑的工程师,能写出大型的软件项目的软件工程大师
-
五级工程师:比工科大学毕业的大学生强一些,更有经验
【编好程序】、【储备模型】、【解决问题】、【建模能力】,是图中第五级工程师的能力,而【优化模型】是图中第二、三级的工程师的能力。
第一级工程师,在玄幻小说里,也是传奇人物了。
比如《斗罗大陆2绝世唐门》的主角[霍雨浩],创造了人类与魂兽新的连接方式并成立了组织传灵塔,消除了俩大种族日益加强的争端…
正是开创了一个产业,这个人的影响力也会波及到后世,不仅可以影响身边的人,还有影响到未来的人们…
现在的培训班、按部就班教学的大学、网络上的课程,大多是教授 “计算机系” 最基础的内容 — 技术。但这些还都是比较浅层的计算机内容,只会这些在现代只会被代替… …
就像很多人说做 IT 是吃青春饭,从现象上看,确实如此。这里面很重要的原因在于,很多人在学习计算机时,以为自己所学的就是热门,自己就是中心,但其实只是掌握了一种服务于他人的工具而已。
因为很多人学了就只会操作这个工具(只会写代码),而操作它做什么,则完全需要别人下命令。
如果一个人只会使用编程这个工具,很快就会被更年轻的,更会操作工具,而且掌握了新工具的人取代。
而算法训练,其实是在训练一种新的认知,一种信息时代的思维方式:计算机思维。
虽然它也是人思维的一部分,但和常人的思维方式完全不同,是伴随计算机出现的,结合人的逻辑、数学思维的思维。
训练好这种思维后,就是要把这种思维方式用到其他学科领域中去,可以带给人、产业的认知升级。 最需要考虑的一个问题就是,如何把那个领域的问题转化为信息或者数学问题,这也正是大部分计算机科学家做的事情。
比如一些,近些年大名鼎鼎的技术:
-
语音识别。
科学家会先去了解人类是怎么识别语言,怎么发音的。
以前的专家系统研究的都是表象,想的是语言学的各种概念:元音(声母)、辅音(韵母)、词组、语法、上下文… …这些都是表象,或者说是我们人为创造出来的概念。
语言只是承载信息的工具,或者说是一种编码方法,而背后的信息才是最重要的。
我们通过说话,即口述语言的表达,是为了让收听者,明白我们脑子里想的意思:
- 说话人将意思用语言描述出来
- 声音在空气、水、电话线中传播,收听人将声波变成耳朵能够接受的信号,通过听觉神经传到收听的大脑里
- 收听人将收听到的信号还原回讲话人的意思
第一个过程,其实和通信中的信息源编码过程是一致的,您在微信中发一条消息,计算机先要将它变成能够在通信系统中传播的编码,这就是编码过程。
第二个过程,其实是信息在不同信道中传输的过程。
第三个过程,则是第一个过程的逆过程,即解码过程。
编码-信道传输-解码,这不就是一个标准的通信过程么?既然语音识别的等价问题是通信问题,那么就可以采用解决通信问题的方法解决语音识别问题… …
信息处理的问题是数学问题,让计算机处理自然语言也是数学问题,看似需要人脑推理的问题,其实是一个计算问题。
所以,贾里尼克教授开玩笑的讲,他每解雇一位语言学家,他的语音识别系统的错误率就降低 1 1 1%。
-
机器翻译。
再接下来,贾里尼克教授的一个叫 彼得∙布朗 的部下发现机器翻译的问题也是一个通信问题。
布朗是这么考虑的:
- 假如我们要将中文翻译成英文,我们通常认为说话人说的是中文。但是布朗换了一个角度看问题,他觉得当你对一个外国人说话时,说的是一种可以用英文表达的意思,只不过你在表达这个意思的时候,选择使用中文做了一次特殊的编码而已。
- 翻译者,也就是解码的一方,所要做的无非是把中文编码的信息串解码还原成你的(英文)意思。这么看待问题,就把机器翻译问题从两种自然语言的理解,变成了一个通信问题。
信息处理的问题是数学问题,让计算机处理自然语言也是数学问题,看似需要人脑推理的问题,其实是一个计算问题。
-
基因测序。
后来,到了 90 90 90年代的时候,约翰∙霍普金斯大学的 萨尔兹伯格 教授采用了一个全新的视角来看待基因测序问题。
他认为:
- 人的基因不过是一本特殊的书,书中的字母只有 A 、 G 、 C 、 T A、G、C、T A、G、C、T 这四种,因此任何识别语言文字的算法,比如语音识别和 O C R OCR OCR 的算法,都可以用于基因测序。
有了这个想法后,他离开了大学,到专门从事基因测序的研究所 T I G R TIGR TIGR,转行从事基因测序研究了,并且后来获得了那个领域的最高奖。信息处理的问题是数学问题,让计算机处理自然语言也是数学问题,看似需要人脑推理的问题,其实是一个计算问题。
-
股票市场的分析和预测
2016年,文艺复兴科技公司 被誉为 “世界上最大的摇钱树”,因为这30多年以来,这个基金平均每年的增幅都在 80 80 80% 左右。
创始人西蒙斯有一个独特的投资座右铭:
- 一旦确定好了一套算法或者模型,那么就百分之百地相信它,不去对它进行任何人为的干扰,直到它给你带来最终的结果。
这么多年来,西蒙斯都坚持着这条专属于他的座右铭。
西蒙斯的管理类似贾里尼克教授,比如他请的人,有物理学家、天文学家、数学家等等,却偏偏没有金融家。
因为西蒙斯认为,数据分析必须要基于非常干净的数据处理,以及最先进严谨的算法,而金融理论跟经验并不是他最需要的。
当西蒙斯 71 71 71 岁选择退休的时候,他把公司的管理权交给了两位语音识别方面的专家。
看起来,语音识别跟对冲基金是两个跨度非常远的行业了,但是在西蒙斯看来,语言是一种非常具有预见性的系统,他相信他请的这两位语音识别专家,可以把他们的语言研究技能运用到金融市场上去。
这个语言研究技能不是语言学的方法,而是身为计算机科学家的计算机思维。
可以说,计算机系最有前途的学生一定是跨学科的 ,利用计算机思维解决那个领域的问题,当然对那个领域的知识也是要懂的。
- 比如做语音识别,计算机还真的只是个工具,对于声学的了解,对于信号处理的了解,对于自然语言处理的了解,构成了从事这个领域研究的必要条件。了解这些,你就可以做研究,发明新算法,成为领域专家。不了解这些知识,只能当一个帮助别人写程序的程序员。
因此,计算机实际上是一个十分跨界、注重组合的学科;与计算机联系的领域,就像四面八方的窗户… …但对于计算机科学家来说,己身最核心、最基础的技能莫过于计算机思维。
如果单纯的把计算机单纯当作实现自动化、提升生产率的工具、一份工作,你就无法深入研究计算本身的逻辑,就无法get到计算的真正魅力,更无法理解深藏于宇宙中的、具有通识意义的计算道理 —— 最终无法获得计算背后、提升效率的心法真意!
反之,如果你不去刻意追逐自动化和效率、工资,另辟蹊径研究计算的问题,研究计算机存在背后的原理,明白人脑的计算逻辑、自然界的计算方式、宇宙的计算公式,那么计算机世界核心的宝藏就会为你敞开,你会找到最至高无上的效率之法!
您想选哪一种都取决于您自己的勤奋、眼光和思想~
有的时候,我们是在聊算法,有的时候是在拿算法说事。
- 《数据结构》:动手为主,刷题练题型,收集模版 — 多看,而后就会有自己独到的写法了
- 《算法训练》:总结为主,计算机思维,就靠推理 — 多想,而后就会有自己独到的看法了
我有试着每天总结,这样可以不受某个具体的教育环境限制,自己培养自己。
- 《定期不定额的总结》:每天总结就好,不要求量
总结的初心很清晰:
- 为了可以不遵守任何作息规则,又生活的自律。
- 为了安顿自己,特别是安于自己的笨拙、孤独。
- 为了让玩游戏、看小说、煲剧、浪费时间、虚度光阴有一种合法的感觉,也能进入看似慢腾腾的体验,享受了过程。还去影响了每一个日子的品质。
- 为了自己做的每件事都有意义,不做没有意义的事。
但发现,真正的收获还不是这些,而是一种通用的认知的能力。
自己的思考与思路越来越接近于正确、越来越完整、越来越高效……
如果不断加强自己的 认知能力,也许终究有一天,哪怕是你不假思索、甚至随随便便创造出来的东西,都是真正有价值的,不仅对自己有价值,对他人也有价值,对很多很多人有价值,甚至对绝大多数人都有价值……
可能,算法训练的背后也不是学了具体(抽象)的算法、题型,而是一种认知能力,一把打开所有知识的万能钥匙。
文字以及文字所阐述的道理,背后是作者的“思考方式” ,作者的“思考方式”与自己的“思考方式”之间的不同,以及,若是作者的“思考方式”有可取之处的话,自己的“思考方式”要做出哪些调整?
于是,一本高数读完,大多数人就是考个试及格,而另外的极少数人却成了科学家——因为他们改良了自己的思考方式,从此可以“像一个科学家一样思考”……
- 《如何意会微积分》:理论背后的思想