WaWa的奇妙冒险(第二周集训自闭现场)
第二周周记
- (一)例题记录
- A-简单计算器 (水题,栈的运用) HDU - 1237
- Input
- Output
- Sample Input
- Sample Output
- 理解
- AC代码
- B-计算 (逆波兰表达式天下第一)
- Input
- Output
- Sample Input
- Sample Output
- 理解
- AC代码
- C-中缀表达式值 (栈的运用)
- Input
- Output
- Sample Input
- Sample Output
- 理解
- AC代码
- D-图形面积 (水题,栈的运用or搜索?)
- Input
- Output
- Sample Input
- Sample Output
- 理解
- AC代码
- E-The Blocks Problem (模拟,map AND vector) UVA - 101
- Input
- Output
- Sample Input
- 理解
- AC代码
- F-Ananagrams (水题,二重映射) UVA - 156
- Input
- Output
- Sample Input
- Sample Output
- 理解
- AC代码
- G-Team Queue (分支队列) UVA - 540
- Input
- Output
- Sample Input
- Sample Output
- 理解
- AC代码
- H-Database (map 查找) UVA - 1592
- Input
- Output
- Sample Input
- Sample Output
- 理解
- AC代码
- I-Unix ls (水题,排版) UVA - 400
- Input
- Output
- Sample Input
- Sample Output
- 理解
- AC代码
- J-对称轴 (水题,map AND pair) UVA - 1595
- Input
- Output
- Sample Input
- Sample Output
- 理解
- AC代码
- K-打印队列 (水题,模拟,队列) UVA - 12100
- Input
- Output
- Sample Input
- Sample Output
- 理解
- AC代码
- L-图书管理系统 (模拟,set) UVA - 230
- Input
- Output
- Sample Input
- Sample Output
- 理解
- AC代码
- M-找Bug (模拟,递归写栈) UVA - 1596
- Input
- Output
- Sample Input
- Sample Output
- 理解
- AC代码
- N- Web中搜索,有意义 (模拟) UVA - 1597
- Input
- Output
- Sample Input
- Sample Output
- 理解
- AC代码
- O-更新字典 (水题) UVA - 12504
- Input
- Output
- Sample Input
- Sample Output
- 理解
- AC代码
- P-Gathering Children (水题,思维题) atcoder
- Input
- 理解
- AC代码
- (二)一些收获
- 关于STL
- 关于模拟题
- (三)感想
- (四)附录[学习笔记]
(一)例题记录
A-简单计算器 (水题,栈的运用) HDU - 1237
读入一个只包含 +, -, *, / 的非负整数计算表达式,计算该表达式的值。
Input
测试输入包含若干测试用例,每个测试用例占一行,每行不超过200个字符,整数和运算符之间用一个空格分隔。没有非法表达式。当一行中只有0时输入结束,相应的结果不要输出。
Output
对每个测试用例输出1行,即该表达式的值,精确到小数点后2位。
Sample Input
1 + 2
4 + 2 * 5 - 7 / 11
0
Sample Output
3.00
13.36
理解
因为暴力模拟过一元一次方程,所以写这题的时候没啥感觉,但因为要用上栈,所以还是做了一些思考
得出来的解决方案是用栈存储“+”和“-”,在优先完成“*”和“/”之后出栈完成最终计算
(这个地方的构思还是不够巧妙,对于第二天写升级版的计算器影响挺大的,后面学了中缀转后缀,以及后缀的计算之后,才惊觉对于中缀表达式的计算
用栈可以达到一个很巧妙的地步,善用栈解决 “优先级” 的问题)
AC代码
#include 但是这题实际上的运算只要两个优先级,而且输入上大有文章可做,所以看到了大佬的神奇代码

这种写法确实十分厉害,一种非常巧妙的思想,后面也是用这种思想封装过简单的计算,但放优先级层次多了之后,我借用这种巧妙的想法无法完成更难的题(高概率是个人实力不行),而逆波兰表达式(后缀表达式)此时便凸显出了作用,能对这类型的题目完成一种模板式的通杀。
个人认为栈的写法(不是我简单计算器的ac代码),确实是对于算式题优先级的解决提供了一个良好的解决方案,虽然打起模板来代码量比较大,但胜在大部分人学习后能够使用(愚蠢的我选择栈),后面题目会贴出类似模板。
B-计算 (逆波兰表达式天下第一)
小明在你的帮助下,破密了Ferrari设的密码门,正要往前走,突然又出现了一个密码门,门上有一个算式,其中只有“(”,“)”,“0-9”,“+”,“-”,“*”,“/”,“^”求出的值就是密码。小明数学学得不好,还需你帮他的忙。(“/”用整数除法,取商)
Input
输入共1行,为一个算式。
Output
输出共1行,就是密码。
Sample Input
1+(3+2)(7^2+69)/(2)
Sample Output
258
理解
最开始是用了类似上面大佬的思路,封装了计算函数,来处理()内的算式,所以,蒟蒻的我成功wa了,关键点在于处理多重(),到最后我都没能想
出来,在百度完中缀表达式转后缀表达式之后,我仿佛找到了a题的途径,因为后缀表达式的计算只需要从左往右进行一个循序计算即可,敲了一晚上的
模板,成功把题a了,也对这种题型有了一个较好解题思路。
AC代码
#include 后来第二天在思考的时候,感觉中缀转后缀,后缀的计算,实质上就是一个中缀表达式利用栈按优先级进行计算的拆分,然后改出了下面这份代码
## 在理解上面代码的情况下很容易能懂下面的代码,此处也不再赘述
#include 参考的大佬blog
中缀转后缀 https://blog.csdn.net/coder_dacyuan/article/details/79941743
后缀的计算 https://blog.csdn.net/sjhdxpz/article/details/81210448
C-中缀表达式值 (栈的运用)
输入一个中缀表达式(由0-9组成的运算数、加+减—乘*除/四种运算符、左右小括号组成。注意“-”也可作为负数的标志,表达式以“@”作为结束符),判断表达式是否合法,如果不合法,请输出“NO”;否则请把表达式转换成后缀形式,再求出后缀表达式的值并输出。
注意:必须用栈操作,不能直接输出表达式的值。如果再考虑是实数运算呢?
Input
输入的第一行为一个以@结束的字符串。
Output
如果表达式不合法,请输出“NO”,要求大写。
如果表达式合法,请输出计算结果。
Sample Input
1+2*8-9@
Sample Output
8
理解
在做完计算之后看这道题,明显就有了思路,因为你知道中缀转后缀和后缀的计算了,剩下需要解决的也就只剩下 “负数的处理” 和 “判断中缀表达
式是否合法” 两项内容。
1.负数的处理:这一项比较简单,选择性地往表达式里面插入0就好了
2.中缀的判断:总体可以归纳为:
(1)对(在末尾以及(前后字符的判断
(2)对)在开头以及)前后字符的判断
(3)对运算符前后的字符判断以及其在开头和结尾的判断
AC代码
#include 写这道题也是有点惨,一直运行错误,理了很久的思路才明白是判断写的有问题(存在漏网之鱼),导致运算过程中出现访问空的栈顶元素以及删除的操作导致re,后面也是看了老师的代码,才惊觉自己写的判断少了连续出现运算符以及空括号这两种情况的判断。
现在的判断也是照抄了老师的判断思路,以字符为准进行选择判断(反正比我之前的判断思路优越许多)。
D-图形面积 (水题,栈的运用or搜索?)
编程计算由“”号围成的下列图形的面积。面积计算方法是统计号所围成的闭合曲线中水平线和垂直线交点的数目。如下图所示,在1010的二维数组中,有“”围住了15个点,因此面积为15。

Input
输入0-1矩阵(1表示*)
Output
输出面积。
Sample Input
0 0 0 0 0 0 0 0 0 0
0 0 0 0 1 1 1 0 0 0
0 0 0 0 1 0 0 1 0 0
0 0 0 0 0 1 0 0 1 0
0 0 1 0 0 0 1 0 1 0
0 1 0 1 0 1 0 0 1 0
0 1 0 0 1 1 0 1 1 0
0 0 1 0 0 0 0 1 0 0
0 0 0 1 1 1 1 1 0 0
0 0 0 0 0 0 0 0 0 0
Sample Output
15
理解
一道简单的水题,没啥好讲的,记录一下的原因也只是这貌似可以用搜索做,但我是拿栈a掉的
AC代码
#include 方法也是比较差,就不多讲了。
网上没找到这题。。。也就没有搜索的写法,以后有空自己试着写一份吧,貌似感觉是dfs???
E-The Blocks Problem (模拟,map AND vector) UVA - 101
Many areas of Computer Science use simple, abstract domains for both analytical and empirical studies.For example, an early AI study of planning and robotics (STRIPS) used a block world in which a robot arm performed tasks involving the manipulation of blocks.
In this problem you will model a simple block world under certain rules and constraints. Rather than determine how to achieve a specified state, you will “program” a robotic arm to respond to a limited set of commands.
The problem is to parse a series of commands that instruct a robot arm in how to manipulate blocks that lie on a flat table. Initially there are n blocks on the table (numbered from 0 to n − 1) with block bi adjacent to block bi+1 for all 0 ≤ i < n − 1 as shown in the diagram below:

The valid commands for the robot arm that manipulates blocks are:
• move a onto b
where a and b are block numbers, puts block a onto block b after returning any blocks that are stacked on top of blocks a and b to their initial positions.
• move a over b
where a and b are block numbers, puts block a onto the top of the stack containing block b, after returning any blocks that are stacked on top of block a to their initial positions.
• pile a onto b
where a and b are block numbers, moves the pile of blocks consisting of block a, and any blocks that are stacked above block a, onto block b. All blocks on top of block b are moved to their
initial positions prior to the pile taking place. The blocks stacked above block a retain their order when moved.
• pile a over b
where a and b are block numbers, puts the pile of blocks consisting of block a, and any blocks that are stacked above block a, onto the top of the stack containing block b. The blocks stacked above block a retain their original order when moved.
• quit
terminates manipulations in the block world.
Any command in which a = b or in which a and b are in the same stack of blocks is an illegal command. All illegal commands should be ignored and should have no affect on the configuration of blocks.
Input
The input begins with an integer n on a line by itself representing the number of blocks in the block world. You may assume that 0 < n < 25.
The number of blocks is followed by a sequence of block commands, one command per line. Your program should process all commands until the quit command is encountered.
You may assume that all commands will be of the form specified above. There will be no syntactically incorrect commands.
Output
The output should consist of the final state of the blocks world. Each original block position numbered i (0 ≤ i < n where n is the number of blocks) should appear followed immediately by a colon. If there is at least a block on it, the colon must be followed by one space, followed by a list of blocks that appear stacked in that position with each block number separated from other block numbers by a space. Don’t put any trailing spaces on a line.
There should be one line of output for each block position (i.e., n lines of output where n is the integer on the first line of input).
Sample Input
10
move 9 onto 1
move 8 over 1
move 7 over 1
move 6 over 1
pile 8 over 6
pile 8 over 5
move 2 over 1
move 4 over 9
quit
Sample Output
0: 0
1: 1 9 2 4
2:
3: 3
4:
5: 5 8 7 6
6:
7:
8:
9:
理解
一道有趣的模拟题,给你各种指令,然后要求你输出执行完所有指令之后各个位置上的数字有什么
因为各个位置上还有各有队列,姑且把他看成二维数值,再用map标记这个数字当前在哪一个数组里方便查找,很容易就能模拟出来
此题的难点在于题意的理解,那几个指令刚开始看把我看傻了,看翻译都看不懂是什么意思
然后指令翻译完之后
1.move a onto b,把a和b上面的木块全都放回原来的位置,然后把a放到b上面。
2.move a over b,把a上面的木块放回原来的位置,然后把a放到b所在的木块堆的最上面
3.pile a onto b,把b上面的木块放回原来的位置然后把a以及a上面的木块全部放到b上
4.pile a over b,把a以及a上面的木块全部放到b所在的木块堆上.
5.quit 结束,然后输出操作完之后的结果
AC代码
#include F-Ananagrams (水题,二重映射) UVA - 156
Most crossword puzzle fans are used to anagrams — groups of words with the same letters in different orders — for example OPTS, SPOT, STOP, POTS and POST. Some words however do not have this attribute, no matter how you rearrange their letters, you cannot form another word. Such words are called ananagrams, an example is QUIZ.
Obviously such definitions depend on the domain within which we are working; you might think that ATHENE is an ananagram, whereas any chemist would quickly produce ETHANE. One possible domain would be the entire English language, but this could lead to some problems. One could restrict the domain to, say, Music, in which case SCALE becomes a relative ananagram (LACES is not in the same domain) but NOTE is not since it can produce TONE.
Write a program that will read in the dictionary of a restricted domain and determine the relative ananagrams. Note that single letter words are, ipso facto, relative ananagrams since they cannot be “rearranged” at all. The dictionary will contain no more than 1000 words
Input
Input will consist of a series of lines. No line will be more than 80 characters long, but may contain any number of words. Words consist of up to 20 upper and/or lower case letters, and will not be broken across lines. Spaces may appear freely around words, and at least one space separates multiple words on the same line. Note that words that contain the same letters but of differing case are considered to be anagrams of each other, thus ‘tIeD’ and ‘EdiT’ are anagrams. The file will be terminated by a line consisting of a single ‘#’.
Output
Output will consist of a series of lines. Each line will consist of a single word that is a relative ananagram in the input dictionary. Words must be output in lexicographic (case-sensitive) order. There will always be at least one relative ananagram.
Sample Input
ladder came tape soon leader acme RIDE lone Dreis peat
ScAlE orb eye Rides dealer NotE derail LaCeS drIed
noel dire Disk mace Rob dries
Sample Output
Disk
NotE
derail
drIed
eye
ladder
soon
理解
比较简单的水题,看两个单词想不想同只要全部大写或小写,然后用sort排序,最后用map计数即可
记录这道题是因为,写这题的时候,因为要处理原单词和处理过后单词的关系,想了一个二重映射,感觉算是开阔了思路
AC代码
#include G-Team Queue (分支队列) UVA - 540
Queues and Priority Queues are data structures which are known to most computer scientists. The Team Queue, however, is not so well known, though it occurs often in everyday life. At lunch time the queue in front of the Mensa is a team queue, for example.
In a team queue each element belongs to a team. If an element enters the queue, it first searches the queue from head to tail to check if some of its teammates (elements of the same team) are already in the queue. If yes, it enters the queue right behind them. If not, it enters the queue at the tail and becomes the new last element (bad luck). Dequeuing is done like in normal queues: elements are processed from head to tail in the order they appear in the team queue.
Your task is to write a program that simulates such a team queue.
Input
The input file will contain one or more test cases. Each test case begins with the number of teams t (1 ≤ t ≤ 1000). Then t team descriptions follow, each one consisting of the number of elements belonging to the team and the elements themselves. Elements are integers in the range 0…999999. A team may consist of up to 1000 elements.
Finally, a list of commands follows. There are three different kinds of commands:
• ENQUEUE x — enter element x into the team queue
• DEQUEUE — process the first element and remove it from the queue
• STOP — end of test case
The input will be terminated by a value of 0 for t.
Warning: A test case may contain up to 200000 (two hundred thousand) commands, so the implementation of the team queue should be efficient: both enqueing and dequeuing of an element should only take constant time.
Output
For each test case, first print a line saying ‘Scenario #k’, where k is the number of the test case. Then,for each ‘DEQUEUE’ command, print the element which is dequeued on a single line. Print a blank line after each test case, even after the last one.
Sample Input
2
3 101 102 103
3 201 202 203
ENQUEUE 101
ENQUEUE 201
ENQUEUE 102
ENQUEUE 202
ENQUEUE 103
ENQUEUE 203
DEQUEUE
DEQUEUE
DEQUEUE
DEQUEUE
DEQUEUE
DEQUEUE
STOP
2
5 259001 259002 259003 259004 259005
6 260001 260002 260003 260004 260005 260006
ENQUEUE 259001
ENQUEUE 260001
ENQUEUE 259002
ENQUEUE 259003
ENQUEUE 259004
ENQUEUE 259005
DEQUEUE
DEQUEUE
ENQUEUE 260002
ENQUEUE 260003
DEQUEUE
DEQUEUE
DEQUEUE
DEQUEUE
STOP
0
Sample Output
Scenario #1
101
102
103
201
202
203
Scenario #2
259001
259002
259003
259004
259005
260001
理解
一道很有意思的题,大意是叫你模拟插队的情况:如果现在的队列中有他认识的人,他插在他认识的人群的最后面,否则他乖乖去队列尾部排队
这道题有着先进先出的原则,在容器的使用上肯定以queue优先
但是要处理好插队的情况,而queue不能随意删改,只能对队首进行操作
所以建立两个队列,将其分为主干和分支
主干:排队的队列,记录哪些团队在队列里有人
分支:团体队列,记录这个团体中的先来后到
在某个团体的人在主队列中走光之后,弹出主队列的队首元素,让下一个团队上
某个团队的人还为在主队列中出现时,将新出现的团体排在主队列队尾
AC代码
#include H-Database (map 查找) UVA - 1592
Peter studies the theory of relational databases. Table in the relational database consists of values that are arranged in rows and columns.
There are different normal forms that database may adhere to. Normal forms are designed to minimize the redundancy of data in the database. For example, a database table for a library might have a row for each book and columns for book name, book author, and author’s email.
If the same author wrote several books, then this representation is clearly redundant. To formally define this kind of redundancy Peter has introduced his own normal form. A table is in Peter’s Normal Form (PNF) if and only if there is no pair of rows and a pair of columns such that the values in the corresponding columns are the same for both rows.

The above table is clearly not in PNF, since values for 2rd and 3rd columns repeat in 2nd and 3rd rows. However, if we introduce unique author identifier and split this table into two tables — one containing book name and author id, and the other containing book id, author name, and author email,then both resulting tables will be in PNF.

Given a table your task is to figure out whether it is in PNF or not.
Input
Input contains several datasets. The first line of each dataset contains two integer numbers n and m(1 ≤ n ≤ 10000, 1 ≤ m ≤ 10), the number of rows and columns in the table. The following n lines contain table rows. Each row has m column values separated by commas. Column values consist of ASCII characters from space (ASCII code 32) to tilde (ASCII code 126) with the exception of comma (ASCII code 44). Values are not empty and have no leading and trailing spaces. Each row has at most 80 characters (including separating commas).
Output
For each dataset, if the table is in PNF write to the output file a single word “YES” (without quotes).
If the table is not in PNF, then write three lines. On the first line write a single word “NO” (without quotes). On the second line write two integer row numbers r1 and r2 (1 ≤ r1, r2 ≤ n, r1 ̸= r2), on the third line write two integer column numbers c1 and c2 (1 ≤ c1, c2 ≤ m, c1 ̸= c2), so that values in columns c1 and c2 are the same in rows r1 and r2.
Sample Input
3 3
How to compete in ACM ICPC,Peter,[email protected]
How to win ACM ICPC,Michael,[email protected]
Notes from ACM ICPC champion,Michael,[email protected]
2 3
1,Peter,[email protected]
2,Michael,[email protected]
Sample Output
NO
2 3
2 3
YES
理解
这题的大意就是,叫你看看输入的东西里面有没有两列在两行中时相等的即((r1,c1) == (r1,c2) && (r2,c1) == (r2,c2))
但这道题恶心就恶心在你要以列开始找,然后确认两行(简单的说,就是优先输出列最小的重复项)
而且直接比较字符串会tle(所以map是必备的,从比较字符串变成比较数字是否相同,能节省很多时间)
AC代码
#include 这道题走了不少弯路,刚开始理解的太简单了,先找行后找列,虽然好写,但题意就理解错了,wa得很流畅。
后面写的时候,因为"!0"这种方式也走了不少弯路,幸好改起来不难。
后来在大佬的代码中看见了count这个函数,给map使用正好能规避这个问题,拿小本本记下来。
I-Unix ls (水题,排版) UVA - 400
The computer company you work for is introducing a brand new computer line and is developing a new Unix-like operating system to be introduced along with the new computer. Your assignment is to write the formatter for the ls function.
Your program will eventually read input from a pipe (although for now your program will read from the input file). Input to your program will consist of a list of (F) filenames that you will sort (ascending based on the ASCII character values) and format into © columns based on the length (L) of the longest filename. Filenames will be between 1 and 60 (inclusive) characters in length and will be formatted into left-justified columns. The rightmost column will be the width of the longest filename and all other columns will be the width of the longest filename plus 2. There will be as many columns as will fit in 60 characters. Your program should use as few rows ® as possible with rows being filled to capacity from left to right.
Input
The input file will contain an indefinite number of lists of filenames. Each list will begin with a line containing a single integer (1 ≤ N ≤ 100). There will then be N lines each containing one left-justified filename and the entire line’s contents (between 1 and 60 characters) are considered to be part of the filename. Allowable characters are alphanumeric (a to z, A to Z, and 0 to 9) and from the following set {._-} (not including the curly braces). There will be no illegal characters in any of the filenames and no line will be completely empty.Immediately following the last filename will be the N for the next set or the end of file. You should read and format all sets in the input file.
Output
For each set of filenames you should print a line of exactly 60 dashes (-) followed by the formatted columns of filenames. The sorted filenames 1 to R will be listed down column 1; filenames R + 1 to 2R listed down column 2; etc.
Sample Input
10
tiny
2short4me
very_long_file_name
shorter
size-1
size2
size3
much_longer_name
12345678.123
mid_size_name
12
Weaser
Alfalfa
Stimey
Buckwheat
Porky
Joe
Darla
Cotton
Butch
Froggy
Mrs_Crabapple
P.D.
19
Mr._French
Jody
Buffy
Sissy
Keith
Danny
Lori
Chris
Shirley
Marsha
Jan
Cindy
Carol
Mike
Greg
Peter
Bobby
Alice
Ruben
Sample Output
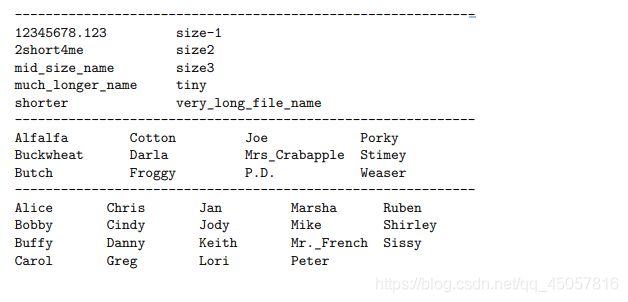
理解
一道水题,就考一下排版,总共60列,除了最右边的为单词最长长度之外,其他列都是最长长度+2,记录这道题是因为他让我看见了两道做过的PTA
题目的影子,感觉题目有强烈的相似性,所以做一下记录
(1)L1-039 古风排版
(2)L1-032 Left-pad
AC代码
#include J-对称轴 (水题,map AND pair) UVA - 1595
The figure shown on the left is left-right symmetric as it is possible to fold the sheet of paper along a vertical line, drawn as a dashed line, and to cut the figure into two identical halves. The figure on the right is not left-right symmetric as it is impossible to find such a vertical line.
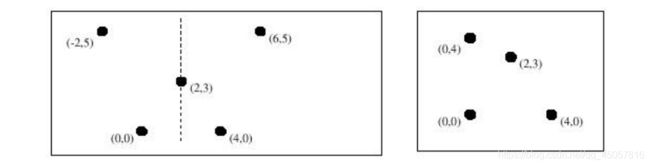
Write a program that determines whether a figure, drawn with dots, is left-right symmetric or not.
The dots are all distinct.
Input
The input consists of T test cases. The number of test cases T is given in the first line of the input file.
The first line of each test case contains an integer N, where N (1 ≤ N ≤ 1, 000) is the number of dots in a figure. Each of the following N lines contains the x-coordinate and y-coordinate of a dot. Both x-coordinates and y-coordinates are integers between −10, 000 and 10, 000, both inclusive.
Output
Print exactly one line for each test case. The line should contain ‘YES’ if the figure is left-right symmetric,and ‘NO’, otherwise.
Sample Input
3
5
-2 5
0 0
6 5
4 0
2 3
4
2 3
0 4
4 0
0 0
4
5 14
6 10
5 10
6 14
Sample Output
YES
NO
YES
理解
一道水题,就考一下找对称轴,记录这道题的原因是,在当时忘记用浮点数耳朵情况下,推数学公式推出了一点好玩的东西,姑且算是有点收获
设对称轴为k,由题意可得
k = sum / n && k = (a + b) / 2
结合一下两个公式可以得到
2 * sum = a * n + b * n 完美地避过了整除将会带来的数据误差问题(也完美地带来了数据过大可能gg的问题【狗头】)
AC代码
## 代码及其简单,就不做注释了
#include K-打印队列 (水题,模拟,队列) UVA - 12100
The only printer in the computer science students’union is experiencing an extremely heavy workload.
Sometimes there are a hundred jobs in the printer queue and you may have to wait for hours to get a
single page of output.
Because some jobs are more important than others,the Hacker General has invented and implemented a
simple priority system for the print job queue. Now,each job is assigned a priority between 1 and 9 (with 9 being the highest priority, and 1 being the lowest), and the printer operates as follows.
• The first job J in queue is taken from the queue.
• If there is some job in the queue with a higher priority than job J, then move J to the end of the queue without printing it.
• Otherwise, print job J (and do not put it back in the queue).
In this way, all those important muffin recipes that the Hacker General is printing get printed very quickly. Of course, those annoying term papers that others are printing may have to wait for quite some time to get printed, but that’s life.
Your problem with the new policy is that it has become quite tricky to determine when your print job will actually be completed. You decide to write a program to figure this out. The program will be given the current queue (as a list of priorities) as well as the position of your job in the queue, and must then calculate how long it will take until your job is printed, assuming that no additional jobs will be added to the queue. To simplify matters, we assume that printing a job always takes exactly one minute, and that adding and removing jobs from the queue is instantaneous.
Input
One line with a positive integer: the number of test cases (at most 100). Then for each test case:
• One line with two integers n and m, where n is the number of jobs in the queue (1 ≤ n ≤ 100) and m is the position of your job (0 ≤ m ≤ n − 1). The first position in the queue is number 0,the second is number 1, and so on.
• One line with n integers in the range 1 to 9, giving the priorities of the jobs in the queue. The first integer gives the priority of the first job, the second integer the priority of the second job, and so on.
Output
For each test case, print one line with a single integer; the number of minutes until your job is completely
printed, assuming that no additional print jobs will arrive.
Sample Input
3
1 0
5
4 2
1 2 3 4
6 0
1 1 9 1 1 1
Sample Output
1
2
5
理解
一道水题,如果不是为了松饼配方我是不会记录这道题的(滑稽)
简单介绍一下题意,你的文件处在打印队列中的某个位置,这个打印队列有一个优先级,如果有优先级更高的文件在队列中,队首文件会被移到队尾,直
到那份优先级最高的文件被打印出来,再继续下一个优先级次一级的文件,且只有打印会消耗时间,移动操作不会耗时。
代码也是十分的暴力,模拟一下就a掉了题
AC代码
#include L-图书管理系统 (模拟,set) UVA - 230
I mean your borrowers of books — those mutilators of collections, spoilers of the symmetry of shelves, and creators of odd volumes.
– (Charles Lamb, Essays of Elia (1823) ‘The Two Races of Men’)
Like Mr. Lamb, librarians have their problems with borrowers too. People don’t put books back where they should. Instead, returned books are kept at the main desk until a librarian is free to replace them in the right places on the shelves. Even for librarians, putting the right book in the right place can be very time-consuming. But since many libraries are now computerized, you can write a program to
help.
When a borrower takes out or returns a book, the computer keeps a record of the title. Periodically, the librarians will ask your program for a list of books that have been returned so the books can be returned to their correct places on the shelves. Before they are returned to the shelves, the returned books are sorted by author and then title using the ASCII collating sequence. Your program should output the list of returned books in the same order as they should appear on the shelves. For each book, your program should tell the librarian which book (including those previously shelved) is already on the shelf before which the returned book should go.
Input
First, the stock of the library will be listed, one book per line, in no particular order. Initially, they are all on the shelves. No two books have the same title. The format of each line will be:title" by author
The end of the stock listing will be marked by a line containing only the word:
END
Following the stock list will be a series of records of books borrowed and returned, and requests from librarians for assistance in restocking the shelves. Each record will appear on a single line, in one of the following formats:
BORROW title
RETURN title
SHELVE
The list will be terminated by a line containing only the word:
END
Output
Each time the SHELVE command appears, your program should output a series of instructions for the librarian, one per line, in the format:
Put title1 after title2
or, for the special case of the book being the first in the collection:
Put title first
After the set of instructions for each SHELVE, output a line containing only the word:
END
Assumptions & Limitations:
- A title is at most 80 characters long.
- An author is at most 80 characters long.
- A title will not contain the double quote (") character.
Sample Input
“The Canterbury Tales” by Chaucer, G.
“Algorithms” by Sedgewick, R.
“The C Programming Language” by Kernighan, B. and Ritchie, D.
END
BORROW “Algorithms”
BORROW “The C Programming Language”
RETURN “Algorithms”
RETURN “The C Programming Language”
SHELVE
END
Sample Output
Put “The C Programming Language” after “The Canterbury Tales”
Put “Algorithms” after “The C Programming Language”
END
理解
一道有一点难度的模拟题,题目大意为告诉你一个图书馆有什么书,然后有被借走和归还的操作,被归还的书会放到书桌上,当要放回书架时,应先按
作者和书名进行排序,然后放回书架,并且要输出,这本书应该放在哪本书后面,如果它应该被放在开头,则输出它在开头位置。
坑点:借书和还书貌似会有重复操作,还书可以用set完美避免,借书一定要先检查这本书在不在书架上,不然会re
写这题时的不足之处:当时对pair运用不太了解,强行自己写了一个book结构体,然后重载了()运算符,实际上,用pair把作者放第一个元素,书名放
第二个元素就能让set按优先级自动排序,比自己写重载好的多
AC代码
#include M-找Bug (模拟,递归写栈) UVA - 1596
In this problem, we consider a simple programming language that has only declarations of onedimensional integer arrays and assignment statements. The problem is to find a bug in the given program.
The syntax of this language is given in BNF as follows:
⟨program⟩ ::= ⟨declaration⟩|⟨program⟩⟨declaration⟩|⟨program⟩⟨assignment⟩
⟨declaration⟩ ::= ⟨array name⟩ [⟨number⟩]⟨new line⟩
⟨assignment⟩ ::= ⟨array name⟩ [⟨expression⟩]= ⟨expression⟩⟨newline⟩
⟨expression⟩ ::= ⟨number⟩|⟨array name⟩ [⟨expression⟩]
⟨number⟩ ::= ⟨digit⟩|⟨digit positive⟩⟨digit string⟩
⟨digit string⟩ ::= ⟨digit⟩|⟨digit⟩⟨digit string⟩
⟨digit positive⟩ ::= 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
⟨digit⟩ ::= 0 | ⟨digit positive⟩
⟨array name⟩ ::= a | b | c | d | e | f | g | h | i | j | k | l | m |
n | o | p | q | r | s | t | u | v | w | x | y | z |
A | B | C | D | E | F | G | H | I | J | K | L | M |
N | O | P | Q | R | S | T | U | V | W | X | Y | Z
where ⟨new line⟩ denotes a new line character (LF).
Characters used in a program are alphabetical letters, decimal digits, =, [, ] and new line characters.
No other characters appear in a program.
A declaration declares an array and specifies its length. Valid indices of an array of length n are integers between 0 and n − 1, inclusive. Note that the array names are case sensitive, i.e. array a and array A are different arrays. The initial value of each element in the declared array is undefined.
For example, array a of length 10 and array b of length 5 are declared respectively as follows.
a[10]
b[5]
An expression evaluates to a non-negative integer. A ⟨number⟩ is interpreted as a decimal integer.
An ⟨array name⟩ [⟨expression⟩] evaluates to the value of the ⟨expression⟩-th element of the array.
An assignment assigns the value denoted by the right hand side to the array element specified by the
left hand side.
Examples of assignments are as follows.
a[0]=3
a[1]=0
a[2]=a[a[1]]
a[a[0]]=a[1]
A program is executed from the first line, line by line. You can assume that an array is declared once and only
once before any of its element is assigned or referred to.
Given a program, you are requested to find the following bugs.
• An index of an array is invalid.
• An array element that has not been assigned before is referred to in an assignment as an index of array or as the value to be assigned.
You can assume that other bugs, such as syntax errors, do not appear. You can also assume that integers represented by ⟨number⟩s are between 0 and 231 − 1 (= 2147483647), inclusive.
Input
The input consists of multiple datasets followed by a line which contains only a single ‘.’ (period).
Each dataset consists of a program also followed by a line which contains only a single ‘.’ (period).
A program does not exceed 1000 lines. Any line does not exceed 80 characters excluding a new line character.
Output
For each program in the input, you should answer the line number of the assignment in which the first bug appears. The line numbers start with 1 for each program. If the program does not have a bug,you should answer zero. The output should not contain extra characters such as spaces.
Sample Input
a[3]
a[0]=a[1]
.
x[1]
x[0]=x[0]
.
a[0]
a[0]=1
.
b[2]
b[0]=2
b[1]=b[b[0]]
b[0]=b[1]
.
g[2]
G[10]
g[0]=0
g[1]=G[0]
.
a[2147483647]
a[0]=1
B[2]
B[a[0]]=2
a[B[a[0]]]=3
a[2147483646]=a[2]
.
.
Sample Output
2
2
2
3
4
0
理解
本题大意就是找出哪一行的代码开始出错。实际上模拟起来也是比较简单的,对各种情况做一个分治就好了
1.定义操作
这个操作时不可能出bug的,文中貌似也没提到重复定义这个操作的存在,但我们要用定义时数组的大小来约束赋值时数组的下标,防止下标越界
2.赋值操作
这个操作又可以分为两种情况,直接赋值和间接赋值
(1)直接赋值
例如a[1]=1,右边的值是数字,那我们只需要判断左边的数组和下标是否合法即可
(2)间接赋值
例如a[1]=b[1],右边的值是数字和下标,这时我们要判断两边的是否都合法
难点:如何处理多重括号,其实经历过“计算”这种题目的洗礼,对于这种规律性极强的括号,处理起来就比较方便了,列出下列两个方法
[1]采用递归的思路,模拟一个栈,层层分解多重括号
[2]采用stl内的stack,不断把数组名称压栈,知道压倒纯数字,再出栈到空
我的代码采用了第一种思路(我能说写计算那题的栈有心理阴影,不想再用stack了吗)
AC代码
#include N- Web中搜索,有意义 (模拟) UVA - 1597
The word “search engine” may not be strange to you. Generally speaking, a search engine searches the web pages available in the Internet, extracts and organizes the information and responds to users’ queries with the most relevant pages. World famous search engines, like GOOGLE, have become very important tools for us to use when we visit the web. Such conversations are now common in our daily life:
“What does the word like ∗ ∗ ∗ ∗ ∗∗ mean?”
“Um. . . I am not sure, just google it.”
In this problem, you are required to construct a small search engine. Sounds impossible, does it?Don’t worry, here is a tutorial teaching you how to organize large collection of texts efficiently and respond to queries quickly step by step. You don’t need to worry about the fetching process of web pages, all the web pages are provided to you in text format as the input data. Besides, a lot of queries are also provided to validate your system.
Modern search engines use a technique called inversion for dealing with very large sets of documents.The method relies on the construction of a data structure, called an inverted index, which associates terms (words) to their occurrences in the collection of documents. The set of terms of interest is called the vocabulary, denoted as V . In its simplest form, an inverted index is a dictionary where each search key is a term ω ∈ V . The associated value b(ω) is a pointer to an additional intermediate data structure,called a bucket. The bucket associated with a certain term ω is essentially a list of pointers marking all the occurrences of ω in the text collection. Each entry in each bucket simply consists of the document identifier (DID), the ordinal number of the document within the collection and the ordinal line number of the term’s occurrence within the document.
Let’s take Figure-1 for an example, which describes the general structure. Assuming that we only have three documents to handle, shown at the right part in Figure-1; first we need to tokenize the text for words (blank, punctuations and other non-alphabetic characters are used to separate words) and construct our vocabulary from terms occurring in the documents. For simplicity, we don’t need to consider any phrases, only a single word as a term. Furthermore, the terms are case-insensitive (e.g. we consider “book” and “Book” to be the same term) and we don’t consider any morphological variants (e.g. we consider “books” and “book”, “protected” and “protect” to be different terms) and hyphenated words (e.g. “middle-class” is not a single term, but separated into 2 terms “middle” and “class” by the hyphen). The vocabulary is shown at the left part in Figure-1. Each term of the vocabulary has a pointer to its bucket. The collection of the buckets is shown at the middle part in Figure-1. Each item in a bucket records the DID of the term’s occurrence.
After constructing the whole inverted index structure, we may apply it to the queries. The query is in any of the following formats:
term
term AND term
term OR term
NOT term
A single term can be combined by Boolean operators: ‘AND’, ‘OR’ and ‘NOT’ (‘term1 AND term2’ means to query the documents including term1 and term2; ‘term1 OR term2’ means to query the documents including term1 or term2; ‘NOT term1’ means to query the documents not including term1). Terms are single words as defined above. You are guaranteed that no non-alphabetic characters appear in a term, and all the terms are in lowercase. Furthermore, some meaningless stop words (common words such as articles, prepositions, and adverbs, specified to be “the, a, to, and, or, not” in our problem) will not appear in the query, either.
For each query, the engine based on the constructed inverted index searches the term in the vocabulary,compares the terms’ bucket information, and then gives the result to user. Now can you construct the engine?
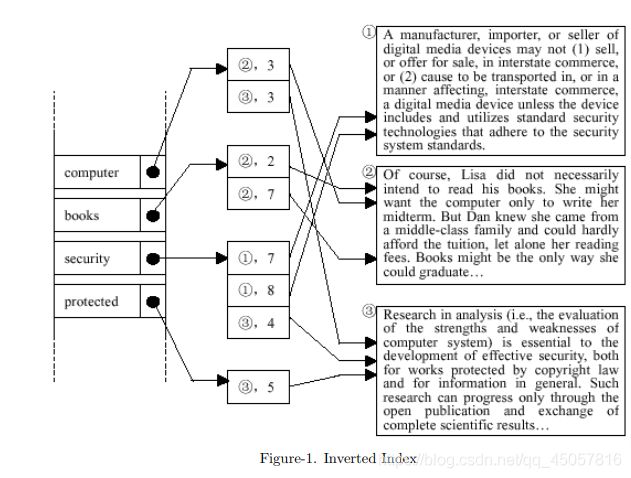
Input

Output

Sample Input

Sample Output

理解
本题大意根据你要查找的单词,找到哪边文章有或没有,然后选择性输出,不同文章直接用---------分割,不同查询直接用=========分割,而找不到
就输出Sorry,I found nothing.
注意:此处的单词的大小写都要考虑在内
模拟起来也是有一点复杂,你要先看这篇文章里有没有这个词,再输出这个词所在的那一行话,虽然繁琐,但还是可以模拟的
下面是一些命令
term 输出有term这个单词的行
term AND term 输出同时有前者和后者的文章里存在两者之一的行
term OR term 输出只要有前者和后者的文章里存在两者之一的行
NOT term 输出没有这个单词的文章里所有的行
AC代码
#include 代码也是写的比较臃肿,模拟的能力还是比较差,有大量相似度极高的代码
O-更新字典 (水题) UVA - 12504
In this problem, a dictionary is collection of key-value pairs, where keys are lower-case letters, and values are non-negative integers. Given an old dictionary and a new dictionary, find out what were changed.
Each dictionary is formatting as follows:
{key:value,key:value,…,key:value}
Each key is a string of lower-case letters, and each value is a non-negative integer without leading zeros or prefix ‘+’. (i.e. -4, 03 and +77 are illegal). Each key will appear at most once, but keys can appear in any order.
Input
The first line contains the number of test cases T (T ≤ 1000). Each test case contains two lines. The first line contains the old dictionary, and the second line contains the new dictionary. Each line will contain at most 100 characters and will not contain any whitespace characters. Both dictionaries could be empty.
WARNING: there are no restrictions on the lengths of each key and value in the dictionary. That means keys could be really long and values could be really large.
Output
For each test case, print the changes, formatted as follows:
• First, if there are any new keys, print ‘+’ and then the new keys in increasing order (lexicographically),separated by commas.
• Second, if there are any removed keys, print ‘-’ and then the removed keys in increasing order (lexicographically), separated by commas.
• Last, if there are any keys with changed value, print ‘*’ and then these keys in increasing order (lexicographically), separated by commas.
If the two dictionaries are identical, print ‘No changes’ (without quotes) instead.Print a blank line after each test case.
Sample Input
3
{a:3,b:4,c:10,f:6}
{a:3,c:5,d:10,ee:4}
{x:1,xyz:123456789123456789123456789}
{xyz:123456789123456789123456789,x:1}
{first:1,second:2,third:3}
{third:3,second:2}
Sample Output
+d,ee
-b,f
*c
No changes
-first
理解
很简单的题目,找找差集就结束了,写完前面的题目写这题感觉在玩一样【狗头】
大意就是看新的密钥串中,新出现的,消失的,以及值改变的密钥
AC代码
#include P-Gathering Children (水题,思维题) atcoder
Time Limit: 2 sec / Memory Limit: 1024 MB
Score : 400 points
Problem Statement
Given is a string S consisting of L and R.
Let N be the length of S. There are N squares arranged from left to right, and the i-th character of S from the left is written on the i-th square from the left.
The character written on the leftmost square is always R, and the character written on the rightmost square is always L.
Initially, one child is standing on each square.
Each child will perform the move below 10^100 times:
Move one square in the direction specified by the character written in the square on which the child is standing. L denotes left, and R denotes right.
Find the number of children standing on each square after the children performed the moves.
Constraints
S is a string of length between 2 and 10^5 (inclusive).
Each character of S is L or R.
The first and last characters of S are R and L, respectively.
Input
Input is given from Standard Input in the following format:
S



理解
这应该是遇见过的最简单的第四题了(上周数位dp写的我想死,后来看大佬代码和题解也看不懂。。。暴风哭泣)
先说说这道题的大意,有数量为s的方块,每个方块上有一个小孩和一个字母,小孩会根据方块上的字母移动,R为往右移动,
L为往左移动,他们每个人都会移动10^100次,求最后每个方块上有多少个小孩(左右两端封闭R和L),不用担心小孩跑出
去。
简单的找一下规律可以发现,小孩最后必然陷入L和R之间的循环,我们完全可以通过小孩的原位置和最终会陷入循环的下标
来判断小孩最后呆在哪里
举个栗子:
RRL,找原坐标为0的孩子最后在那,对于0坐标的R,第一次遇到L在下标2的地方,进行一个简单的计算
(2 - 0) % 2 == 0 所以他最后会呆在下标为2的地方
而原坐标为1的R,(1 - 0) % 2 != 0 所以他最后会想下标2 - 1的地方
所以我们只要找到每个L和R最近的陷入循环的R和L,然后计算最后小孩会呆在哪就ok了
k代表陷入循环的下标,i代表当前下标
R的位置公式
if((k - i) % 2 == 0) ans[k]++;
if((k - i) % 2 != 0) ans[k - 1]++;
L的位置公式
if((i - k) % 2 != 0) ans[k + 1]++;
if((i - k) % 2 == 0) ans[k]++;
AC代码
#include (二)一些收获
关于STL
说实话,STL的学习感觉还是太急促了,感觉就是刚讲完加减乘除,你就要硬着头皮上去写积分了一半(苦笑)
下面就写一点点关于STL的想法吧
1.STL在解题上确实起到了极大的帮助,对于一些本来处理起来很复杂的模拟题,我们用简短的代码就能写出答案
2.STL单纯的使用并不难,真正的难点在于容器的叠加使用,在后面一些比较复杂的模拟题里面,单纯的容器显然是不够用的
,而在结合使用这一块确实是有难度,需要有一个慢慢练习的过程
3.不能过分依赖于STL,对于一些题目,模板式的STL可能还没自己写的代码方便
4.一定要充分掌握STL容器和string类型里面大部分基础函数的用法,并且使用熟练,这样写题时很多操作才能快速想到(这
两天写题疯狂查函数太累了人,好在在这过程中也学了不少东西)
关于模拟题
在学习玩STL之后,写之前难写的模拟题写起来不要太轻松,但也引出了真正的难题(反正课后习题训练,后面几个难的模拟题把我看自闭了,不是看不懂,就是完全没有模拟的思路,蒟蒻的我望题自闭)
1.写模拟题的时候注意分块写,一点一点来不容易出错,这一点上周也说过了,只是这周感觉更深了
2.很多模拟题的输入和预处理相当麻烦,这一块优先处理,再慢慢考虑后面模拟的事
3.可以每写完一小块模拟,先运行看看这一块写的是否可行(我这么写的时候,明显的减少了wa次数),因
有错也可以及时找出。但也会造成写题速度较慢的缺点(比较写一块调整一块,肯定没有人家大佬一次写对
来的快),目前蒟蒻的我还是很喜欢这种方法的
(三)感想
大概就以下几点
1.对STL有一定学习之后,写一些难点的模拟题确实也是更加得心应手了,但也认识到了真正难的模拟会难到什么程度,模拟这一块还要继续联系
2.对STL里容器的叠加运用掌握实在是太少,很多题目对于这方面要求较高,还是要自己慢慢摸索
3.写题目时还是要注意容器的选择,合适的容器模拟起来会简单很多
4.感觉对于长代码的构架能力强了不少,一些稍微有点复杂的模拟是能慢慢敲出来了,但不足之处也很明显,很多时候敲出来的代码很臃肿,重复内容有点多
总结:经过这一周的学习,是对STL有了一定的掌握,在各种容器的帮助下,能够写出一些原来写起来很费力的题目了。构架代码的能力也算有点增强,对于模拟的题目更加得心应手了一点。读题能力貌似增强不多(大部分时候谷歌翻译或者直接找中文题意),真的长篇题目读起来太累了,英语水平确实太低了,还有待增强。
(革命尚未成功,同志尚需努力[狗头])
(四)附录[学习笔记]
另写了一片blog记载,放一起堆着太多了,就贴一下地址
https://blog.csdn.net/qq_45057816/article/details/97759205