c语言数据结构实现-哈希表/哈希桶(hashtable/hashbucket)
一、需求
以“key-value”的形式进行插入、查询、删除,是否可以考虑牺牲空间换时间的做法?
二、相关知识
哈希表(Hashtable)又称为“散列表”,Hashtable是会根据索引键的哈希程序代码组织成的索引键(Key)和值(Value)配对的集合。Hashtable 对象是由包含集合中元素的哈希桶(Bucket)所组成的。而Bucket是Hashtable内元素的虚拟子群组,可以让大部分集合中的搜寻和获取工作更容易、更快速。[1]
哈希函数(Hash Function)为根据索引键来返回数值哈希程序代码的算法。索引键(Key)是被存储对象的某些属性值(Value)。当对象加入至 Hashtable时,它存储在与对象哈希程序代码相符的哈希程序代码相关的Bucket中。当在Hashtable内搜寻值时,哈希程序代码会为该值产生,并且会搜寻与该哈希程序代码相关的Bucket。例如,student和teacher会放在不同的Bucket中,而dog和god会放在相同的 Bucket中。所以当索引键是唯一从Hashtable获取元素的性能时表现会较好。[1]
哈希表的优势体现在于空间换时间上,在设计哈希表时需要注意以下情况[2]:
1)Hash函数的选择,一个好的哈希函数可以均匀地将数据样本散列到表中;
2)冲突的解决方法,常用的冲突处理就是拉链法,即出现冲突时以链表的形式扩展;
3)表大小与关键字个数的平衡,设表大小为M,关键字个数为N,当装填因子(k=N/M)越大则冲突越严重;
三、源码实现
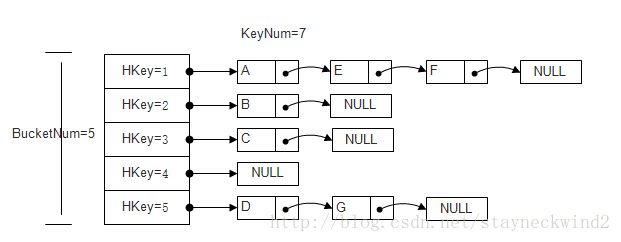
先放一个图例,Hashtable由多个Bucket组成,Bucket以HashKey值为索引,每个Bucket中存放着所有HashKey相同的(Key, Value)
如图所示,BucketNum = 5, DataNum = 7, 可见 k = 1.4 有一些冲突,更能很好地看出拉链法是如何解决冲突问题的:
如Key=A Key=E Key=F 算出来的 HKey 均为1,所以(A, ValueA) (B, ValueB) (C, ValueC) 均放入HKey = 1 的 Bucket中;
程序源码源于Linux内核源码修改:linux-3.10.25/security/selinux/ss/hashtab.c
以下直接分析源码,先上结构体,其中hashtab标识了整个hash表,而**htable 为buckets集合,hashtab_node则是链表节点
仔细看了一下,他这种写法灵活性非常强,首先(key, datum)分别为指针,按照调用者的用法就是外部申请好datum空间,告诉接口key 进行索引管理,而接口内部并不关心datum是什么内容,查询的时候只需要再把datum指针返回给调用者;
然后在主体结构hashtab中,预留了回调函数hash_value、keycmp,我理解就是相当于c++模板、java抽象类的思路,调用者的key可以是int、long、char*任何类型的,只需要定义好相关的合理实现即可;
struct hashtab_node {
void *key;
void *datum;
struct hashtab_node *next;
};
struct hashtab {
struct hashtab_node **htable; /* hash table */
u32 size; /* number of slots in hash table */
u32 nel; /* number of elements in hash table */
u32 (*hash_value)(struct hashtab *h, void *key); /* hash function */
int (*keycmp)(struct hashtab *h, void *key1, void *key2); /* key comparison function */
};struct hashtab *hashtab_create(u32 (*hash_value)(struct hashtab *h, void *key),
int (*keycmp)(struct hashtab *h, void *key1, void *key2),
u32 size)
{
struct hashtab *p;
u32 i;
p = kzalloc(sizeof(*p), GFP_KERNEL);
if (p == NULL)
return p;
p->size = size;
p->nel = 0;
p->hash_value = hash_value;
p->keycmp = keycmp;
p->htable = kmalloc(sizeof(*(p->htable)) * size, GFP_KERNEL);
if (p->htable == NULL) {
kfree(p);
return NULL;
}
for (i = 0; i < size; i++)
p->htable[i] = NULL;
return p;
}但是有一点使用起来不太方便,就是key的保存他使用的是直接指针赋值,若使用同一个变量取地址进行传参,这样将会出现问题;
int hashtab_insert(struct hashtab *h, void *key, void *datum)
{
u32 hvalue;
struct hashtab_node *prev, *cur, *newnode;
if (!h || h->nel == HASHTAB_MAX_NODES)
return -EINVAL;
hvalue = h->hash_value(h, key);
prev = NULL;
cur = h->htable[hvalue];
while (cur && h->keycmp(h, key, cur->key) > 0) {
prev = cur;
cur = cur->next;
}
if (cur && (h->keycmp(h, key, cur->key) == 0))
return -EEXIST;
newnode = kzalloc(sizeof(*newnode), GFP_KERNEL);
if (newnode == NULL)
return -ENOMEM;
newnode->key = key;
newnode->datum = datum;
if (prev) {
newnode->next = prev->next;
prev->next = newnode;
} else {
newnode->next = h->htable[hvalue];
h->htable[hvalue] = newnode;
}
h->nel++;
return 0;
}同理可知删除节点也是类似的流程;
void *hashtab_search(struct hashtab *h, void *key)
{
u32 hvalue;
struct hashtab_node *cur;
if (!h)
return NULL;
hvalue = h->hash_value(h, key);
cur = h->htable[hvalue];
while (cur != NULL && h->keycmp(h, key, cur->key) > 0)
cur = cur->next;
if (cur == NULL || (h->keycmp(h, key, cur->key) != 0))
return NULL;
return cur->datum;
}在这个接口中,我认为是可以扩充的,一是可以加一个 free_callback 帮助用户数据进行销毁;其次传参的时候可以用二级指针,调用结束后外部的变量设置为NULL,避免了野指针的出现;
void hashtab_destroy(struct hashtab *h)
{
u32 i;
struct hashtab_node *cur, *temp;
if (!h)
return;
for (i = 0; i < h->size; i++) {
cur = h->htable[i];
while (cur != NULL) {
temp = cur;
cur = cur->next;
kfree(temp);
}
h->htable[i] = NULL;
}
kfree(h->htable);
h->htable = NULL;
kfree(h);
}四、总结
参考文章:
[1] http://www.nowamagic.net/academy/detail/3008086
[2] http://blog.csdn.net/freetourw/article/details/53493616
[3] http://blog.chinaunix.net/uid-27213819-id-3794127.html